







点击下方标题,迅速定位到你感兴趣的内容
前言
Github:本文代码放在该项目中:NLP相关Paper笔记和代码复现
说明:讲解时会对相关文章资料进行思想、结构、优缺点,内容进行提炼和记录,相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
我们所熟知的encoder和decoder结构中,通常采用RNN结构如GRU或LSTM等,在encoder RNN中将输入语句信息总结到最后一个hidden vector中,并将其作为decoder的初始hidden vector,从而利用decoder的解码成对应的其他语言中的文字。但是这样的结构会出现一些问题,比如老生常谈的长程梯度消失的问题,对于较长的句子很难寄希望于将输入的序列转化为定长的向量而保存所有的有效的信息,所以随着输入序列的长度增加,这种结构的效果就会显著下降。因此这个时候就是Attention出场了,用一个浅显描述总结Attention就是,分配权重系数,保留序列的有效信息,而不是局限于原来模型中的定长隐藏向量,并且不会丧失长程的信息。
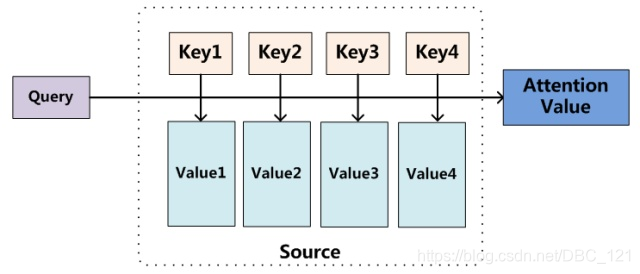
本篇文章主要是汇总我目前在对话和语音方面遇到的各类Attention,针对这些Attention进行理解阐述、总结、论文、代码复现。本文只对各Attention的关键处进行阐述,具体细节可查阅资料或阅读原论文了解。**本文所述的结构不是很多,主要是目前我再学习中遇到的比较重要的Attention(一些用的不多的在最后提了一下),后续还会持续更新。
Bahdanau Attention
Bahdanau Attention实现可以说是Attention的开创者之一,该实现的论文名叫“Neural Machine Translation by Learning to Jointly Align and Translate”,其中使用到了“Align”一次,意思是在训练模型的同时调整直接影响得分的权重,下面是论文中的结构图:

计算公式如下:
c
t
=
∑
j
=
1
T
x
a
t
j
h
j
c_t = \sum_{j=1}^{T_x}a_{tj}h_j
ct=j=1∑Txatjhj
a
t
j
=
e
x
p
(
e
t
j
)
∑
k
=
1
T
x
e
x
p
(
e
t
k
)
a_{tj}=\frac{exp(e_{tj})}{\sum_{k=1}^{T_x}exp(e_{tk})}
atj=∑k=1Txexp(etk)exp(etj)
e
t
j
=
V
a
T
t
a
n
h
(
W
a
[
s
t
−
1
;
h
j
]
)
e_{tj}=V_a^Ttanh(W_a[s_{t-1};h_j])
etj=VaTtanh(Wa[st−1;hj])
其中, c t c_t ct 是 t t t 时刻的语义向量, e i j e_ij eij 是encoder中 j j j 时刻Encoder隐藏层状态 h j h_j hj 对decoder中 t t t 时刻隐藏层状态 s t s_t st 的影响程度,然后通过softmax函数(第二个式子)将 e t j e_{tj} etj 概率归一化为 a t j a_{tj} atj
论文是使用Seq2seq结构对Attention进行阐述的,所以需要注意几点的是:
- 在模型结构的encoder中,是使用双向RNN处理序列的,并将方向RNN的最后一个隐藏层作为decoder的初始化隐藏层。
- attention层中的分数计算方式是使用 additive/concat
- 解码器的下一个时间步的输入是前一个解码器时间步生成的单词(或ground-truth)与当前时间步的上下文向量之间的concat。
