







一、ClickHouse 概述
1.1 什么是ClickHouse
ClickHouse是(战斗民族)俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS)GitHub地址GitHub - ClickHouse/ClickHouse: ClickHouse® is a real-time analytics database management system,使用 C++语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
1.2 什么是列式存储
在传统的行式数据库系统中,数据按如下顺序存储:
| Id | Name | Age |
| 1 | 张三 | 18 |
| 2 | 李四 | 22 |
| 3 | 王五 | 34 |
采用行式存储时,数据在磁盘上的组织结构为:

好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
而采用列式存储时,数据在磁盘上的组织结构为:

这时想查所有人的年龄只需把年龄那一列拿出来就可以了。
1.3Clickhouse的SQL引擎和向量化
支持SQL
ClickHouse支持基于SQL的声明式查询语言,该语言大部分情况下是与SQL标准兼容的。 支持的查询包括 GROUP BY,ORDER BY,IN,JOIN以及非相关子查询。 不支持窗口函数和相关子查询。
向量引擎
为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU。
二、为什么使用ClickHouse
2.1特性
2.1.1 DBMS 的功能
几乎覆盖了标准 SQL 的大部分语法,包括 DDL 和 DML,以及配套的各种函数,用户管
理及权限管理,数据的备份与恢复。
2.1.2 多样化引擎
ClickHouse 和 MySQL 类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同
的存储引擎。目前包括合并树、日志、接口和其他四大类 20 多种引擎。
2.1.3 高吞吐写入能力
ClickHouse 采用类 LSM Tree的结构,数据写入后定期在后台 Compaction。通过类 LSM tree
的结构,ClickHouse 在数据导入时全部是顺序 append 写,写入后数据段不可更改,在后台
compaction 时也是多个段 merge sort 后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞
吐能力,即便在 HDD 上也有着优异的写入性能。
官方公开 benchmark 测试显示能够达到 50MB-200MB/s 的写入吞吐能力,按照每行
100Byte 估算,大约相当于 50W-200W 条/s 的写入速度。
2.1.4 数据分区与线程级并行
ClickHouse 将数据划分为多个 partition,每个 partition 再进一步划分为多个 index
granularity(索引粒度),然后通过多个 CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条 Query 就能利用整机所有 CPU。极致的并行处理能力,极大的降低了查
