






一、前言
在当今信息化快速发展的时代,数据分析已成为各个行业不可或缺的一部分。从市场营销到金融投资,从医疗健康到教育科技,数据分析能够帮助我们洞察数据背后的规律,优化决策过程,提高业务效率。Excel作为一种广泛使用的电子表格软件,拥有强大的数据处理和可视化功能,但面对大规模、复杂的数据集时,其分析能力往往显得力不从心。
因此,我们利用Python编程语言对Excel文件中的数据进行深入分析和挖掘。Python以其丰富的数据分析库和强大的数据处理能力,为我们提供了灵活、高效的数据分析工具。通过Python,我们可以自动化地处理和分析Excel数据,提取有价值的信息,为业务决策提供支持。
二、配置python虚拟环境
这里的运用主要以pycharm为主,个人偏向pycharm,jupyter没有补全功能,几个软件各有优势。
1.为什么需要配置虚拟环境
我们使用直接安装好的python环境的时候,往往在运行时会缺少各种需要的库,这种时候我们就需要去下载,但装得太多太杂的时候就很容易出各种问题,所以这种时候配置一个python的虚拟环境就会减少各种出现的问题,因为配置出来的都是纯净的几乎没有装什么库的,这时候根据需要去安装自己所需要的库去运行就能大大减少各种库冲突或者覆盖带来的报错问题。
2.配置虚拟环境的流程
这里配置的虚拟环境我以python3.8.10为演示。
第一步:
找到自己安装好的Python环境,没有就下载安装一个python,可以根据需求安装对应版本的python,版本的差别在于对一些库或者函数运行时会