






1. 前言
上篇我们已经优化了以下部分:
已优化部分:
1)每次启动服务,都要重新构建知识库向量索引(build_vector_index方法),耗时造成不必要的性能浪费,如果每次只针对新加入的知识库文件做向量索引,只做增量索引,这样就好很多了。
2)embedding有待优化,模型选择,分词器选择怎样才适合?
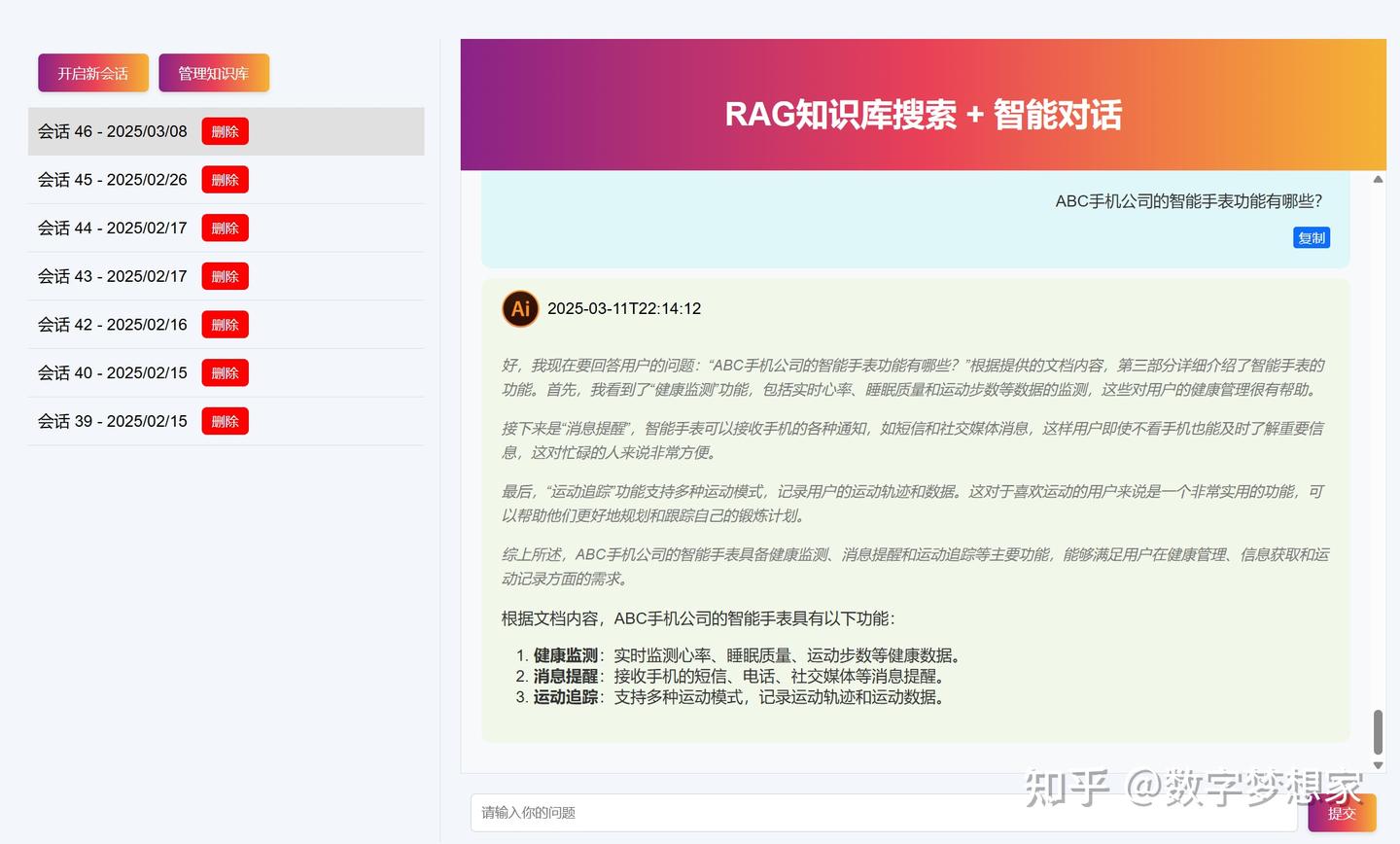
3)打造一个UI界面进行交互,为交付奠定基础
本文为LLM+RAG系列最后一篇,我们将实现会话管理、历史消息的加载与删除、知识库的预览与管理操作。
2. 会话的保存与加载
我们知道,会话就是指用户与AI之间的一轮对话,只要不开始新的聊天,都算做同一个会话。(当然,在实际设计时,需考虑上下文长度,在即将到达LLM上下文上限时就要强制用户开启新的会话,以免造成服务端性能崩溃,一般设置为80%上文长度就自动开启新的会话)。
会话创建与保存策略:
在初次聊天时,服务端会自动生成一个session_id,随后,每次聊天的记录,都会携带这个session_id进行保存。
当用户点击“开启新会话”时,主动调用后端/new_session 方法创建新的会话,前端也会自动将创建后的会话id缓存在浏览器,以供后续对话进行携带。
所以整个过程比较简单,在在上篇文章中,对话方法(generate_answer) 中,已经包含了聊天记录的保存代码。
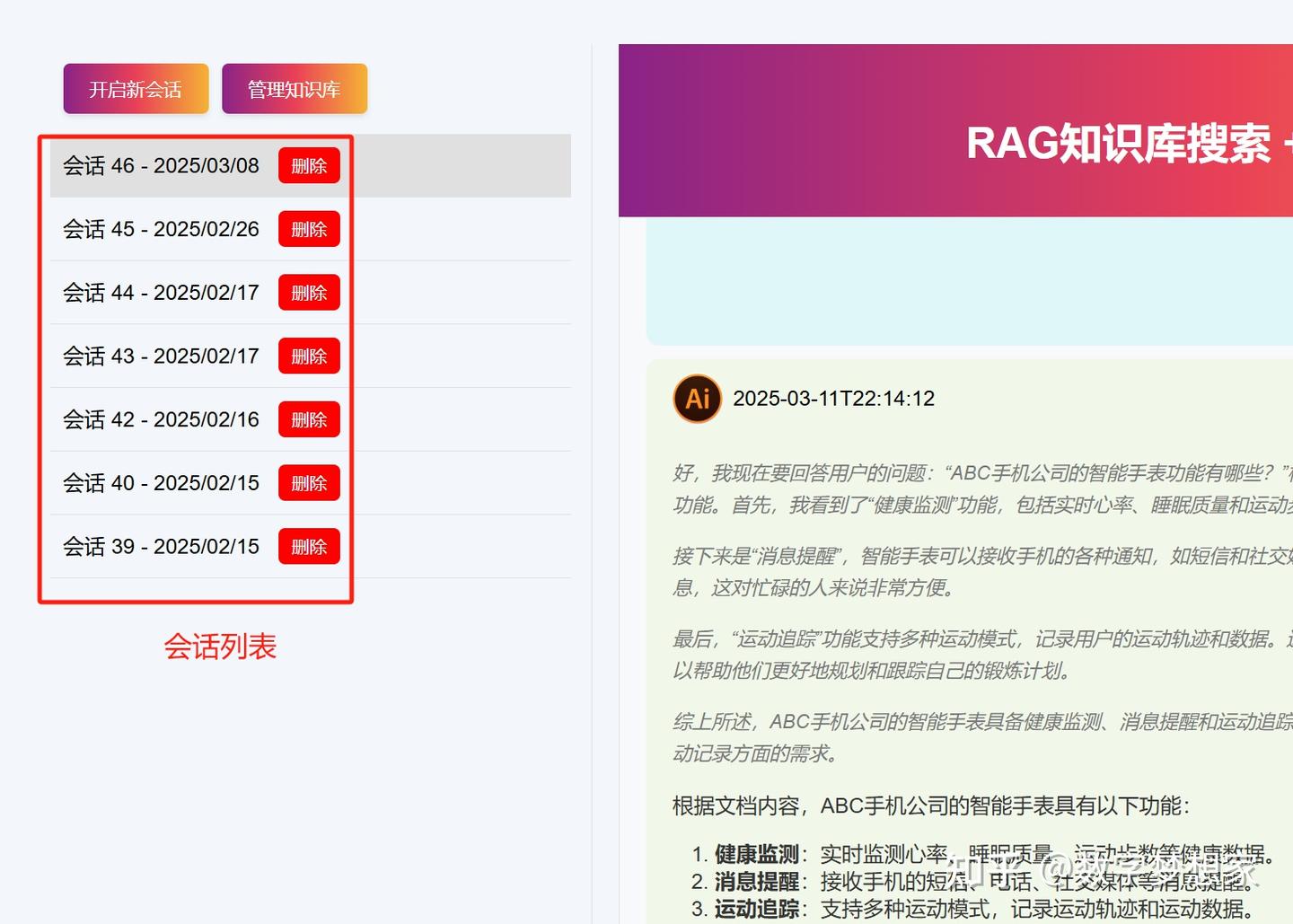
创建与删除会话代码:
@app.post("/new_session")
async def start_new_session(db: Session = Depends(get_db)):
new_session_id = str(uuid.uuid4())
new_session = SessionModelDB(session_id=new_session_id)
db.add(new_session)
db.commit()
db.refresh(new_session)
return {"id": new_session.id}
