






蚂蚁 AI Infra 团队在深度学习最核心之一的训练框架方向上持续投入与创新,实现了提升资源利用率、加速训练、提升训练稳定性等目标。我们提出的 EDiT 方法,即为其中一项工作。
目前的分布式训练方法面临通信瓶颈、慢节点和缺乏弹性等问题。虽然研究者针对性地提出了 Local SGD 方法,但受限于额外的内存开销以及缺乏对效率和稳定性的考虑,其仅在小规模模型的训练中有效。因此,我们提出了 EDiT (Efficient Distributed Training) 方法,将 Local SGD 方法与模型划分技术结合以提高大模型训练效率。EDiT 引入了层级同步策略、虚拟梯度惩罚策略和时间间隔同步策略,进一步提升了大模型训练速度、稳定性与模型效果。通过在公开数据集上的实验,我们证明了 EDiT 方法比其他 Local SGD 方法以及同步方法有更快的训练速度与更好的模型效果。EDiT 在蚂蚁内部的大模型训练场景中也被采用并取得了显著效果。相关论文已被 ICLR '25 接收。
ArXiv 论文《EDiT: A Local-SGD-Based Efficient Distributed Training Method for Large Language Models》:https://arxiv.org/abs/2412.07210
代码集成到蚂蚁开源项目 Atorch:https://github.com/intelligent-machine-learning/atorch/tree/main/atorch/local_sgd
背景介绍
随着模型规模和数据量的爆炸性增长,分布式方法在训练深度神经网络时变得越来越重要。然而,现有的方法依赖于同步模式,因此会在训练过程中引入了显著的通信开销。此外,同步模式还带来了慢节点问题,即较快的工作节点会空闲等待较慢的工作节点。这个问题在大规模集群或异构集群中尤为普遍。最后,我们希望可以在资源受限的集群中进行弹性训练。然而,同步训练模式下机器的增减涉及到模型、数据和超参的调整,会显著影响训练效果。
一种解决上述问题的典型方法是 Local Stochastic Gradient Descent (Local SGD),该方法又被称作 Local-Update SGD、Parallel SGD 或 Federated Averaging 等,其中每个节点独立并行执行多次本地更新步骤,然后所有节点之间再对参数进行平均以恢复同步状态。后续的研究改进了这一基础范式,如在模型同步时引入外部优化器以提升训练效果。如图 1 所示,Local SGD 系列方法可以减少通信频率和随机慢节点的影响以提高整体训练速度。