有版本差异带来的问题,比如最新的版本无法兼容一些旧版的库,或者一些库的内容进行更新了,这个版本已经没有对应的函数了等问题。(图二为版本差异所带来的下载库时产生的问题,无法完整的下载整个库,得之后根据报错一个一个下载)
第二步:
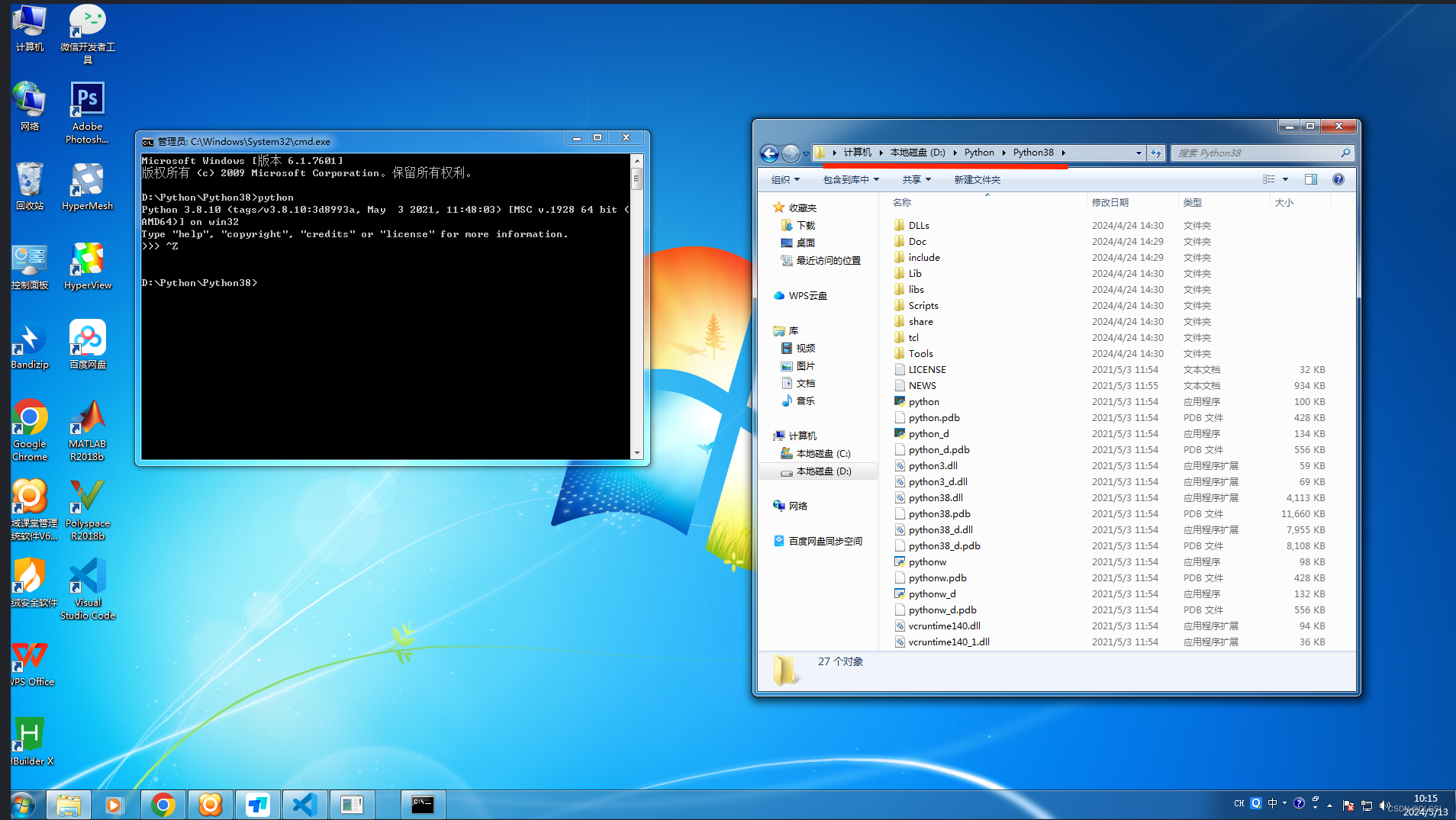
在文件里,你的Python文件路径里面输cmd进入命令窗口(图中画红色横线的位置就是文件路径了),建议检查一下环境是否能运行或者有没有问题。进入后退出是按ctrl+z回车就可以了
第三步:
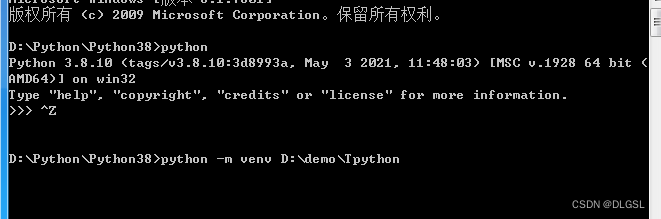
找一个自己放环境的位置(这里我放的D盘) 结构:python -m venv 你要放的盘:\放的文件夹\文件的名称(你自己定)
