







概述
Combiner 是在map端,对map端的输出做一次合并.
减少map和reduce 节点之间的数据传输量.
是 Reduce 的子组件
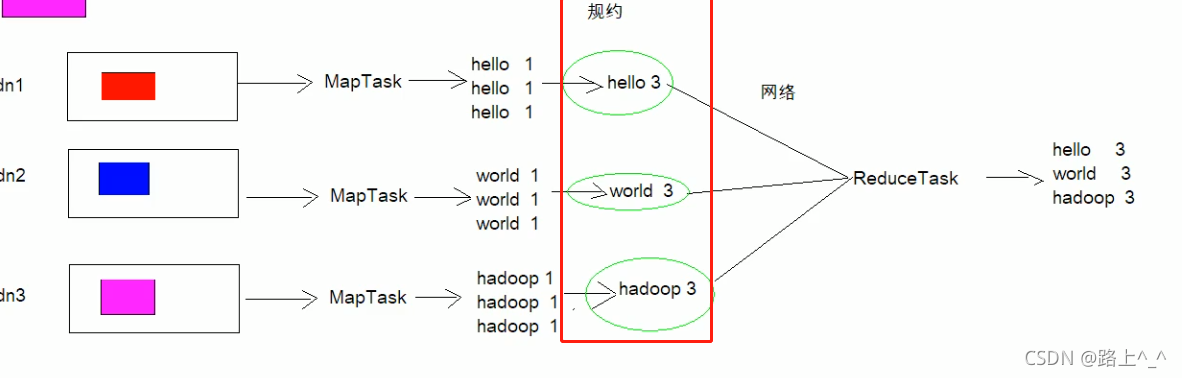
是在每个 MapTask之后,将map 方法要输出的数据进行合并.
将相同 key 的数据合并
思路
写两个 reduce. 都继承 reduce
只不过在 job中将其中一个 reduce 设置为 Combiner
代码
public class MyCombiner extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
Long count = 0L;
for (LongWritable value : values) {
count += value.get();
}
context.write(key,new LongWritable(count));
}
}
public class JobMainCombiner extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int status = ToolRunner.run(configuration, new JobMainCombiner(), args);
System.out.println("任务运行状态是 :: "+status);
}
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(), "JobCombiner");
// 设置在集群环境下运行
job.setJarByClass(JobMainCombiner.class);
// 设置读取的路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("/suibian"));
// mapper
job.setMapperClass(combinerMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置 shuffle 规约
job.setCombinerClass(MyCombiner.class);
// 设置 reduce
job.setReducerClass(combinerReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("/suibian"));
return job.waitForCompletion(true) ? 0 : 1;
}
}
















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









