







文章目录
3.4 Redis 三种特殊数据类型
1️⃣ geospatial
应用场景参考:
微信朋友圈中的朋友的位置,附近的人搜索展示
饿了么中外卖小哥的位置距离
**中文网站参考:**http://www.redis.cn/commands/geoadd.html https://www.redis.net.cn/order/3685.html
**官网地址:**https://redis.io/commands/geoadd/
注意:在 geoadd 命令中文翻译页面是错误的,官网是 " Adds the specified geospatial items (longitude(经度), latitude(纬度), name) to the specified key. ",中文网站时( 纬度、经度、名称 )
顺序错误的话添加时会报错 ,如下
“127.0.0.1:6379> GEOADD china:city 31.23 121.47 shanghai
ERR invalid longitude,latitude pair 31.230000,121.470000”
中国城市地理位置参考网站: http://www.jsons.cn/lngcode
GEOADD
将指定的地理空间位置(经度、纬度、名称)添加到指定的
key中
# 示例:添加一些城市
127.0.0.1:6379> GEOADD china:city 121.472644 31.231706 shanghai
1
127.0.0.1:6379> GEOADD china:city 116.405285 39.904989 beijing
1
127.0.0.1:6379> GEOADD china:city 113.280637 23.125178 guangzhou
1
127.0.0.1:6379> GEOADD china:city 114.298572 30.384355 wuhan 106.88656 39.44128 hainan
2
127.0.0.1:6379>
GEOPOS
从
key里返回所有给定位置元素的位置(经度和纬度)
127.0.0.1:6379> GEOPOS china:city shanghai
121.47264629602432251
31.23170490709807012
127.0.0.1:6379> GEOPOS china:city shanghai beijing
121.47264629602432251
31.23170490709807012
116.40528291463851929
39.9049884229125027
127.0.0.1:6379>
GEODIST
返回两个给定位置之间的距离
如果两个位置之间的其中一个不存在, 那么命令返回空值。
指定单位的参数 unit 必须是以下单位的其中一个:
- m 表示单位为米。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
如果用户没有显式地指定单位参数, 那么
GEODIST默认使用米作为单位。
GEODIST命令在计算距离时会假设地球为完美的球形, 在极限情况下, 这一假设最大会造成 0.5% 的误差。
# 示例:
127.0.0.1:6379> GEODIST china:city shanghai beijing M # 北京到上海的距离
1067597.9668
127.0.0.1:6379> GEODIST china:city shanghai beijing KM
1067.5980
127.0.0.1:6379>
GEORADIUS
以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
范围可以使用以下其中一个单位:
- m 表示单位为米。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
在给定以下可选项时, 命令会返回额外的信息:
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。WITHCOORD: 将位置元素的经度和维度也一并返回。WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。命令默认返回未排序的位置元素。 通过以下两个参数, 用户可以指定被返回位置元素的排序方式:
ASC: 根据中心的位置, 按照从近到远的方式返回位置元素。DESC: 根据中心的位置, 按照从远到近的方式返回位置元素。在默认情况下, GEORADIUS 命令会返回所有匹配的位置元素。 虽然用户可以使用 COUNT 选项去获取前 N 个匹配元素, 但是因为命令在内部可能会需要对所有被匹配的元素进行处理, 所以在对一个非常大的区域进行搜索时, 即使只使用
COUNT选项去获取少量元素, 命令的执行速度也可能会非常慢。 但是从另一方面来说, 使用COUNT选项去减少需要返回的元素数量, 对于减少带宽来说仍然是非常有用的。
# 语法格式:
GEORADIUS key longitude latitude radius M|KM|FT|MI [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC|DESC] [STORE key] [STOREDIST key]
# 参数解析:
key # zadd 设置的键值
longitude # 经度
latitude # 纬度
radius # 对应的名称
M|KM|FT|MI # 距离单位
WITHDIST # 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
WITHCOORD # 将位置元素的经度和维度也一并返回。
WITHHASH # 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
COUNT count [ANY] # 获取指定个数的元素
ASC # 根据中心的位置, 按照从近到远的方式返回位置元素
DESC # 根据中心的位置, 按照从远到近的方式返回位置元素
STORE key # 将通过前面参数查询到的结果添加到一个新的 key 中
# 示例:
127.0.0.1:6379> GEORADIUS china:city 115 30 500 KM # 这里模拟经纬度是 115 30 方圆 500KM 距离内在这个集合中的城市
wuhan
127.0.0.1:6379> GEORADIUS china:city 115 30 1000 KM
guangzhou
wuhan
shanghai
