







 本文详细描述了如何通过爬虫技术抓取极简壁纸网站的图片,包括确定抓取思路、追踪请求链路、解密图片地址和处理重定向等步骤,强调了学习和参考价值,但提醒读者不要滥用爬虫。
本文详细描述了如何通过爬虫技术抓取极简壁纸网站的图片,包括确定抓取思路、追踪请求链路、解密图片地址和处理重定向等步骤,强调了学习和参考价值,但提醒读者不要滥用爬虫。
声明:本文章仅供学习参考,请勿滥用爬虫下载
目录
前言
分享下爬取「极简壁纸」网站图片的爬虫流程,主要是分享个人处理的思路。
网站地址(bs64):aHR0cHM6Ly9iei56enptaC5jbi9pbmRleA==
一、确定抓取思路
- 打开网站,先确定下图片下载保存操作的基本逻辑
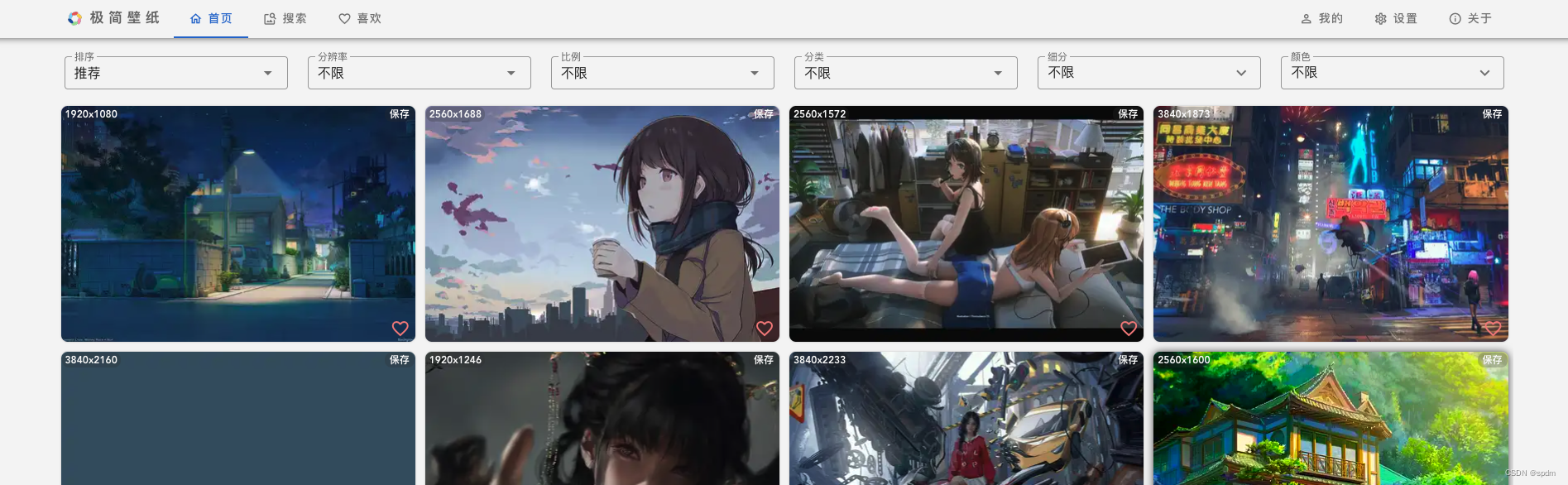
- )可以看到网站首页列表加载了多张图片,点击其中一张,会弹出一个巨大的预览窗口,点击下载按钮后就可以下载原图片。不需要多余的东西,非常友好
- )我们可以暂且认为一张图片可能有三种状态,可以称之为列表页的略缩图、点击展开后的预览图、提供下载的原图。我们的目标就是获取原图的下载链接
- )那我们就从点击下载这一步开始往前推
- )可以看到网站首页列表加载了多张图片,点击其中一张,会弹出一个巨大的预览窗口,点击下载按钮后就可以下载原图片。不需要多余的东西,非常友好
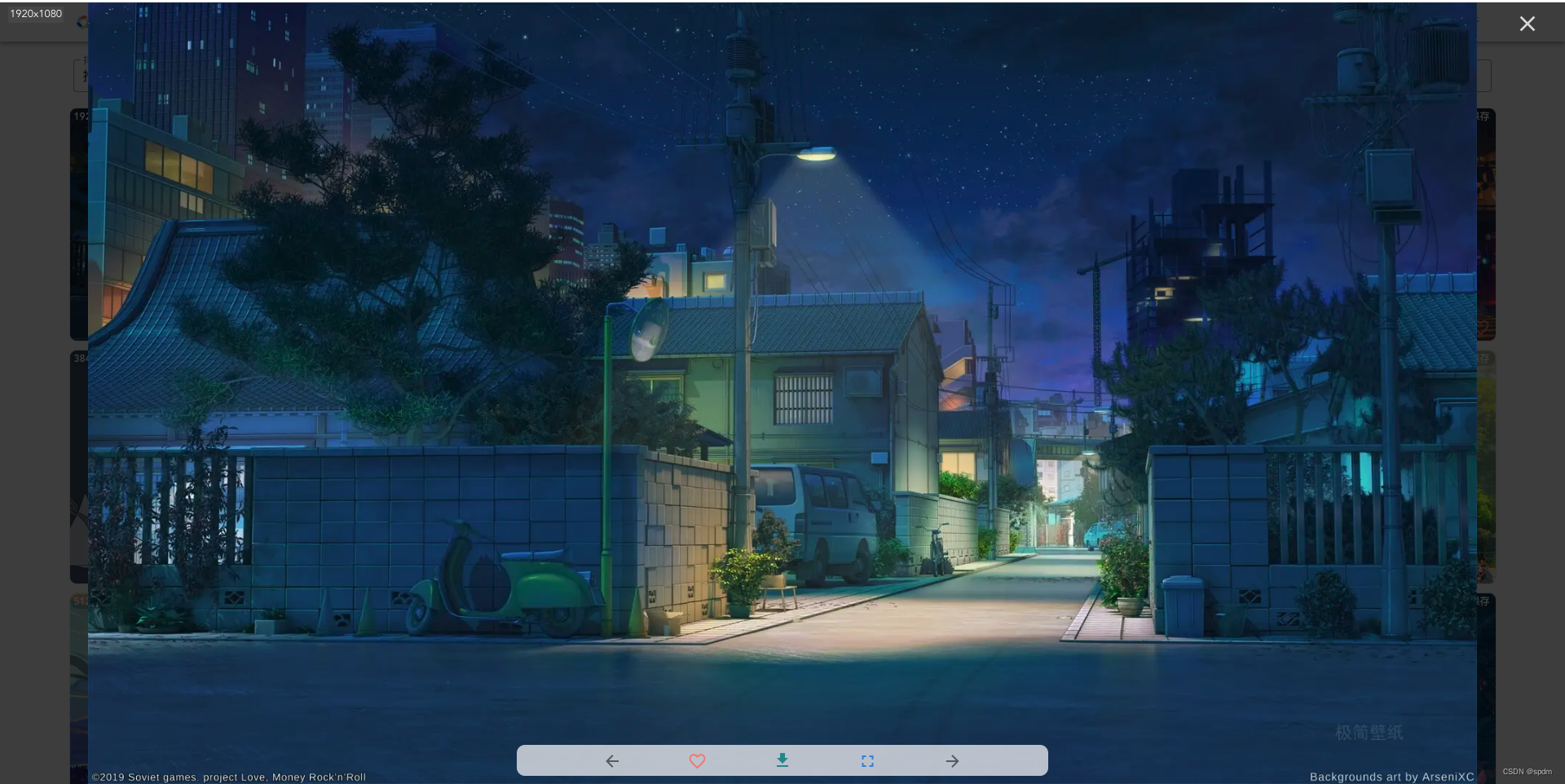
- 打开控制台-网络面板,清除cookie,刷新页面。然后点击预览一张图片。这时候再清除网络面板的浏览记录,因为接下来我们要点击下载,要看下载请求的内容
- 可以看到下面几个请求包
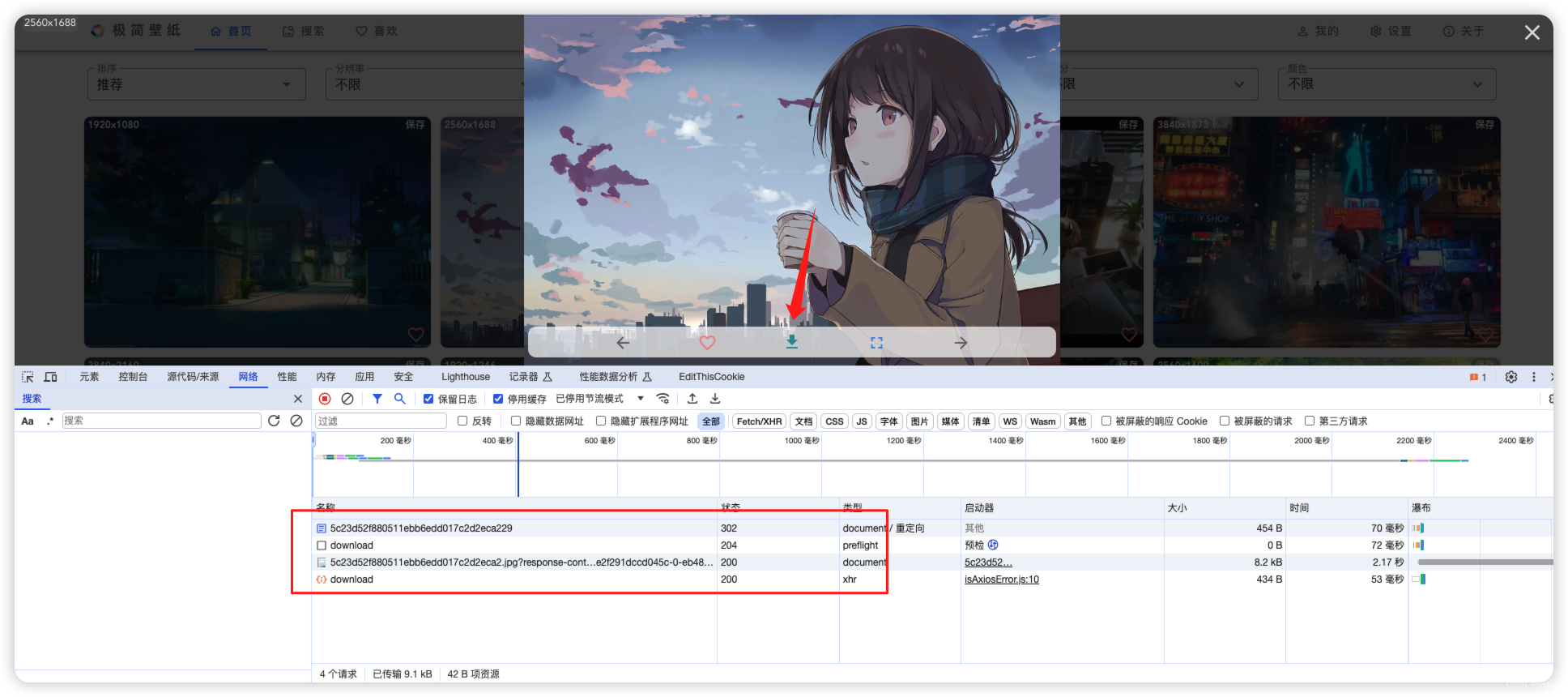
- 很显然其中第三个才是下载图片的请求,复制请求链接在新窗口打开,可以看到确实下载了图片。当然这时候我们还不能确定这个链接需不需要我们自己构造,能不能直接拿到。简单看下这个链接的请求参数:/wallpaper/origin/5c23d52f880511ebb6edd017c2d2eca2.jpg?response-content-disposition=attachment&auth_key=1711900800-340294865c06427f78a2d41ce8e2f291dccd045c-0-eb48d71e26b14ebcc2ac2fead8f390d3