python -m venv回车等待配置,然后去找到你所配置的虚拟环境位置

第四步:
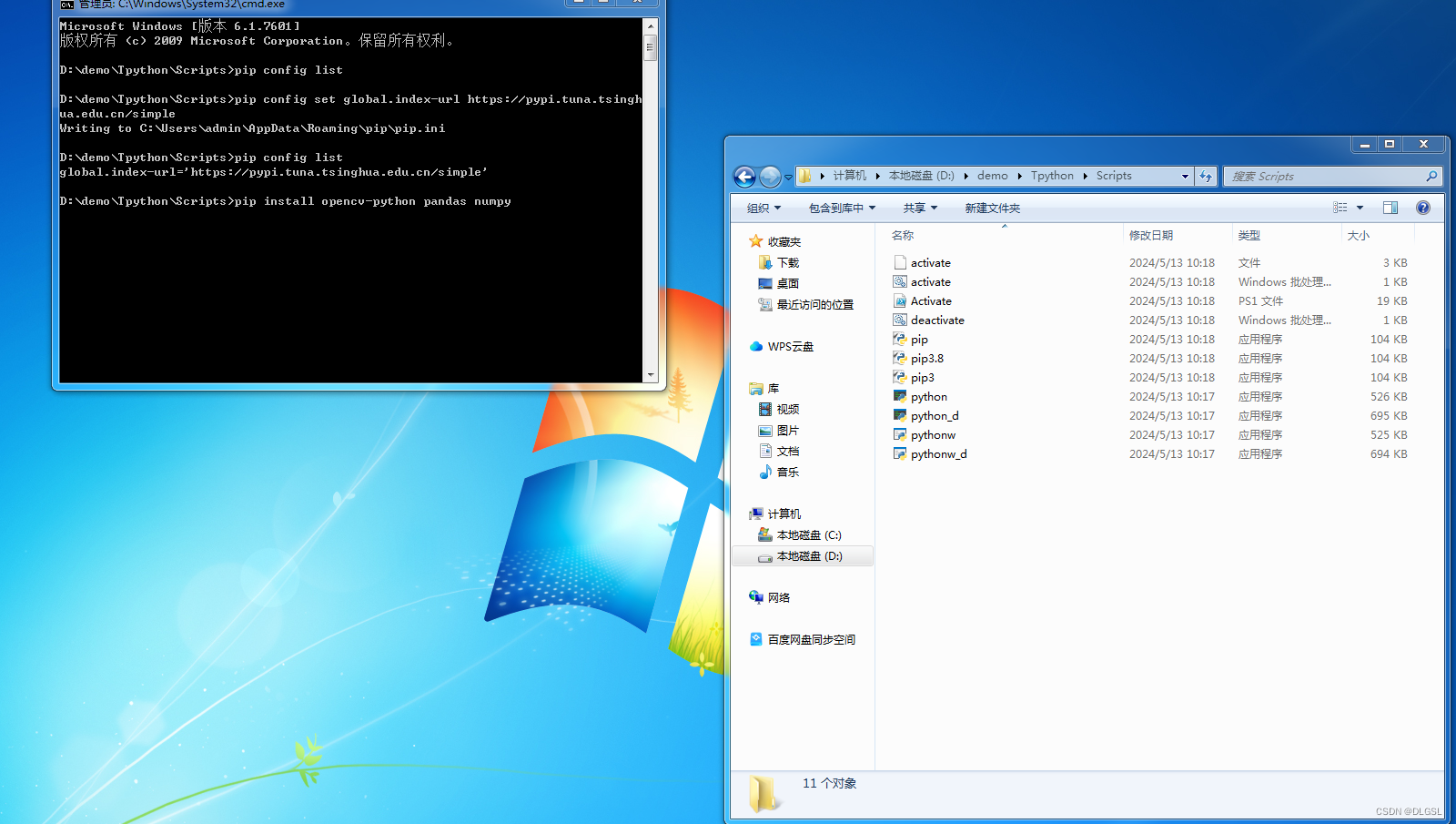
进入已经安装好的虚拟环境的文件夹位置 以为我的为例D:\demo\Tpython\Scripts ,然后跟第二步一样的cmd进入命令窗口

第五步:
根据需要安装你所需要的库即可(注:建议更换为
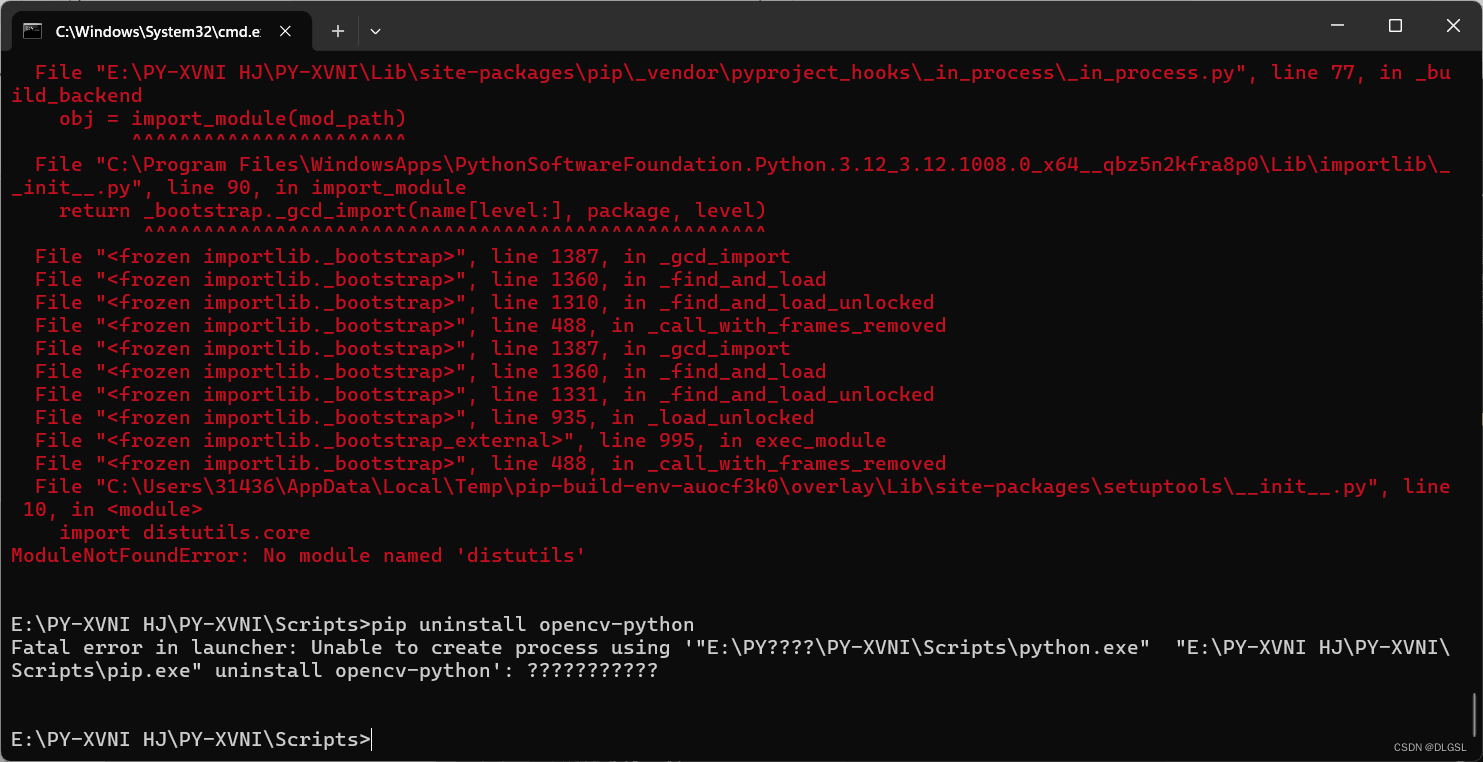
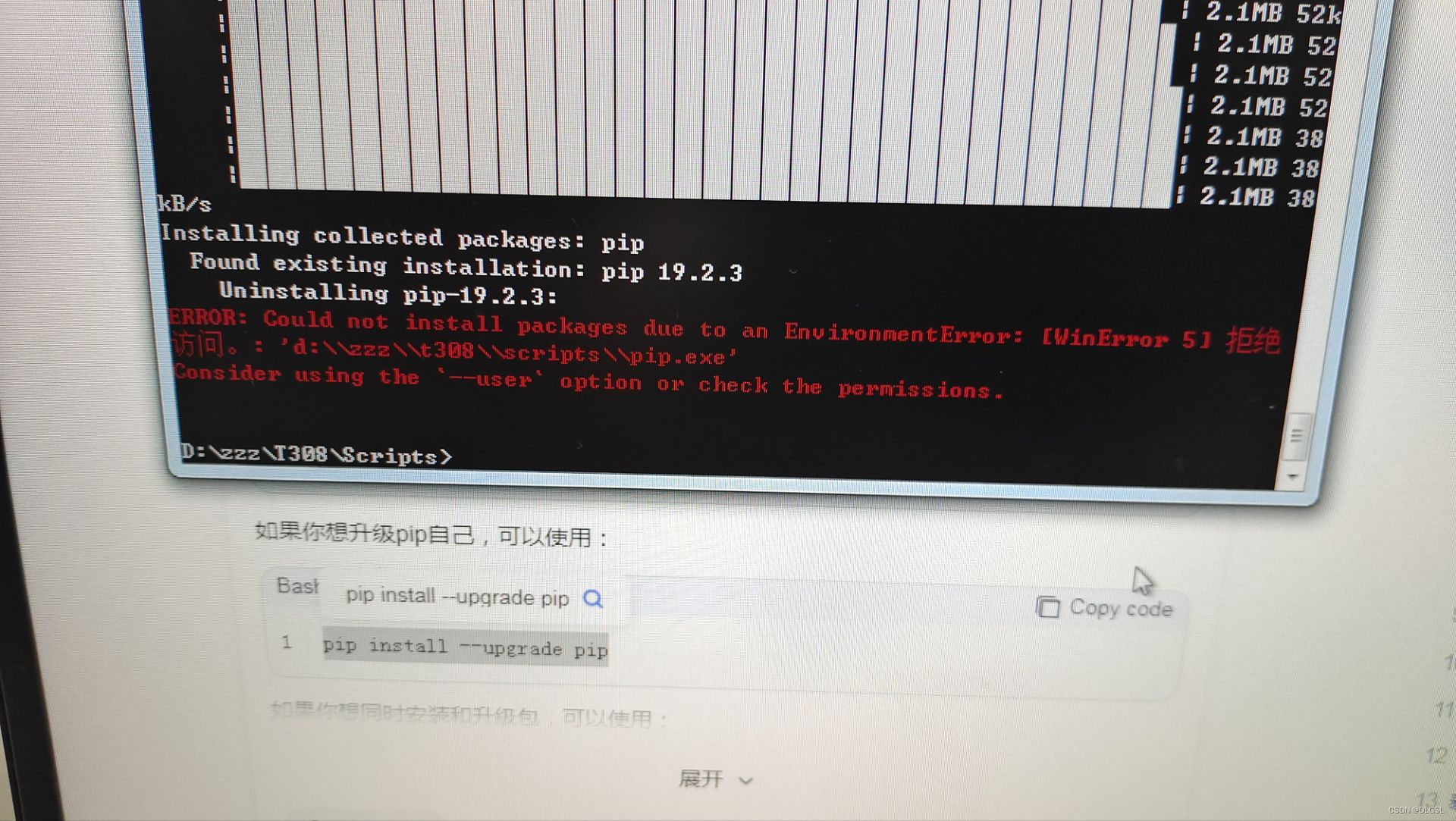
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple因为有些电脑会出现权限等问题产生无法更新的错误,导致pip没有更新好,在更新过程中被删除。