







目录
FROM
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
我的环境
- 语言环境:Python 3.11.9
- 开发工具:Jupyter Lab
- 深度学习环境:
- torch==2.3.1+cu121
- torchvision==0.18.1+cu121
一、本周内容及个人收获
1. 本周内容
本周学习内容包括:
- CNN 算法发展
- 残差网络的由来
- ResNet-50 介绍
- 手动构建 ResNet-50 网络模型
2. 个人收获
2.1 ResNet
ResNet(残差网络)是一种深度学习架构,由微软研究院的Kaiming He等人在2015年提出,主要解决深度神经网络训练中的退化问题。ResNet的核心思想是引入“残差学习”,即网络的每个层学习的是输入与输出之间的残差(差异),而不是直接学习输出。这种设计使得网络能够通过简单地堆叠更多的层来增加深度,而不会降低训练性能,反而能够提高性能。
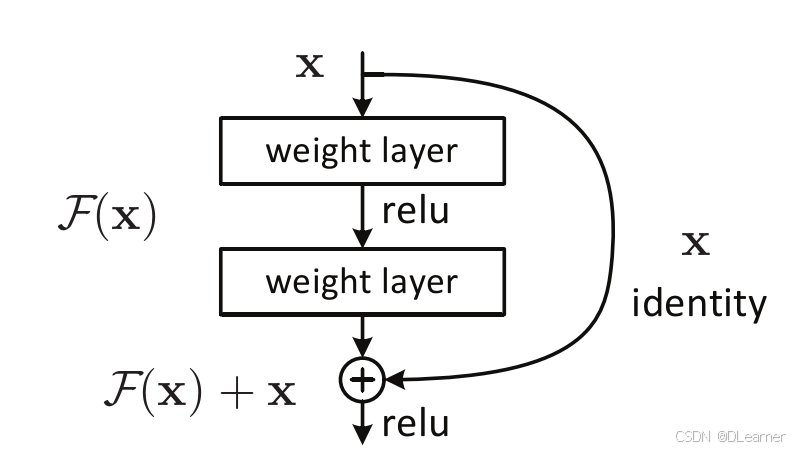
1. 残差块(Residual Block)
ResNet的基本构建单元是残差块,如下图所示,每个残差块包含输入和输出之间的一条捷径(shortcut connection)或恒等连接(identity shortcut)。这种结构允许梯度在网络中直接传播,从而缓解梯度消失问题。
2. 恒等映射(Identity Mapping)
在残差块中,如果输入和输出的维度相同,输入可以直接通过捷径连接添加到输出上,即 F(x)+x 这种结构使得网络即使在增加深度时也能保持性能不会下降,解决了退化问题。
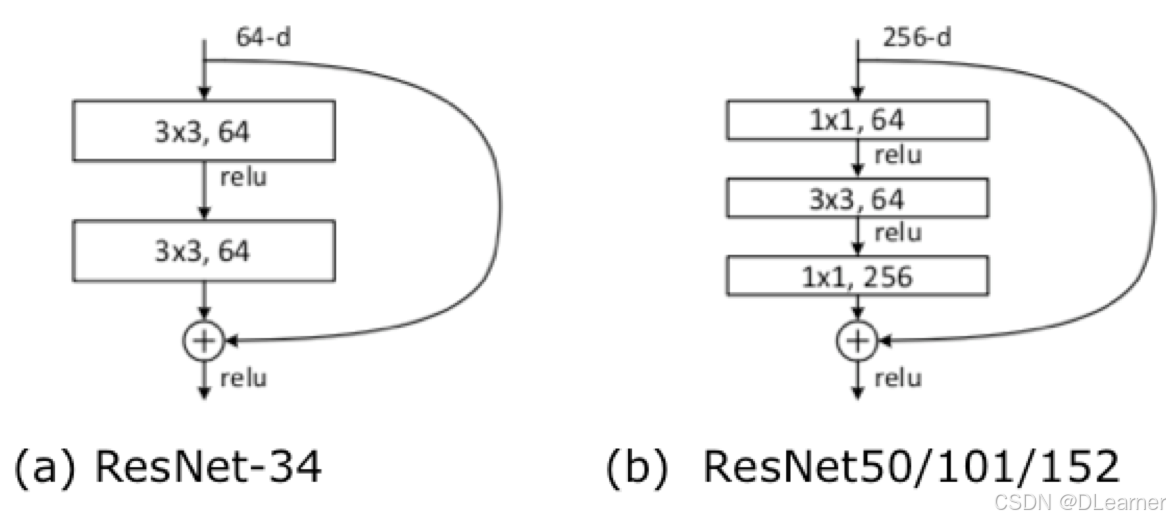
3. 维度匹配(Dimension Matching)
当输入和输出的维度不匹配时,通过1x1的卷积进行降维或升维,以确保输入和输出可以通过捷径连接相加,如下图(b)。
4. Identity Block 恒等块
Identity Block是ResNet中的一种基本构建块,其特点是输入和输出具有相同的维度。这种块的设计允许网络在增加深度时不会降低性能,因为它提供了一个直接的路径(shortcut connection),使得输入可以直接传递到输出,从而避免了梯度消失的问题。
Input ──────────────────────────────────┐
│ │
↓ │
1x1 Conv (filters1) │
│ │
↓ │
BatchNorm + ReLU │
│ │
↓ │
3x3 Conv (filters2) │
│ │
↓ │
BatchNorm + ReLU │
│ │
↓ │
1x1 Conv (filters3) │
│ │
↓ │
BatchNorm │
│ │
↓ ↓
└─────────────── + ──────────────────┘
│
↓
ReLU
Identity Block的结构通常包括:
- 1x1卷积层:用于降低或增加通道数,通常用于降维。
- 3x3卷积层:用于提取特征,保持通道数不变。
- 1x1卷积层:再次用于调整通道数,使其与输入匹配。
- Batch Normalization(批量归一化):在每个卷积层后应用,以加速训练过程并提高性能。
- Activation(激活函数):通常是ReLU,引入非线性。
如果输入和输出的维度相同,Identity Block的shortcut connection直接将输入添加到输出上。如果维度不同,Identity Block不包含额外的卷积层来调整维度,因为输入和输出的维度已经匹配。
5. Convolutional Block(卷积块)
Convolutional Block与Identity Block的主要区别在于,它在shortcut connection中包含一个1x1的卷积层,用于调整输入的维度以匹配输出。这种块通常用于网络中需要改变特征图维度的地方,例如在不同的stage之间。
Input ─────────────────────────────────────┐
│ │
↓ ↓