其中显然可以拆成三部分。一部分是文件路径5c23d52f880511ebb6edd017c2d2eca2;一部分是参数response-content-disposition,显然是固定的attachment;还有个长长的auth_key。
那我们开始找图片链接哪里来的
二、顺藤摸瓜
- 全局搜索图片地址 5c23d52f880511ebb6edd017c2d2eca2 ,可以看到源码中没有找到任何内容,只有请求地址中包含。尝试搜索bz/v3/getUrl也一样。说明图片的地址大概率是被加密了
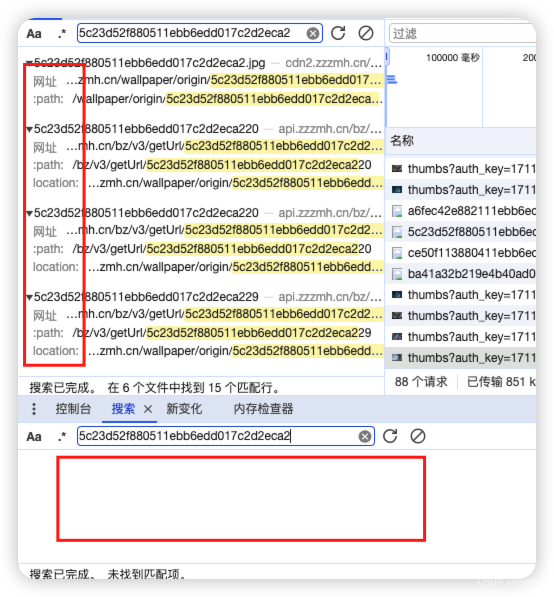
- 点击检查页面元素,看下网页加载的图片地址
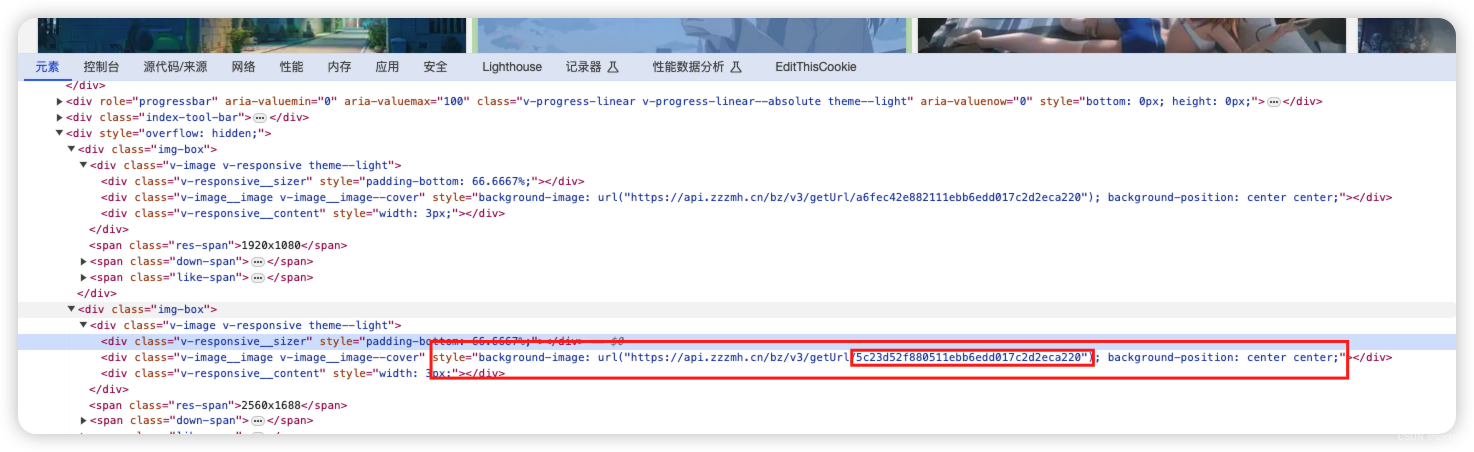
- 可以看到网页上图片的地址也是包含一串特殊字符,对比下就会发现,网页略缩图地址是5c23d52f880511ebb6edd017c2d2eca220, 相比5c23d52f880511ebb6edd017c2d2eca2,结尾多了个20,20是什么还不确定,可以先不管。可以确定的是这串字符就是这张图片的关键,必然在某个请求中返回来加密的。
- 重新刷新页面,筛选请求Fetch/XHR, 可以很明显看到/getData,应该就是获取数据的接口。
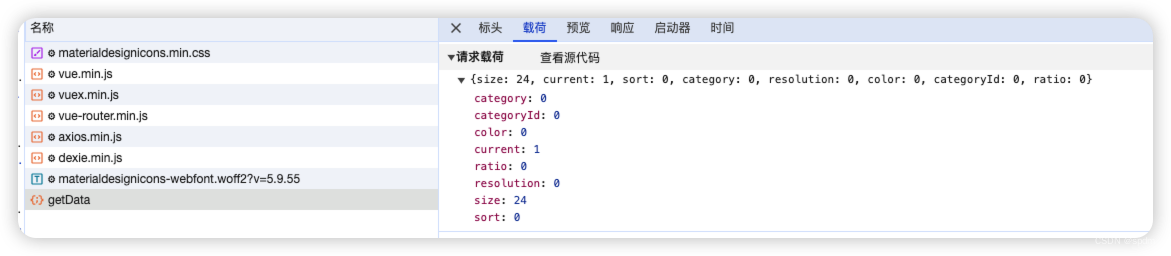
- 返回结果中的result显然是加密内容,应该就是我们想要的包含图片地址的内容

- 观察该请求,或者直接复制cURl然后转成python代码请求,会发现不需要cookie或有加密的参数,直接请求即可。那就开始破解响应解密
- 添加XHR断点

- 刷新页面,断住。但是可以看到并没有跟预期一样,断在send()的地方,而是个很奇怪的地方。假设我们并不了解axios是什么,很陌生,这里尝试往下继续执行看看。会发现代码已经被OB混淆了,执行下来也没办法看出什么有用的信息
