







系列文章目录
前言
在深入学js逆向的时候,看到百度翻译,尝试了一下。破解后想看下其他人的思路,看了下基本上讲的都不够全。所以在这里详细记录下我个人的处理流程,希望能对其他学者提供参考
一、明确需要的接口和、参数
1.打开网站,检查,然后清除全部cookie、请求记录。然后重新刷新页面
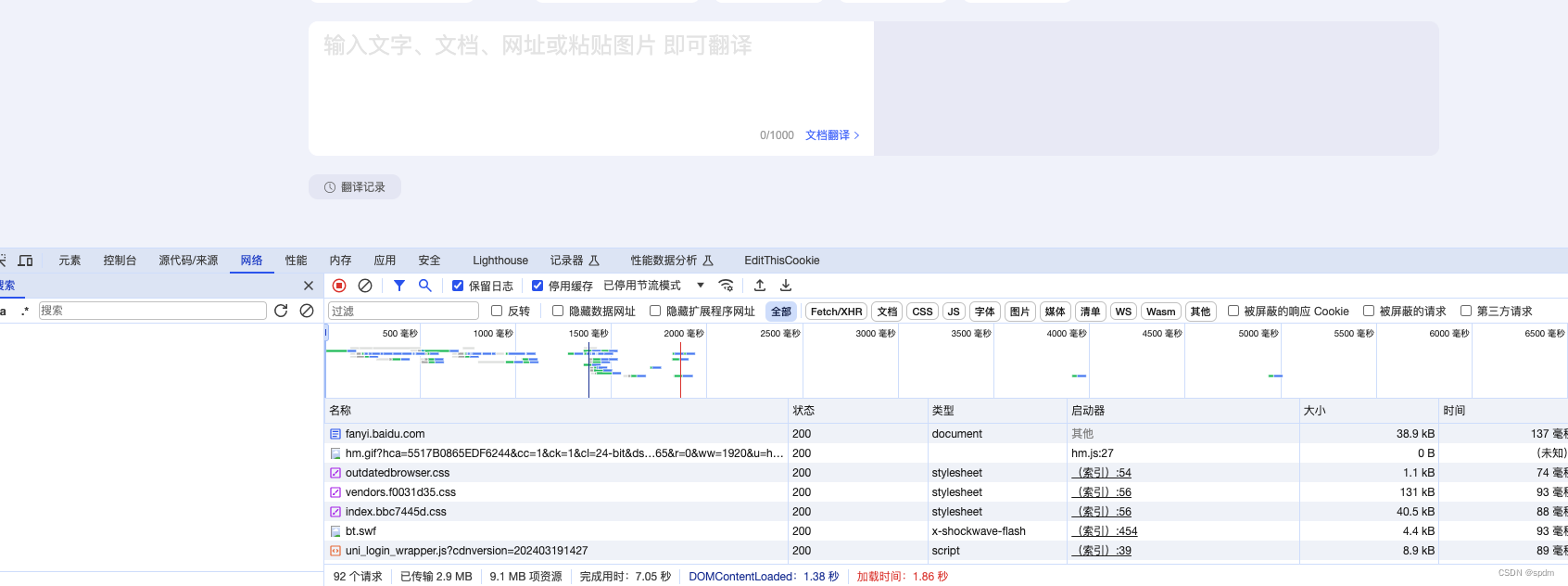
2.输入任意内容,都会直接翻译,这里以”你好“为例。输入你好 翻译后,很容易找到/v2transapi接口
- 右键选中该请求,选择以cURL格式复制。这里是方便直接转成可用的python代码,省的自己写
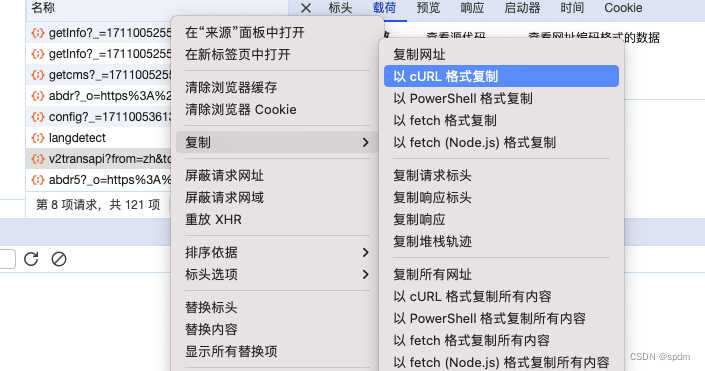
- 找个curl转换的网站,我一直用的是https://spidertools.cn/#/curl2Request(其他功能也很好用的网站)。效果如下
