




1.常用Web服务器软件
- Apache
- IIS(Internet Information Server)
- Nginx
- Lighttpd
- Zeus
- Resin
- Tomcat
2.Web服务器应用架构
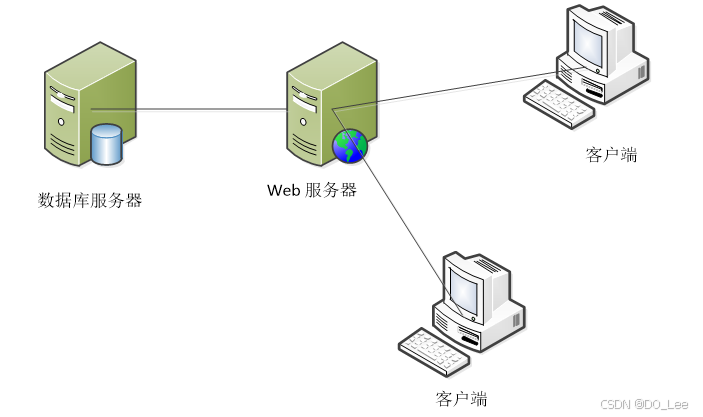
- Clinet/Server
客户端可以是各种浏览器,也可以是爬虫程序。
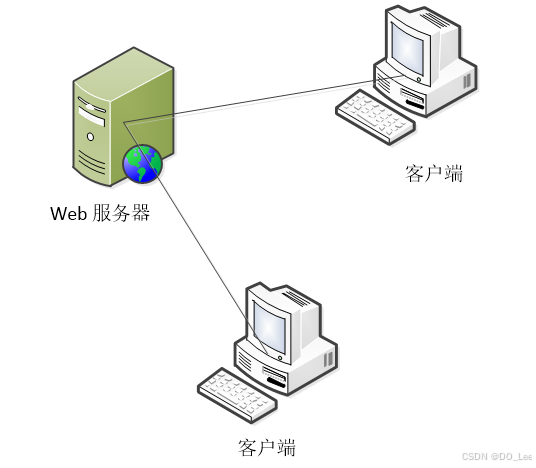
- Client/Server/Database
在这个架构中,Web服务器上的HTML文件中通常存在一些动态脚本,这些脚本在用户请求时由Web服务器执行。
- Web服务器集群
为应对大量用户并发访问的情况而设计。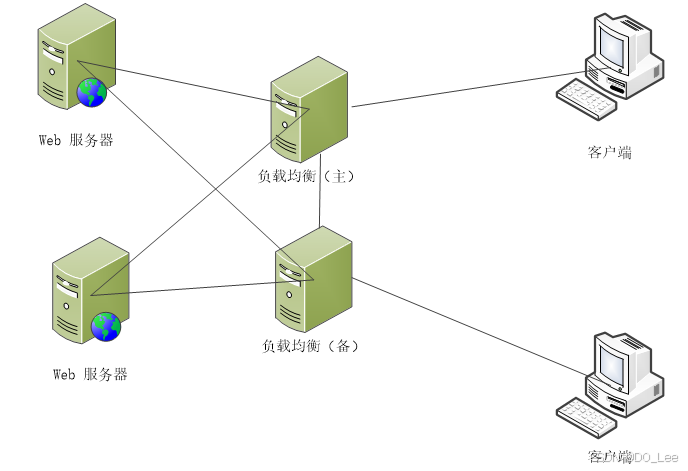
- 虚拟主机
在一台服务器里配置多个网站,使得每个网站看起来具有独立的物理计算机。实现方法有:
- 基于IP地址的方法:在服务器里绑定多个IP,配置Web服务器,把网站绑定在不同的IP上。
- 基于端口的方法:不同网站共享一个IP地址,但是通过不同的端口实现对不同网站的访问。
- 基于主机名的方法:设置DNS将多个域名解析到同一个IP地址上,IP地址对应的服务器上配置Web服务端,添加多个网站,为每个网站设定一个主机名。
3.Web页面类型
Web页面的组成部分:内容、结构、表现效果和行为。
根据Web页面组成结构中的信息内容的生成方式,可将Web页面分成以下三种类型。
- 静态型:以HTML文件的形式存在于Web服务器的硬盘上,内容、结构和表现效果是固定的,行为也比较简单。除了Web服务外,不需要其他服务的支持,对服务器的资源消耗少。
- 动态性:
- 页面内容是可变的。
- 页面结构也是允许变化的。
- 在表现效果上,页面中不同部分的效果会随着内容的变化而变化。
- 页面行为是区别于静态页面最主要的特征。动态页面并不是直接把内容存储到文件中,而是要进一步执行内容生成步骤,通常的方式有访问数据库等。
- 伪静态型:以静态页面展现出来,但实际上是用动态脚本来处理的。伪静态页面的URL本质上可以理解为不带“=”的参数。
4.Robots协议(Robots Exclusion Protocol)
指定了某种标识的爬虫能够抓取的目录或不能抓取的目录,也就是访问许可策略。
在网站首页的地址后面添加“/robots.txt”即可访问。
- 文件中包含一个或多个记录,每个记录由一个或多个空白行隔开。

- User-Agent:

- Allow 或 Disallow:
Disallow指定的字段值可以是一个全路径,也可以是部分路径。

- 通配符的使用
- * 代表0个或多个任意字符
- $ 表示行结束符
- 抓取延时(Crawl - delay):规定爬虫程序两次访问网站的最小时间延时(以秒为单位)。
- 访问时段(Visit - time):规定爬虫程序访问网站的时间。
- 抓取频率(Request - rate):限定URL读取频率。
- Robots版本号(Robot - version)

















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