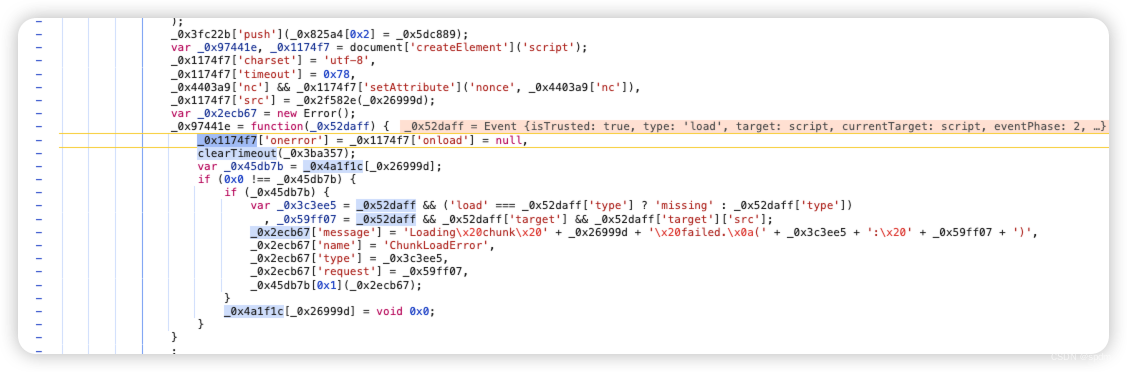
- 这时候先换个方式试试。先删掉这个XHR断点。然后直接全局搜索接口名称/getData

- 只有一处,点击跳转对应位置,在对应位置打上断点。重新刷新页面,断住了
- 此时我们已经可以观察到,对应位置前面,实际上就是请求参数定义的地方。那么这一块应该就是请求定义的地方。
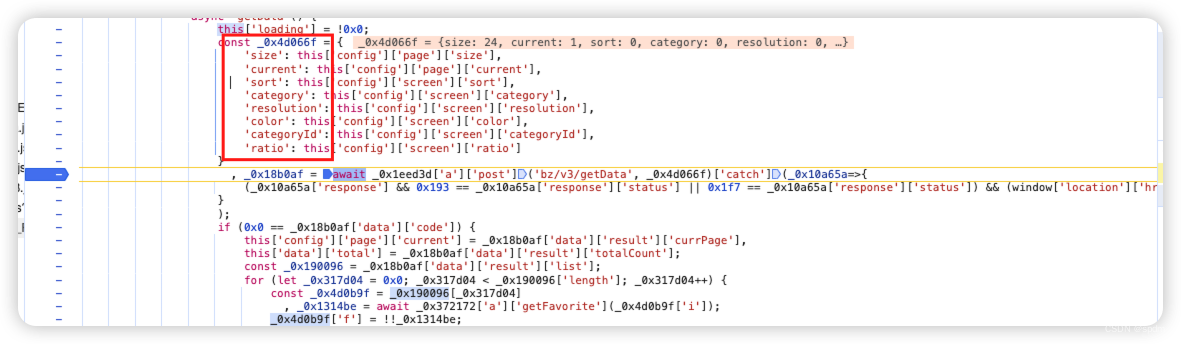
- 那我们的目标是定位到请求完成返回响应后,进行解密的地方,那就继续向下执行。虽然这里的变量名什么的被混淆过,但我们先不需要关心它到底是什么。实际上我们能大概读懂代码:这里用了await, 并且能看到post和目标地址、应该就是个异步请求,然后对状态码什么的做判断
- 不好读懂也没关系,先找到我们想要的变量值即可。正常向下走(一般就是先用”跳过下一个函数调用“这个),可以看到_0x18b0af这个变量已经有值了,看到status 200就知道是响应的结果,看一下是不是我们想要的结果

- 可以鼠标选中查看,也可以在控制台输出查看
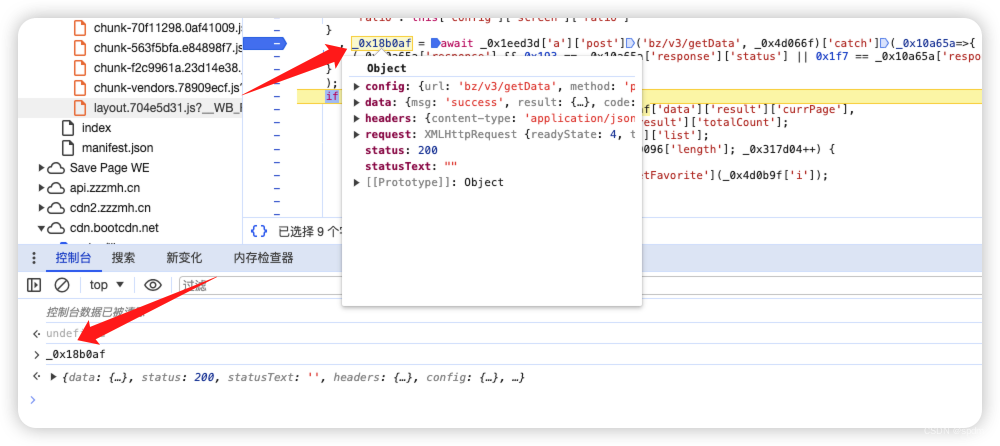
- 展开后很显然能看到,data就是响应的内容,但是这里已经是被解密后的结果。这说明在上一行代码的执行中,已经完成了请求和响应解密的过程。
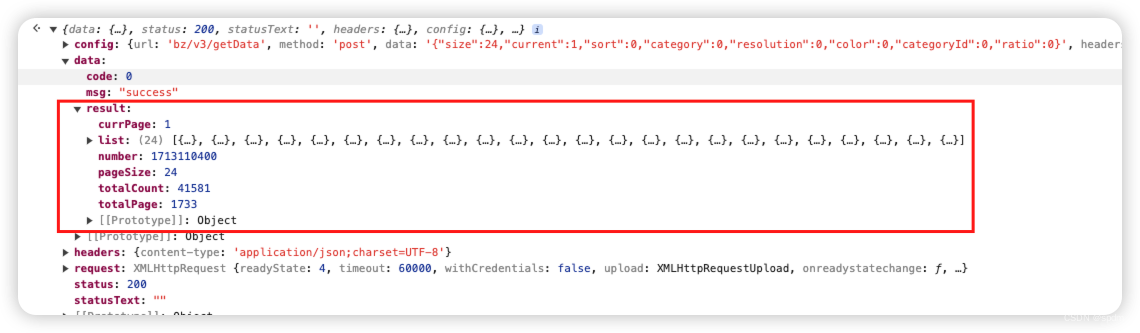
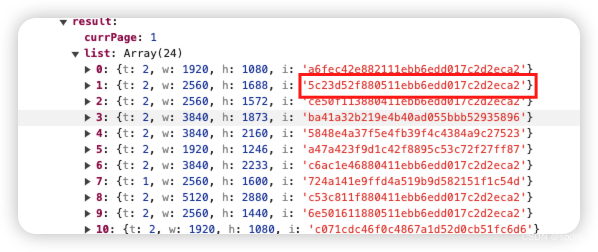
- 点击展开观察下result中的内容,就能看到,确实包含了我们想要的5c23d52f880511ebb6edd017c2d2eca2。再看下另外几个值,一个t, 是2或者1;w和h比较明显能看出来,就是图片的像素。这里看到了注意了就行。
- 那就重新刷新,回到前面断点断住(这里如果选中`_0x1eed3d['a']['post']('bz/v3/getData', _0x4d066f)`会发现这就是个Promise对象,这里实际上就是执行了Promise实例,不熟悉可以了解下。实际上不知道也没关系,完全可以不用管)