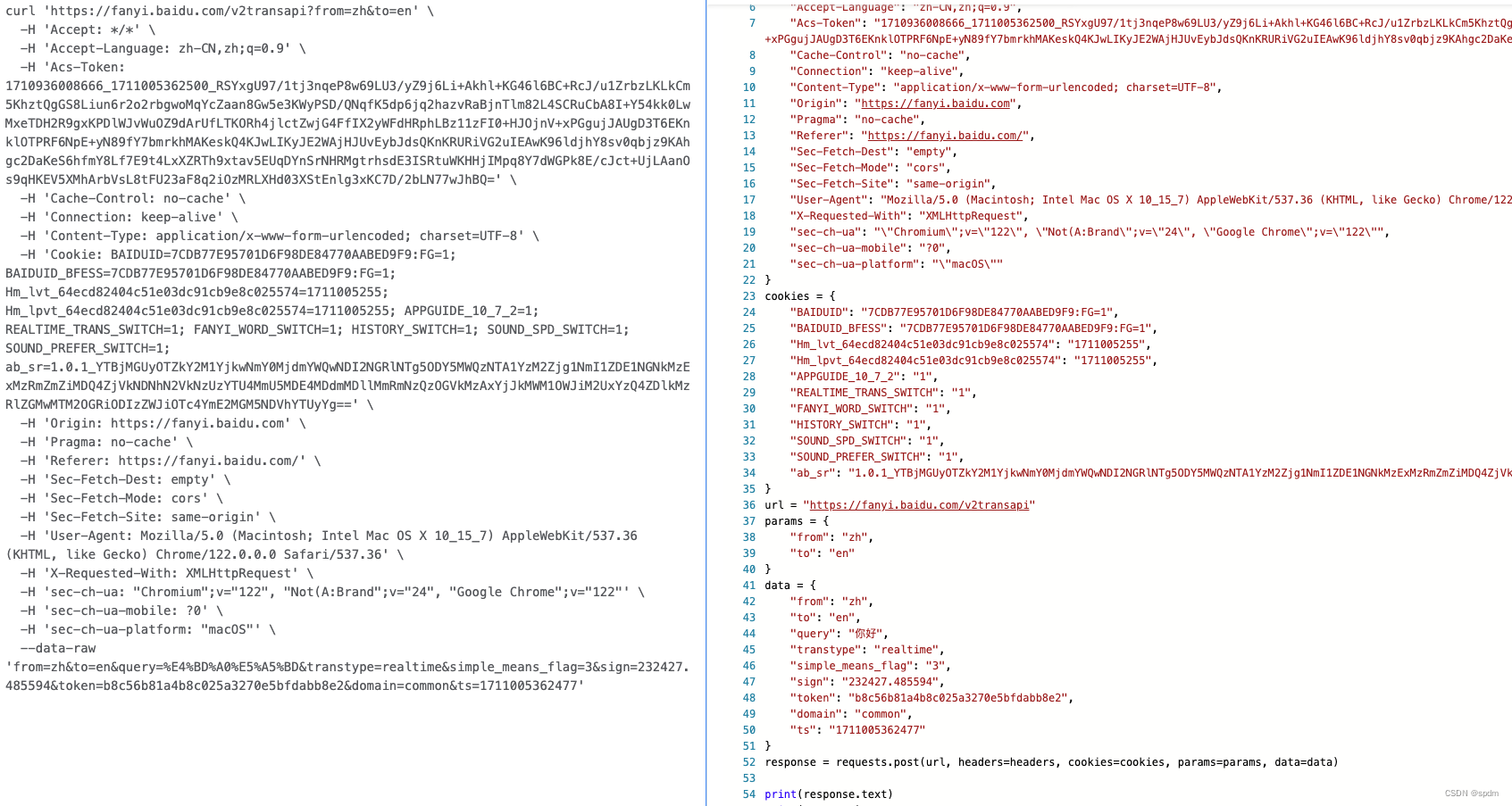
- 复制转换后的代码,复制到自己的python文件中,执行试试,没有问题,能正常请求。
3.开始定位关键参数。
- (1)首先能看到请求带了cookie,先确定cookie是否是必须的。
- 此时先在requests请求中删掉cookie,再请求,失败了,说明某些cookie是有用的。
- 这里很明显BAIDUID、BAIDUID_BFESS、ab_sr这些参数可能是有意义的。可以重新清除网页cookie对比变化、或者直接在代码中挨个删除,然后重新请求 去试哪个是有用的。最后发现必需的cookie只有BAIDUID,所以我们先找BAIDUID怎么生成的。
- 直接在左侧搜索,先看是不是某个请求set的,很显然能直接找到cookie生成的请求,就是第一次打开网站的请求