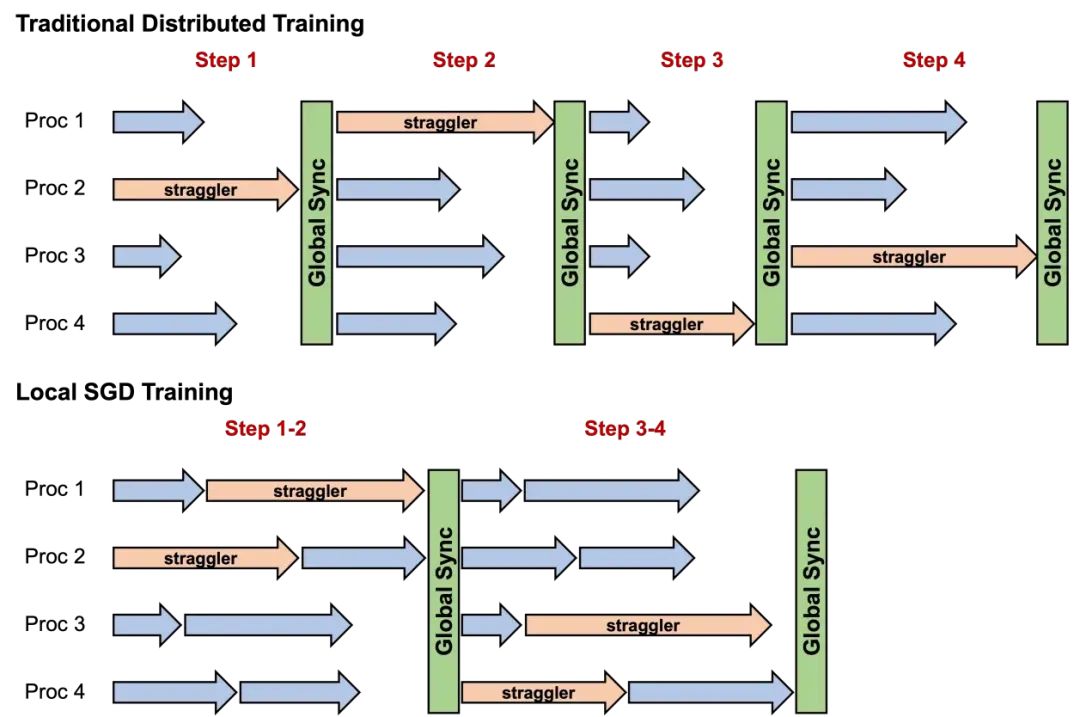
图1 Local SGD 方法和传统分布式训练方法的对比示意图
然而,现有的 Local SGD 方法并不适用于大语言模型 (LLM) 的训练。首先,这些方法不能很好地处理模型分片问题,这限制了它们在参数规模超过数十亿的模型上的应用。其次,这些方法主要应用在小规模、高质量的数据集上,而 LLM 的训练通常会用到超大规模的、包含低质语料的数据集,而这种数据集通常会造成训练的不稳定。此外,当前的方法虽然可以解决随机慢节点的问题,但无法解决固定慢节点的问题。同时,当前的方法在参数同步时会引入不可重叠的通信开销。最后,当前的方法采用一致的平均策略同步参数,没有充分利用不同 worker 间的模型差异。
因此,我们基于 Local SGD 策略与模型划分技术,提出了 EDiT (Efficient Distributed Training) 方法,以提升大模型训练的效率。EDiT 引入层级同步策略,减少了通信和内存开销,并实现了模型同步和计算的重叠。此外,EDiT 采用了一种新的虚拟梯度惩罚策略,解决了大规模语料库引入的训练不稳定问题,并利用了节点间的差异性来提高模型效果。同时,EDiT 还通过引入时间间隔同步策略,实现了完全异步的训练方法,解决了固定慢节点的问题。我们的主要贡献总结如下:
-
工程创新:我们引入了 EDiT 方法,结合了 Local SGD 策略和模型划分技术以提升模型训练速度。
-
算法创新:我们提出了层级同步策略、虚拟梯度惩罚策略和时间间隔同步策略,进一步提升了模型训练速度,提高了训练的稳定性和模型性能,减少了额外的内存开销。
-
应用贡献:我们对异步训练 LLM 进行了大规模的验证,针对其收敛性、泛化性、速度、弹性和稳定性等方面进行了全面分析。
方法介绍
EDiT方法总览
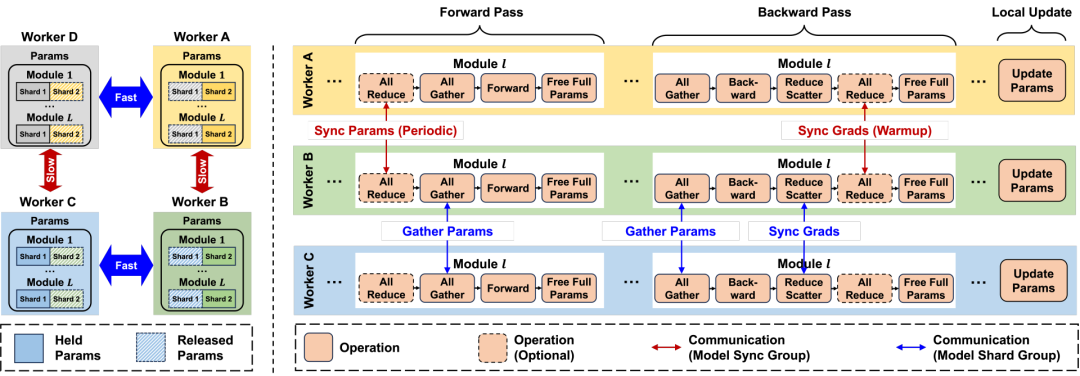
图2 EDiT 方法流程示意图

算法 1 EDiT 算法图
EDiT 方法细节见图 2 和算法 1 。EDiT 采用了二维设备网格结构,即将 个节点分为
个模型同步组和
个模型划分组,
。通常来说,我们会将所有机内 GPU 连接作为模型划分组,而将所有机间具有相同序号的 GPU 连接作为模型同步组。模型参数在每个模型划分组中均匀分割,而每个模型同步组中的所有节点维护相同部分的参数。这样,通过将通信密集的操作聚集到模型划分组中,再使用阶段同步策略来减缓模型同步组中的通信开销,就可以实现训练加速。EDiT在训练开始时会进行预热,即采用标准的分布式训练,以确保初始阶段的训练稳定性。EDiT的具体流程如下:
1. 第 个模块在第个模块的前向阶段,如果当前步数需要模型同步,则会对模型同步组中的参数进行同步。在实践中,模型同步间隔会设置很大,因此同步的通信开销很小。这里在同步时我们引入了一种新的虚拟梯度惩罚策略以增强稳定性,我们会在下文进行详细介绍。在此之后,每个节点通过它所在的模型划分组聚合完整的模块参数进行前向计算,并在此之后释放掉多余参数以节约显存。
2. 在第 个模块的反向阶段,节点再次通过模型划分组聚合参数以进行梯度计算,之后在模型划分组中平均梯度。如果当前处在预热阶段,则会在每个模型同步组中做一次额外的通信操作以平均梯度,否则该操作会被跳过以减少通信。在此之后,每个节点再次释放掉多余的参数。
3. 当所有的模块都完成一次前向-反向的迭代,就会使用内部优化器更新每个节点的局部参数。
与其他 Local SGD 方法的参数同步不同,EDiT 会在前向计算时逐层对参数进行同步,减小了额外的显存和通信开销。当使用预取 (prefetch) 策略时,模型同步组中的通信可以有效地与前向计算重叠,从而进一步减少了由参数同步引入的通信开销。
此外,EDiT与大多数现有的大规模分布式训练框架兼容。在我们的代码实现中,我们同时支持了其与FSDP和Megatron的集成。
虚拟梯度惩罚策略
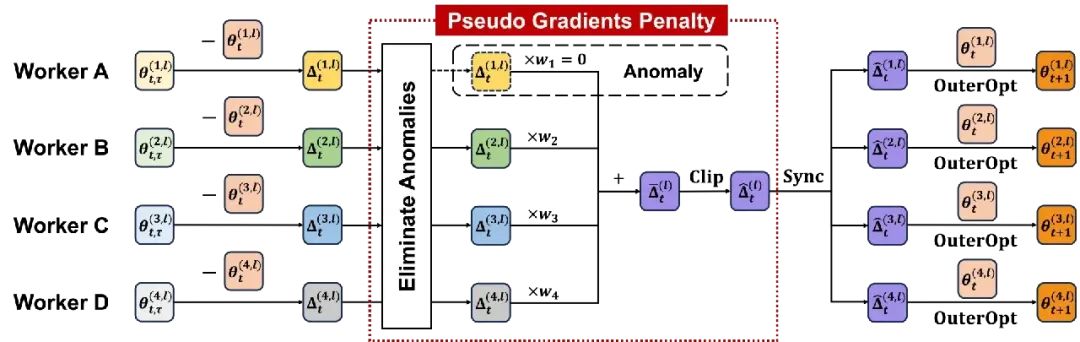
图 3 虚拟梯度惩罚策略示意图

算法 2 参数同步算法
为了解决 Local SGD 模式训练的不稳定性与模型效果下降等问题,我们在参数同步阶段引入了一种虚拟梯度惩罚策略。如图 3 和算法 2 所示。该策略包含异常点剔除、加权平均和梯度裁剪三个步骤:
-
异常点剔除。我们首先去除掉有显著异常的节点以减少其对模型效果的影响。这里我们使用虚拟梯度范数作为衡量指标,并使用 z-test 进行统计分析,去除掉超过阈值的节点。在训练过程中,我们会对虚拟梯度范数的平均值和标准差使用指数滑动平均进行更新,并且在训练开始时设置一个预热过程。如果所有节点都被判定为异常节点,则所有参数会被回滚至上一次同步的参数。
-
加权平均。我们进一步基于虚拟梯度范数对每个非异常的节点的虚拟梯度进行加权平均,以使得所有节点对于参数更新方向有相同的贡献。
-
梯度裁剪。最后,我们使用梯度裁剪限制更新的步长,进一步增强训练的稳定性。
