







4 月底,阿里通义千问团队发布了全新一代大模型 Qwen 3,该模型一经推出便登顶全球开源模型首位。Qwen3 提供从 0.6B 到超大规模的 235B-A22B 多种模型,涵盖 Dense 和 MoE 架构(如 30B-A3B),满足不同场景需求。业界将其评价为“全面超越 o1、DeepSeek R1 等模型”。
Qwen3 系列包含多种模型(如 0.6B、14B、32B、235B-A22B 等),不同版本显存需求差异较大:
- Qwen3-0.6B :RTX 6000 Ada 可运行,最低可支持单卡消费级显卡(如 RTX 3090/4090,24GB 显存)运行。
- Qwen3-14B 及以上 :推荐使用专业级 GPU(如 NVIDIA A100/H100),单卡显存需 40GB 以上,或通过多卡分布式部署。
- Qwen3-235B-A22B(旗舰版) :需多卡并行(如 2-3 张 H100 或 1-2 张 H200 显卡)才能完整运行。
而以上绝大部分 GPU,都可以在 DigitalOcean 云平台上获取,并且支持按需实例。那么我们正好借此机会, 在 DigitalOcean GPU Droplet 服务器上跑一跑最新的 Qwen3 大模型。
在本文中,我们将介绍 Qwen3 的新发布版本,讨论它与之前 Qwen 版本以及其他领先的开源大型语言模型(SOTA Open-Source LLMs)的不同,然后展示如何在配备 NVIDIA GPU 的 DigitalOcean GPU 服务器上运行 Qwen3。
Qwen3概览
Qwen3 是基于阿里云原始 Qwen 架构的大型语言模型。自首次发布以来,该模型一直在不断迭代,而 Qwen3 是最新公开发布的版本。
我们可以根据已有的信息和之前发布的版本对模型做出一些推测。由于 Qwen v1 的原始模型架构据报道与 LLaMA 相似,我们可以推断这种架构在Qwen3中得到了延续。他们在Qwen2和Qwen2.5中使用了基于Transformer的解码器架构,我们可以假设这种架构在Qwen3中得到了进一步发展。我们还可以假设他们使用了类似的专家混合技术,即用专门的专家混合层替换了标准的前馈网络(FFN)层,每个层由多个FFN专家和一个将令牌分配给顶级K专家的路由机制组成。这可能在Qwen3中从Qwen2.5得到了进一步改进,但由于没有技术报告,我们对这方面的了解有限。
幸运的是,我们对模型能够做什么有了更多的了解。以下是官方Qwen3博客文章中特别提到的模型能力。
- 在单个模型中独特地支持在思考模式(用于复杂的逻辑推理、数学和编码)和非思考模式(用于高效的通用对话)之间无缝切换,确保在各种场景中都能实现最佳性能。
- 在推理能力上有了显著提升,超越了之前的QwQ(在思考模式下)和Qwen2.5指令模型(在非思考模式下)在数学、代码生成和常识逻辑推理方面的表现。
- 在人类偏好对齐方面表现出色,擅长创意写作、角色扮演、多轮对话和指令遵循,提供更自然、更吸引人、更沉浸式的对话体验。
- 在代理能力方面表现出色,能够在思考和非思考模式下精准地与外部工具集成,并在复杂的基于代理的任务中实现开源模型中的领先性能。
- 支持100多种语言和方言,具有强大的多语言指令遵循和翻译能力。
Qwen3与其他领先的大型语言模型的比较
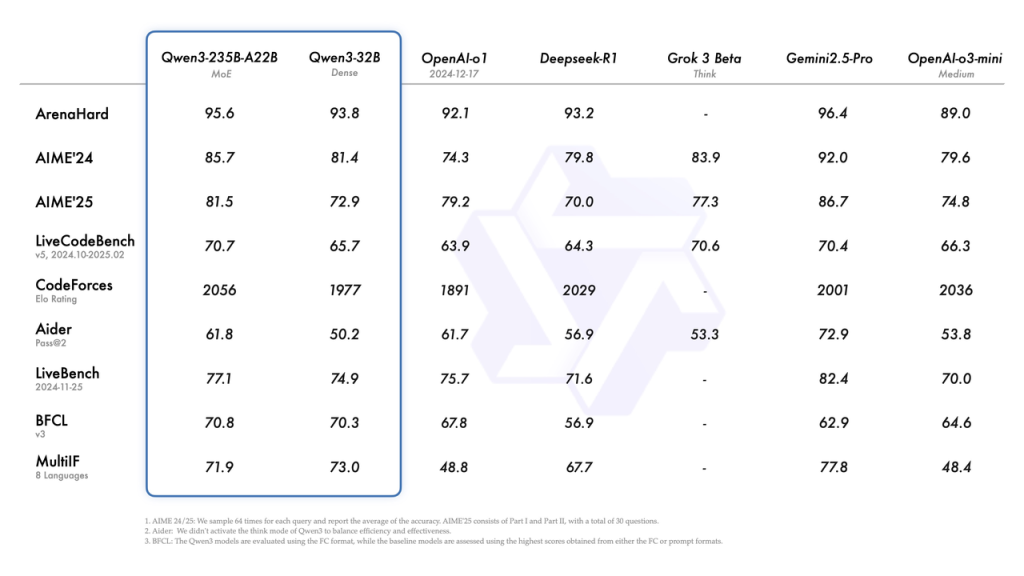
从Qwen团队为此次发布的版本发布的技术比较中,我们可以看到,Qwen3-235B-A22(该模型的最大版本)在性能上超越或接近DeepSeek-R1和Gemini2.5-Pro等顶级开源和闭源模型。随着更多信息的发布,我们将使用DigitalOcean机器对这些模型的性能进行基准测试,并更新此部分内容。
如何在GPU服务器上运行Qwen3
在DigitalOcean的GPU服务器上有多种方法可以运行Qwen3,包括使用VLLM、SGLang和transformers。在本文的这一部分,我们将展示如何在DigitalOcean的服务器上部署Qwen3 30B A3B模型。
首先,启动并运行你的DigitalOcean GPU服务器。完成后,通过SSH登录到你的机器或使用云控制台访问我们远程机器的终端。
接下来,我们将设置环境。将以下代码粘贴到终端中:
apt-get install git-lfs python3-pip
pip install vllm transformers sgl_kernel orjson torchao
pip install --upgrade pip
pip install uv
uv pip install "sglang[all]>=0.4.6.post2"
这将安装部署Qwen3模型所需的全部内容。
最后,我们将模型下载到机器上,以便我们可以在选择的目录中轻松访问模型文件。
git-lfs clone https://huggingface.co/Qwen/Qwen3-30B-A3B
这将把模型文件下载到目录./Qwen3-30B-A3B中。至此,我们可以通过三种方法之一开始部署模型。让我们先讨论VLLM。或者,我们可以使用HuggingFace CLI下载器。下载时务必保存模型保存文件的路径!