- 所以直接用session即可,这时候就可以先把这部分请求代码写好,
headers = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7", "Accept-Language": "zh-CN,zh;q=0.9", "Referer": "https://fanyi.baidu.com/", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36", } session_ = requests.session() home_res = session_.get('https://fanyi.baidu.com/', headers=headers)
- (2)cookie解决了,接下来找请求表单中的参数
- 很容易看出来请求参数中只有三个:sign、token、ts。不确定的话 重复请求几次也能看出来。其中sign会随输入的内容变化。
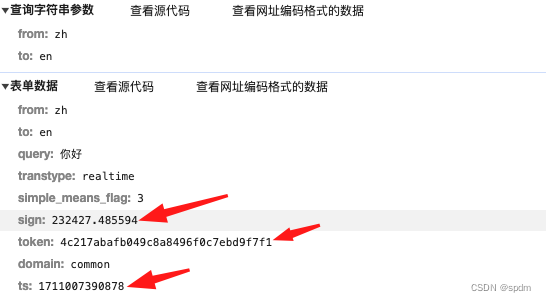
- 其中ts很容易能看出来是时间戳。无法确定也没关系,可以先不管,按顺序逐个处理
- 首先找sign
- 直接搜索sign,一般搜索参数可以用sign=、sign = 、sign:、sign : 这类方式,更容易定位
- 这里搜索可以看到结果不多,挨个看一下,很容易就能看到请求参数定义的地方,都在一起,非常友好 (这里如果不能确定的话,都打上断点,刷新几遍看看就知道了),这里左边打上断点,刷新后断住,e变量就是”你好“,选中b(e) ,也能看到这个执行结果就是我们想要的sign
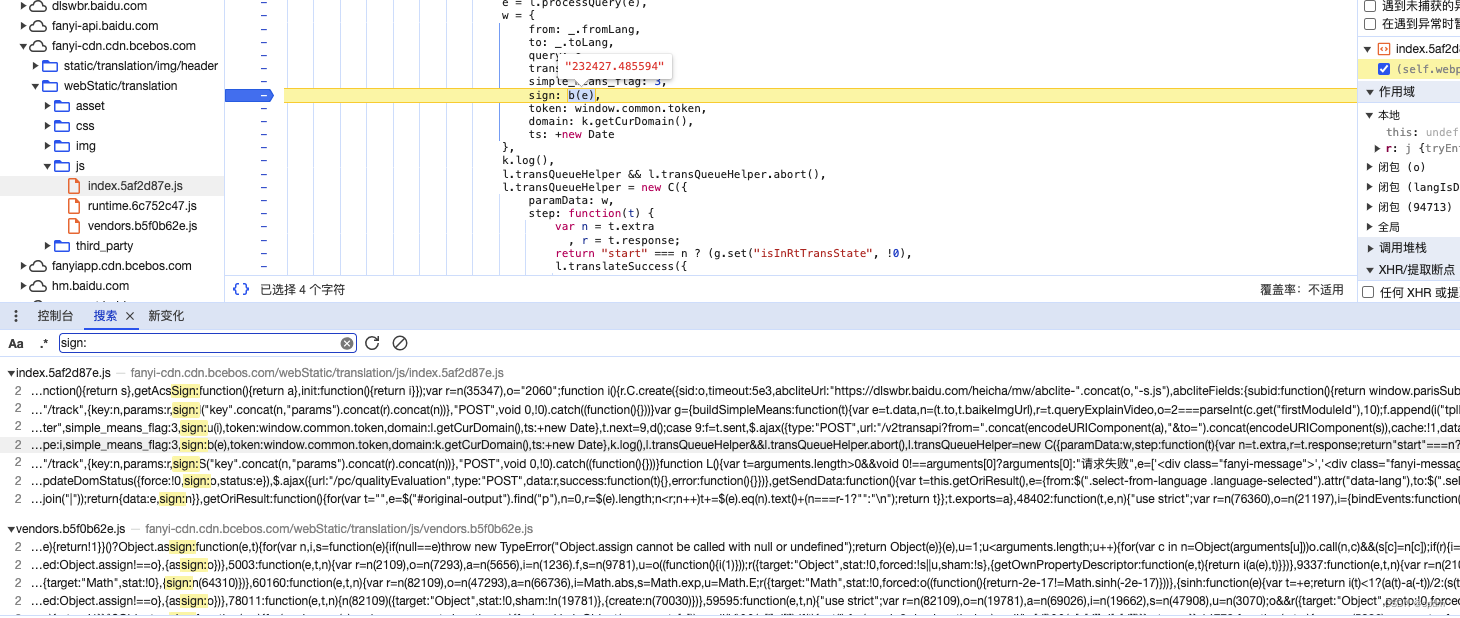
- 说明sign就是通过这个b方法生成的,鼠标放在b上,弹出框中点击js文件位置,跳转到b原函数中
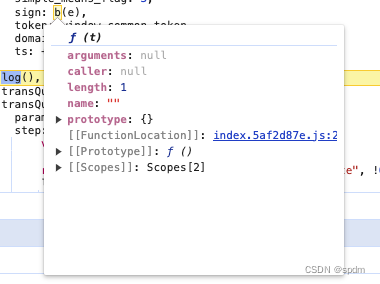

