







PyTorch 4.DataLoader与Dataset
torch.utils.data.DataLoader
DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None
)
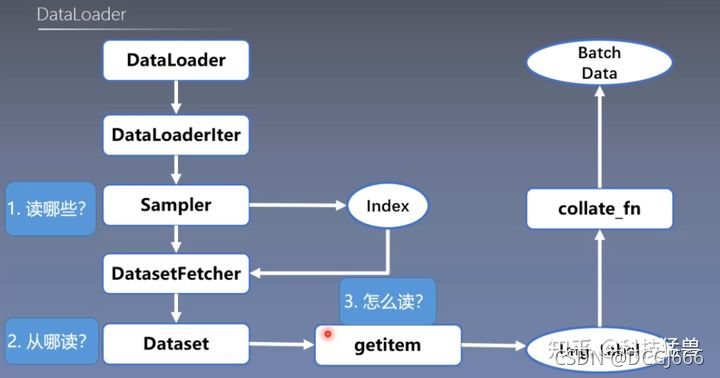
功能:构建可迭代的数据装载器
dataset:Dataset类,决定数据从哪读取几如何读取
batchsize:批大小
num_works:是否多进程读取数据
shuffle:每个epoch是否乱序
drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
- 读哪些数据?->Sampler输出的index
- 从哪读数据?->Dataset中的data_dir
- 怎么读数据? ->Dataset中的getitem
torch.utils.data.Dataset
功能:Dataset抽象类,所有自定义的Dataset需要继承它,并且复写__getitem__()
getitem:接收一个索引,返回一个样本
Dataset的目标是根据输入的索引输出对应的image和label,而且这个功能是要在__getitem__()函数中完成的,所以当自定义数据集时,首先要继承Dataset类,还要复写__getitem__()函数
例子:
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader
class My_dataset(Dataset):
def __init__(self):
super().__init__()
# 使用sin函数返回10000个时间序列,如果不自己构造数据,就使用numpy,pandas等读取自己的数据为x即可。
# 以下数据组织这块即可以放在init方法,也可以放在getitem方法里
self.x = torch.randn(1000,3)
self.y = self.x.sum(axis=1)
self.src, self.trg = [], []
for i in range(1000):
self.src.append(self.x[i])
self.trg.append(self.y[i])
def __getitem__(self,index):
return self.src[index], self.trg[index]
def __len__(self):
return len(self.src)
DataLoader源码解析
在自定义Dataset时,通过继承torch.utils.data.Dataset, 在继承的时候,需要override三个方法。
- init: 用来初始化数据集
- getitem:
- len
那么DataLoader是使用__getitem__和__len__的呢:
DataLoader源码
class DataLoader(object):
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None,
num_workers=0, collate_fn=default_collate, pin_memory=False,
drop_last=False):
self.dataset = dataset
self.batch_size = batch_size
self.num_workers = num_workers
self.collate_fn = collate_fn
self.pin_memory = pin_memory
self.drop_last = drop_last
if batch_sampler is not None:
# batch采样与batch_size互斥
if batch_size > 1 or shuffle or sampler is not None or drop_last:
raise ValueError('batch_sampler is mutually exclusive with '
'batch_size, shuffle, sampler, and drop_last')
if sampler is not None and shuffle:
# 采样器与shuffle互斥
raise ValueError('sampler is mutally exclusive with shuffle')
if batch_sampler is None:
if sampelr is None:
if shuffle:
# dataset.__len__()在Sampler中被使用
# 目的是生成一个长度为len(dataset)的序列索引(随机的)
sampler = RandomSampler(dataset)
else:
sampler = SequentialSampler(dataset)
# Sampler是一个迭代器,一次只返回一个索引
# BatchSampler也是个迭代器,但是一次返回batch_size个索引
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
self.sampler = sampler
self.batch_sampler = batch_sampler
def __iter__(self):
return DataLoaderIter(self)
def __len__(self):
return len(self.batch_sampler)
# 以下两个代码等价
for data in dataloader:
...