下列第二张为出现的错误,如果出现这种情况目前我不知道解决方法,只能重新安装虚拟环境,还有不建议直接使用pip的临时直接下包这种权限有问题的大概会出问题)
三、对数据进行分析
我要对一个年龄、平均血糖和中风患者的信息数据表进行分析
1.导入数据
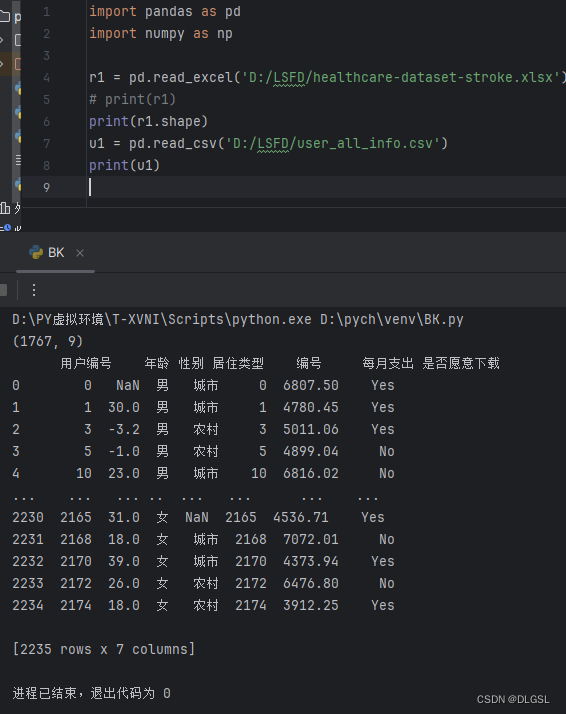
首先需要对数据进行导入,在这里我们就可以一眼看出这个文件中有多少的数据,不用像使用execl一样慢慢去拉来看
# 读取对应的文件
import pandas as pd
import numpy as np
r1 = pd.read_excel('你的文件路径.xlsx')