1x1 Conv (filters1, stride=2) 1x1 Conv (filters3, stride=2)
│ │
↓ │
BatchNorm + ReLU │
│ │
↓ │
3x3 Conv (filters2) │
│ │
↓ │
BatchNorm + ReLU │
│ │
↓ │
1x1 Conv (filters3) │
│ │
↓ │
BatchNorm BatchNorm
│ │
↓ ↓
└──────────────── + ──────────────────┘
│
↓
ReLU
Convolutional Block的结构通常包括:
- 1x1卷积层:用于降维,同时应用stride来下采样。
- 3x3卷积层:用于提取特征。
- 1x1卷积层:用于升维,以匹配shortcut connection的输出维度。
- Batch Normalization:在每个卷积层后应用。
- Activation:通常是ReLU。
在Convolutional Block中,由于输入和输出的维度可能不同,因此需要一个额外的1x1卷积层来调整shortcut connection的维度,以便可以将输入添加到输出上。
2.2 ResNet50中的"50"
- ResNet50中的"50"代表网络的深度,即网络中包含50个卷积层
- 由多个残差块堆叠而成
- 5个阶段的卷积块组成
输入图像(224x224x3)
↓
7x7卷积, 64, /2
↓
3x3最大池化, /2
↓
[1x1卷积, 64 ]
[3x3卷积, 64 ] x 3
[1x1卷积, 256 ]
↓
[1x1卷积, 128 ]
[3x3卷积, 128 ] x 4
[1x1卷积, 512 ]
↓
[1x1卷积, 256 ]
[3x3卷积, 256 ] x 6
[1x1卷积, 1024 ]
↓
[1x1卷积, 512 ]
[3x3卷积, 512 ] x 3
[1x1卷积, 2048 ]
↓
全局平均池化
↓
1000-d 全连接层
↓
Softmax
二、代码运行及截图
1. 数据处理及可视化
import os,PIL,random,pathlib
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data_dir = './bird_photos/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("/")[1] for path in data_paths]
print(classeNames)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:", image_count)
output:

train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
test_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
total_data = datasets.ImageFolder("bird_photos/", transform=train_transforms)
total_data
output:
Dataset ImageFolder
Number of datapoints: 568
Root location: bird_photos/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=warn)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 32
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True, # 对应 TensorFlow 的 shuffle
num_workers=4, # 多进程加载数据,类似 AUTOTUNE
pin_memory=True, # 将数据直接加载到 GPU 缓存,加速数据传输
prefetch_factor=2, # 预加载的批次数
