









目录
异常
HTTPError是URLError的子类
例如如下代码
import urllib.request
url = 'https://blog.csdn.net/DDDDWJDDDD/article/details/136343427'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
如上的话正常访问是没有一点问题的,可如果你将URL修改一下
比如修改成如下的样子
url = 'https://blog.csdn.net/DDDDWJDDDD/article/details/136343427666'我在后面加了个666
这样再运行直接就报错HTTPError了

如果是这样写URL:
url = 'https://www.aaaaa666.com'那么直接报错URLError
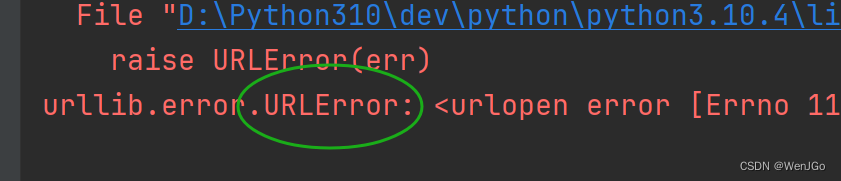
遇到这种异常直接try起来就好了,至少不会报错,然后取修改你的URL吧
import urllib.request
import urllib.error
# url = 'https://blog.csdn.net/DDDDWJDDDD/article/details/136343427666'
url = 'https://www.aaaaa666.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
try:
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级...sorry~~')
except urllib.error.URLError:
print('系统正在升级...dbq')
Cookie登录
当你在数据采集的时候需要绕过登录然后进入某个页面,这时候cookie登录就派上用场了
比如在微博的个人信息的详细页面,如果我们直接这样写可以获得内容吗
import urllib.request
# 在数据采集的时候需要绕过登录然后进入某个页面
url = 'https://weibo.cn/6582012663/info'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取数据获取数据
content = response.read().decode('utf-8')
# 将数据保存到本地
fp = open("weibo.html", 'w', encoding='utf-8')
fp.write(content)
但是实际上是不可以,因为我们这样模拟浏览器去访问和直接换一个浏览器或者设备去访问好像是一个效果,所以都会让你从新登录,因此是不可以的。
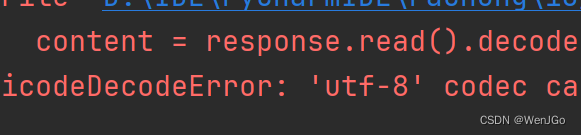
个人信息页面是utf-8,但还是报错了编码错误 ,因为没有进入个人信息页面,然后网站的拦截器拦截了请求,将其跳转到了登录页面,但是登录页面又不是utf-8,所以报错。
那这就是因为请求头的信息不够了,因此访问失败了
我们将登录成功的header中的所有内容都加入忙着哩可以使用notepad++全部替换搞定
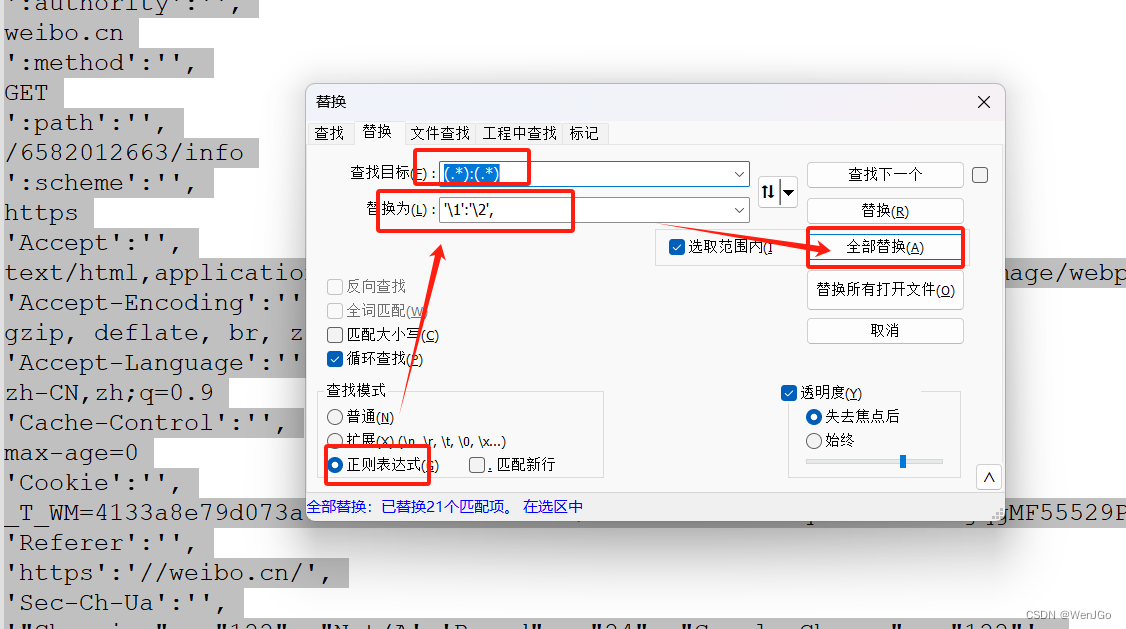
然后一定要注意当前页面的编码格式是utf-8,有些时候可能不是,因此会报错
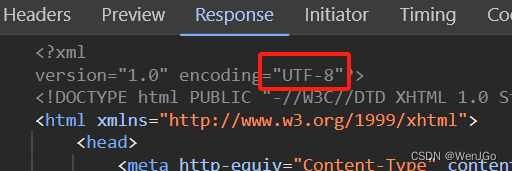
一定要注释掉
这个一定要注释掉,因为页面是utf-8的,但是这里没有 'Accept-Encoding': 'gzip, deflate, br, zstd'
import urllib.request
# 在数据采集的时候需要绕过登录然后进入某个页面
url = 'https://weibo.cn/6582012663/info'
headers = {
# ':authority': 'weibo.cn',
# ':method': 'GET',
# ':path': '/6582012663/info',
# ':scheme': 'https',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
# 这个一定要注释掉,因为页面是utf-8的,但是这里没有
# 'Accept-Encoding': 'gzip, deflate, br, zstd',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
# cookie中携带着登录信息,如果header中包含了登录成功的cookie基本上什么页面都可以进入
'Cookie': '_T_WM=4133a8e79d073a6e4444be1aecb1f5d9; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFjvcLkvsbHBY.bhyLEBkDS5JpX5KzhUgL.Foqf1hz7eKzcSoe2dJLoI7LP9g4GI.peKG.t; MLOGIN=1; SUB=_2A25I5SeKDeRhGeBL41AR8SzKzT-IHXVrmyVCrDV6PUJbktANLW__kW1NRsUK0DVE9PwTPckkLswxXPEQFm1G-kMC; SSOLoginState=1709266906; ALF=1711858906; M_WEIBOCN_PARAMS=luicode%3D20000174',
# referer判断当前路径是否由上一个路径进来的,常用于图片的防盗链
'Referer':'https: //weibo.cn/',
# 'Sec-Ch-Ua-Mobile': '?0',
# 'Sec-Ch-Ua-Platform': '"Windows"',
# 'Sec-Fetch-Dest': 'document',
# 'Sec-Fetch-Mode': 'navigate',
# 'Sec-Fetch-Site': 'same-origin',
# 'Sec-Fetch-User': '?1',
# 'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取数据获取数据
content = response.read().decode('utf-8')