# print(r1)
print(r1.shape)
u1 = pd.read_csv('你的文件路径.csv')
print(u1)读文件pd.read_要多的文件的后缀格式
shape是只显示维度方便观看这个表有多少的内容
有些表格文件会因为默认格式不兼容导致错误需要更改格式
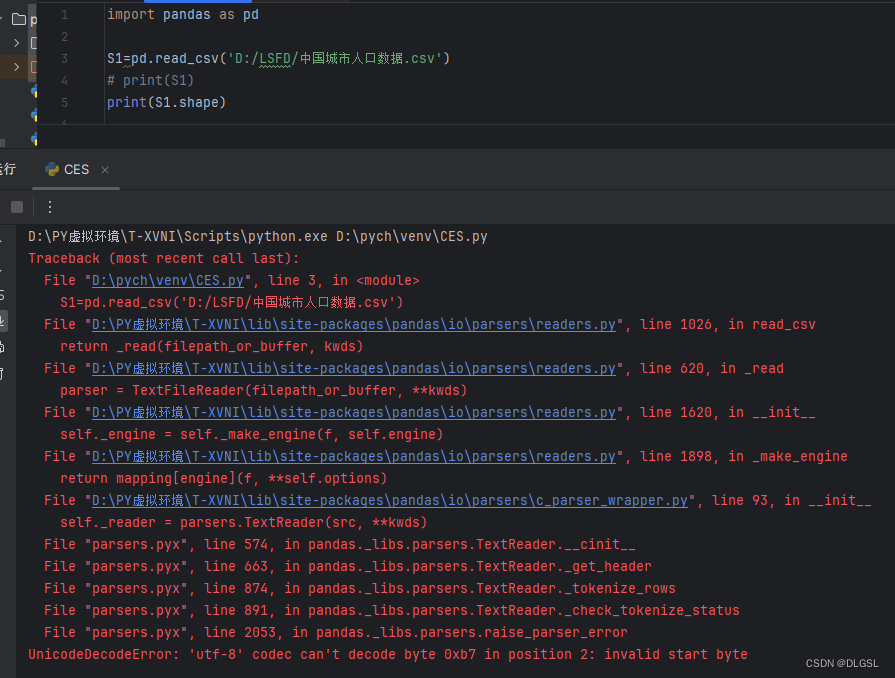
初次进行导入xlsx文件时可能会产生错误
Importirroz:Tissing optiomal derendency 'xlrd . Install xlrd >=1.0.0 for Excel support UIse pip or conda to install xclrd.
