







当 DeepSeek R1 系列以 7B 到 671B的参数跨度构建起完整技术栈时,微调场景的硬件选择已演变为一场精密的数学游戏。以 FP16 精度计算,7B 模型微调需要至少 14GB显存(含优化器状态),而 671B 版本则需要惊人的 3TB 级存储空间。这种指数级增长不仅考验硬件工程师的决策能力,更揭示了算力投资的核心法则:选错 GPU 的代价,远不止于训练失败——轻则增加 30% 推理延迟,重则造成百万级硬件成本的浪费。
我们之前介绍过如何对 DeepSeek R1 模型进行微调,但是还未讲过应该如何选择微调时的GPU。本文我们将聊聊 DeepSeek R1 从 7B 到 671B 不同版本在做微调时如何做 GPU 选型。
微调的作用是什么?
很多人希望对DeepSeek模型进行微调,主要是为了提升模型在特定领域或任务中的专业性和性能,最典型的场景就是将其应用在专业领域,例如:通过微调,可以将模型训练为特定领域的“专家”(比如法律、医学等),比如让其掌握专业术语、逻辑推理规则或行业规范。这是因为通用大模型虽然“学习”过各种知识、信息,但对医学、法律、金融等专业领域的深度理解有限,或者说很片面,所以需要通过微调来增强其专业度。
另外还有人会希望通过微调来提升模型在任务(推理和非推理)中的表现。比如通过微调让它在自动驾驶中的表现更加优异;或者是在内容生成、代码编写等场景中,能针对需求给出更精准的结果。
最后的最后,还有一个作用,就是降低成本。微调后,模型可通过量化(如4-bit/8-bit)压缩显存需求,适配消费级显卡(如RTX 4090)或低成本云服务(比如DigitalOcean的 GPU Droplet服务器),同时保持高性能。这对于资源有限的开发者或企业尤为重要。
不同版本DeepSeek的微调需要什么GPU?
再次强调,这里我们说的是DeepSeek R1 模型。首先我们先看下数据量最大的满血版。
DeepSeek R1 671B
在对 DeepSeek R1(671 B 参数量)进行微调时,不同精度或量化策略对 GPU VRAM 的需求差异巨大。所以,我们需要考虑到全精度、FP8 原生和 4-bit 量化三种主要精度的 VRAM 需求,以及相应的推荐 GPU 配置。
未量化的全精度模型需要 约1.5 TB GPU VRAM,而原生 FP8(8 位浮点)微调则需要 约700–750 GB VRAM;若使用 4-bit 量化,显存需求可进一步降至 约436 GB。因此,常见的 GPU 选型会采用多卡拼接的方式:
- 全精度:大约需要 1 543 GB VRAM,NVIDIA A100 80 GB×20 或 H100 80 GB×20 的多卡集群。
- FP8 (原生):大约需要 700–750 GB VRAM,那么就需要配置 NVIDIA A100 80 GB×9 或 H100 80 GB×9。
- 4-bit 量化:大约需要436 GB VRAM,那么就需要配置NVIDIA A100 80 GB×6 或 RTX 4090 24 GB×19 。
当然,也可采用梯度检查点(gradient checkpointing)或 ZeRO 分区来减少单卡占用,但多卡仍是主流方案。另外,如果想寻求更强性能,也可以考虑 H200,如果想得到更高的显存带宽,也可以选择AMD MI300X。最后要提醒一点,4-bit量化虽然可以大幅降本,但是它可能导致模型精度损失,你需要根据任务需求权衡利弊,谨慎判断。 以上这几款GPU 服务器在DigitalOcean 云平台上都可以找到,而且价格比一线云平台更便宜,且支持裸金属方案,具体可点击文末的链接咨询卓普云AI Droplet。
DeepSeek R1 70B
