







 本文记录了使用pandas和matplotlib对爬取的2030条爱屋吉屋二手房数据进行清洗和分析的过程。通过转换数据类型、提取数值和创建新列,展示了房源的看房次数、挂牌天数、区域、单价分布、面积和户型等信息,并绘制了图表。数据显示,长宁静安黄埔区的房价较高,70-90平方米的房子较为常见,且近60%的房源报价保持不变或下降。
本文记录了使用pandas和matplotlib对爬取的2030条爱屋吉屋二手房数据进行清洗和分析的过程。通过转换数据类型、提取数值和创建新列,展示了房源的看房次数、挂牌天数、区域、单价分布、面积和户型等信息,并绘制了图表。数据显示,长宁静安黄埔区的房价较高,70-90平方米的房子较为常见,且近60%的房源报价保持不变或下降。
之前爬取的爱屋吉屋二手房数据做了下简单的处理,电脑太慢只爬取了2030条。整个过程记录一下
首先导入数据:
import pymysql as py
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
conn=py.connect(host='127.0.0.1',port=3306,user='root',passwd='xxxxxxx',db='scrapy',charset='utf8')
cur=conn.cursor()
sql = "select * from aiwuv2"
df = pd.read_sql(sql,conn)查看下数据

接下来开始整个清洗处理过程
查看数据的列
df.columns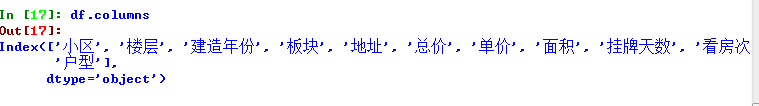
看起来很乱索性导入到excel里查看下,毕竟只有2000多条
df.to_excel('h:\\new\\aiwu\\aiwuver1.0.xlsx')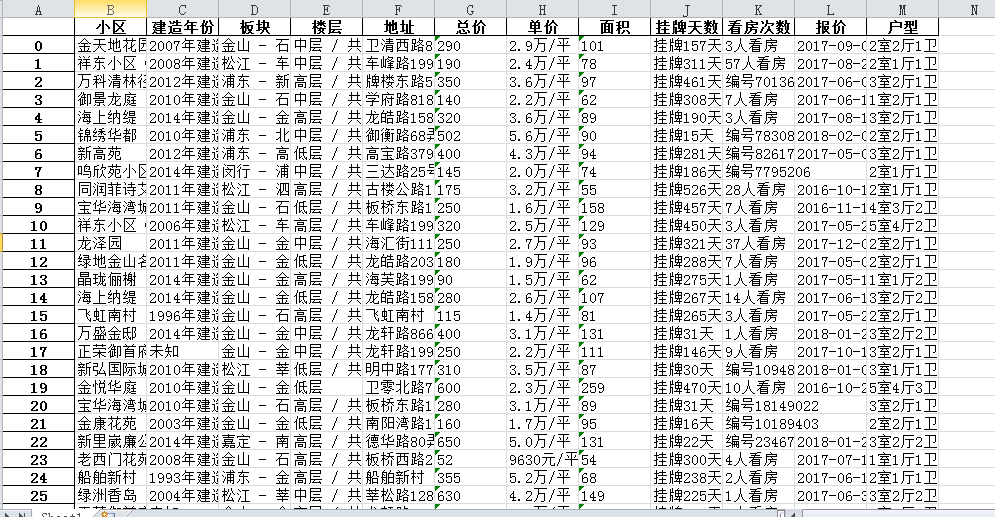
处理的思路是:
看房次数列转为int类型,内容为编号xxxx的定义为看房次数为0
挂牌天数列提取数字
根据板块一列增加一列区
单价一栏大部分是万/平,少部分是元/平要提取出数字
OK,现在从看房次数列开始
观察到此列的基本格式是:1.编号开头 2.x人看房。所以处理方式针对第一种直接定义为0次看房,第二种提取出数字
def kanfang(a):
if a.startswith('编号'):
retu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