这个时候需要对库进行更新
pip install xlrd>=1.0.02.合并表数据
因为血糖和患者的表不是同一个表,两个表的数据不在一起不好分析,所以我们对这两个表进行合并,对同一个对应的编号或者事物等的数据进行合并会更方便分析数据,一个合并在这个对应编号右边一个合并在左边
r3=pd.merge(r1,r2,left_on='你的同一个对应的需要合并的列的编号等',
right_on='你的同一个对应的需要合并的列的编号等',how='outer')
print(r3.shape)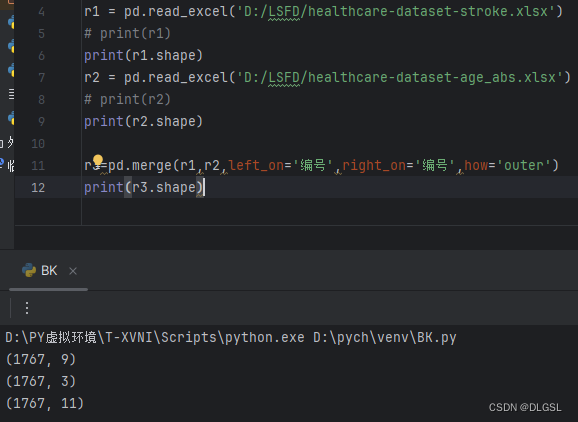
3.分析数据是否存在异常值
先判断年龄中是否存在异常值,存在就删除
r4=r3['年龄']
r4_normal=[]
for i in r4:
if i % 1 ==0:
r4_normal.append(True)
else:
r4_normal.append(False)
r5=r3.loc[r4_normal, :]
print(r5.head(20))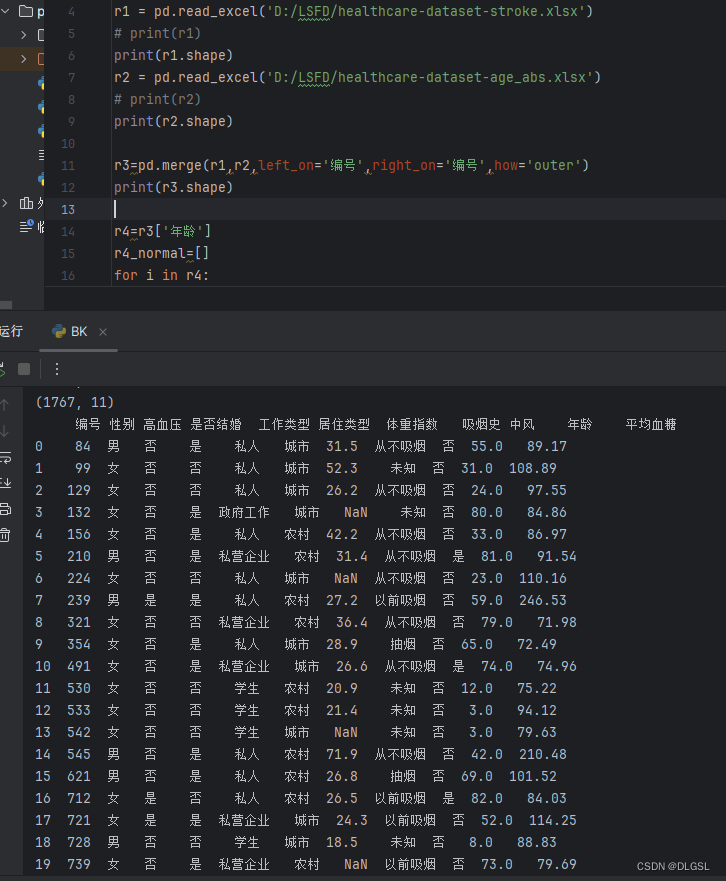 head(20)是打印的前20行