persistent_workers=True # 保持工作进程存活,减少重新创建的开销
)
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=False, # 验证集不需要打乱
num_workers=4,
pin_memory=True,
prefetch_factor=2,
persistent_workers=True
)
for X, y in test_loader:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5)) # 图形的宽为10高为5
# 从 DataLoader 中获取一个批次的数据
images, labels = next(iter(train_loader)) # PyTorch 使用 next(iter()) 替代 TensorFlow 的 take(1)
mean = torch.tensor([0.485, 0.456, 0.406]).view(3, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).view(3, 1, 1)
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
img = images[i] * std + mean
img = img.permute(1, 2, 0)
img = (img * 255).clamp(0, 255).numpy().astype('uint8')
plt.imshow(img)
plt.title(classeNames[labels[i]])
plt.axis("off")
plt.show()
output:

2. ResNet-50 网络 torch 构建
import torch
import torch.nn as nn
import torchsummary as summary
import torchvision.models as models
def identity_block(input_tensor, kernel_size, filters, stage, block):
"""
构建残差网络的恒等映射块
Args:
input_tensor: 输入张量
kernel_size: 卷积核大小
filters: [f1, f2, f3] 形式的过滤器数量列表
stage: 阶段编号
block: 块编号
"""
filters1, filters2, filters3 = filters
name_base = f'{stage}{block}_identity_block_'
# 第一个 1x1 卷积层
x = nn.Conv2d(input_tensor.size(1), filters1, 1, bias=False)(input_tensor)
x = nn.BatchNorm2d(filters1)(x)
x = nn.ReLU(inplace=True)(x)
# 3x3 卷积层
x = nn.Conv2d(filters1, filters2, kernel_size, padding=kernel_size//2, bias=False)(x)
x = nn.BatchNorm2d(filters2)(x)
x = nn.ReLU(inplace=True)(x)
# 第二个 1x1 卷积层
x = nn.Conv2d(filters2, filters3, 1, bias=False)(x)
x = nn.BatchNorm2d(filters3)(x)
# 添加跳跃连接
x = x + input_tensor
x = nn.ReLU(inplace=True)(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2,2)):
"""
构建残差网络的卷积块
Args:
input_tensor: 输入张量
kernel_size: 卷积核大小
filters: [f1, f2, f3] 形式的过滤器数量列表
stage: 阶段编号