在 EDiT 中,每个节点上的额外参数和外部动量会按照参数划分的方式进行划分。与之前在每个节点上维护完整额外参数和外部动量的 Local SGD 方法相比,EDiT 减少了额外的内存使用。此外,基于逐层同步和预取策略,EDiT 可以进一步将额外参数和外部动量卸载到 CPU ,并仅在需要时将对应层的数据传输到 GPU,从而进一步减少内存开销。由于每层的数据量相对较小,GPU 与 CPU 之间的数据传输可以有效地与 GPU 计算和 GPU 间通信重叠,确保快速的参数同步。
完全异步的EDiT方法
EDiT要求每过固定次数的局部迭代之后做一次全局同步。然而,同步时最快的节点依然需要等待其他未完成的节点,造成资源浪费。这种现象在异构集群中尤为突出。
直觉上,如果能让每个节点按照自己的速度进行训练,移除固定步数同步的限制,可以使训练效率更高。因此,我们提出了一种完全异步的 EDiT 方法,称作 A-EDiT。二者区别如图4所示。
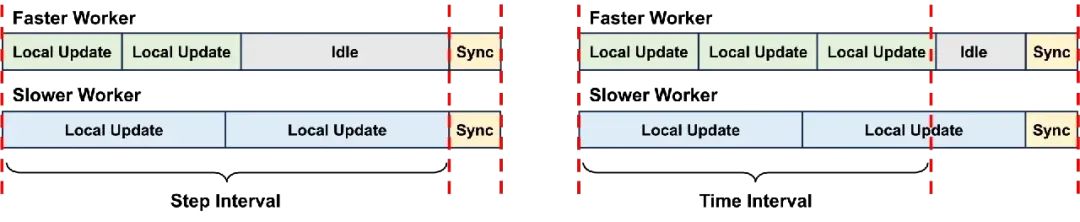
图 4 EDiT 和 A-EDiT 的区别示意图
这里我们使用固定的时间间隔,并令每个节点的本地更新时间超过这个时间阈值之后再进行同步。这一修改确保了更快的节点可以在两次同步之间进行更多次的迭代。理论上,每个 worker 同步时的等待时间不会超过最慢节点的单步时间。
实验
实验设置
模型:我们在 4 种不同规模的 Llama 模型上进行了实验,包括 350M、1B、3B 和 7B 模型。
-
数据集:我们在开源数据集 FineWeb-Edu Dataset 和蚂蚁内部闭源数据集 In-House Dataset(代称)上进行了实验。
-
对比方法:我们和标准的分布式方法(Baseline)、Post Local SGD(PLS)、DiLoCo 和 CO2/CO2* 进行了对比,其中 CO2* 是 CO2 的显存节约版本,即对额外参数和外部动量进行了划分。
收敛性实验
图 5 报告了使用不同训练方法在两个数据集上训练 Llama-1B 模型的训练 loss(越低越好)和验证 PPL(越低越好)。可以看到 EDiT 取得了最优的训练 loss,并且在 FineWeb-Edu 数据集上取得了最优的验证 PPL,甚至超过了同步的 Baseline 方法。A-EDiT 效果略差于 EDiT,但是同样超过了大多数对比方法。表 1 展示了在通用 LLM Benchmark 上测试不同方法训练模型的结果。可以看到 EDiT 均取得了最优的结果,而 A-EDiT 也超过了大多数其他的对比方法。上述实验结果证明了 EDiT/A-EDiT 的收敛性和泛化性。
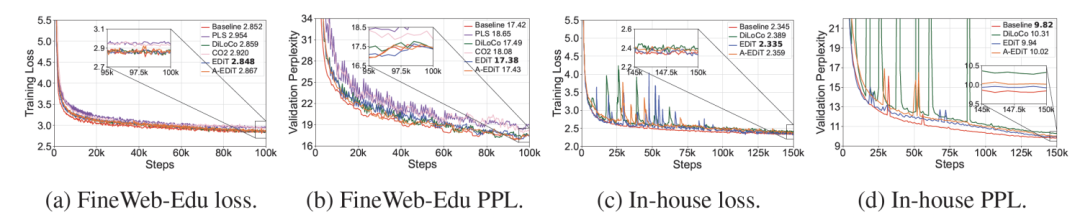