head(20)是打印的前20行
4.离散化年龄特征
对取到的特征进行离散化分成5个部分,然后统计数量就可以更好容易的判断数据的关系了。
r6=pd.cut(r4_normal,5).value_counts()
print(r6)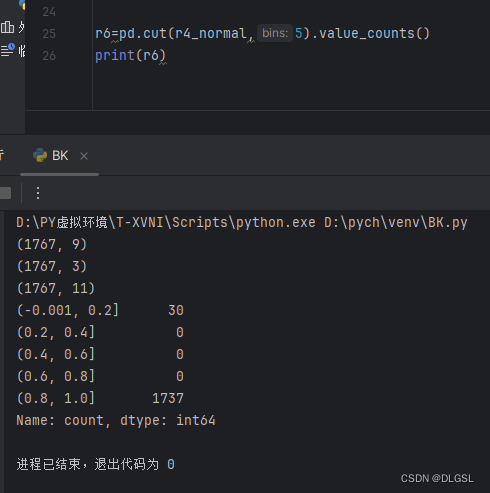
针对不同数据和需要可以使用不同的离散化方法来对数据进行分析
常用的离散化方法:
等宽法分离化;
等频法离散化;
聚类分析法离散化;
决策树离散化;
最优分割点离散化;
自定义分段离散化。
四、不同软件带来的差异
在pycharm中相关性中带有字符串会直接报错不显示,而jupyter的兼容性问题和版本问题,有些版本不会产生字符串的报错问题只会直接不显示字符串,我使用的有一个版本就不会
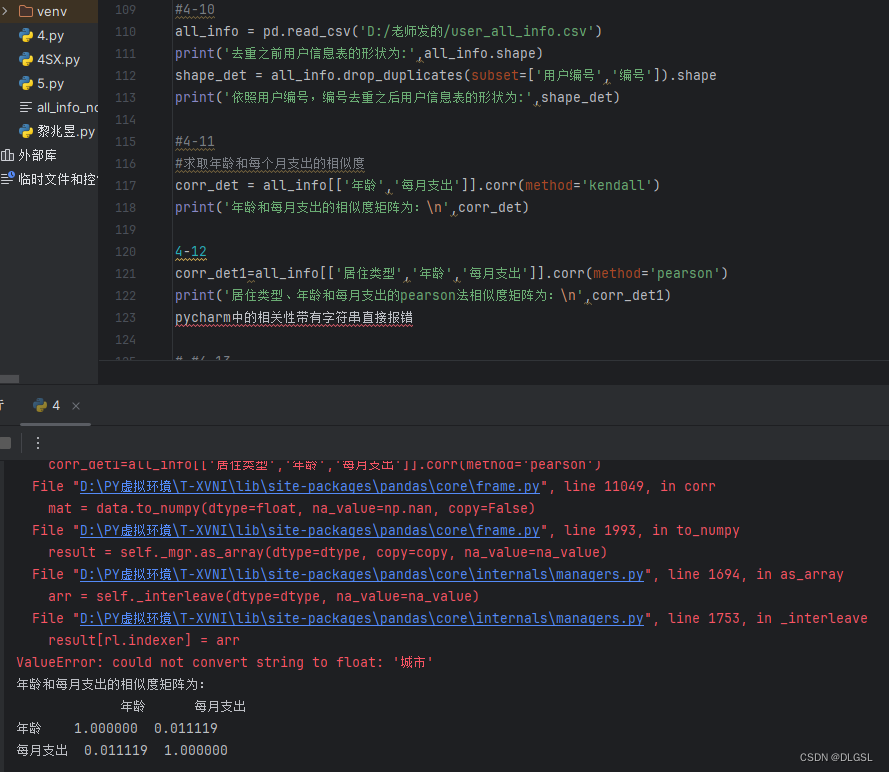
五、总结
使用的软件等根据个人习惯等不同,还有需求时的不同选用不同的方式进行使用,所以使用选用最合适的方式就可以了















 2051
2051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