@app.delete("/delete_session/{session_id}")
async def delete_session(session_id: int, db: Session = Depends(get_db)):
# 查询要删除的会话
session_to_delete = db.query(SessionModelDB).filter(SessionModelDB.id == session_id).first()
# 如果会话不存在,返回 404 错误
if not session_to_delete:
raise HTTPException(status_code=404, detail="会话不存在")
# 删除会话
db.delete(session_to_delete)
db.commit()
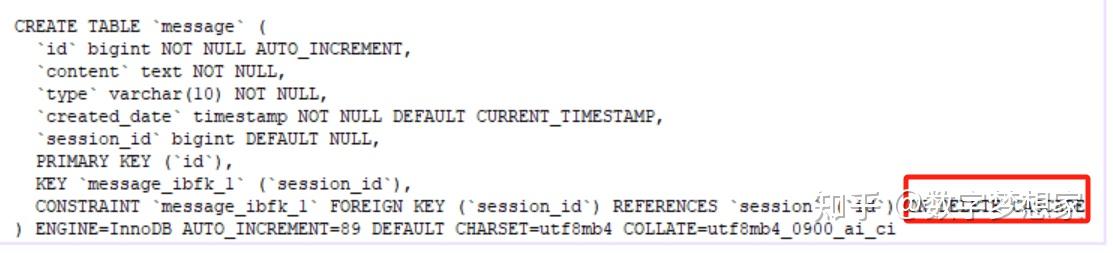
return {"message": "会话删除成功"}3、历史消息的加载与删除
在删除会话的同时,历史消息一并删除。为了代码简洁,保证数据的一致性考虑,在设计消息表时可以直接设置级联删除策略:
4. 知识库的预览与管理
知识库的管理是比较重要的模块,也是可以持续优化的模块,本文仅提供基础的知识库管理思路,后续优化还请大家自行处理和完善。
4.1 知识库文件列表管理
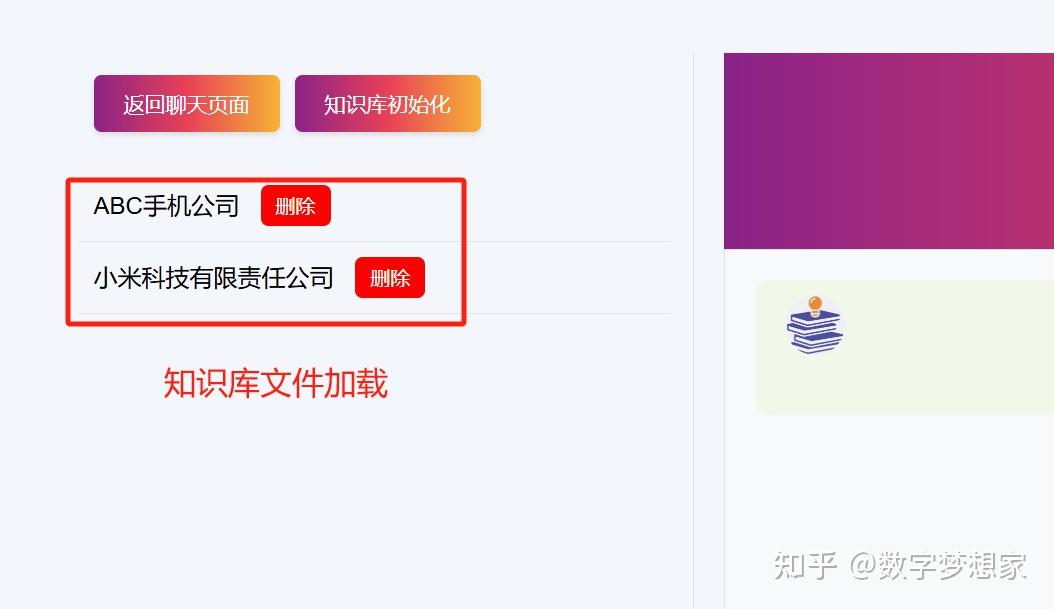
我们只需要通过服务端的list_documents方法即可获得文件列表:
@app.get("/list_documents")
async def list_documents():
documents = []
for root, dirs, files in os.walk(KNOWLEDGE_BASE_DIR):
for file in files:
if file.endswith('.md'): # 只获取 md 文件
file_path = os.path.join(root, file)
company_name = get_company_name_from_md(file_path)