下面附一张更清晰的结构图:

复现代码(以TensorFlow2为例),注意,将如下实现应用到实际模型中,需要根据具体模型微调:
def bahdanau_attention(hidden_dim: int, units: int):
"""
:param units: 全连接层单元数
"""
query = tf.keras.Input(shape=(hidden_dim))
values = tf.keras.Input(shape=(None, hidden_dim))
V = tf.keras.layers.Dense(1)
W1 = tf.keras.layers.Dense(units)
W2 = tf.keras.layers.Dense(units)
# query其实就是decoder的前一个状态,decoder的第一个状态就是上
# 面提到的encoder反向RNN的最后一层,它作为decoderRNN中的初始隐藏层状态
# values其实就是encoder每个时间步的隐藏层状态,所以下面需要将query扩展一个时间步维度进行之后的操作
hidden_with_time_axis = tf.expand_dims(query, 1)
score = V(tf.nn.tanh(W1(values) + W2(hidden_with_time_axis)))
attention_weights = tf.nn.softmax(score, axis=1)
context_vector = attention_weights * values
context_vector = tf.reduce_mean(context_vector, axis=1)
return tf.keras.Model(inputs=[query, values], outputs=[context_vector, attention_weights])
Luong Attention
论文名为“Effective Approaches to Attention-based Neural Machine Translation”,文章其实是基于Bahdanau Attention进行研究的,但在架构上更加简单。论文研究了两种简单有效的注意力机制:一种始终关注所有词的global方法和一种仅一次查看词子集的local方法。结构如下图:

计算公式如下:
a
t
(
s
)
=
a
l
i
g
n
(
h
t
,
h
ˉ
s
)
=
e
x
p
(
s
c
o
r
e
(
h
t
,
h
ˉ
s
)
)
∑
s
′
e
x
p
(
s
c
o
r
e
(
h
t
,
h
ˉ
s
′
)
)
a_t(s)=align(h_t,\bar{h}_s)=\frac{exp(score(h_t, \bar{h}_s))}{\sum_{s'}exp(score(h_t, \bar{h}_{s'}))}
at(s)=align(ht,hˉs)=∑s′exp(score(ht,hˉs′))exp(score(ht,hˉs))
s
c
o
r
e
(
h
t
,
h
ˉ
s
)
{
h
t
T
h
ˉ
s
d
o
t
h
t
T
W
a
h
ˉ
s
g
e
n
e
r
a
l
v
a
T
t
a
n
h
(
W
a
[
h
t
;
h
ˉ
s
]
)
c
o
n
c
a
t
score(h_t, \bar{h}_s)\left\{\begin{matrix} h_t^T\bar{h}_s & dot \\ h_t^TW_a\bar{h}_s &general \\ v_a^Ttanh(W_a[h_t;\bar{h}_s]) &concat \end{matrix}\right.