- 方法内部打个断点,继续执行一下,可以看到传入的t就是”你好“
- 函数内部就是执行了一堆计算逻辑,具体先不管,整个折叠复制下来。本地建一个js文件保存
- 修改一下函数定义,定义成getSign,尝试执行打印结果
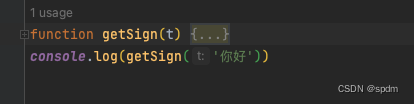
- 报错r没有定义,找到r的位置,在这里

- 在网页上找到对应的位置,在最近的位置打上断点,可以看到这一行代码实际上是个for循环,具体逻辑先不管
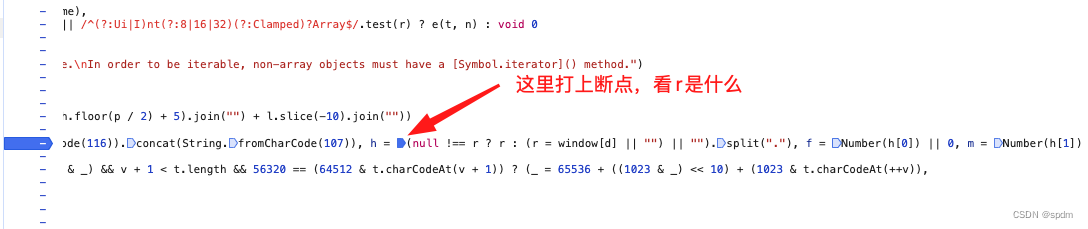
- 继续执行调到这个断点,发现r是null, 那就好办了,直接在代码最开始,定义r = null。重新执行js代码,又报错,window没有定义,那就啥也不管,先把window变量补上,前面加一行window = global(不了解window是什么的可以简单了解下)。重新执行js代码,报错,n方法没有定义,同样在网页上对应的n方法执行的位置打上断点,然后进入n方法
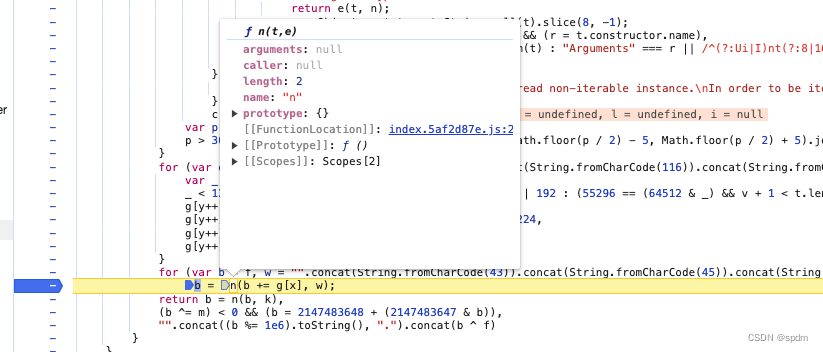
- 很简短的一个方法,直接整个复制下来贴进去。重新执行js文件。终于没有报错了,输出了结果,但是很显然,结果不对,这怎么看都不对

- 同样的js代码,传入相同的参数,结果不对, 说明一定是某个中间变量不对。我们可以在本地和浏览器上分别断点执行,逐步对比中间的数据哪些不一样,可能是环境不同导致的某种差异。但是这种方式很麻烦,读不懂代码也很费劲,非常不建议。
- 想到刚刚重新定义了r和window,很可能是这里导致的,所以再看一下这部分执行逻辑,再打上断点调试。

