







硅基流动SiliconCloud(https://cloud.siliconflow.cn/)是一款集合顶尖大模型的一站式云服务平台,为开发者提供极速响应、价格亲民、品类齐全、体验丝滑的模型API服务。平台已上架数十种加速版大语言模型、向量&重排序模型、图片/视频生成大模型(包括20+免费模型),免去开发者模型部署门槛,自由切换适合不同应用场景的模型,高效提升用户体验。
目前,用户可在Dify、Cursor、ChatBox、Obsidian Copilot、Cherry Studio、沉浸式翻译等应用接入SiliconCloud的各类大模型。
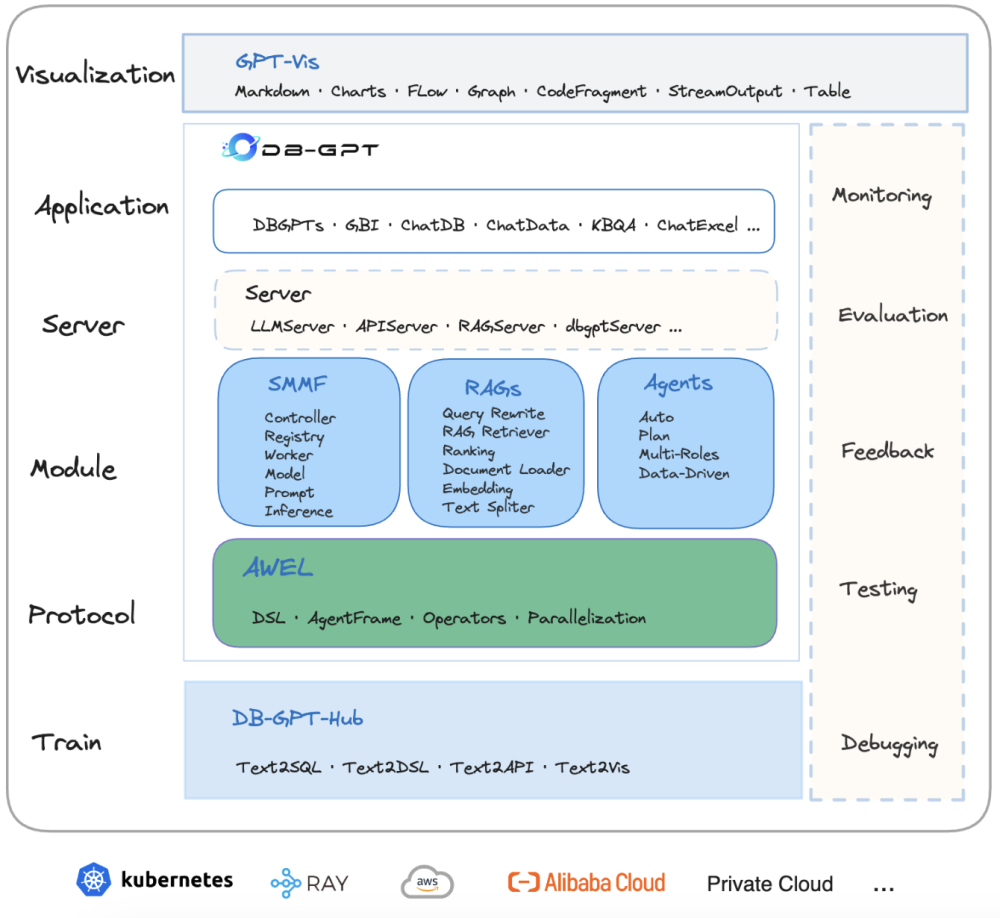
作为一款去年刚上线的开源“新秀”, AI原生数据应用开发框架DB-GPT(https://github.com/eosphoros-ai/DB-GPT)在不到一年的时间内快速成长,在Github上收获了超过 14k star的关注。DB-GPT通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
DB-GPT围绕大模型提供了灵活、可扩展的AI原生数据应用管理与开发能力,帮助用户快速构建、部署智能AI数据应用,通过智能数据分析、洞察、决策, 实现企业数字化转型与业务增长。目前有超过106万用户学习和使用DB-GPT,其中100+家企业已将其集成到生产系统中,应用场景覆盖了金融、政务、互联网等多个行业。
本文将分享如何通过DB-GPT使用SiliconCloud的模型,让用户体验到强大的多模型管理能力,灵活、可扩展的AI应用管理开发能力,以及在AI应用开发过程中提供全流程的更极致的用户体验。
1. 获取 API Key
1.进入 SiliconCloud 官网(https://cloud.siliconflow.cn/)并注册/登录账号即可。
2.登录后,点击左边栏的“API密钥” ,创建 API Key,点击密钥进行复制,以备后续使用。
2. 部署 DB-GPT
1.克隆 DB-GPT 源码
git clone https://github.com/eosphoros-ai/DB-GPT.git
2.创建虚拟环境并安装依赖
# cd 到 DB-GPT 源码根目录
cd DB-GPT
# DB-GPT 要求python >= 3.10
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env
# 这里选择代理模型类依赖安装
pip install -e ".[proxy]"
3.配置基础的环境变量
# 复制模板 env 文件为 .env
cp .env.template .env
4.修环境变量文件.env,配置 SiliconCloud 模型
# 使用 SiliconCloud 的代理模型
LLM_MODEL=siliconflow_proxyllm
# 配置具体使用的模型名称
SILICONFLOW_MODEL_VERSION=Qwen/Qwen2.5-Coder-32B-Instruct
SILICONFLOW_API_BASE=https://api.siliconflow.cn/v1
# 记得填写您在步骤2中获取的 API Key
SILICONFLOW_API_KEY={your-siliconflow-api-key}
# 配置使用 SiliconCloud 的 Embedding 模型
EMBEDDING_MODEL=proxy_http_openapi
PROXY_HTTP_OPENAPI_PROXY_SERVER_URL=https://api.siliconflow.cn/v1/embeddings
# 记得填写您在步骤2中获取的 API Key
PROXY_HTTP_OPENAPI_PROXY_API_KEY={your-siliconflow-api-key}