询延时。
所以,ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端
就是对于单条查询使用多 cpu,就不利于同时并发多条查询。所以对于高 qps(每秒钟的查询次数) 的查询业务, ClickHouse 并不是强项。
功能丰富:
- 友好的SQL:ClickHouse具有用户友好的SQL查询,并具有许多内置分析功能。除了大多数DBMS中可以找到的常用功能外,ClickHouse还提供了许多特定的功能。
- 高效管理非规范化数据:ClickHouse的面向列性质允许每个表具有数百或数千列,而不会减慢SELECT查询的速度。通过利用广泛的数据组织选项,例如数组,元组和嵌套数据结构,可以打包更多数据。
- 连接分布式或共置数据:ClickHouse提供了用于联接表的各种选项。联接既可以是本地群集,也可以访问存储在外部系统中的数据。还有一个外部字典支持,它提供了另一种更简单的语法,用于从外部源访问数据。
- 近似查询处理:用户可以控制结果准确性和查询执行时间之间的权衡,这在处理多个TB或PB的数据时非常方便。 ClickHouse还提供了概率数据结构,可快速有效地计算基数和分位数
可靠:
- ClickHouse一直在管理PB级数据,这些数据为俄罗斯领先的搜索提供商,欧洲最大的IT公司之一Yandex的大量高负载大众受众服务提供服务。自2012年以来,ClickHouse一直为公司的网络分析服务,比较电子商务平台,公共电子邮件服务,在线广告平台,商业智能工具和基础架构监视提供强大的数据库管理。
- ClickHouse可以配置为位于独立节点上的纯分布式系统,而没有任何单点故障。
- 软件和硬件故障或配置错误不会导致数据丢失。 ClickHouse不会删除“损坏的”数据,而是将其保存或询问您在启动前该怎么做。每次对磁盘或网络进行读取或写入之前,所有数据均经过校验和。几乎不可能意外删除数据,因为即使存在人为错误,也有保护措施。
- ClickHouse提供了对查询复杂性和资源使用情况的灵活限制,可以通过设置对其进行微调。可以同时为多个高优先级低延迟请求和一些具有后台优先级的长时间运行的查询提供服务。
何时使用ClickHouse:
用于分析结构良好且不可变的事件或日志流,建议将每个此类流放入具有预连接维度的单个宽表中。
何时不使用ClickHouse:
不适合事务性工作负载(OLTP)、高价值的键值请求、Blob或文档存储。
性能感人,来自官网截图(相对查询处理时间,越低越好):
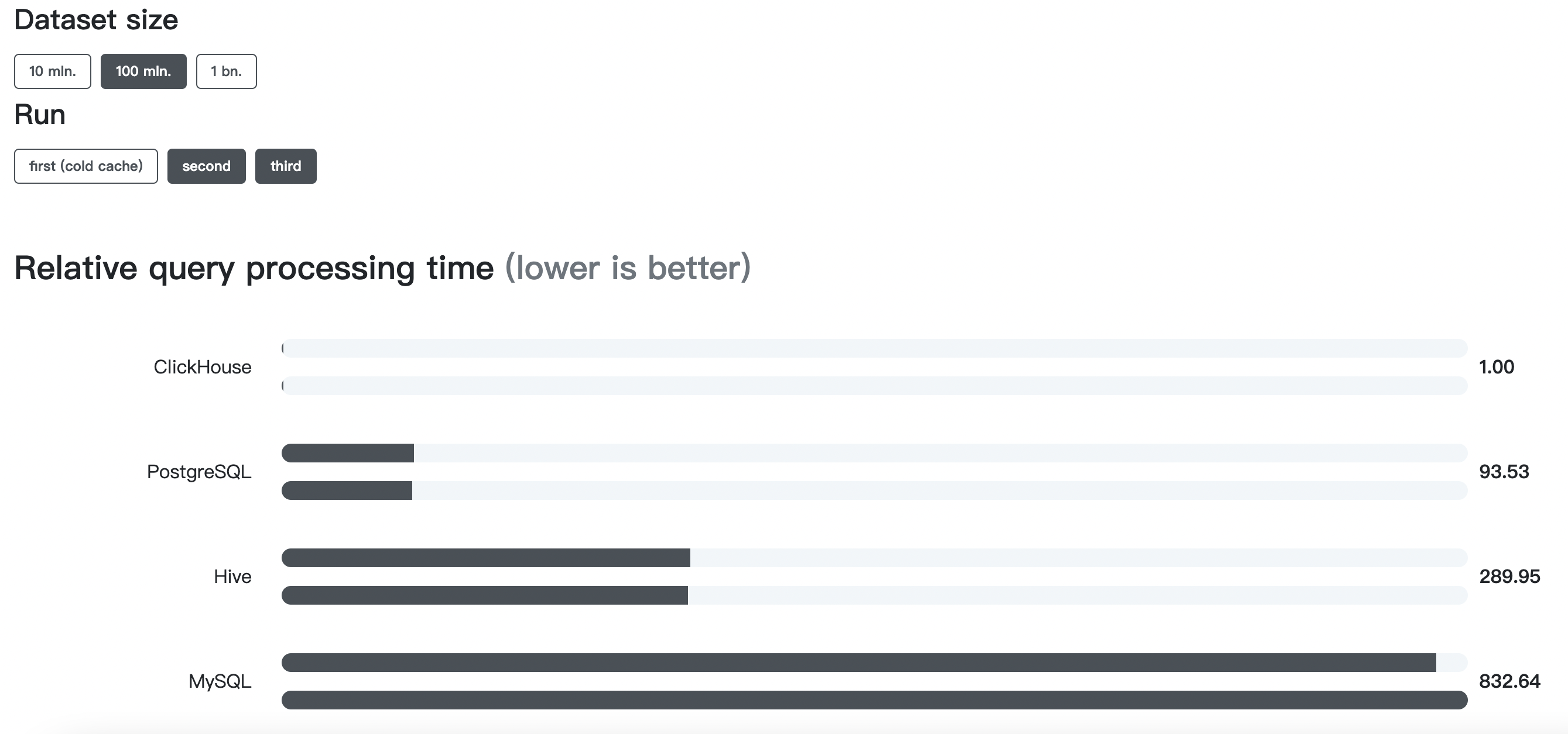
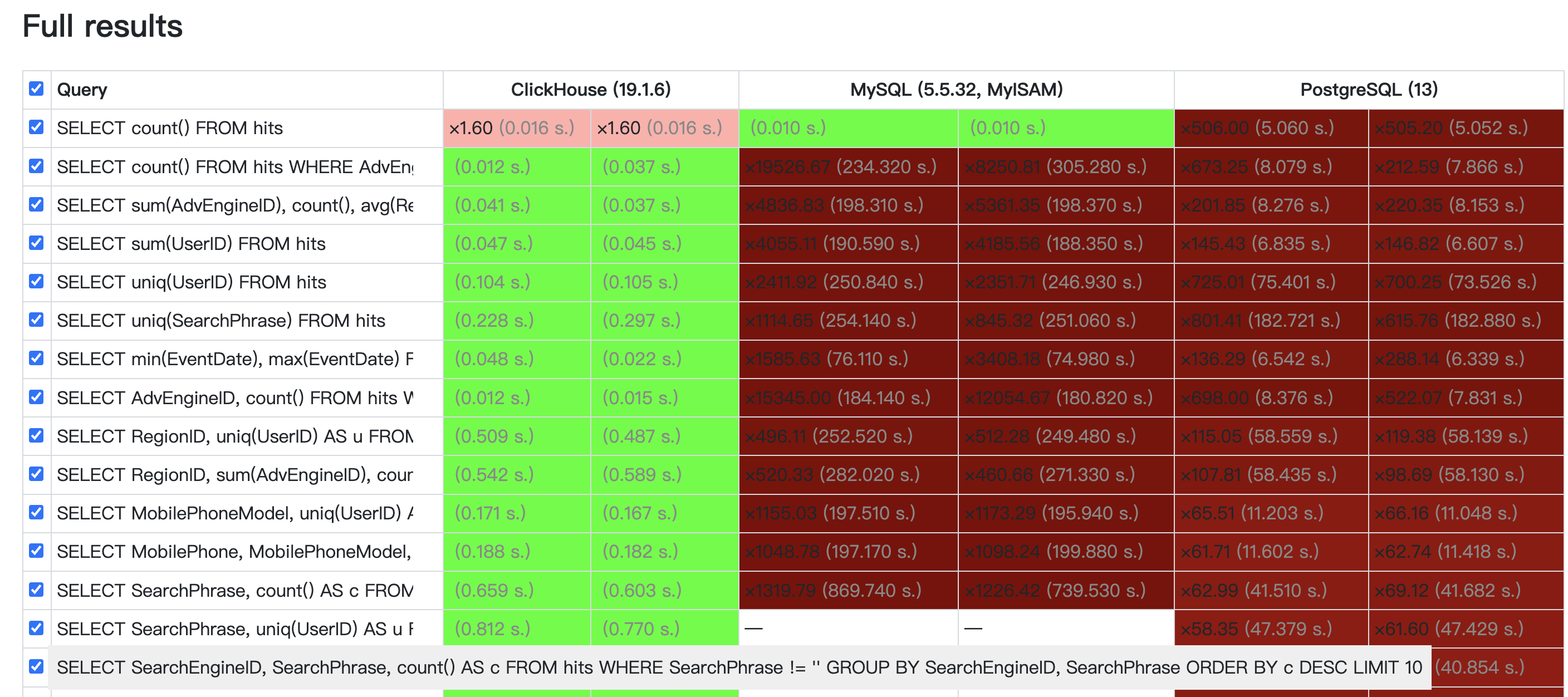
Most results are for single server setup with the following configuration: two socket Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz; 128 GiB RAM; md RAID-5 on 8 6TB SATA HDD; ext4.