- 可以确定r开始确实是null,但是这里执行了判断:当r为null时,将window[d]赋值给r。不看具体逻辑也行,但显然这里用到了window中的d属性的值,看一下是什么东西。直接把断点往后打一点,可以看到执行完这句后,r被赋值成window[d]的值,是一串数字

- 其中d=‘gtk’, 是浏览器环境中的某个值?在本地抠下来的代码上断点执行一下,发现同样的逻辑在本地确实是没有window['gtk‘]这个属性。说明在浏览器某个地方给windows对象添加了全局变量gtk = ‘320305.131321201’,至于会不会变,我们还每不能确定。先在代码中将window[d]替换成’320305.131321201’试试,重新执行,现在getSign执行结果就对了,跟浏览器请求的sign一样

- 即使我们重试几次发现window.gtk并没有发生变化,也不能认为它不会变化,除非我们能确定它在函数执行前明确定义了gtk = ‘320305.131321201’。所以要先找一下gtk是哪里来的。
- 先尝试全局搜一下gtk, 结果真的直接出来了,就是请求首页源码返回的,正则取出来就好了,非常友好
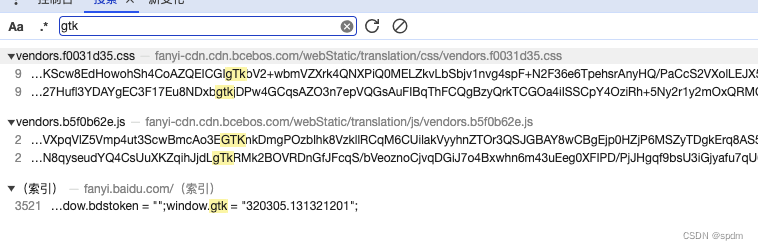
- 整个sign生成的逻辑就很清晰了
- sign搞定了,接下来找token
- 随便一搜token:就出来了,很显然也是首页直接源码返回的

- 随便一搜token:就出来了,很显然也是首页直接源码返回的
- token也找到了,最后一个ts
- 跟sign一样的位置,这里ts直接就是 +new Date,反正就是个时间戳完全不用看
- 跟sign一样的位置,这里ts直接就是 +new Date,反正就是个时间戳完全不用看
参数全部搞定了,开始写代码
二、完成代码
1.js代码
代码如下(示例)baidu.js:
window = global
r = null
function n(t, e) {...}
function Sign(t, gtk) {...} //因为gtk是额外获取的,这里加个参数传进去;只要里面window['d']换成gtk变量就行;
console.log(Sign("你好", '320305.131321201'))
2.python代码
代码如下(示例):
import json
import re
import time
import execjs
import requests
from proxy.get_proxy import get_proxy
requests.packages.urllib3.disable_warnings()
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9",
"Referer": "https://fanyi.baidu.com/",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
}
session_ = requests.session()
# 第一次请求首页,目的是生成cookie
res1 = session_.get('链接自行替换', headers=headers, proxies=get_proxy())
# 第二次请求首页,目的是获取token
res2 = session_.get('链接自行替换', headers=headers, proxies=get_proxy())
query = '你好'
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Accept-Encoding": "gzip, deflate",
"Accept": "*/*",
"Connection": "keep-alive",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Origin": "https://fanyi.baidu.com",
"Pragma": "no-cache",
"Referer": "https://fanyi.baidu.com/",
"X-Requested-With": "XMLHttpRequest",
}
url = "链接自行替换/v2transapi"
params = {
"from": "zh",
"to": "en"
}
gtk = re.search(r"gtk = \"(.*?)\";", res1.text).group(1)
with open(r'baidu.js', 'r', encoding='utf-8') as f:
js_ = f.read()
js_c = execjs.compile(js_)
sign = js_c.call("Sign", query, gtk)
ts = str(int(time.time()*1000))
data = {
"from": "zh",
"to": "en",
"query": query,
"transtype": "realtime",
"simple_means_flag": "3",
"sign": sign,
"token": re.search(r"token: '(.*?)'", res2.text).group(1),
"domain": "common",
"ts": ts
}
response = session_.post(url, headers=headers, params=params, proxies=get_proxy(), data=data)
print(json.loads(response.text))
上述代码只是写了个简单的demo。
实际上里面还有个地方需要注意,就是实际获取token是需要携带cookie第二次请求首页,源码中才会返回token,这个也比较容易发现,这里就不再详细说明。
总结
以上方法仅用于个人学习参考















 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