score(ht,hˉs)⎩⎨⎧htThˉshtTWahˉsvaTtanh(Wa[ht;hˉs])dotgeneralconcat
同样的,论文中也是使用Seq2Seq结构进行阐述,需要注意如下几点:
- 在encoder部分是使用两层堆叠的LSTM,decoder也是同样的结构,不过它使用encoder最后一个隐藏层作为初始化隐藏层。
- 用作Attention计算的隐藏层向量是使用堆叠的最后一个LSTM的隐层
- 论文中实验的注意力分数计算方式有:(1)additive/concat,(2)dot product,(3)location-based,(4)‘general’
- 当前时间步的解码器输出与当前时间步的上下文向量之间的concat喂给前馈神经网络,从而给出当前时间步的解码器的最终输出。
下面附一张更清晰的结构图:你会发现和Bahdanau Attention很像区别在于score计算方法和最后decoder中和context vector合并部分。

复现代码(以TensorFlow2为例),注意,将如下实现应用到实际模型中,需要根据具体模型微调:
def luong_attention_concat(hidden_dim: int, units: int) -> tf.keras.Model:
"""
:param units: 全连接层单元数
"""
query = tf.keras.Input(shape=(hidden_dim))
values = tf.keras.Input(shape=(None, hidden_dim))
W1 = tf.keras.layers.Dense(units)
V = tf.keras.layers.Dense(1)
# query其实就是decoder的前一个状态,decoder的第一个状态就是上
# 面提到的encoder反向RNN的最后一层,它作为decoderRNN中的初始隐藏层状态
# values其实就是encoder每个时间步的隐藏层状态,所以下面需要将query扩展一个时间步维度进行之后的操作
hidden_with_time_axis = tf.expand_dims(query, 1)
scores = V(tf.nn.tanh(W1(hidden_with_time_axis + values)))
attention_weights = tf.nn.softmax(scores, axis=1)
context_vector = tf.matmul(attention_weights, values)
context_vector = tf.reduce_mean(context_vector, axis=1)
return tf.keras.Model(inputs=[query, values], outputs=[attention_weights, context_vector])
def luong_attention_dot(query: tf.Tensor, value: tf.Tensor) -> tf.Tensor:
"""
:param query: decoder的前一个状态
:param value: encoder的output
"""
hidden_with_time_axis = tf.expand_dims(query, 1)
scores = tf.matmul(hidden_with_time_axis, value, transpose_b=True)
attention_weights = tf.nn.softmax(scores, axis=1)
context_vector = tf.matmul(attention_weights, value)
context_vector = tf.reduce_mean(context_vector, axis=1)
Self-Attention、Multi-Head Attention
Transformer用的就是Self-Attention、Multi-Head Attention。对于self-attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入,首先我们要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度
d
k
\sqrt{d_k}
dk ,其中
d
k
d_k
dk 为一个query和key向量的维度。再利用Softmax操作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表示。多头Attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention,两个的结构图如下:

计算公式如下:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
q
i
,
K
,
V
)
head_i=Attention(q_i,K,V)
headi=Attention(qi,K,V)
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
h
)
W
O
MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O
MultiHead(Q,K,V)=Concat(head1,...,headh)WO
复现代码(以TensorFlow2为例),注意,将如下实现应用到实际模型中,需要根据具体模型微调:
def scaled_dot_product_attention(query: tf.Tensor, key: tf.Tensor, value: tf.Tensor, mask: tf.Tensor=None):
"""
计算注意力权重。
q, k, v 必须具有匹配的前置维度。
k, v 必须有匹配的倒数第二个维度,例如:seq_len_k = seq_len_v。
虽然 mask 根据其类型(填充或前瞻)有不同的形状,
但是 mask 必须能进行广播转换以便求和。
参数:
q: 请求的形状 == (..., seq_len_q, depth)
k: 主键的形状 == (..., seq_len_k, depth)
v: 数值的形状 == (..., seq_len_v, depth_v)
mask: Float 张量,其形状能转换成
(..., seq_len_q, seq_len_k)。默认为None。
返回值:
输出,注意力权重
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# 缩放 matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# 将 mask 加入到缩放的张量上。