Some additional results (marked as x2, x3, x6) are for clustered setup for comparison. These results are contributed from independent teams and hardware specification may differ.
三、快速开始
ClickHouse 可以在任何具有 x86_64、AArch64 或 PowerPC64LE CPU 架构的 Linux、FreeBSD 或 Mac OS X 上运行。
3.1 选择Tgz安装包安装
下载地址:https://packages.clickhouse.com/tgz/stable/
第一种方式:
(Linux x86架构)
选择stable目录下的安装包,采用22.3.22版本,分别是:
clickhouse-client-22.3.2.2.tgz
clickhouse-common-static-22.3.2.2.tgz
clickhouse-common-static-dbg-22.3.2.2.tgz
clickhouse-server-22.3.2.2.tgz
3.2 解压安装
依次将这四个安装包解压,并且每解压一个,执行一下解压文件夹下的install下的doinst.sh脚本
解压顺序:
clickhouse-client-22.3.2.2.tgz
clickhouse-common-static-22.3.2.2.tgz
clickhouse-common-static-dbg-22.3.2.2.tgz
clickhouse-server-22.3.2.2.tgz ------------------------------------------------------------
# 解压
tar -zxvf clickhouse-common-static-22.3.2.2.tgz
cd clickhouse-common-static-22.3.2.2/install/
# 运行doinst.sh
./doinst.sh
------------------------------------------------------------
tar -zxvf clickhouse-common-static-dbg-22.3.2.2.tgz
./clickhouse-common-static-dbg-22.3.2.2/install/doinst.sh
------------------------------------------------------------
tar -zxvf clickhouse-server-22.3.2.2.tgz
./clickhouse-server-22.3.2.2/install/doinst.sh
------------------------------------------------------------
tar -zxvf clickhouse-client-22.3.2.2.tgz
./clickhouse-client-22.3.2.2/install/doinst.sh
------------------------------------------------------------(注意⚠️)在解压clickhouse-server-22.3.2.2.tgz并运行./clickhouse-server-22.3.2.2/install/doinst.sh
后,clickhouse会默认创建一个default的用户,设置密码,如果不设置密码可以按回车
3.3 启动
#查看命令
clickhouse --help
#启动
clickhouse start 连接clickhouse
clickhouse-client
## -m 支持多行语句
clickhouse-client -m3.4 clickhosue相关目录
-------------------------------------------
# 命令目录
/usr/bin
ll |grep clickhouse
-------------------------------------------
# 配置文件目录
cd /etc/clickhouse-server/
-------------------------------------------
# 日志目录
cd /var/log/clickhouse-server/
-------------------------------------------
# 数据文件目录
cd /var/lib/clickhouse/
-------------------------------------------3.5 允许远程访问
cd /etc/clickhouse-server/
vim config.xml把listen 注释打开
强行保存wq!
clickhouse restart在浏览器输入服务器ip+8123验证一下
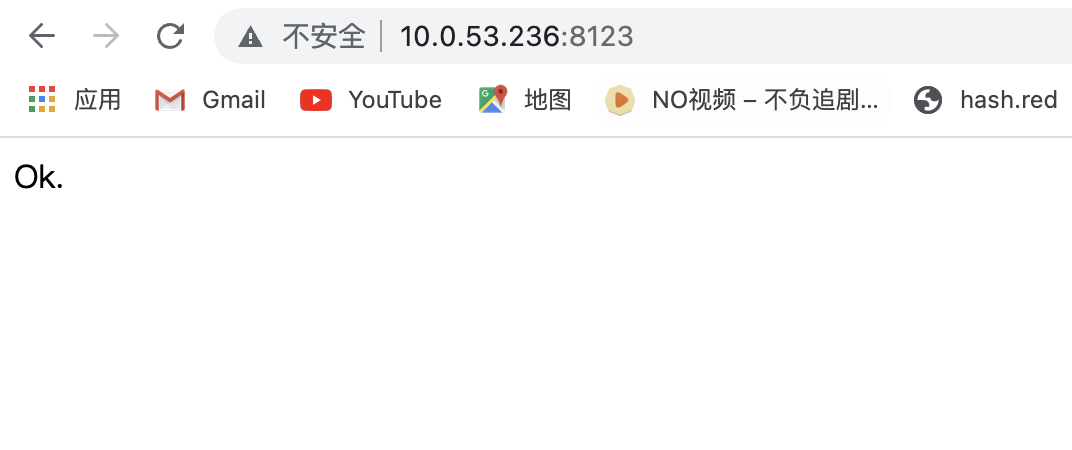
这样就可以远程访问了!
