







文章目录
概述
主要是 Shuffle 阶段的排序功能
序列化
Hadoop 自定义序列化格式
Writable
排序
排序是 Shuffle 阶段的功能之一.
Hadoop 将序列化和排序结合在一起.
WritableComparable
有其他子接口,来实现其他的功能
例如 WritableComparable 可以实现排序功能的序列化接口
思路
源文件
我们有一个文件. 这个文件是之前 map-reduce 过程的结果.
文件里面存储了 每个单词字母出现的次数.
我们对这个文件进行排序.

map
通过 map 方法,形成特殊的 K2V2.

每个单词以及他们出现的次数,作为 K2V2
Shuffle-Sort
Shuffle阶段的排序. 实现 WritableComparable 接口
自定义排序字段.
因为 有单词以及单词出现的次数.
相同的字母或单词按照出现的次数排序
不同的单词按照 26个字母的顺序排序

我们将单词进行 split. 得到每个单词以及出现的次数.顺便排序
注意们这里的 K2 是一个 JavaBean 对象. 也就是, map 要传递的K2 是一个Bean对象.
而这里的V2就是String字符串
我们的排序就是在 K2 Bean对象里面实现的

Reduce阶段
自定义 reduce 逻辑. 将 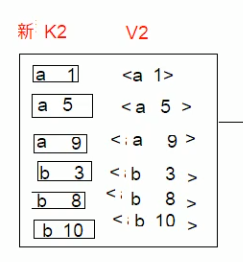
转为 新的 K3V3
新的 K3V3 就是排好序的东东
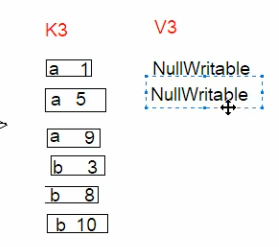
最后在输出 TextOutputFormat
代码部分
JobMian
public class JobMain extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int status = ToolRunner.run(configuration,new JobMain(), args);
System.out.println("任务运行状态 :: "+status);
}
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(),"sortJob");
// 在集群上运行的话,设置主类
job.setJarByClass(JobMain.class);
// 设置input
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("/path"));
// 设置 mapper
job.setMapperClass(SortMapper.class);
job.setMapOutputKeyClass(SortShuffle.class);
job.setMapOutputValueClass(Text.class);
// 设置 Shuffle 阶段 排序
// 这里的排序会自己调用对应的方法
// 设置 reduce 阶段
job.setReducerClass(SortReduce.class);
job.setOutputKeyClass(SortShuffle.class);
job.setOutputValueClass(NullWritable.class);
// 设置 Output
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("/"));
// 设置 等待运行
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
}
Mapper
public class SortMapper extends Mapper<LongWritable,Text, SortShuffle,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String str = value.toString();
String[] split = str.split(",");
SortShuffle sortShuffle = new SortShuffle();
sortShuffle.setFirst(split[0]);
sortShuffle.setSecond(Integer.valueOf(split[1]));
context.write(sortShuffle,new Text(str));
}
}
Reduce
public class SortReduce extends Reducer<SortShuffle,Text, SortShuffle, NullWritable> {
@Override
protected void reduce(SortShuffle key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
Shuffle
SortShuffle
public class SortShuffle implements WritableComparable<SortShuffle> {
private String first;
private int second;
/**
* 实现排序规则
* @param o
* @return
*/
@Override
public int compareTo(SortShuffle o) {
// 先比较 first
int result = this.first.compareTo(o.first);
// 两个字符串相等,则比较second
if (result == 0) {
return this.second - o.second;
}
return result;
}
/**
* 序列化
* @param dataOutput
* @throws IOException
*/
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(first);
dataOutput.writeInt(second);
}
/**
* 反序列化
* @param dataInput
* @throws IOException
*/
@Override
public void readFields(DataInput dataInput) throws IOException {
this.first = dataInput.readUTF();
this.second = dataInput.readInt();
}
public String getFirst() {
return first;
}
public void setFirst(String first) {
this.first = first;
}
public int getSecond() {
return second;
}
public void setSecond(int second) {
this.second = second;
}
@Override
public String toString() {
return first + "\t" + second;
}
}
















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