# 将数据保存到本地
fp = open("weibo.html", 'w', encoding='utf-8')
fp.write(content)
cookie 中携带着登录信息,如果header中包含了登录成功的cookie基本上什么页面都可以进入
referer 判断当前路径是否由上一个路径进来的,常用于图片的防盗链
Handler处理器
handler定制更高级的请求头,随着业务逻辑的复杂,请求对象的定制已经满足不了我们的需求(动态cookie和代理不能使用请求对象的定制)
基本使用
其实就是三个单词对应三行代码
(1)handler :
handler = urllib.request.HTTPHandler()
(2)build_opener :
opener = urllib.request.build_opener(handler)
(3)open :
response = opener.open(request)
整体代码如下:
import urllib.request
# 使用handler访问百度获得网页源码
import urllib.request
url = "http://www.baidu.com"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
# handler build_opener open
# 获取handler对象
handler = urllib.request.HTTPHandler()
# 获取opener对象
opener = urllib.request.build_opener(handler)
# 调用open方法
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)
代理服务器
普通代理
1.代理的常用功能?
1.突破自身IP访问限制,访问国外站点。
2.访问一些单位或团体内部资源
扩展:某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
3.提高访问速度
扩展:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲中区中,当其他用户再访问相同的信息时,则直接由缓冲区中取出信息,传给用户,以提高访问速度
4.隐藏真实IP
扩展:上网者也可以通过这种方法隐藏自己的IP,免受攻击,
2.代码配置代理
创建Reugest对象
创建ProxyHandler对象
用handler对象创建opener对象
使用opener.open函数发送请求
import urllib.request
url = "http://www.baidu.com/s?wd=ip"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问服务器
# response = urllib.request.urlopen(request)
# handler build_opener open
# proxies代理ip,以代理的形式存在
proxies = {
'http': '111.13.12.202:80'
}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
# 获取响应信息
content = response.read().decode('utf-8')
# 保存
with open('daili.html', 'w', encoding='utf-8') as fp:
fp.write(content)
代理池
例如这样使用一堆ip分别访问,我这里没有循环的逻辑,大家自己加上就行
import urllib.request
import random
proxies_pool = [
{'http': '111.13.12.202:80'},
{'http': '111.13.12.203:80'},
{'http': '111.13.12.204:80'}
]
proxie = random.choice(proxies_pool)
# print(proxie)
url = "http://www.baidu.com/s?wd=ip"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
handler = urllib.request.ProxyHandler(proxies=proxie)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('daili2.html', 'w', encoding='utf-8') as fp:
fp.write(content)
import urllib.request
import random
proxies_pool = [
{'http': '111.13.12.202:80'},
{'http': '111.13.12.203:80'},
{'http': '111.13.12.204:80'}
]
proxie = random.choice(proxies_pool)
# print(proxie)
url = "http://www.baidu.com/s?wd=ip"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
handler = urllib.request.ProxyHandler(proxies=proxie)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('daili2.html', 'w', encoding='utf-8') as fp:
fp.write(content)
总结
注意headers携带cookie还有为了避免高频次的访问下的被拉黑问题,可以采用代理的模式或者使用代理池来达到目标效果















 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