# 配置具体的 Embedding 模型名称
PROXY_HTTP_OPENAPI_PROXY_BACKEND=BAAI/bge-large-zh-v1.5
# 配置使用 SiliconCloud 的 rerank 模型
RERANK_MODEL=rerank_proxy_siliconflow
RERANK_PROXY_SILICONFLOW_PROXY_SERVER_URL=https://api.siliconflow.cn/v1/rerank
# 记得填写您在步骤2中获取的 API Key
RERANK_PROXY_SILICONFLOW_PROXY_API_KEY={your-siliconflow-api-key}
# 配置具体的 rerank 模型名称
RERANK_PROXY_SILICONFLOW_PROXY_BACKEND=BAAI/bge-reranker-v2-m3
注意:上述的 SILICONFLOW_API_KEY、PROXY_HTTP_OPENAPI_PROXY_SERVER_URL 和RERANK_PROXY_SILICONFLOW_PROXY_API_KEY环境变量是您在步骤 2 中获取的 SiliconCloud 的 API Key。语言模型(SILICONFLOW_MODEL_VERSION)、 Embedding 模型(PROXY_HTTP_OPENAPI_PROXY_BACKEND)和 rerank 模型(RERANK_PROXY_SILICONFLOW_PROXY_BACKEND) 可以从 获取用户模型列表 - SiliconFlow(https://docs.siliconflow.cn/api-reference/models/get-model-list)中获取。
5.启动 DB-GPT 服务
dbgpt start webserver --port5670
在浏览器打开地址 http://127.0.0.1:5670/ 即可访问部署好的 DB-GPT。
3. 开始使用
通过 DB-GPT Python SDK 使用 SiliconCloud 的模型。
1.安装 DB-GPT Python 包
pip install"dbgpt>=0.6.3rc2" openai requests numpy
为了后续验证,额外安装相关依赖包。
2.使用 SiliconCloud 的大语言模型
import asyncio
import os
from dbgpt.core import ModelRequest
from dbgpt.model.proxy import SiliconFlowLLMClient
model = "Qwen/Qwen2.5-Coder-32B-Instruct"
client = SiliconFlowLLMClient(
api_key=os.getenv("SILICONFLOW_API_KEY"),
model_alias=model
)
res = asyncio.run(
client.generate(
ModelRequest(
model=model,
messages=[
{"role": "system", "content": "你是一个乐于助人的 AI 助手。"},
{"role": "human", "content": "你好"},
]
)
)
)
print(res)
3.使用 SiliconCloud 的 Embedding 模型
import os
from dbgpt.rag.embedding import OpenAPIEmbeddings
openai_embeddings = OpenAPIEmbeddings(
api_url="https://api.siliconflow.cn/v1/embeddings",
api_key=os.getenv("SILICONFLOW_API_KEY"),
model_name="BAAI/bge-large-zh-v1.5",
)
texts = ["Hello, world!", "How are you?"]
