






在查阅文献的时候,经常会需要阅读一些年代久远的经典论文,这些论文往往为扫描版,不够清晰也无法复制,可以用acrobat进行文本的识别并转换为清晰、可复制的内容。
用adobe acrobat打开一篇不太清晰的文献。
在需要识别的当页点击“编辑文本和图像”
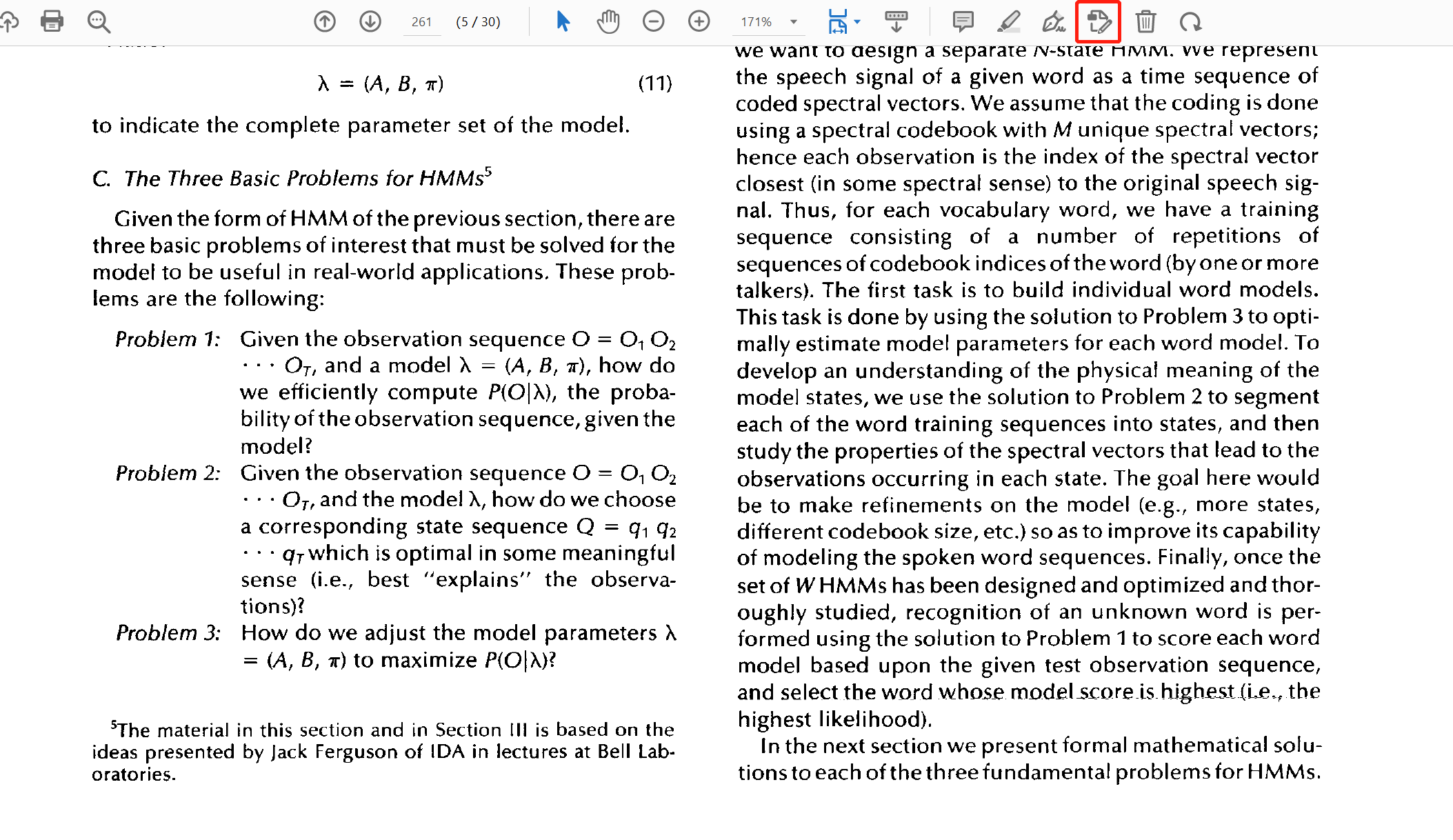
等待识别

