







08 【聚合函数与分组查询】
我们上一章讲到了 SQL 单行函数。实际上 SQL 函数还有一类,叫做聚合(或聚集、分组)函数,它是对一组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值。
1.聚合函数介绍
- 什么是聚合函数
聚合函数作用于一组数据,并对一组数据返回一个值。
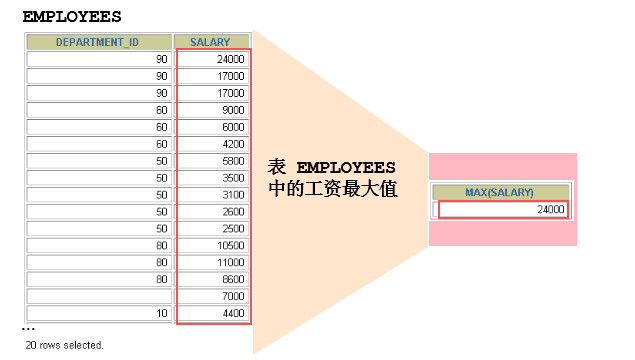
-
聚合函数类型
-
函数 功能 count 统计数量 max 最大值 min 最小值 avg 平均值 sum 求和
-
-
聚合函数语法

- 聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用。
1.1 AVG和SUM函数
可以对数值型数据使用AVG 和 SUM 函数。
SELECT AVG(salary), MAX(salary), MIN(salary), SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';

1.2 MIN和MAX函数
可以对任意数据类型(包括数值类型、字符串类型、日期类型)的数据使用 MIN 和 MAX 函数。
SELECT MIN(hire_date), MAX(hire_date)
FROM employees;

1.3 COUNT函数
作用:计算指定字段在查询结构中出现的个数
如果计算表中有多少条记录,如何实现?
方式1:count(*)
方式2:count(常量),例如count(1)或count(2)…
方式3:count(字段名),注意:计算指定字段出现的个数时,是不计算NULL值的。
- COUNT(*)返回表中记录总数,适用于任意数据类型。
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;

- COUNT(expr) 返回expr不为空的记录总数。
SELECT COUNT(commission_pct)
FROM employees
WHERE department_id = 50;

-
问题:用count(*),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器
row_count在维护着行数,查询效率都是o(1)。Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
count(*)=count(1)>count(字段) -
问题:能不能使用count(列名)替换count(*)?
不要使用 count(列名)来替代
count(*),count(*)是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
2. GROUP BY
2.1 基本使用
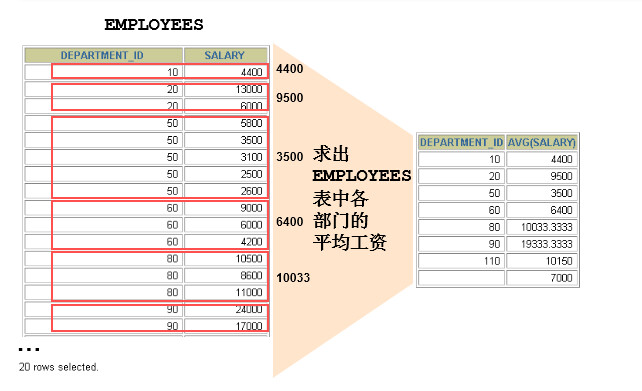
可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GRO 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