# 等价于
iterr = iter(dataloader)
while True:
try:
next(iterr)
except StopIteration:
break
在DataLoader中,iter(dataloader)返回的是一个DataLoaderIter对象,这才是一直next的对象
RandomSampler, SequentialSampler, BatchSampler
首先,是RandomSampler, iter(randomSampler)会返回一个可迭代对象,这个可迭代对象每次next都会输出当前要采样的index, SequentialSampler也是一样,只不过它产生的index是顺序的:
class RandomSampler(Sampler):
def __init__(self, data_source):
self.data_source = data_source
def __iter__(self):
return iter(torch.randperm(len(self.data_source)).long())
def __len__(self):
return len(self.data_source)
BatchSampler是一个普通Sampler的warpper, 普通Sampler一次仅产生一个index, 而BatchSampler一次产生一个batch的indices
class BatchSampler(object):
def __init__(self, sampler, batch_size, drop_last):
# 这里的sampler是randomSampler或者SequentialSampler
# 他们每次吐出一个idx
self.sampler = sampler
self.batch_size = batch_size
self.drop_last = drop_last
def __iter__(self):
batch = []
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0 and not self.drop_last:
yield batch
def __len__(self):
if self.drop_last:
# 不足的丢弃
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1)//self.batch_size
DataLoaderIter
- self.index_queue 中存放的是(batch_idx, sample_indices),其中batch_idx是个int值,sample_indices 是个list,存放了组成batch的sample indices。
- self.data_queue存放的是(batch_idx,samples),其中samples是一个mini-batch的样本
- self.send_idx表示:这次 放到self.index_queue中的batch_id
- self.rcvd_idx表示:这次要取的batch_id
class DataLoaderIter(object):
"Iterates once over the DataLoader's dataset, as specified by the sampler"
def __init__(self, loader):
# loader 是 DataLoader 对象
self.dataset = loader.dataset
# 这个留在最后一个部分介绍
self.collate_fn = loader.collate_fn
self.batch_sampler = loader.batch_sampler
# 表示 开 几个进程。
self.num_workers = loader.num_workers
# 是否使用 pin_memory
self.pin_memory = loader.pin_memory
self.done_event = threading.Event()
# 这样就可以用 next 操作 batch_sampler 了
self.sample_iter = iter(self.batch_sampler)
if self.num_workers > 0:
# 用来放置 batch_idx 的队列,其中元素的是 一个 list,其中放了一个 batch 内样本的索引
self.index_queue = multiprocessing.SimpleQueue()
# 用来放置 batch_data 的队列,里面的 元素的 一个 batch的 数据
self.data_queue = multiprocessing.SimpleQueue()
# 当前已经准备好的 batch 的数量(可能有些正在 准备中)
# 当为 0 时, 说明, dataset 中已经没有剩余数据了。
# 初始值为 0, 在 self._put_indices() 中 +1,在 self.__next__ 中减一
self.batches_outstanding = 0
self.shutdown = False
# 用来记录 这次要放到 index_queue 中 batch 的 idx
self.send_idx = 0
# 用来记录 这次要从的 data_queue 中取出 的 batch 的 idx
self.rcvd_idx = 0
# 因为多线程,可能会导致 data_queue 中的 batch 乱序
# 用这个来保证 batch 的返回 是 idx 升序出去的。
self.reorder_dict = {}
# 这个地方就开始 开多进程了,一共开了 num_workers 个进程
# 执行 _worker_loop , 下面将介绍 _worker_loop
self.workers = [
multiprocessing.Process(
target=_worker_loop,
args=(self.dataset, self.index_queue, self.data_queue, self.collate_fn))
for _ in range(self.num_workers)]
for w in self.workers:
w.daemon = True # ensure that the worker exits on process exit
w.start()
if self.pin_memory:
in_data = self.data_queue
self.data_queue = queue.Queue()
self.pin_thread = threading.Thread(
target=_pin_memory_loop,
args=(in_data, self.data_queue, self.done_event))
self.pin_thread.daemon = True
self.pin_thread.start()
# prime the prefetch loop
# 初始化的时候,就将 2*num_workers 个 (batch_idx, sampler_indices) 放到 index_queue 中。
for _ in range(2 * self.num_workers):
self._put_indices()
def __len__(self):
return len(self.batch_sampler)
def __next__(self):
if self.num_workers == 0: # same-process loading
indices = next(self.sample_iter) # may raise StopIteration