图 5 不同训练方法的训练 loss 曲线和验证 PPL 曲线
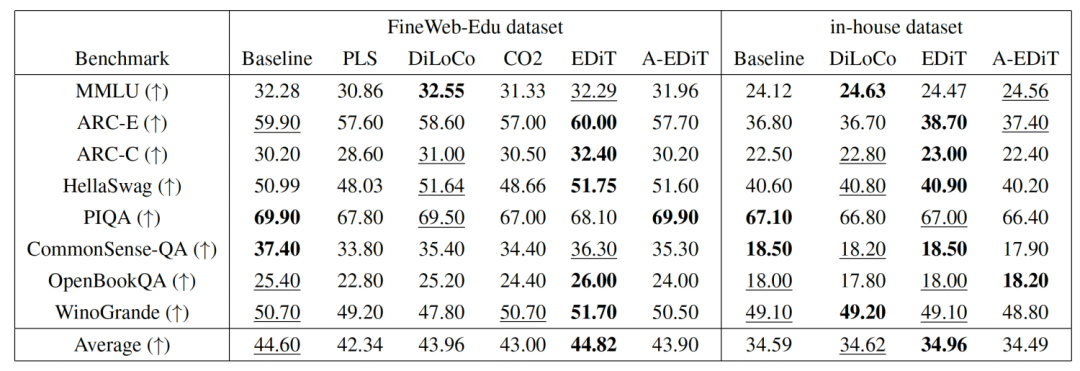
表 1 不同训练方法的测试结果
加速实验
表 2 展示了不同方法在 2 机 16 卡的环境中训练不同规模 Llama 模型的速度。表中数据分别对应平均的吞吐(Tokens/Sec)和 TFLOPS。之前的 Local SGD 系列方法需要维护完整的额外参数和外部动量,因此在较大规模的模型上会显存溢出。EDiT 和 A-EDiT 取得了和之前最快方法 CO2 接近的训练速度,同时在较大规模的模型上也避免了显存溢出的问题。图 6 展示了在更具挑战的训练场景中 EDiT/A-EDiT 相比于 Baseline 的训练速度。可以看到随着延迟程度变大,Baseline 的训练速度会明显下降。相比之下,EDiT 和 A-EDiT 在随机慢节点和通信带宽受限的场景下都表现良好,其中 A-EDiT 还进一步解决了固定慢节点的问题。

表 2 不同训练方法的速度对比
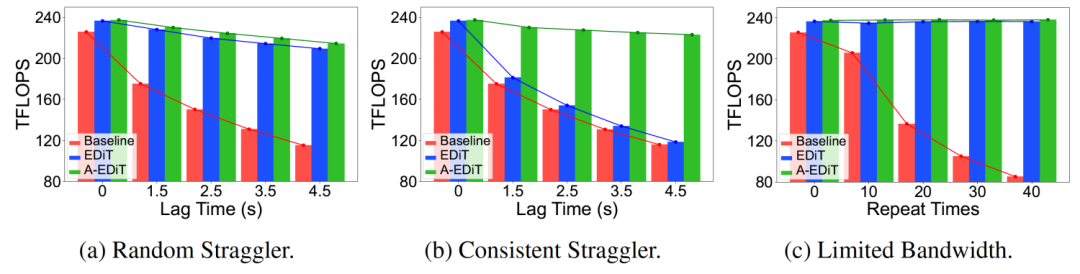
图 6 EDiT 和 A-EDiT 方法的加速表现
弹性训练实验
这里我们探究 Local SGD 的阶段同步策略是否可以使得最优学习率仅和每个节点的 batchsize 相关,从而解决弹性训练的超参问题。从图 7 (a) 和图 7 (b) 中可以看到,随着节点数的增加,Baseline 的最优学习率会跟着变化,而 EDiT 的最优学习率保持不变。我们进一步模拟了正式的弹性训练场景,在训练过程中增加/减少节点数。从图 7 (c) 中可以看到,在两种场景中 EDiT 最终收敛的 PPL 相比于 Baseline 分别降低了 4.5% 和 2.6%。实验结果证明了 EDiT 更适用于弹性训练的场景。
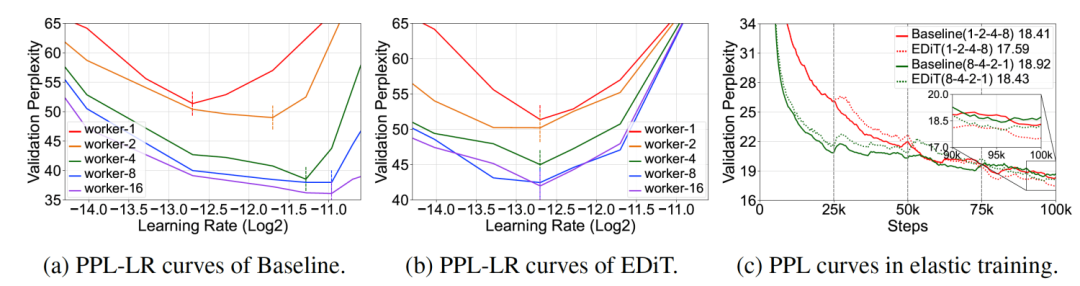
图 7 EDiT 的弹性训练实验结果
消融实验
我们分析了 EDiT 虚拟梯度惩罚策略中三种方法是否均对提升稳定性和模型效果有效。从图 8 (a) 中可以看到,去除整个虚拟梯度惩罚策略或其中的每一项方法,都会影响训练的稳定性和最终的 PPL。我们进一步分析了 8 个不同节点上的训练曲线。从图 8 (b) 和图 8 (c) 中可以看到,当 DiLoCo 遇到异常时,需要较长时间恢复;而 EDiT 中即使有一个异常节点,其他节点也可以正常训练,并且在所有节点遇到异常时可以通过回滚快速恢复正常 loss。
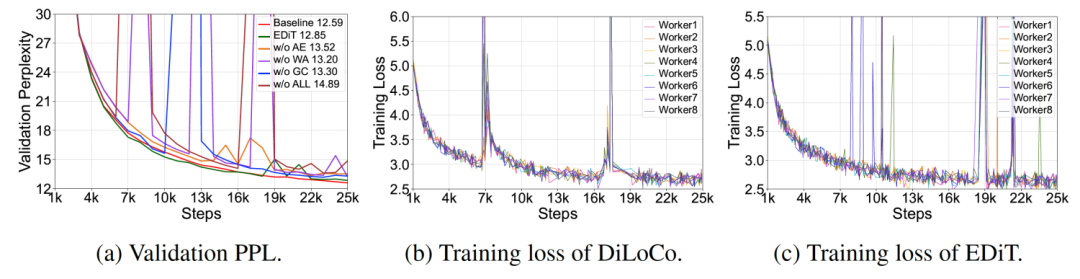