- 点击执行进入“下一个函数调用“。为什么现在是执行这个?因为刚刚用左边的”跳过下一个函数调用“,直接就已经拿到结果了,那就慢点走看看,所以点这个执行,钻进其他方法内部看看
- 可以看到进入到构建Promise实例函数的方法内了,按常规来看那么then后面接的应该就是获取到响应后执行的回调函数了。也可以直接看出来,后面有对响应内容执行的某些操作
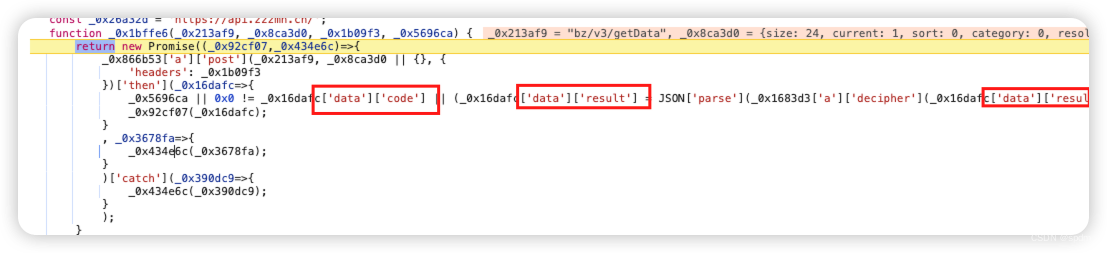
- 打个断点执行过去,打印下result的内容。以及后面用json.parse解析,大概率就是解密后做序列化了,打印下看看,确实是的,基本已经可以断定,_0x1683d3['a']['decipher']就是解密的方法
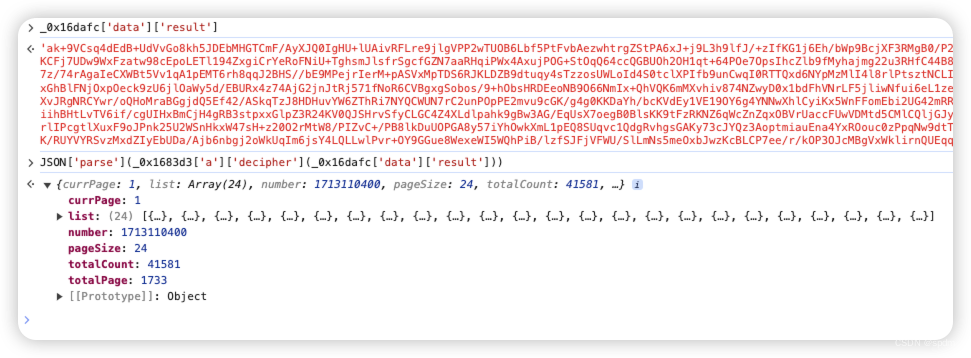
- 选中_0x1683d3['a']['decipher'],在弹出的函数信息中点击跳转到对应js文件位置中,可以看到是嵌套了好几层函数,先不管,本地新建js文件复制进去。然后补一下这三个函数,同样选中点击跳转,发现就都在前面,大致是一些运算逻辑。不用管具体内容,整体复制下来
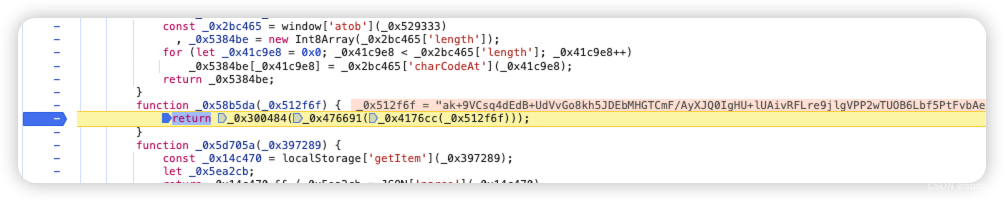
- 稍微改下关键的函数名,看起来更舒服,直接执行
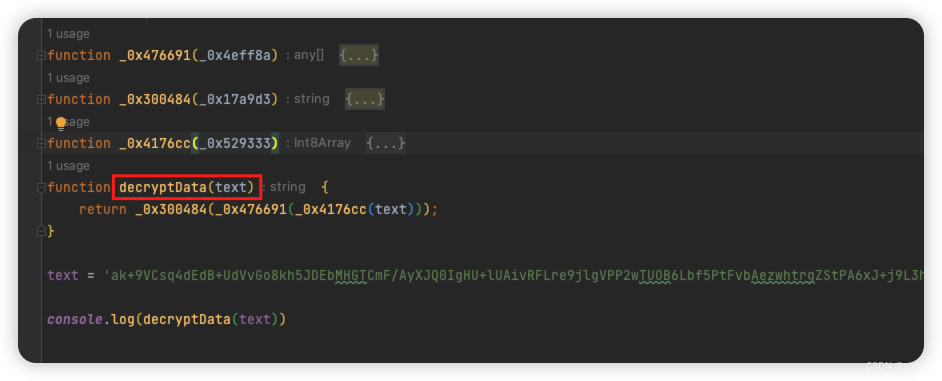
- 报错ReferenceError: window is not defined,那就还是补上window = global。重新执行,完美打印出结果

- 至此响应的解密过程就完成了。简单验证下(代码demo如下)
- js部分代码
window = global function _0x476691(_0x4eff8a) {} function _0x300484(_0x17a9d3) {} function _0x4176cc(_0x529333) {} function decryptData(text) { return _0x300484(_0x476691(_0x4176cc(text))); } text = '' console.log(decryptData(text)) - python部分。执行下,没有问题