127.0.0.1:6379> GEORADIUS china:city 115 30 500 KM withcoord # 返回定位位置信息
1) 1) "wuhan"
2) 1) "114.29857403039932251"
2) "30.38435522769453456"
127.0.0.1:6379> GEORADIUS china:city 115 30 500 KM withdist # 返回定位距离
1) 1) "wuhan"
2) "79.8425"
127.0.0.1:6379>
127.0.0.1:6379> GEORADIUS china:city 115 30 500 KM withhash
1) 1) "wuhan"
2) (integer) 4051933734342121
127.0.0.1:6379> GEORADIUS china:city 115 30 500 KM count 1
1) "wuhan"
127.0.0.1:6379> GEORADIUS china:city 115 30 500 KM count 2 # 返回指定个数的元素,这个测试的数据只有一个符合的,所以就算是统计两个也只有一个返回
1) "wuhan"
127.0.0.1:6379> GEORADIUS china:city 115 30 500 KM store
(error) ERR syntax error
127.0.0.1:6379> GEORADIUS china:city 115 30 500 KM store china # 将查询到的结果返回到一个新的 key 中
(integer) 1
127.0.0.1:6379> keys *
1) "china"
2) "china:city"
127.0.0.1:6379> ZRANGE china 0 -1
1) "wuhan"
GEORADIUSBYMEMBER
这个命令和 GEORADIUS 命令一样, 都可以找出位于指定范围内的元素, 但是
GEORADIUSBYMEMBER的中心点是由给定的位置元素决定的, 而不是像 GEORADIUS 那样, 使用输入的经度和纬度来决定中心点
- 指定成员的位置被用作查询的中心
# 示例:
127.0.0.1:6379> GEORADIUSBYMEMBER china:city shanghai 1000 KM # 以上海为指定元素,查出距离上海 1000 KM 内的城市
1) "wuhan"
2) "shanghai"
127.0.0.1:6379>
ZRANGE / ZREM
GEO 底层的实现原理其实就是 zset ,所以我们可以通过 zset 的命令来操作 geo
# 示例:
127.0.0.1:6379> ZRANGE china:city 0 -1 # 查看集合中的所有元素
1) "hainan"
2) "guangzhou"
3) "wuhan"
4) "shanghai"
5) "beijing"
127.0.0.1:6379> ZREM china:city hainan # 删除集合中的一个指定元素
(integer) 1
127.0.0.1:6379> ZRANGE china:city 0 -1
1) "guangzhou"
2) "wuhan"
3) "shanghai"
4) "beijing"
127.0.0.1:6379>
2️⃣ HyperLogLog
HyperLogLog是用来做基数统计的算法,它提供不精确的去重计数方案(这个不精确并不是非常不精确),标准误差是0.81%,对于UV这种统计来说这样的误差范围是被允许的。HyperLogLog的优点在于,输入元素的数量或者体积非常大时,基数计算的存储空间是固定的。在Redis中,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64个不同的基数。
但是:HyperLogLog只能统计基数的大小(也就是数据集的大小,集合的个数),他不能存储元素的本身,不能向set集合那样存储元素本身,也就是说无法返回元素
案例场景:
假设产品经理让你设计一个模块,来统计PV(Page View页面的访问量),那么你会怎么做?
我想很多人对于PV(Page View页面的访问量)的统计会很快的想到使用Redis的incr、incrby指令,给每个网页配置一个独立Redis计数器就可以了,把这个技术区的key后缀加上当它的日期,这样一个请求过来,就可以通过执行incr、incrby指令统计所有PV。
此时当你完成这个需求后,产品经理又让你设计一个模块,统计UV(Unique Visitor,独立访客),那么你又会怎么做呢?
UV与PV不一样,UV需要根据用户ID去重,如果用户没有ID我们可能需要考虑使用用户访问的IP或者其他前端穿过了的唯一标志来区分,此时你可能会想到使用如下的方案来统计UV。
存储在MySQL数据库表中,使用distinct count计算不重复的个数
使用Redis的set、hash、bitmaps等数据结构来存储,比如使用set,我们可以使用用户ID,通过sadd加入set集合即可
但是上面的两张方案都存在两个比较大的问题:
随着数据量的增加,存储数据的空间占用越来越大,对于非常大的页面的UV统计,基本不合实际
统计的性能比较慢,虽然可以通过异步方式统计,但是性能并不理想
因此针对UV的统计,我们将会考虑使用Redis的新数据类型HyperLogLog
PFADD
如果一个HyperLogLog的估计的近似基数在执行命令过程中发了变化, PFADD 返回1,否则返回0,如果指定的key不存在,这个命令会自动创建一个空的HyperLogLog结构(指定长度和编码的字符串).
如果在调用该命令时仅提供变量名而不指定元素也是可以的,如果这个变量名存在,则不会有任何操作,如果不存在,则会创建一个数据结构(返回1)
# 示例:
127.0.0.1:6379> PFADD mykey 1 2 3 4 5 6 7 8
(integer) 1
127.0.0.1:6379> PFCOUNT mykey
(integer) 8
127.0.0.1:6379>
PFCOUNT
当参数为一个key时,返回存储在HyperLogLog结构体的该变量的近似基数,如果该变量不存在,则返回0.
当参数为多个key时,返回这些HyperLogLog并集的近似基数,这个值是将所给定的所有key的HyperLoglog结构合并到一个临时的HyperLogLog结构中计算而得到的.
HyperLogLog可以使用固定且很少的内存(每个HyperLogLog结构需要12K字节再加上key本身的几个字节)来存储集合的唯一元素.
返回的可见集合基数并不是精确值, 而是一个带有 0.81% 标准错误(standard error)的近似值.