四、ClickHouse的基本使用
4.1 数据类型
4.1.1 整型
固定长度的整型,包括有符号整型或无符号整型。
整型范围(-2n-1~2n-1-1):
Int8 - [-128 : 127]
Int16 - [-32768 : 32767]
Int32 - [-2147483648 : 2147483647]
Int64 - [-9223372036854775808 : 9223372036854775807]
无符号整型范围(0~2n-1):
UInt8 - [0 : 255]
UInt16 - [0 : 65535]
UInt32 - [0 : 4294967295]
UInt64 - [0 : 18446744073709551615]
使用场景: 个数、数量、也可以存储型 id。 3.2 浮点型
Float32 - float
Float64 – double
建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫
秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。
使用场景:一般数据值比较小,不涉及大量的统计计算,精度要求不高的时候。比如
保存商品的重量。
4.1.2 布尔型
没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
4.1.3 Decimal 型
有符号的浮点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)。
有三种声明:
Decimal32(s),相当于 Decimal(9-s,s),有效位数为 1~9
Decimal64(s),相当于 Decimal(18-s,s),有效位数为 1~18
Decimal128(s),相当于 Decimal(38-s,s),有效位数为 1~38
s 标识小数位
使用场景: 一般金额字段、汇率、利率等字段为了保证小数点精度,都使用 Decimal
进行存储。
3.5 字符串
1)String
字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
2)FixedString(N)
固定长度 N 的字符串,N 必须是严格的正自然数。当服务端读取长度小于 N 的字符
串时候,通过在字符串末尾添加空字节来达到 N 字节长度。 当服务端读取长度大于 N 的
字符串时候,将返回错误消息。
与 String 相比,极少会使用 FixedString,因为使用起来不是很方便。
使用场景:名称、文字描述、字符型编码。 固定长度的可以保存一些定长的内容,比
如一些编码,性别等但是考虑到一定的变化风险,带来收益不够明显,所以定长字符串使用
意义有限。
4.1.4 枚举类型
包括 Enum8 和 Enum16 类型。Enum 保存 'string'= integer 的对应关系。
Enum8 用 'String'= Int8 对描述。
Enum16 用 'String'= Int16 对描述。
1)用法演示
创建一个带有一个枚举 Enum8('hello' = 1, 'world' = 2) 类型的列
CREATE TABLE t_enum
(
x Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog; 2)这个 x 列只能存储类型定义中列出的值:'hello'或'world'
INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello');3)如果尝试保存任何其他值,ClickHouse 抛出异常
insert into t_enum values('a')4)如果需要看到对应行的数值,则必须将 Enum 值转换为整数类型
SELECT CAST(x, 'Int8') FROM t_enum;实际使用中往往因为一些数据内容的变化增加一定的维护成本,甚至是数据丢失问题。所以谨
慎使用。
4.1.5 时间类型
目前 ClickHouse 有三种时间类型
Date 接受年-月-日的字符串比如 ‘2019-12-16’
Datetime 接受年-月-日 时:分:秒的字符串比如 ‘2019-12-16 20:50:10’
Datetime64 接受年-月-日 时:分:秒.亚秒的字符串比如‘2019-12-16 20:50:10.66’
日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值。
还有很多数据结构,可以参考官方文档:ClickHouse中的数据类型 | ClickHouse Docs
4.1.6 数组
Array(T):由 T 类型元素组成的数组。
T 可以是任意类型,包含数组类型。 但不推荐使用多维数组,ClickHouse 对多维数组
的支持有限。例如,不能在 MergeTree 表中存储多维数组。
(1)创建数组方式 1,使用 array 函数
SELECT array(1, 2) AS x, toTypeName(x) ;4.2 表引擎
表引擎是 ClickHouse 的一大特色。可以说, 表引擎决定了如何存储表的数据。包括:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据。 (/var/lib/clickhouse/)
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
- 表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关
- 参数。
特别注意:引擎的名称大小写敏感
4.2 .1 TinyLog (日志)
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表,
生产环境上作用有限。可以用于平时练习测试用。
如:
create table t_tinylog ( id String, name String) engine=TinyLog;4.2 .2 Memory (内存)
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。
读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过 10G/s)。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太
大(上限大概 1 亿行)的场景。
4.2.3 MergeTree (合并树)⭐️
ClickHouse 中最强大的表引擎当属 MergeTree(合并树)引擎及该系列(*MergeTree)