res = openai_embeddings.embed_documents(texts)
print(res)
4.使用 SiliconCloud 的 Rerank 模型
import os
from dbgpt.rag.embedding import SiliconFlowRerankEmbeddings
embedding = SiliconFlowRerankEmbeddings(
api_key=os.getenv("SILICONFLOW_API_KEY"),
model_name="BAAI/bge-reranker-v2-m3",
)
res = embedding.predict("Apple", candidates=["苹果", "香蕉", "水果", "蔬菜"])
print(res)
4. 上手指南
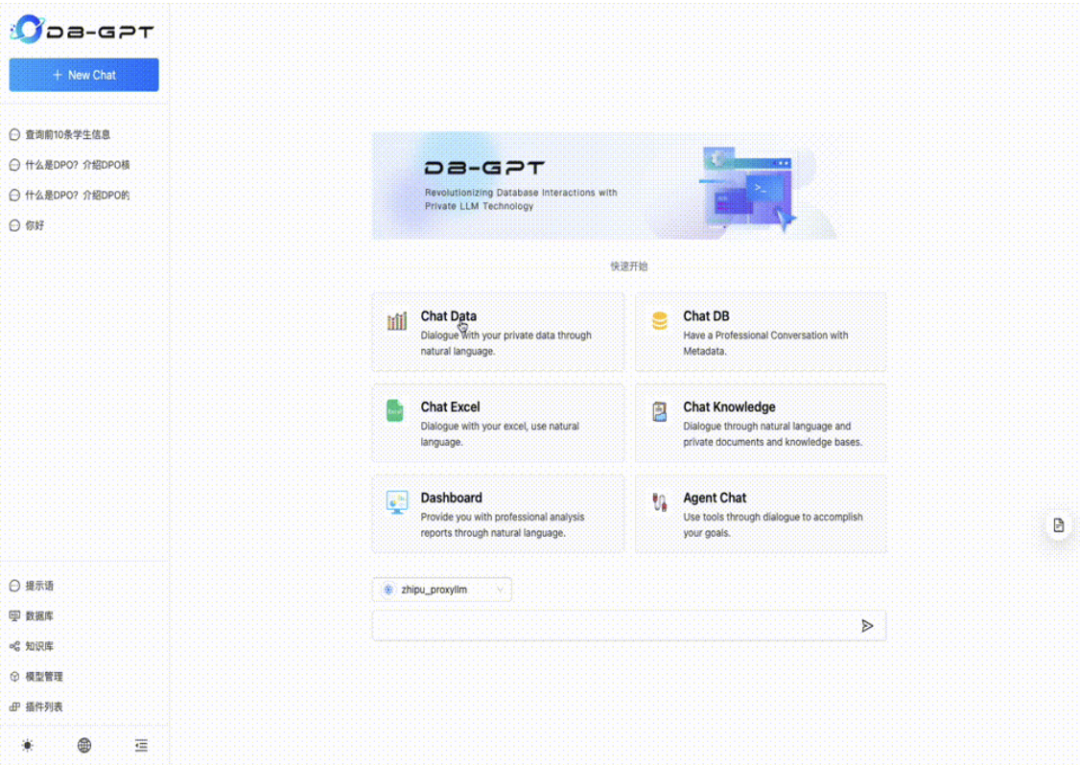
以数据对话案例为例,数据对话能力是通过自然语言与数据进行对话,目前主要是结构化与半结构化数据的对话,可以辅助做数据分析与洞察。以下为具体操作流程:
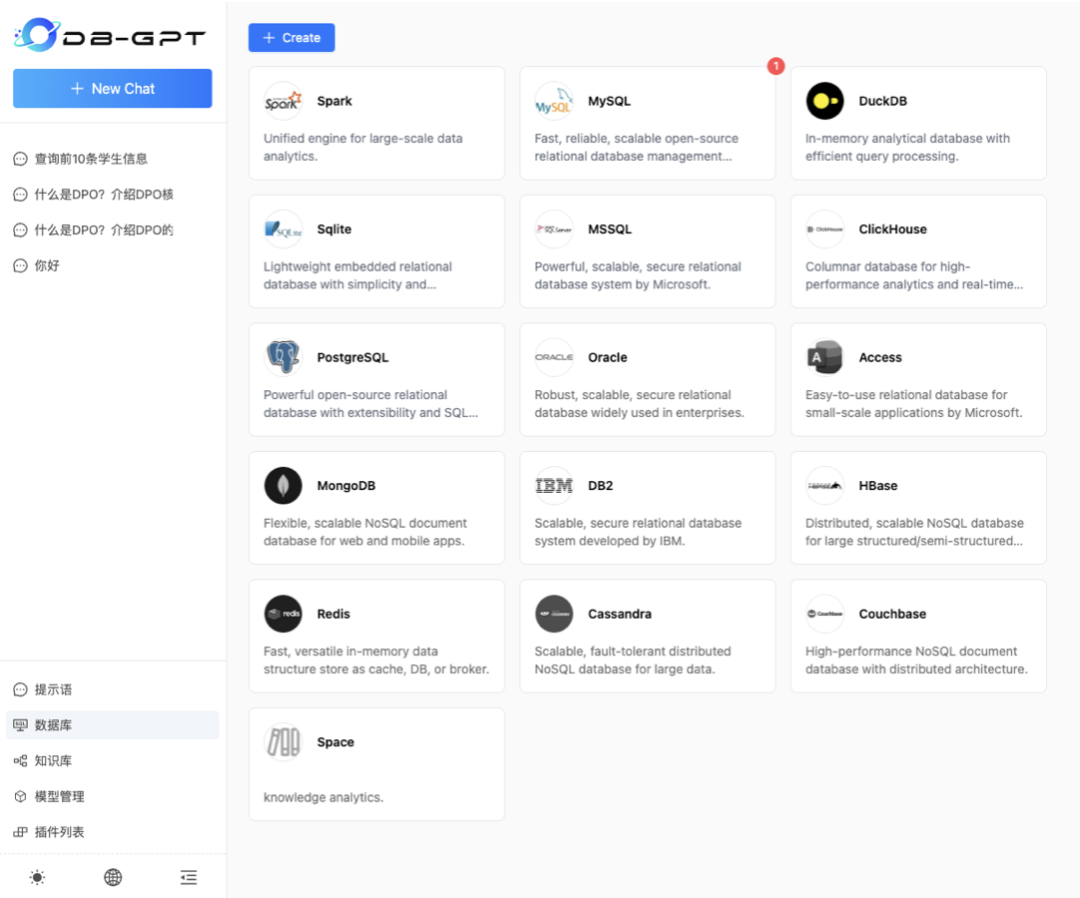
1. 添加数据源
首先选择左侧数据源添加,添加数据库,目前DB-GPT支持多种数据库类型。选择对应的数据库类型添加即可。