显存仍然是最主要的考虑因素。70B 参数的模型即便在量化和使用参数高效微调技术(PEFT)的情况下,也需要大量的显存。
对于 70B 模型,在 16-bit 精度下可能需要数百 GB 的显存(例如,有人就估算出大约需要 670GB )。这就意味着,你需要使用多张高端数据中心 GPU。
而参数高效微调 (PEFT)如 LoRA, QLoRA后的模型,显存的需求会降低很多:
- LoRA (例如 16-bit): 显存需求会降至约 140-150GB。
- QLoRA (例如 4-bit): 显存需求可以进一步降低到约 40-50GB。
那么根据这些不同情况,可以考虑的 GPU 包括:
- 用于全参数微调或高精度 LoRA 微调 (通常需要 >150GBVRAM):
- NVIDIA A100 (80GB): 需要多卡并行,例如 2-4 张用于 LoRA,更多张(如 8 张以上)用于全参数微调。有数据显示微调 Llama 3 70B (与 Deepseek R1 70B 同级别) 在 float16 精度下推荐使用 2 张 A100。 DeepSeek-R1-Distill-Llama-70B(完整模型)需要约 181GB VRAM,推荐使用 3 张 NVIDIA A100 80GB。
- NVIDIA H100 (80GB): 作为 A100 的继任者,性能更强,同样需要多卡配置。
- NVIDIA H200 (141GB): 提供更大的单卡显存,可以减少所需卡的数量,但依然可能需要多卡。
- 用于 QLoRA 微调 (例如 4-bit,显存需求约 40-90GB):
- NVIDIA A100 (80GB): 单张或两张基本可以满足 QLoRA 的需求。LinuxBlog.io 提到 8-bit 量化的 DeepSeek R1 70B 推荐使用 A100 80GB。
- NVIDIA H100 (80GB): 同样,单张或两张即可。
- NVIDIA RTX A6000 (48GB): 单张或两张。Database Mart 和 RunPod Blog 均提及 A6000 适用于 70B 模型的场景(后者特指 QLoRA 4-bit 约 46GB 需求,A40/A6000 可满足)。
- NVIDIA L40S (48GB): 较新的数据中心 GPU,提供 48GB 显存。
在选择 GPU 时,除了显存大小,还应考虑 GPU 架构、内存带宽以及可用的软件栈和驱动支持。如果你要效率高,最好还是不要选择 4090 等一系列不支持 NVLink 的消费级 NVIDIA GPU。
DeepSeek R1 32B
这个版本跟前两个版本的 GPU 选型思路相似。具体所需的 GPU 型号和数量会因微调方法(全参数微调、LoRA、QLoRA 等)、训练精度(如 FP16、8-bit、4-bit)以及批量大小等因素而异。
简要来讲,对于成本有限的团队或个人开发者,QLoRA 配合具有至少 24GB VRAM 的 GPU(如 RTX 4090、RTX 3090、RTX A5000)是微调 Deepseek R1 32B 的可行路径。如果预算和资源允许,40GB 以上显存的 GPU(如 A100、RTX A6000、L40S)将提供更大的灵活性和更佳的性能,特别是对于 LoRA 或更高精度的微调。
如果是全参数微调则必须使用 A100 80GB 或 H100 80GB 这样的顶级数据中心 GPU。因为对于 32B 模型,在 16-bit 精度 (FP16/BF16) 下,可能需要约 60GB 到 80GB 以上的显存。
DeepSeek R1 14B