中的其他引擎,支持索引和分区,地位可以相当于 innodb 之于 Mysql。而且基于 MergeTree,
还衍生除了很多小弟,也是非常有特色的引擎。
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);insert into t_order_mt values
(101,'sku_001',1000.00,'2022-08-01 12:00:00') ,
(102,'sku_002',2000.00,'2022-08-01 11:00:00'),
(102,'sku_004',2500.00,'2022-08-01 12:00:00'),
(102,'sku_002',2000.00,'2022-08-01 13:00:00'),
(102,'sku_002',12000.00,'2022-08-01 13:00:00'),
(102,'sku_002',600.00,'2022-08-02 12:00:00');MergeTree 其实还有很多参数(绝大多数用默认值即可),但是三个参数是更加重要的,
也涉及了关于 MergeTree 的很多概念。
A)partition by 分区(可选)
1)作用
用过 hive 的应该都不陌生,分区的目的主要是降低扫描的范围,优化查询速度
2)如果不填
只会使用一个分区。
3)分区目录
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文
件就会保存到不同的分区目录中。
4)并行
分区后,面对涉及跨分区的查询统计,ClickHouse 会以分区为单位并行处理。
5)数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入
后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作(等不及也可以手动
通过 optimize 执行),把临时分区的数据,合并到已有分区中。
optimize table xxxx final;B)primary key 主键(可选)
ClickHouse 中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不
是唯一约束。这就意味着是可以存在相同 primary key 的数据的。
主键的设定主要依据是查询语句中的 where 条件。
根据条件通过对主键进行某种形式的二分查找,能够定位到对应的 index granularity,避
免了全表扫描。
index granularity: 直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数
据的间隔。ClickHouse 中的 MergeTree 默认是 8192。官方不建议修改这个值,除非该列存在
大量重复值,比如在一个分区中几万行才有一个不同数据。
稀疏索引:
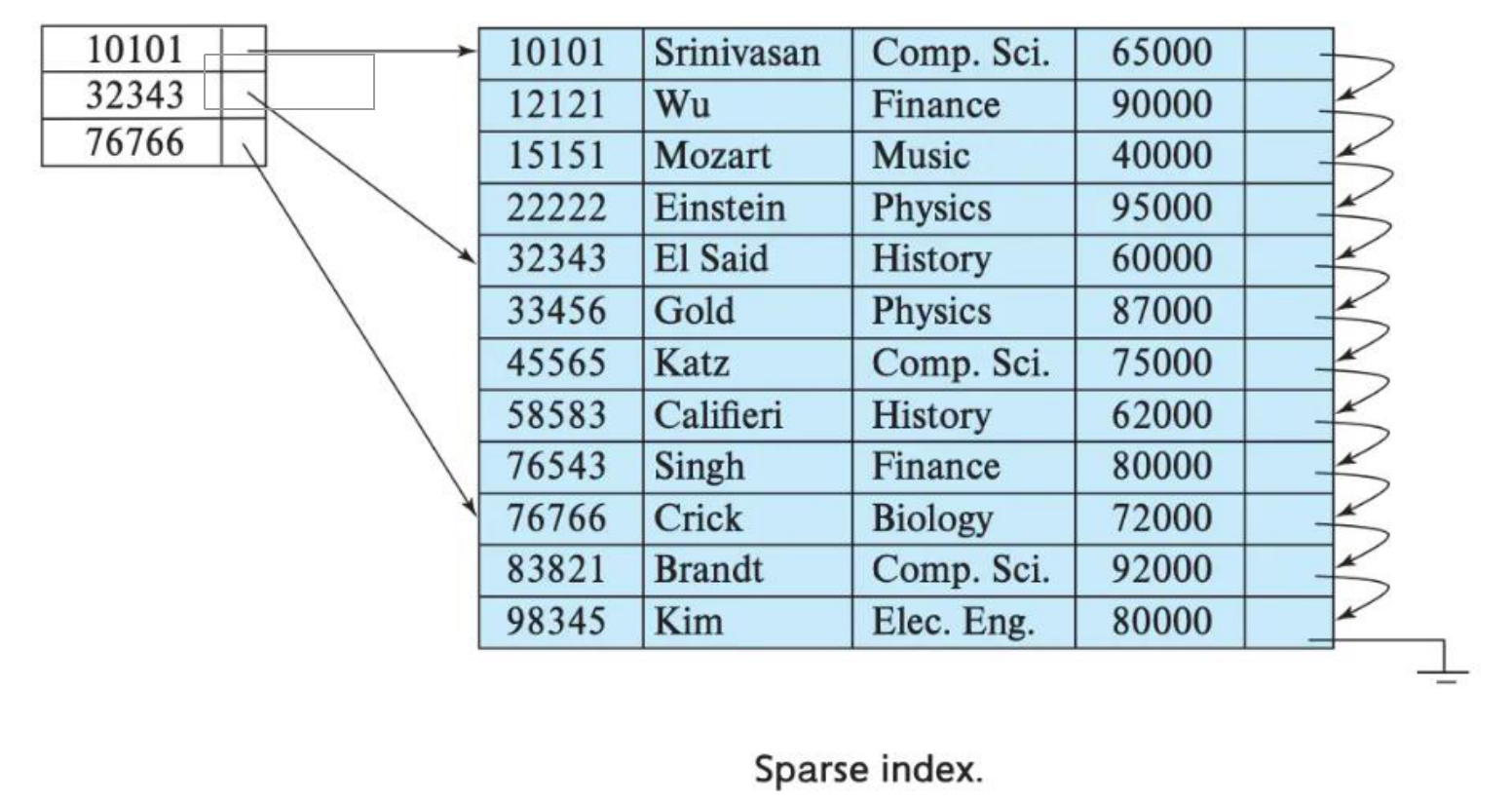
引粒度的第一行,然后再进行进行一点扫描。
C) order by(必选)
order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by 是 MergeTree 中唯一一个必填项,甚至比 primary key 还重要,因为当用户不
设置主键的情况,很多处理会依照 order by 的字段进行处理(比如后面会讲的去重和汇总)。
要求:主键必须是 order by 字段的前缀字段。
比如 order by 字段是 (id,sku_id) 那么主键必须是 id 或者(id,sku_id)
D)二级索引
create table t_order_mt2(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime,
INDEX a total_amount TYPE minmax GRANULARITY 5
)
engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);其中 GRANULARITY N 是设定二级索引对于一级索引粒度的粒度。
insert into t_order_mt2 values
(101,'sku_001',1000.00,'2022-08-01 12:00:00') ,
(102,'sku_002',2000.00,'2022-08-01 11:00:00'),
(102,'sku_004',2500.00,'2022-08-01 12:00:00'),
(102,'sku_002',2000.00,'2022-08-01 13:00:00'),
(102,'sku_002',12000.00,'2022-08-01 13:00:00'),
(102,'sku_002',600.00,'2022-08-02 12:00:00');那么在使用下面语句进行测试,可以看出二级索引能够为非主键字段的查询发挥作用
E) 数据 TTL
TTL 即 Time To Live,MergeTree 提供了可以管理数据表或者列的生命周期的功能。
1)列级别 TTL
create table t_order_mt3(
id UInt32,
sku_id String,
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);(2)插入数据(注意:根据实际时间改变)
insert into t_order_mt3 values
(106,'sku_001',1000.00,'2022-08-01 22:52:30'),
(107,'sku_002',2000.00,'2022-08-01 22:52:30'),
(110,'sku_003',600.00,'2022-08-02 12:00:00');(3)手动合并,查看效果 到期后,指定的字段数据归 0
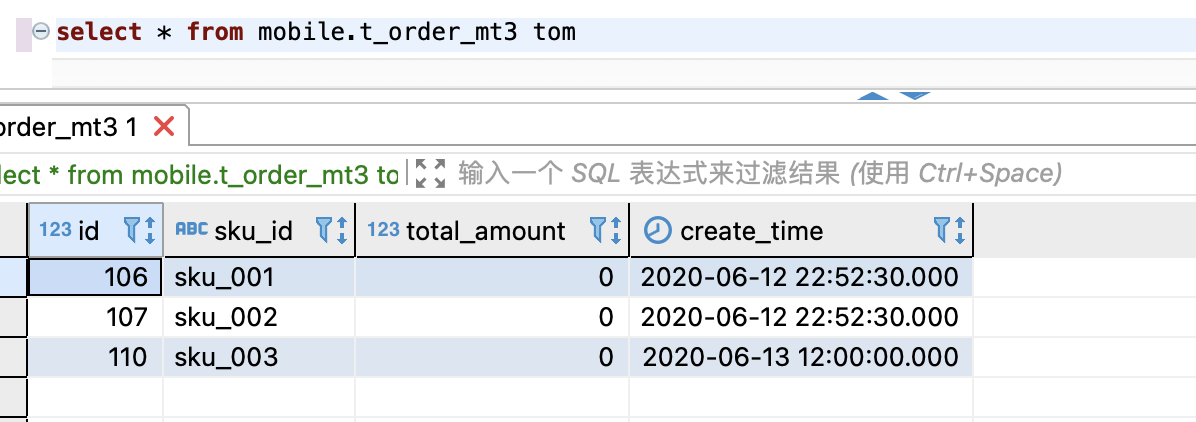
2)表级 TTL
下面的这条语句是数据会在 create_time 之后 10 秒丢失
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND; 涉及判断的字段必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
能够使用的时间周期:
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER
- YEAR
4.2.4 ReplacingMergeTree
ReplacingMergeTree 是 MergeTree 的一个变种,它存储特性完全继承 MergeTree,只是