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# softmax 在最后一个轴(seq_len_k)上归一化,因此分数相加等于1。
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
Location Sensitive Attention
- Link
语音合成中的Tacotron2用的就是Location Sensitive Attention,即对位置敏感的Attention,也就是说加入了位置特征,是一种混合注意力机制(见最后一节说明)。原论文中提出,基于内容的Attention对于所输入内容的输入序列中的绝对位置能够跟踪捕获信息,但是在较长的语音片段中性能迅速下降,所以作者为了解决这个问题,通过将辅助的卷积特征作为输入添加到注意机制中来实现的,而这些卷积特征是通过将前一步的注意力权重进行卷积而提取的。结构图如下:

计算公式如下:
e
i
j
=
s
c
o
r
e
(
s
i
−
1
,
c
a
i
−
1
,
h
j
)
=
v
a
T
t
a
n
h
(
W
s
i
+
V
h
j
+
U
f
i
,
j
+
b
)
e_{ij}=score(s_{i-1},ca_{i-1}, h_j)=v_a^Ttanh(Ws_i+Vh_j+Uf_{i,j}+b)
eij=score(si−1,cai−1,hj)=vaTtanh(Wsi+Vhj+Ufi,j+b)
其中,
s
i
s_i
si 为当前解码器隐状态而非上一步解码器隐状态,偏置值
b
b
b 被初始化为
0
0
0。位置特征
f
i
f_i
fi 使用累加注意力权重
c
a
i
ca_i
cai 卷积而来:
f
i
=
F
∗
c
a
i
−
1
f_i=F*ca_{i-1}
fi=F∗cai−1
c
a
i
=
∑
j
=
1
i
−
1
a
j
ca_i=\sum_{j=1}^{i-1}a_j
cai=j=1∑i−1aj
复现代码(以TensorFlow2为例),注意,将如下实现应用到实际模型中,需要根据具体模型微调:
class Attention(tf.keras.layers.Layer):
def __init__(self, attention_dim, attention_filters, attention_kernel):
super(Attention, self).__init__()
self.attention_dim = attention_dim
self.attention_location_n_filters = attention_filters
self.attention_location_kernel_size = attention_kernel
self.query_layer = tf.keras.layers.Dense(
self.attention_dim, use_bias=False, activation="tanh")
self.memory_layer = tf.keras.layers.Dense(
self.attention_dim, use_bias=False, activation="tanh")
self.V = tf.keras.layers.Dense(1, use_bias=False)
self.location_layer = LocationLayer(self.attention_location_n_filters, self.attention_location_kernel_size,
self.attention_dim)
self.score_mask_value = -float("inf")
def get_alignment_energies(self, query, memory, attention_weights_cat):
processed_query = self.query_layer(tf.expand_dims(query, axis=1))
processed_memory = self.memory_layer(memory)
attention_weights_cat = tf.transpose(attention_weights_cat, (0, 2, 1))
processed_attention_weights = self.location_layer(
attention_weights_cat)
energies = tf.squeeze(self.V(tf.nn.tanh(
processed_query + processed_attention_weights + processed_memory)), -1)
return energies
def call(self, attention_hidden_state, memory, attention_weights_cat):
alignment = self.get_alignment_energies(
attention_hidden_state, memory, attention_weights_cat)
attention_weights = tf.nn.softmax(alignment, axis=1)
attention_context = tf.expand_dims(attention_weights, 1)
attention_context = tf.matmul(attention_context, memory)
attention_context = tf.squeeze(attention_context, axis=1)
return attention_context, attention_weights
Attention形式
关于Attention形式和获取信息方式的总结,可参考这篇文章:Attention用于NLP的一些小结。我接下来陈列出具体形式下的相关论文(这里的陈列的论文我并没有全部研读,单纯在这里汇总,往后有空或者需要用到对应Attention时,再仔细研读)。
Soft attention、global attention、动态attention
这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。
Hard attention
这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)
Local Attention(半软半硬attention)
这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
- A Context-aware Attention Network for Interactive Question Answering