例如为了记录一天会执行多少次各不相同的搜索查询, 一个程序可以在每次执行搜索查询时调用一次PFADD, 并通过调用PFCOUNT命令来获取这个记录的近似结果.
注意: 这个命令的一个副作用是可能会导致HyperLogLog内部被更改,出于缓存的目的,它会用8字节的来记录最近一次计算得到基数,所以PFCOUNT命令在技术上是个写命令.
# 示例:
127.0.0.1:6379> PFADD mykey 1 2 3 4 5 6 7 8
(integer) 1
127.0.0.1:6379> PFCOUNT mykey
(integer) 8
127.0.0.1:6379>
PFMERGE
将多个 HyperLogLog 合并(merge)为一个 HyperLogLog , 合并后的 HyperLogLog 的基数接近于所有输入 HyperLogLog 的可见集合(observed set)的并集.
合并得出的 HyperLogLog 会被储存在目标变量(第一个参数)里面, 如果该键并不存在, 那么命令在执行之前, 会先为该键创建一个空的.
# 示例:
127.0.0.1:6379> PFADD mykey 1 2 3 4 5 6 7 8
(integer) 1
127.0.0.1:6379> PFCOUNT mykey
(integer) 8
127.0.0.1:6379> PFADD mykey2 9 7 5 3 1
(integer) 1
127.0.0.1:6379> PFMERGE mykey3 mykey mykey2 # 合并
OK
127.0.0.1:6379> keys *
1) "mykey"
2) "mykey3"
3) "mykey2"
127.0.0.1:6379> PFCOUNT mykey3
(integer) 9
3️⃣Bitmaps
Bitmaps 称为位图,它不是一种数据类型。网上很多视频教程把Bitmaps称为数据类型,应该是不正确的。Bitmaps 是Redis提供给使用者用于操作位的“数据类型”。
它主要有如下的基本特性:
- Bitmaps 不是数据类型,底层就是字符串(key-value),byte数组。我们可以使用普通的get/set直接获取和设值位图的内容,也可以通过Redis提供的位图操作getbit/setbit等将byte数组看成“位数组”来处理
- Bitmaps 的“位数组”每个单元格只能存储0和1,数组的下标在Bitmaps中称为偏移量
- Bitmaps设置时key不存在会自动生成一个新的字符串,如果设置的偏移量超出了现有内容的范围,就会自动将位数组进行零扩充
SETBIT
Setbit 命令用于对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
案例参考:
使用Bitmaps来存储用户是否打卡,打卡记做1,未打卡为0,时间 id 作为偏移量 (周一到周末)
假设一个用户,如下图,在1,3,4,7 打卡,其他日期未打卡(下标从 0 开始)
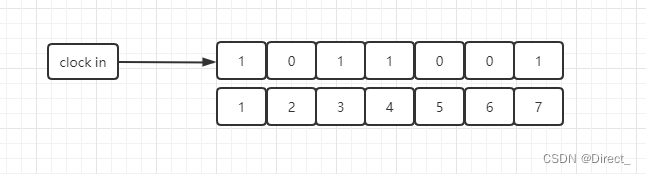
# 示例:记录 id 为 1001 的员工打卡情况
127.0.0.1:6379> SETBIT clock:1001 1 1
(integer) 0
127.0.0.1:6379> SETBIT clock:1001 2 0
(integer) 0
127.0.0.1:6379> SETBIT clock:1001 3 1
(integer) 0
127.0.0.1:6379> SETBIT clock:1001 4 1
(integer) 0
127.0.0.1:6379> SETBIT clock:1001 5 0
(integer) 0
127.0.0.1:6379> SETBIT clock:1001 6 0
(integer) 0
127.0.0.1:6379> SETBIT clock:1001 7 1
(integer) 0
127.0.0.1:6379> GETBIT clock:1001 3 # 使用 getbit 查看记录数据,查看某天的打卡记录
(integer) 1
127.0.0.1:6379> GETBIT clock:1001 6
(integer) 0
127.0.0.1:6379> BITCOUNT clock:1001 # 使用 BITCOUNT 统计打卡记录
(integer) 4
127.0.0.1:6379>
GETBIT
Getbit 命令用于对 key 所储存的字符串值,获取指定偏移量上的位(bit)
当偏移量 OFFSET 比字符串值的长度大,或者 key 不存在时,返回 0
# 示例:
127.0.0.1:6379> GETBIT clock:1001 3 # 使用 getbit 查看记录数据
(integer) 1
127.0.0.1:6379> GETBIT clock:1001 6
(integer) 0
BITCOUNT
BITCOUNT key [start end [BYTE|BIT]]计算给定字符串中,被设置为1的bit位的数量。start和end参数可以指定查询的范围,可以使用负数值。-1代表最后一个字节,-2代表倒是第二个字节。
注意:start和end是字节索引,因此每增加1 代表的是增加一个字符,也就是8位,所以位的查询范围必须是8的倍数。
# 示例:
127.0.0.1:6379> BITCOUNT clock:1001 # 使用 BITCOUNT 统计打卡记录
(integer) 4
127.0.0.1:6379>















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