多了一个去重的功能。 尽管 MergeTree 可以设置主键,但是 primary key 其实没有唯一约束
的功能。如果你想处理掉重复的数据,可以借助这个 ReplacingMergeTree。
1)去重时机
数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预
先作出计划。有一些数据可能仍未被处理。
4.2.5 SummingMergeTree
对于不查询明细,只关心以维度进行汇总聚合结果的场景。如果只使用普通的MergeTree
的话,无论是存储空间的开销,还是查询时临时聚合的开销都比较大。
ClickHouse 为了这种场景,提供了一种能够“预聚合”的引擎 SummingMergeTree
更多引擎了解请关注 表引擎 | ClickHouse Docs
4.3 clickhouse的简单操作
ClickHouse 支持有限的 SQL 操作,SQL 语法和传统的关系型数据库有相似之处。下面简单介绍下 ClickHouse 基础语法:
clickhouse-clientCREATE DATABASE test(创建数据库为test)成功是这样的:
Query id: c17cbf32-ab8c-45a0-8ebb-a7b0bdb88efe
Ok.
0 rows in set. Elapsed: 0.015 sec.
create table t1 (id Int32,name String) engine=TinyLog;查看表
show tables;表结果是这样的
┌─name─┐
│ t1 │
└──────┘
1 rows in set. Elapsed: 0.007 sec.
TinyLog是最简单的表的引擎,用于将数据存储在磁盘上,常用于小表。
insert into t1 (id, name) values (1, 'abc'), (2, 'bbbb'),(3,'sdfg');再查看:
select * from t1;结果为:
┌─id─┬─name─┐
│ 1 │ abc │
│ 2 │ bbbb │
│ 3 │ sdfg │
└────┴──────┘
3 rows in set. Elapsed: 0.002 sec. 4.4 springboot 整合 clickhouse使用
- 正餐来临前,先来看看JAVA如何与ClickHouse交互的
------------------------------优雅的分割线-Start-------------------------------
PS.1 使用 JDBC 将应用程序连接到 ClickHouse
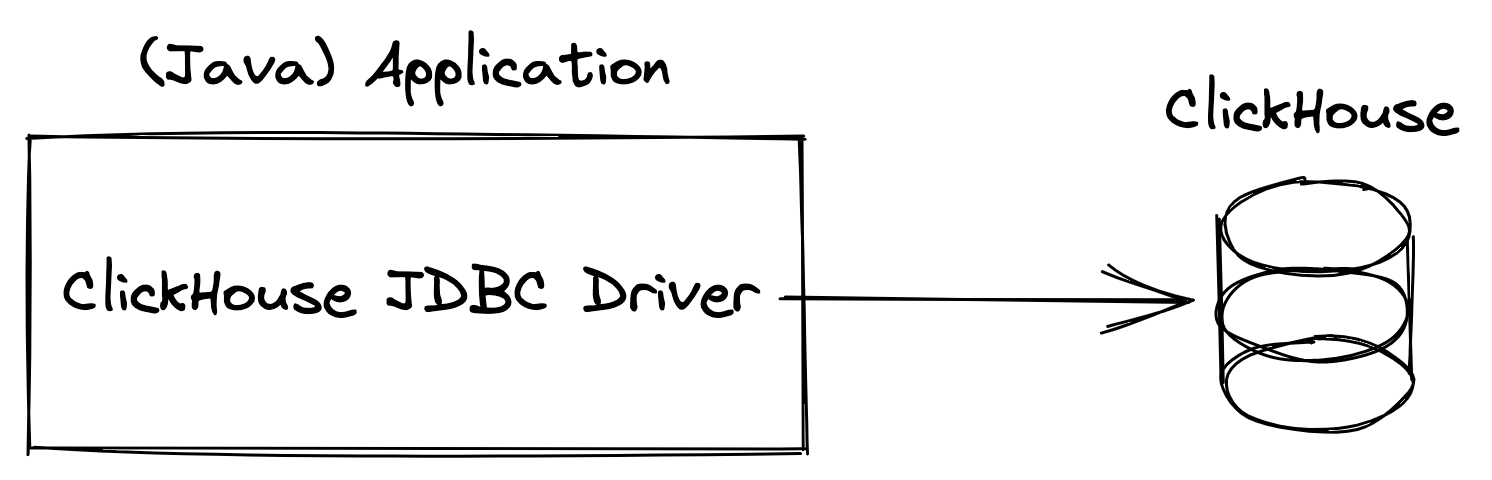
先决条件
您可以访问具有以下功能的机器:
们从连接到安装了 Java 的机器上的 Unix shell 开始,并为我们的最小 Java 应用程序创建一个项目目录(您可以随意命名文件夹,并将其放在任何您喜欢的位置):
mkdir ~/hello-clickhouse-java-app现在我们将当前版本的 ClickHouse JDBC 驱动程序下载到项目目录的子文件夹中:
cd ~/hello-clickhouse-java-app
mkdir lib
wget -P lib https://repo1.maven.org/maven2/com/clickhouse/clickhouse-jdbc/0.3.2-patch7/clickhouse-jdbc-0.3.2-patch7-shaded.jar接下来,我们在子目录结构中为最小 Java 应用程序的 Java 主类创建一个文件:
cd ~/hello-clickhouse-java-app
mkdir -p src/main/java/helloclickhouse
touch src/main/java/helloclickhouse/HelloClickHouse.java现在可以将以下 Java 代码复制并粘贴到文件中~/hello-clickhouse-java-app/src/main/java/helloclickhouse/HelloClickHouse.java:
import com.clickhouse.jdbc.*;
import java.sql.*;
import java.util.*;
public class HelloClickHouse {
public static void main(String[] args) throws Exception {
String url = "jdbc:ch://<host>:<port>";
Properties properties = new Properties();
// properties.setProperty("ssl", "true");
// properties.setProperty("sslmode", "NONE"); // NONE to trust all servers; STRICT for trusted only
ClickHouseDataSource dataSource = new ClickHouseDataSource(url, properties);
try (Connection connection = dataSource.getConnection(<username>, <password>);
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("select * from system.tables limit 10")) {
ResultSetMetaData resultSetMetaData = resultSet.getMetaData();
int columns = resultSetMetaData.getColumnCount();
while (resultSet.next()) {
for (int c = 1; c <= columns; c++) {
System.out.print(resultSetMetaData.getColumnName(c) + ":" + resultSet.getString(c) + (c < columns ? ", " : "\n"));
}
}
}
}
}在上面的Java类文件中
- 在 main 方法内的第一行代码中,您需要替换<host>,并<port>使用与您正在运行的 ClickHouse 实例匹配的值,例如"jdbc:ch://localhost:8123"
- 您还需要用 ClickHouse 实例凭据替换<username>和<password>,如果您不使用密码,则可以替换<password>为null