block: 块编号
strides: 步长元组
"""
filters1, filters2, filters3 = filters
name_base = f'{stage}{block}_conv_block_'
# 主路径
x = nn.Conv2d(input_tensor.size(1), filters1, 1, stride=strides, bias=False)(input_tensor)
x = nn.BatchNorm2d(filters1)(x)
x = nn.ReLU(inplace=True)(x)
x = nn.Conv2d(filters1, filters2, kernel_size, padding=kernel_size//2, bias=False)(x)
x = nn.BatchNorm2d(filters2)(x)
x = nn.ReLU(inplace=True)(x)
x = nn.Conv2d(filters2, filters3, 1, bias=False)(x)
x = nn.BatchNorm2d(filters3)(x)
# shortcut 路径
shortcut = nn.Conv2d(input_tensor.size(1), filters3, 1, stride=strides, bias=False)(input_tensor)
shortcut = nn.BatchNorm2d(filters3)(shortcut)
# 添加跳跃连接
x = x + shortcut
x = nn.ReLU(inplace=True)(x)
return x
def ResNet50(input_shape=[224,224,3], num_classes=1000):
"""
构建 ResNet50 模型
Args:
input_shape: 输入图像的形状 [H, W, C]
num_classes: 分类类别数
"""
# 输入层
inputs = torch.randn(1, input_shape[2], input_shape[0], input_shape[1])
# 初始卷积块 - 修改 ZeroPadding2d 为 pad 操作
x = nn.functional.pad(inputs, (3, 3, 3, 3)) # 替换 ZeroPadding2d
x = nn.Conv2d(input_shape[2], 64, 7, stride=2, bias=False)(x)
x = nn.BatchNorm2d(64)(x)
x = nn.ReLU(inplace=True)(x)
x = nn.MaxPool2d(3, stride=2, padding=1)(x)
# Stage 2
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1,1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
# Stage 3
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
# Stage 4
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
for block in ['b', 'c', 'd', 'e', 'f']:
x = identity_block(x, 3, [256, 256, 1024], stage=4, block=block)
# Stage 5
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')
# 分类层
x = nn.AdaptiveAvgPool2d((1, 1))(x)
x = torch.flatten(x, 1)
x = nn.Linear(2048, num_classes)(x)
# 修改模型创建和前向传播的方式
class ResNet(nn.Module):
def __init__(self):
super(ResNet, self).__init__()