batch = self.collate_fn([self.dataset[i] for i in indices])
if self.pin_memory:
batch = pin_memory_batch(batch)
return batch
# check if the next sample has already been generated
if self.rcvd_idx in self.reorder_dict:
batch = self.reorder_dict.pop(self.rcvd_idx)
return self._process_next_batch(batch)
if self.batches_outstanding == 0:
# 说明没有 剩余 可操作数据了, 可以停止 worker 了
self._shutdown_workers()
raise StopIteration
while True:
# 这里的操作就是 给 乱序的 data_queue 排一排 序
assert (not self.shutdown and self.batches_outstanding > 0)
idx, batch = self.data_queue.get()
# 一个 batch 被 返回,batches_outstanding -1
self.batches_outstanding -= 1
if idx != self.rcvd_idx:
# store out-of-order samples
self.reorder_dict[idx] = batch
continue
# 返回的时候,再向 indice_queue 中 放下一个 (batch_idx, sample_indices)
return self._process_next_batch(batch)
next = __next__ # Python 2 compatibility
def __iter__(self):
return self
def _put_indices(self):
assert self.batches_outstanding < 2 * self.num_workers
indices = next(self.sample_iter, None)
if indices is None:
return
self.index_queue.put((self.send_idx, indices))
self.batches_outstanding += 1
self.send_idx += 1
def _process_next_batch(self, batch):
self.rcvd_idx += 1
# 放下一个 (batch_idx, sample_indices)
self._put_indices()
if isinstance(batch, ExceptionWrapper):
raise batch.exc_type(batch.exc_msg)
return batch
def __getstate__(self):
# TODO: add limited pickling support for sharing an iterator
# across multiple threads for HOGWILD.
# Probably the best way to do this is by moving the sample pushing
# to a separate thread and then just sharing the data queue
# but signalling the end is tricky without a non-blocking API
raise NotImplementedError("DataLoaderIterator cannot be pickled")
def _shutdown_workers(self):
if not self.shutdown:
self.shutdown = True
self.done_event.set()
for _ in self.workers:
# shutdown 的时候, 会将一个 None 放到 index_queue 中
# 如果 _worker_loop 获得了这个 None, _worker_loop 将会跳出无限循环,将会结束运行
self.index_queue.put(None)
def __del__(self):
if self.num_workers > 0:
self._shutdown_workers()
_worker_loop
这部分是多进程执行的代码:他从index_queue中取索引,然后处理数据,然后再将处理好的batch数据放到data_queue中
def _worker_loop(dataset, index_queue, data_queue,collate_fn):
global _use_shared_memory
_use_shared_memory = True
torch.set_num_threads(1)
while True:
r = index_queue.get()
if r is None:
data_queue.put(None)
break
idx, batch_indices = r
try:
# 这里就可以看到dataset.__getitem__的作用了
# 传到collate_fn的数据是list of ...
samples = collate_fn([dataset[i] for i in batch_indices])
except Exception:
data_queue.put((idx, ExceptionWrapper(sys.exc_info())))
else:
data_queue.put((idx, samples))
collate_fn参数
一般的,默认的collate_fn函数是要求一个batch中的图片都具有相同size(因为要做stack操作),当一个batch中的图片大小都不同时,可以使用自定义的collate_fn函数,则一个batch中的图片不再被stack操作,可以全部存储在一个list中
例子
def collate_fn(batch):
imgs, labels, paths, sizes = zip(*batch)
batch_size = len(labels)
imgs = torch.stack(imgs, 0)
max_box_len = max([l.shape[0] for l in labels])
labels = [torch.from_numpy(l) for l in labels]
filled_labels = torch.zeros(batch_size, max_box_len, 6)
labels_len = torch.zeros(batch_size)
for i in range(batch_size):
isize = labels[i].shape[0]
if len(labels[i]) > 0:
filled_labels[i, :isize,:] = labels[i]
labels_len[i] = isize
return imgs, filled_labels, paths, sizes, labels_len.unsqueeze(1)
参考:
https://zhuanlan.zhihu.com/p/144373921
https://zhuanlan.zhihu.com/p/169497395














 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