- Dynamic Attention Deep Model for Article Recommendation by Learning Human Editors’ Demonstration
Concatenation-based Attention
- Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention
- Dipole: Diagnosis Prediction in Healthcare via A‚ention-based Bidirectional Recurrent Neural Networks
- Enhancing Recurrent Neural Networks with Positional Attention for Question Answering
- Learning to Generate Rock Descriptions from Multivariate Well Logs with Hierarchical Attention
- REASONING ABOUT ENTAILMENT WITH NEURAL ATTENTION
静态attention
对输出句子共用一个 s t s_t st 的attention就够了,一般用在Bilstm的首位hidden state输出拼接起来作为 s t s_t st
- Teaching Machines to Read and Comprehend
- Supervised Sequence Labelling with Recurrent Neural Networks
多层Attention
- A Context-aware Attention Network for Interactive Question Answering
- Learning to Generate Rock Descriptions from Multivariate Well Logs with Hierarchical Attention
- Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention
- Leveraging Contextual Sentence Relations for Extractive Summarization Using a Neural Attention Model
说在最后
Attention的提出到现在拥有很多的变种,但是经典的还是Bahdanau Attention和Luong Attention,很多Attention都是对这两个进行改进的。其实学习了Attention的伙伴会发现,对于Attention而言,重要的是Score计算方法,对于不同的计算方法在下面做个总结:
- 基于内容的注意力机制(content-based attention):
e i j = s c o r e ( s i − 1 , h j ) = v a T t a n h ( W a s i − 1 + U a h j ) e_{ij}=score(s_{i-1}, h_j)=v_a^Ttanh(W_as_{i-1}+U_ah_j) eij=score(si−1,hj)=vaTtanh(Wasi−1+Uahj)
其中, s i − 1 s_{i−1} si−1 为上一个时间步中解码器的输出(解码器隐状态,decoder hidden states), h j h_j hj 是编码器此刻输入(编码器隐状态,encoder hidden state j), v a v_a va、 W a W_a Wa 和 U a U_a Ua 是待训练参数张量。由于 U a h j U_ah_j Uahj 是独立于解码步i的,因此可以独立提前计算。基于内容的注意力机制能够将不同的输出与相应的输入元素连接,而与其位置无关。 - 基于位置的注意力机制(location-based attention):
e i j = s c o r e ( a i − 1 , h j ) = v a T t a n h ( W h j + U f i , j ) e_{ij}=score(a_{i-1}, h_j)=v_a^Ttanh(Wh_j+Uf_{i,j}) eij=score(ai−1,hj)=vaTtanh(Whj+Ufi,j)
其中, f i , j f_{i,j} fi,j 是之前的注意力权重, a i − 1 a_{i-1} ai−1 是经卷积而得的位置特征, f i = F ∗ α i − 1 f_i=F∗α_{i−1} fi=F∗αi−1, v a v_a va、 W a W_a Wa、 U a U_a Ua 和 F F F 是待训练参数。基于位置的注意力机制仅关心序列元素的位置和它们之间的距离。基于位置的注意力机制会忽略静音或减少它们,因为该注意力机制没有发现输入的内容。 - 混合注意力机制(hybrid attention):
e i j = s c o r e ( s i − 1 , a i − 1 , h j ) = v a T t a n h ( W s i − 1 + U h j + U f i , j ) e_{ij}=score(s_{i-1},a_{i-1}, h_j)=v_a^Ttanh(Ws_{i-1}+Uh_j+Uf_{i,j}) eij=score(si−1,ai−1,hj)=vaTtanh(Wsi−1+Uhj+Ufi,j)
顾名思义,混合注意力机制是上述两者注意力机制的结合。其中, s i − 1 s_{i-1} si−1 为之前的解码器隐状态, a i − 1 a_{i-1} ai−1 是之前的注意力权重, h j h_j hj 是第j个编码器隐状态。为其添加偏置值b,最终的score函数计算如下:
e i j = v a T t a n h ( W s i − 1 + V h j + U f i , j + b ) e_{ij}=v_a^Ttanh(Ws_{i-1}+Vh_j+Uf_{i,j}+b) eij=vaTtanh(Wsi−1+Vhj+Ufi,j+b)
其中, v a v_a va、 W W W、 V V V、 U U U 和 b b b 为待训练参数, s i − 1 s_{i−1} si−1 为上一个时间步中解码器隐状态, h j h_j hj 是当前编码器隐状态, f i , j f_{i,j} fi,j 是之前的注意力权重 a i − 1 a_{i-1} ai−1 经卷积而得的位置特征(location feature), f i = F ∗ α i − 1 f_i=F∗α_{i−1} fi=F∗αi−1。混合注意力机制能够同时考虑内容和输入元素的位置。
参考资料:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