if company_name is not None:
documents.append(company_name )
return {"documents": documents}4.2 知识库文件的预览:
通过服务端接口/get_document_content,加载知识库文件的内容:
@app.get("/get_document_content")
async def get_document_content(file_path: str = Query(..., description="要获取内容的文档名称"),
db: Session = Depends(get_db)):
print("预览的文件===" + file_path)
# 根据文件名从数据库中查询对应的路径
kb_file = db.query(KbFile).filter(KbFile.name == file_path).first()
if not kb_file:
raise HTTPException(status_code=404, detail="文档不存在")
full_path = kb_file.path
if not os.path.exists(full_path):
raise HTTPException(status_code=404, detail="文档不存在")
try:
with open(full_path, 'r', encoding='utf-8') as file:
content = file.read()
return content
except Exception as e:
raise HTTPException(status_code=500, detail=f"读取文档内容出错: {str(e)}")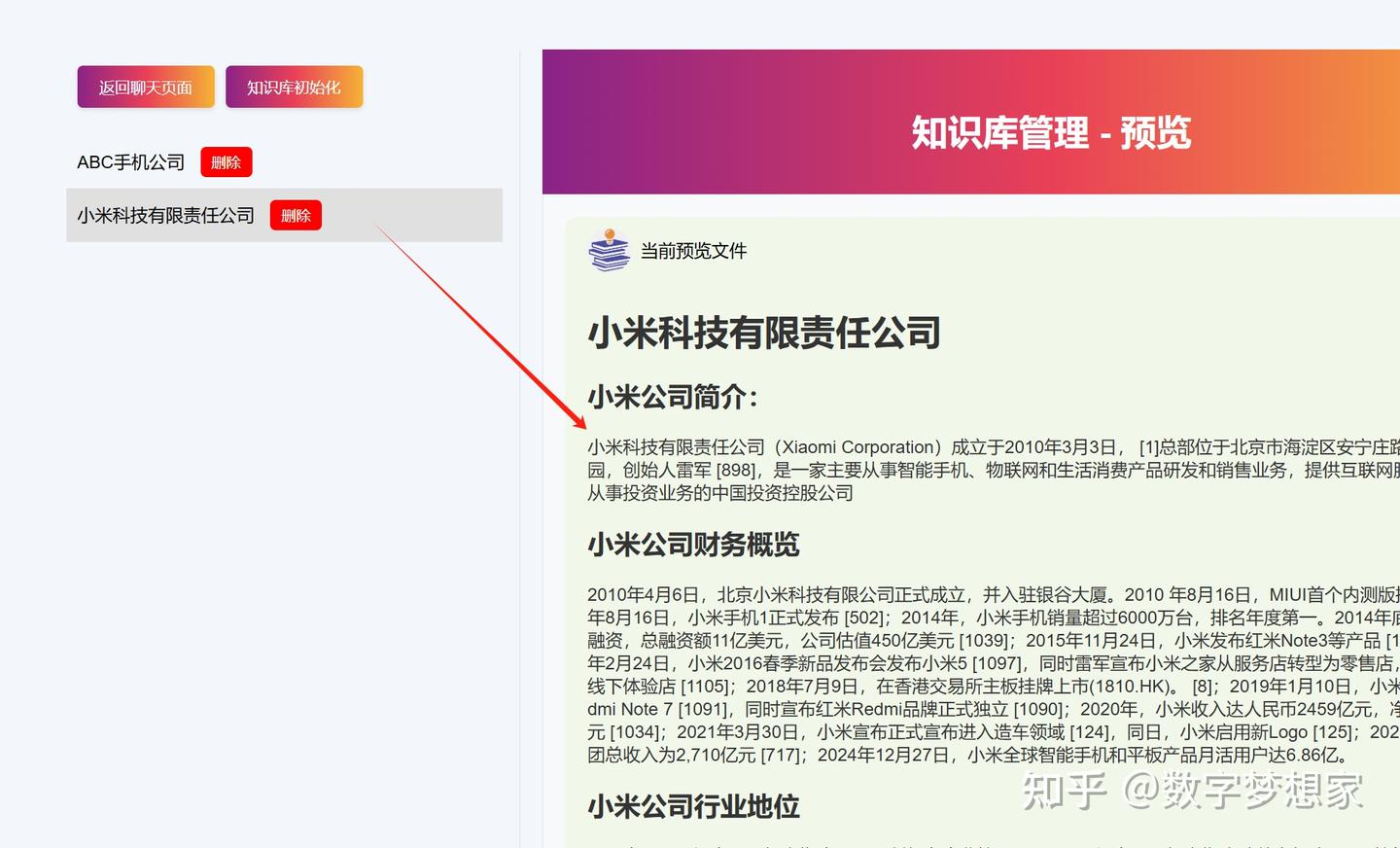
4.3 知识库文件初始化
当我们更新了知识库的内容,或者新增了知识库文件,就需要对知识库重新初始化,重新构建向量索引。
所以我们提供了服务端/kb_init方法:
@app.get("/kb_init")