import execjs import requests import json from proxy.get_proxy import get_proxy with open('test.js', 'r') as f: js_ = f.read() js_c = execjs.compile(js_) def get_page(page_num): list_headers = { "authority": "api.zzzmh.cn", "accept": "application/json, text/plain, */*", "content-type": "application/json;charset=UTF-8", "origin": "https://bz.zzzmh.cn", "referer": "https://bz.zzzmh.cn/", "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36" } url = "https://api.zzzmh.cn/bz/v3/getData" data = { "size": 24, "current": page_num, "sort": 0, "category": 0, "resolution": 0, "color": 0, "categoryId": 0, "ratio": 0 } data = json.dumps(data, separators=(',', ':')) response = requests.post(url, headers=list_headers, data=data, proxies=get_proxy()) page_data = json.loads(js_c.call('decryptData', json.loads(response.text)['result'])) return page_data print(get_page(1))
- js部分代码
- 添加XHR断点
- 我们需要的列表请求解密,获取到图片下载路径的过程已经实现了,那么接下来就是找url中的auth_key是如何生成的
- 还是先把浏览器cookie、以及我们打过的断点什么的取消/清除掉(每次开始新的数据定位之前,为了避免一些无效的干扰,一般最好都恢复原始状态)。然后刷新页面
- 这时候保留网络请求记录,再点击略缩图->打开预览图后点击载,然后看最新的下载请求的url中的auth_key,直接取一部分在请求中搜索一下
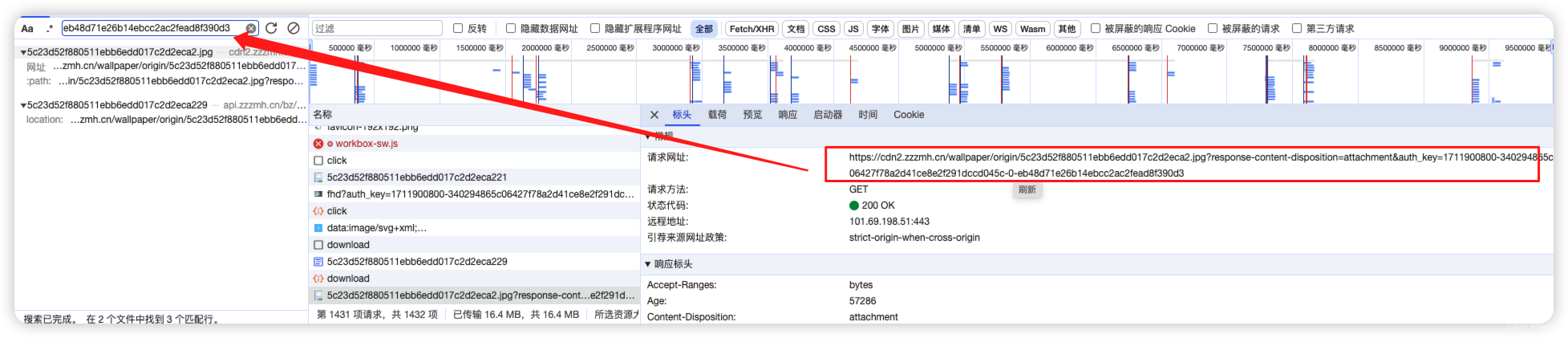
- 比如我这里取最后的eb48d71e26b14ebcc2ac2fead8f390d3进行搜索,会发现只有两个结果。一个是下载图片时请求的地址,另一个是某个请求的响应头中的Location。这时我们可以知道,当我们点击下载图片时,是先请求了某个地址,然后发生重定向转到了我们真正下载图片的地址。那么这里我们只需要用requests简单模拟重定向过程就行了
- 实际上我们发现重定向不一定需要这么繁琐的过程,当我们检查预览图上的下载按钮时也能看到重定向前的地址。复制下来新窗口打开,就会发现重定向到了新地址。或者我们第一次下载图片看网络请求记录时如果注意到了,也可以发现。这里各人处理方式、步骤不同。只要最终找到就行
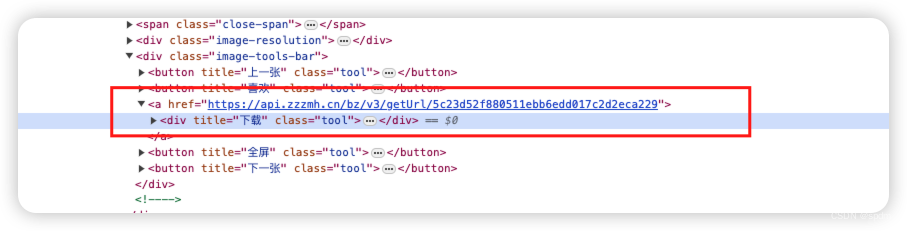
- 实际上我们发现重定向不一定需要这么繁琐的过程,当我们检查预览图上的下载按钮时也能看到重定向前的地址。复制下来新窗口打开,就会发现重定向到了新地址。或者我们第一次下载图片看网络请求记录时如果注意到了,也可以发现。这里各人处理方式、步骤不同。只要最终找到就行
- 我们可以看到,原请求地址是/bz/v3/getUrl/5c23d52f880511ebb6edd017c2d2eca229,其中很明显也包含了5c23d52f880511ebb6edd017c2d2eca2,只是结尾多了个29。前面我们已经注意到略缩图地址结尾多了20。20是什么不确定我们可以先不管 因为我们不需要略缩图,但是这里包含29的地址是我们需要构造的请求地址,那就没办法避开了,必须先确定它是什么。
- 一般这种情况,第一步先观察,是不是固定值。如果不是,再看看是不是有什么规律,比如跟位置有关、或者顺序有关?这里我们就多点开几张图片下载试试。