这里我们选择的是MySQL作为演示,演示的测试数据参见测试样例(https://github.com/eosphoros-ai/DB-GPT/tree/main/docker/examples/sqls)。
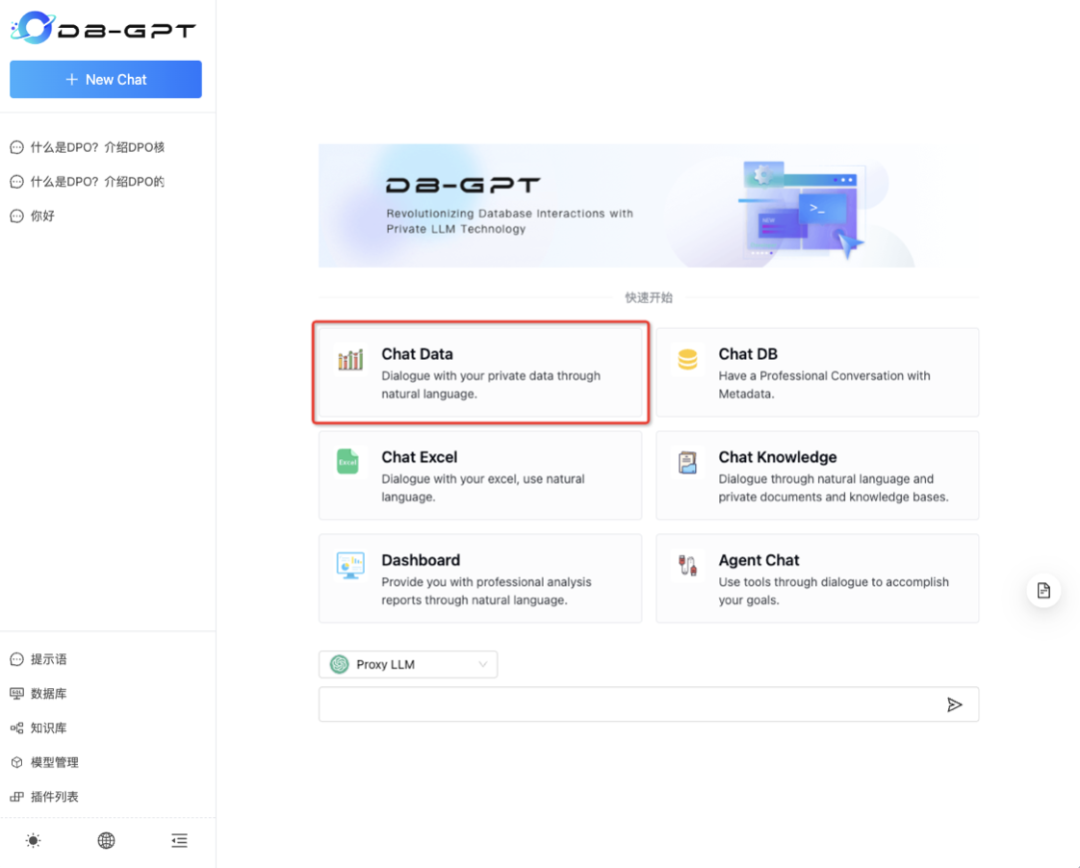
2. 选择对话类型
选择ChatData对话类型。
3. 开始数据对话
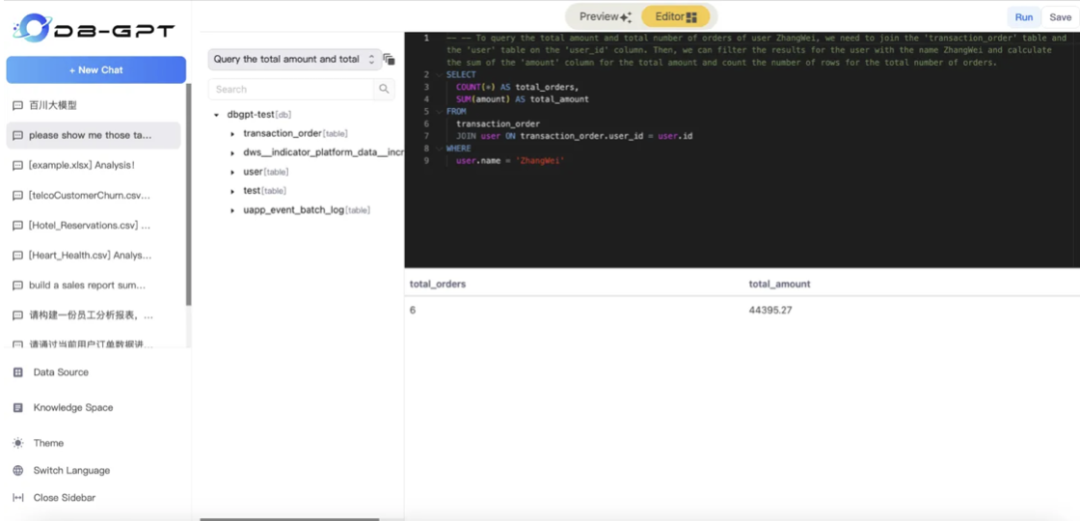
注意:在对话时,选择对应的模型与数据库。同时DB-GPT也提供了预览模式与编辑模式。
编辑模式:

















 3395
3395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