async def kb_init():
db = SessionLocal()
inserted_kb_files = []
try:
# 清空数据库里的所有 KbFile 记录 - 使用更明确的删除方式
try:
count = db.query(KbFile).delete(synchronize_session='fetch')
db.commit()
logger.info(f"已删除 {count} 条知识库文件记录")
# 验证删除是否成功
remaining = db.query(KbFile).count()
logger.info(f"剩余知识库文件记录数: {remaining}")
if remaining > 0:
logger.warning("数据库记录未完全清空,尝试使用原生SQL")
db.execute(text("DELETE FROM kb_file"))
db.commit()
except Exception as e:
db.rollback()
logger.error(f"删除知识库文件记录失败: {e}")
return {"message": f"知识库文件初始化失败: {e}"}
# 扫描并添加知识库文件到数据库
for root, dirs, files in os.walk(KNOWLEDGE_BASE_DIR):
for file in files:
file_path = os.path.join(root, file)
file_ext = os.path.splitext(file)[1].lower()
if file_ext == '.md':
name = get_company_name_from_md(file_path)
if not name:
name = os.path.splitext(file)[0] # 如果获取第一行失败,使用文件名
else:
name = os.path.splitext(file)[0]
new_kb_file = KbFile(name=name, path=file_path)
db.add(new_kb_file)