- 首先在多下载几张不同的图片之后就会发现,要么是29,要么是19,暂时看不到其他情况(这里最后有一种最极端的情况就是我们实在无法判断到底是29还是19,那就只能29和19都试试,万一就是随机的都能用呢?或者就是在代码上兼容,29、19都请求一次,哪个成功了就用哪个。这些都可以是解决问题的一种方式)
- 这里可以说有两种判断方式:
- 按常规方式,我们需要知道29是什么,那就要找到请求地址构造逻辑。
- 既然是构造url,那先拿url一部分去搜,比如就拿/getUrl, 搜出来发现刚好就一个地方,并且正好就是一个相加的逻辑。打上断点,刷新页面

- 可以很清楚看到其中_0x107034传参就是我们想要的值。这时候就可以开始通过右侧堆栈往前找,看是哪一步传入的

- 比较容易能找到对应的最开始传参调用的地方,查看其中_0x4b8fb3其实已经很明显了,就是我们获取到的响应,包含t, 还有图片像素的东西。后面的0x0就是0,因为这还是在生成略缩图地址,细心点能看到代码后面,有个0x9,就是生成预览图时执行的部分
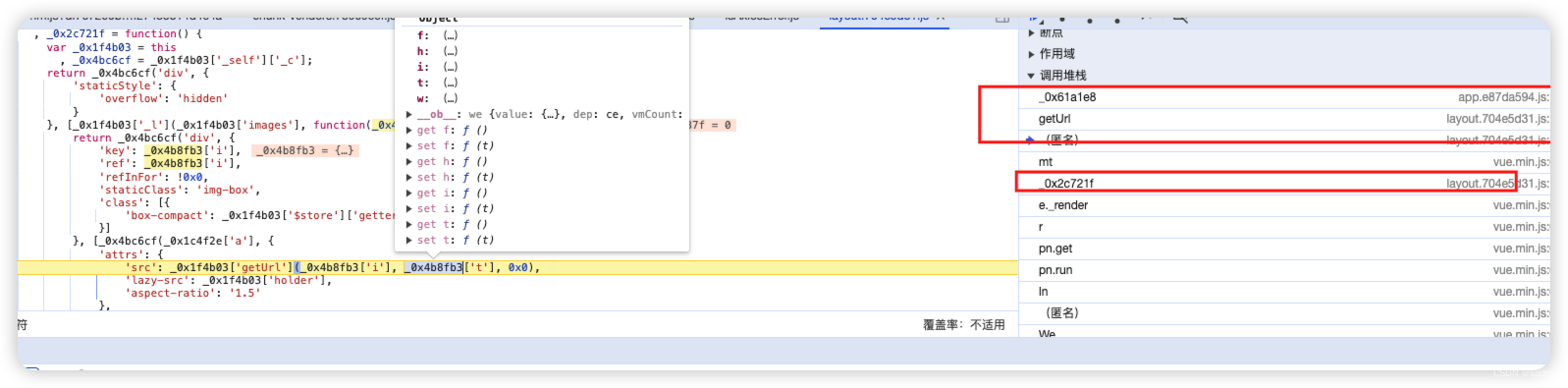
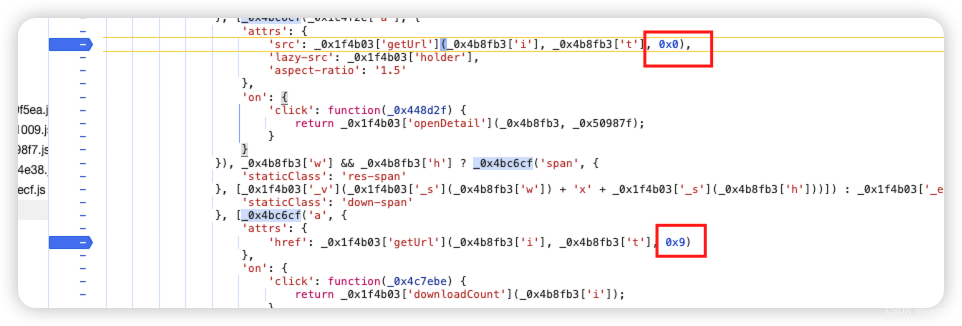
- 那这个逻辑就很清晰了,这个29就是两部分,2是取列表页响应result.list中包含的那个t值,9是固定值
- 既然是构造url,那先拿url一部分去搜,比如就拿/getUrl, 搜出来发现刚好就一个地方,并且正好就是一个相加的逻辑。打上断点,刷新页面
- 另一种判断29如何生成的方式,其实就是凭感觉。
- 因为开始我们破解出列表页响应内容的时候,已经注意到里面包含一个未知的t值,也是1或者2。很容易就能想到29中的2可能就是t,;另外9一直没变,大概率是个固定值。
- 那就只需要逐一对比了,拿到响应result,然后在网页上逐个点击图片,逐个对比,会发现都能对得上,就可以确定了。
- 这时我们需要的原图的原地址的url构造方式也确定了。先把代码完成看看
- 简单写下python代码