huggingface-cli download Qwen/Qwen3-30B-A3B
VLLM
VLLM是一个旨在提高大型语言模型(LLM)推理和服务效率的开源库。使用VLLM,我们可以非常快速地以生产就绪的容量提供模型服务。由于我们已经安装了所有所需的软件包,现在可以立即开始。
要启动Qwen3模型的VLLM服务器,请将以下代码粘贴到终端中。
vllm serve ./Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1
如果你使用了CLI,请更改指向HuggingFace缓存位置的路径。
现在服务器已经启动,我们可以通过VLLM的常规cURL语法查询模型。使用下面的示例生成模型的示例输出。
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
如果一切正常,我们应该得到类似以下的输出:
text {“id”:“cmpl-b3f3e575ee034634a0691bc586fa98be”,“object”:“text_completion”,“created”:1746468551,“model”:“./Qwen3-30B-A3B”,“choices”:[{“index”:0,“text”:" city in the state of California,",“logprobs”:null,“finish_reason”:“length”,“stop_reason”:null,“prompt_logprobs”:null}],“usage”:{“prompt_tokens”:4,“total_tokens”:11,“completion_tokens”:7,“prompt_tokens_details”:null}}
SGLang
接下来,我们将使用SGLang运行模型。与VLLM类似,SGLang是一个用于大型语言模型和视觉语言模型的开源框架。它在大规模托管LLM方面非常有效,适用于测试和生产就绪的用例。要在GPU服务器上启动Qwen3-30B-A3B,我们只需将以下命令粘贴到终端中。
python3 -m sglang.launch_server --model-path ./Qwen3-30B-A3B --reasoning-parser qwen3
与VLLM一样,由于我们已经下载了模型,这应该是一个相对快速的过程。如果你使用了CLI,请更改指向HuggingFace缓存位置的路径。现在我们可以通过cURL查询模型。
curl -X POST http://localhost:30000/generate \
-H "Content-Type: application/json" \
-d '{
"text": "The capital of France is",
"sampling_params": {
"temperature": 0,
"max_new_tokens": 32
}
}'
这将生成类似以下的输出:
{"text":" Paris. The capital of the United Kingdom is London. The capital of Germany is Berlin. The capital of Spain is Madrid. The capital of Italy is Rome.","meta_info":{"id":"eb1e4282eddc4e5e93ef0186ae3f1a89","finish_reason":{"type":"length","length":32},"prompt_tokens":5,"completion_tokens":32,"cached_tokens":2,"e2e_latenc
Transformers
最后,我们可以通过Transformers库直接查询模型,并以Python的方式操作。虽然其他方法也可以通过Python访问,但Transformers是我们的首选,因为它提供了最大的灵活性。由于我们已经将模型加载到存储中,现在可以使用以下代码首先加载我们的检查点,同时设置Python环境。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
接下来,我们可以准备模型输入。修改以下代码以更改提示,是否使用推理以及对输入进行分词。
# 准备模型输入
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 在思考模式和非思考模式之间切换,默认为True。
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
最后,我们可以生成输出:
# 进行文本补全
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思考内容
try:
# 从后向前查找151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
这将使用模型的推理能力生成输出。由于输出有几段长,我们选择不在此处包含它。尽管如此,很容易看出我们现在可以如何根据需要将此代码无缝集成到我们的项目中,例如Gradio应用程序。
写在最后
Qwen3是一个特别令人兴奋的模型,因为它能够在思考和非思考模式之间无缝切换,并具有创新的代理能力。我们期待看到越来越多像Qwen3这样的模型发布,以进一步推动大型语言模型的发展。
最后,如果你在寻找价格实惠、计费透明、性能稳定且开发者友好的GPU服务器, 欢迎进一步了解DigitalOcean GPU Droplet,详情可点击下方链接咨询DigitalOcean中国区独家战略合作伙伴卓普云AI Droplet。


















 1293
1293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