对于 14B 模型全参数微调,在 16-bit 精度下,有资料显示可能需要高达 134GB 的显存。也就意味着 NVIDIA A100 (80GB)需要至少两张,或者 NVIDIA H100 (80GB)需要至少两张。
如果是高效微调的方法,LoRA (例如 16-bit),显存需求大幅下降,估计约为 30GB 。对 DeepSeek-R1-Distill-Qwen-14B 进行 LoRA 微调推荐使用 1 张具有 48GB 显存的 GPU ,这为实际操作提供了一个参考点,表明拥有超过30GB显存的单卡是理想的。另一份阿里云文档针对类似的 14B Qwen Coder 模型进行训练(微调)推荐使用具有 32GB 显存的 GPU (如 V100) 或更高规格。
QLoRA 技术让我们可以在消费级 GPU 上微调 14B 模型,16GB 显存的 GPU(如 RTX A4000, RTX 4060 Ti 16GB)对于 4-bit QLoRA 来说是比较合适的选择,甚至 12GB 显存的 GPU 也有可能。但还是那句话,4-bit量化虽然可以大幅降本,但是它可能导致模型精度损失,你需要视情况而定。
DeepSeek R1 7B
DeepSeek R1 7B的微调的可选项就很多了。全参数微调的话预估需要约 67GB 的显存,那么你可以选择多张 NVIDIA RTX A6000 Ada (48GB),或者直接选择 NVIDIA A100(80GB)。
如果是LoRA 微调 (16-bit,预计显存需求 16GB-24GB),那么NVIDIA RTX 4090 (24GB)、NVIDIA RTX A5000 (24GB)、NVIDIA A10G / A10 (24GB)都是不错的选型。
从GPU维度来看
如果我们换个维度,可能会让一部分读者更清晰,不同型号 GPU 可以用来做哪些模型微调呢?我们简要总结了一张表格:
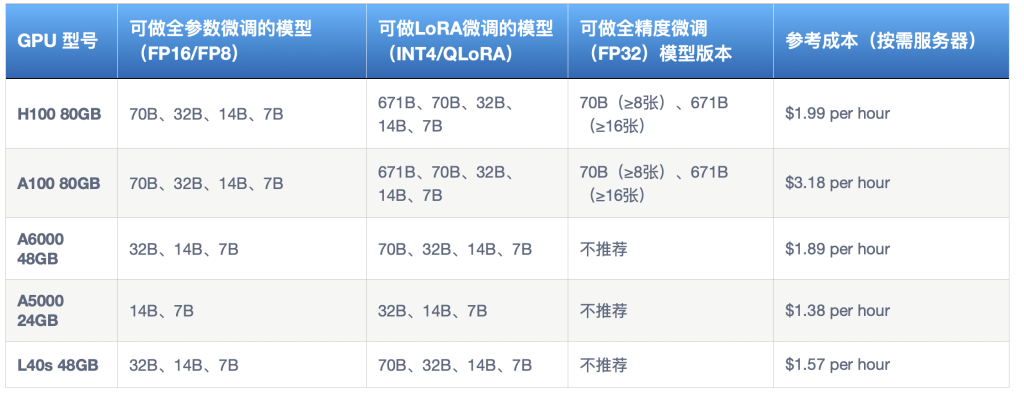
我们仅列出了一部分的GPU型号。DigitalOcean云平台支持提供以上型号的GPU云服务器,并且支持按需付费,并在套餐中提供大量免费流量。以上价格可能会根据时间而变化(有时会有节日促销), 具体实时价格与折扣福利可点击文末链接咨询 DigitalOcean中国区独家战略合作伙伴卓普云AI Droplet。
我们怎么判断微调应该用什么GPU?
都说授人以鱼不如授人以渔。我们上面其实给出的知识不同版本 DeepSeek R1 所需的 GPU 型号。那么以后 NVIDIA 和 AMD 甚至国产GPU再出新产品,或者我们要微调其他大模型(比如 Qwen 3 ,新版本开源模型表现也很不错),应该怎么做 GPU 选型呢?所以我们来提供一些思考的维度:
- 快速估算:以「参数量×1 B/16 GB」原则,初步锁定显存需求。
- 局部验证:先在可用算力上跑通最小工作流,利用 profiling 校准内存与带宽瓶颈。
- 精细对比:综合算力、带宽、功耗、价格和生态支持,选出性价比最高的 GPU 型号或组合。
- 持续迭代:结合项目进展与硬件动态,定期复盘选型逻辑,确保在新产品发布时迅速更新方案。
以上就是关于DeepSeek R1 不同版本的微调应该怎么选GPU的经验与思路。最后,如果你正在训练模型,然而嫌一线云平台的GPU价格太贵或流量费过高,或是由于其他原因希望尝试其他GPU 服务器,欢迎尝试DigitalOcean GPU Droplet, 如需详细咨询可点击文末链接联系DigitalOcean中国区独家战略合作伙伴卓普云AI Droplet。


















 1294
1294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