现在我们准备从 Unix shell 启动我们最小的 Java 应用程序:
cd ~/hello-clickhouse-java-app
java -classpath lib/clickhouse-jdbc-0.3.2-patch7-shaded.jar src/main/java/helloclickhouse/HelloClickHouse.java-------------------------------优雅的分割线-END-------------------------------
4.4.1.clickhouse应用场景:
应用场景:
1.绝大多数请求都是用于读访问的
2.数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
3.数据只是添加到数据库,没有必要修改
4.读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
5.表很“宽”,即表中包含大量的列
6.查询频率相对较低(通常每台服务器每秒查询数百次或更少)
7.对于简单查询,允许大约50毫秒的延迟
8.列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
9.在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
10.不需要事务
11.数据一致性要求较低
12.每次查询中只会查询一个大表。除了一个大表,其余都是小表
13.查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小4.4.2 项目应用
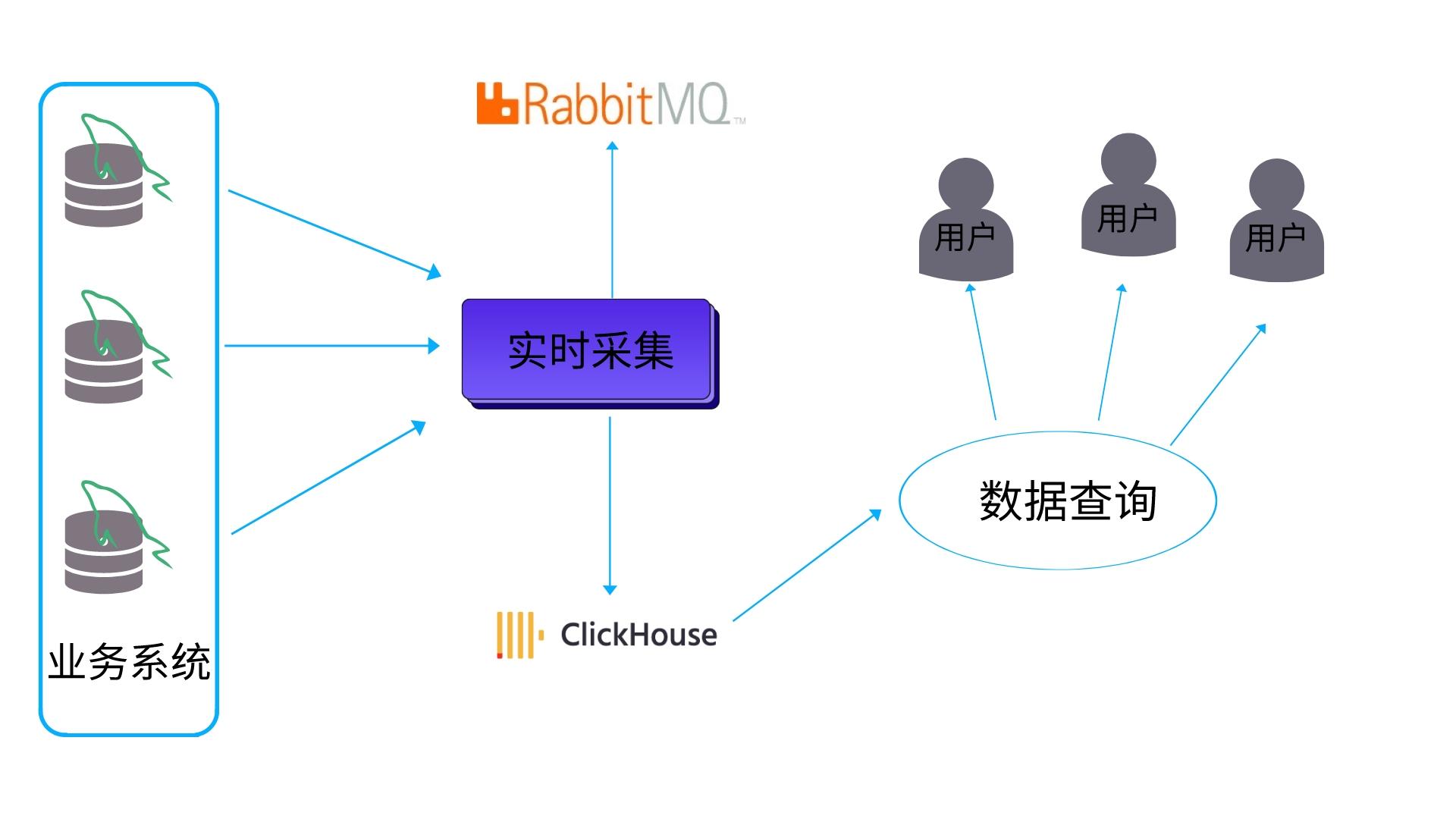
4.4.3.整合springboot
依赖(mybatis plus做持久层,druid做数据源):
<!-- https://mvnrepository.com/artifact/ru.yandex.clickhouse/clickhouse-jdbc -->
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.2</version>
</dependency>
<!-- Druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.4</version>
</dependency>
<!-- mybatis-plus依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.2.0</version>
</dependency>spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
click:
driverClassName: ru.yandex.clickhouse.ClickHouseDriver
url: jdbc:clickhouse://xx.xx.xx.xx:8123/default
username: default
password: 123456
initialSize: 10
maxActive: 100
minIdle: 10
maxWait: 6000
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
cache-enabled: true
lazy-loading-enabled: true
multiple-result-sets-enabled: true
use-generated-keys: true
default-statement-timeout: 60
default-fetch-size: 100
type-aliases-package: com.xrj.clickhouse.pojo
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.Resource;
import javax.sql.DataSource;
@Configuration
public class DruidConfig {
@Resource
private JdbcParamConfig jdbcParamConfig ;
@Bean
public DataSource dataSource() {
DruidDataSource datasource = new DruidDataSource();
datasource.setUrl(jdbcParamConfig.getUrl());
datasource.setDriverClassName(jdbcParamConfig.getDriverClassName());
datasource.setInitialSize(jdbcParamConfig.getInitialSize());
datasource.setMinIdle(jdbcParamConfig.getMinIdle());
datasource.setMaxActive(jdbcParamConfig.getMaxActive());
datasource.setMaxWait(jdbcParamConfig.getMaxWait());
datasource.setUsername(jdbcParamConfig.getUsername());
datasource.setPassword(jdbcParamConfig.getPassword());
return datasource;
}
}
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Data
@Component
@ConfigurationProperties(prefix = "spring.datasource.click")
public class JdbcParamConfig {
private String driverClassName ;
private String url ;
private String username ;
private String password ;
private Integer initialSize ;
private Integer maxActive ;
private Integer minIdle ;
private Integer maxWait ;
}接下来配置实体类,mapper,service,controlle以及mapper.xml。与mybatisplus操作mysql一样的思路。
@Data