def download_picture(page_data): for i in page_data['list']: first_headers = { "authority": "api.zzzmh.cn", "accept": "image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8", "accept-language": "zh-CN,zh;q=0.9", "cache-control": "no-cache", "pragma": "no-cache", "referer": "https://bz.zzzmh.cn/", "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36" } first_url = f'https://api.zzzmh.cn/bz/v3/getUrl/{i["i"]}{i["t"]}9' first_res = requests.get(url=first_url, headers=first_headers, proxies=get_proxy()) with open(f"./img/{i['i']}.jpg", 'wb') as f: f.write(first_res.content) download_picture(get_page(1)) - 执行后正常下载,查看下图片大小什么的,跟网页下载没有什么区别。
- 简单写下python代码
- 按常规方式,我们需要知道29是什么,那就要找到请求地址构造逻辑。
- 通过上述过程实际上已经完成了全部内容。这里额外说明一点,因为我之前在抓取该站点时发现,在最后使用原url请求下载原图时,通过request无法正常进行302重定向,返回都是403。通过抓包发现,该请求只能通过h2协议请求。所以改成通过httpx的h2请求后手动获取Location地址触发二次请求,才完成下载。但现在好像没有碰到这个问题了。
总结
仅供学习参考,请勿恶意采集

















 1937
1937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