# 在这里定义所有层
def forward(self, x):
# 定义前向传播
return x
model = ResNet()
# 移除 load_weights,改用 PyTorch 的加载方式
model.load_state_dict(torch.load("resnet50_pretrained.pth"))
return model
model = models.resnet50().to(device)
model
output:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
torchsummary.summary(model, (3, 224, 224))
output:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 4,096
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
----------------------------------------------------------------
Conv2d-166 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-167 [-1, 512, 7, 7] 1,024
ReLU-168 [-1, 512, 7, 7] 0
Conv2d-169 [-1, 2048, 7, 7] 1,048,576
BatchNorm2d-170 [-1, 2048, 7, 7] 4,096
ReLU-171 [-1, 2048, 7, 7] 0
Bottleneck-172 [-1, 2048, 7, 7] 0
AdaptiveAvgPool2d-173 [-1, 2048, 1, 1] 0
Linear-174 [-1, 1000] 2,049,000
================================================================
Total params: 25,557,032
Trainable params: 25,557,032
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 286.56
Params size (MB): 97.49
Estimated Total Size (MB): 384.62
----------------------------------------------------------------
3. 训练及可视化
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X)
loss = loss_fn(pred, y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step() #
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_loader, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_loader, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
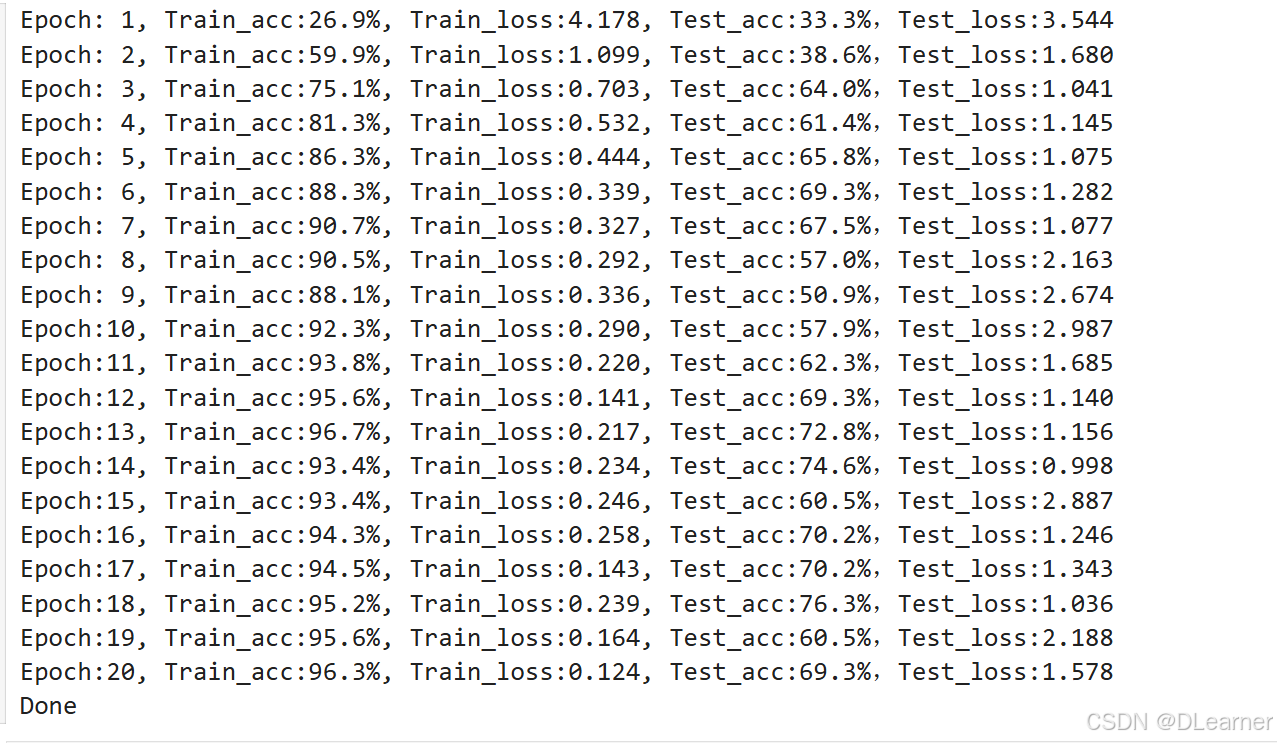
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
output:
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
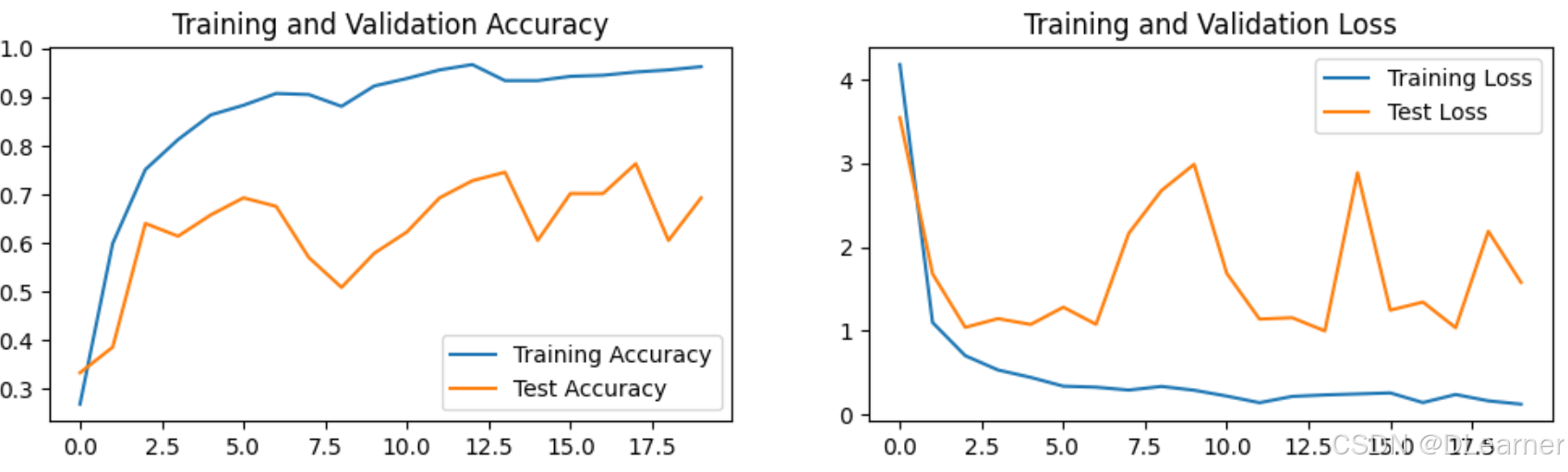
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
output:

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