识别完成后随便选取该页的任意一段文字,该页的内容就会自动变成清晰、可复制的pdf页面
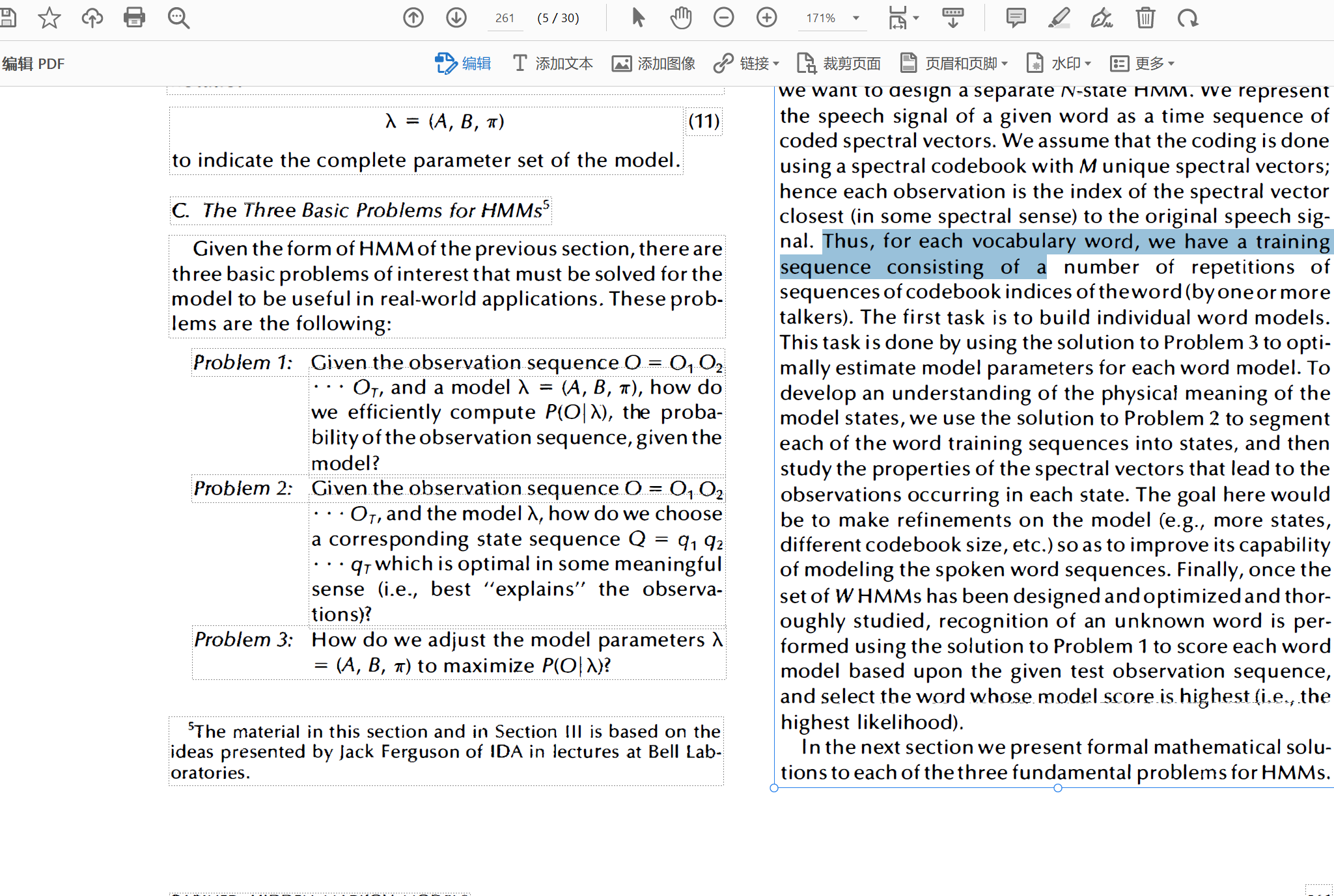
点击关闭,ctrl+s保存即可。
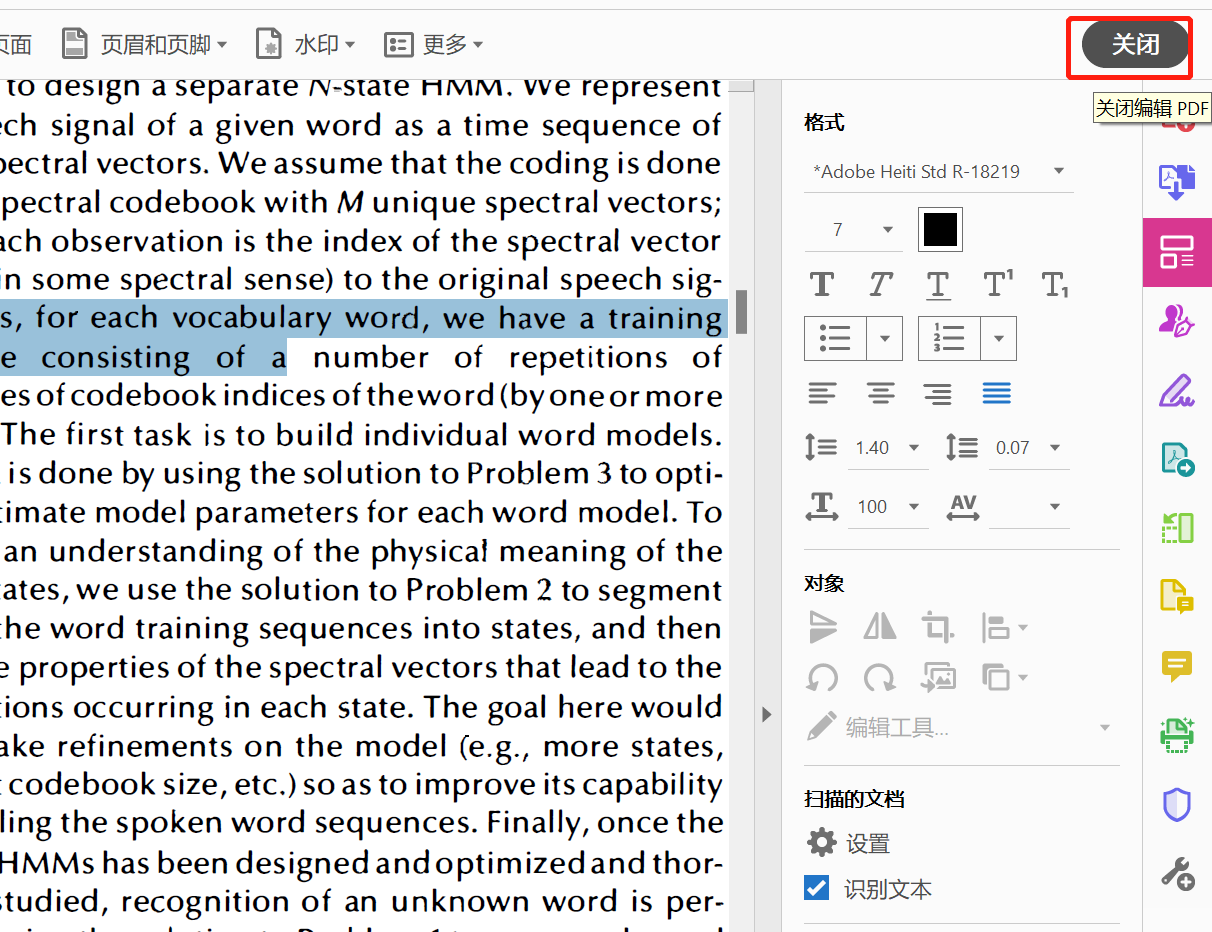
在查阅文献的时候,经常会需要阅读一些年代久远的经典论文,这些论文往往为扫描版,不够清晰也无法复制,可以用acrobat进行文本的识别并转换为清晰、可复制的内容。
用adobe acrobat打开一篇不太清晰的文献。
在需要识别的当页点击“编辑文本和图像”
等待识别
识别完成后随便选取该页的任意一段文字,该页的内容就会自动变成清晰、可复制的pdf页面
点击关闭,ctrl+s保存即可。
 926
11万+
926
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