public class UserInfo implements Serializable {
private static final long serialVersionUID = 1L;
private int id;
private String userName;
private String passWord;
private String phone;
private String email;
private String createDay;
}@Repository
public interface UserInfoMapper extends BaseMapper<UserInfo> {
// 写入数据
void saveData (UserInfo userInfo) ;
// ID 查询
UserInfo selectById (@Param("id") Integer id) ;
// 查询全部
List<UserInfo> selectList () ;
}public interface UserInfoService extends IService<UserInfo> {
// 写入数据
void saveData (UserInfo userInfo) ;
// ID 查询
UserInfo selectById (@Param("id") Integer id) ;
// 查询全部
List<UserInfo> selectList () ;
}@Service
public class UserInfoServiceImpl extends ServiceImpl<UserInfoMapper, UserInfo> implements UserInfoService {
@Autowired
UserInfoMapper userInfoMapper;
@Override
public void saveData(UserInfo userInfo) {
userInfoMapper.saveData(userInfo);
}
@Override
public UserInfo selectById(Integer id) {
return userInfoMapper.selectById(id);
}
@Override
public List<UserInfo> selectList() {
return userInfoMapper.selectList();
}
}@RestController
public class UserInfoController {
@Autowired
UserInfoService userInfoService;
@GetMapping("/selectById/{id}")
public UserInfo selectById(@PathVariable("id") Integer id){
return userInfoService.selectById(id);
}
@PostMapping("/saveData")
public void saveData(@RequestBody UserInfo userInfo){
userInfoService.saveData(userInfo);
}
@GetMapping("/selectList")
public List<UserInfo> selectList(){
return userInfoService.selectList();
}
}<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xrj.clickhouse.mapper.UserInfoMapper">
<!-- 可根据自己的需求,是否要使用 -->
<resultMap type="com.xrj.clickhouse.pojo.UserInfo" id="UserInfoMap">
<result property="id" jdbcType="INTEGER" column="id"/>
<result property="userName" jdbcType="VARCHAR" column="user_name"/>
<result property="passWord" jdbcType="VARCHAR" column="pass_word"/>
<result property="phone" jdbcType="VARCHAR" column="phone"/>
<result property="email" jdbcType="VARCHAR" column="email"/>
<result property="createDay" jdbcType="VARCHAR" column="create_day"/>
</resultMap>
<sql id="Base_Column_List">
id,user_name,pass_word,phone,email,create_day
</sql>
<insert id="saveData" parameterType="com.xrj.clickhouse.pojo.UserInfo" >
INSERT INTO cs_user_info
(id,user_name,pass_word,phone,email)
VALUES
(#{id,jdbcType=INTEGER},#{userName,jdbcType=VARCHAR},#{passWord,jdbcType=VARCHAR},
#{phone,jdbcType=VARCHAR},#{email,jdbcType=VARCHAR})
</insert>
<select id="selectById" parameterType="java.lang.Integer" resultMap="UserInfoMap">
select
<include refid="Base_Column_List" />
from cs_user_info
where id = #{id,jdbcType=INTEGER}
</select>
<select id="selectList" resultMap="UserInfoMap" >
select
<include refid="Base_Column_List" />
from cs_user_info
</select>
</mapper>附录:
如何在 ClickHouse 中复制 MySQL 数据库
如何使用消息队列增量同步数据


















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