图 8 EDiT 的消融实验结果
总结与展望
我们分析了在大规模集群中使用现有分布式训练方法训练 LLM 时存在的问题,并进一步分析了现有解决方案——Local SGD 方法存在的问题。在此基础上,我们提出了一种叫做 EDiT 的针对 LLM 的新颖的高效分布式训练方法。EDiT 有效地将模型划分策略和 Local SGD 机制相结合,并通过引入层级同步策略、虚拟梯度惩罚策略和时间间隔同步策略提升了模型的训练速度、稳定性和模型效果。实验结果和蚂蚁内部业务场景都证明了 EDiT 的有效性。
目前还有一些遗留的问题,可以作为后续的研究方向:
1.A-EDiT 方法中较慢的节点更新次数较少,在同步时会影响整体模型效果。因此,需要探究如何减弱慢节点对整体性能的影响。
2.我们在模拟弹性训练时需要在增减节点时暂停并重启训练过程。我们希望能够开发一种真正的弹性训练框架,可以在不影响当前训练流程的情况下快速地调整计算资源。
参考文献
[1] Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, et al. Zero: Memory optimizations toward training trillion parameter models.
[2] Deepak Narayanan, Mohammad Shoeybi, Jared Casper, et al. Efficient large-scale language model training on gpu clusters using megatron-lm.
[3] Jian Zhang, Christopher De Sa, Ioannis Mitliagkas, et al. Parallel sgd: When does averaging help?
[4] Jianyu Wang, Vinayak Tantia, Nicolas Ballas, et al. Slowmo: Improving communication-efficient distributed sgd with slow momentum.
[5] Arthur Douillard, Qixuan Feng, Andrei A Rusu, et al. Diloco: Distributed lowcommunication training of language models.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