inserted_kb_files.append(new_kb_file)
db.commit()
# 重要:强制重建向量索引
# 删除现有的向量索引和文件列表,以便它们被重新创建
if os.path.exists(VECTOR_INDEX_FILE):
os.remove(VECTOR_INDEX_FILE)
if os.path.exists(FILE_LIST_FILE):
os.remove(FILE_LIST_FILE)
# 重新构建向量索引
logger.info("知识库文件更新,正在重建向量索引...")
global docsearch
docsearch = await load_or_build_vector_index(KNOWLEDGE_BASE_DIR)
logger.info("向量索引重建完成")
# 将 SQLAlchemy 对象转换为 Pydantic 模型对象
pydantic_kb_files = [KbFileModel.model_validate(kb_file) for kb_file in inserted_kb_files]
return {
"message": "知识库文件初始化成功",
"inserted_kb_files": pydantic_kb_files
}
except Exception as e:
db.rollback()
logger.error(f"知识库文件初始化失败: {e}")
return {"message": f"知识库文件初始化失败: {e}"}
finally:
db.close()对于重建后的知识库,数据库中会保存新的知识库文件名称、保存路径已经创建时间。
此处可优化的点: 可以给每个文件创建md5码,只有内容发生变更的,才参与重建。这样在知识库文件很多的时候,不用全部从头来过,节约大量索引重建的时间。
至此,一个完整的本地化LLM+RAG知识库搜索应用框架便完成了,在此基础上,大家可以自行扩展和优化。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









