







1 操作数据表中的记录
1.1 插入记录INSERT
插入记录共有三种方式:
1.1.1 第一种方式
INSERT [INSERT] tbl_name [(col_name,…)] {VALUES|VALUE} ({expr|DEFAULT},…),(…),…- 创建一个空的数据表,字段:id,wname,wpassword,wsalary,wsex:
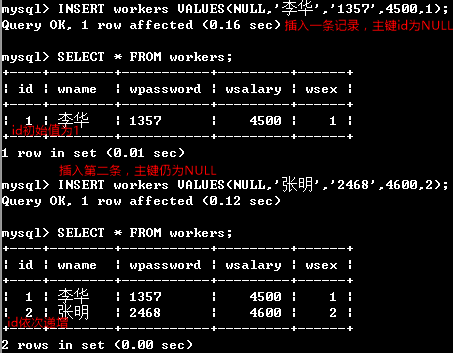
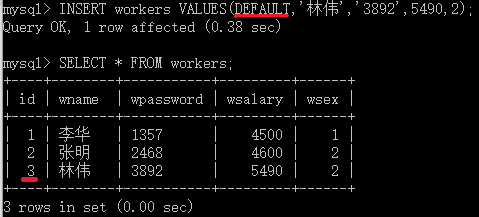
插入记录,id字段自动编号,可以使用NULL或DEFALUT使其采用默认的编号形式
- 插入记录的值可以是数学表达式、字符表达式或函数都可以;
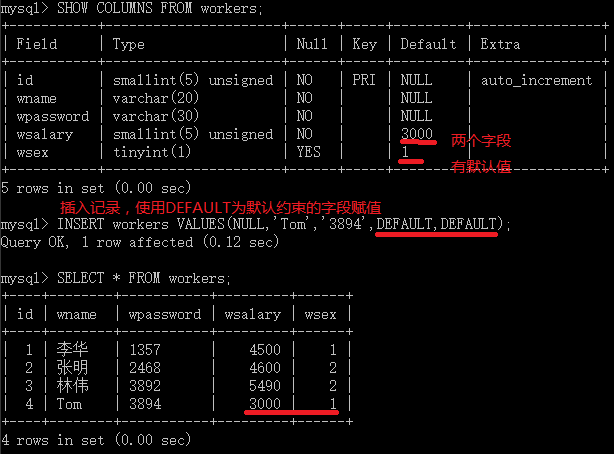
对于具有默认值的数据,插入时可以使用DEFAULT;
插入多个记录:
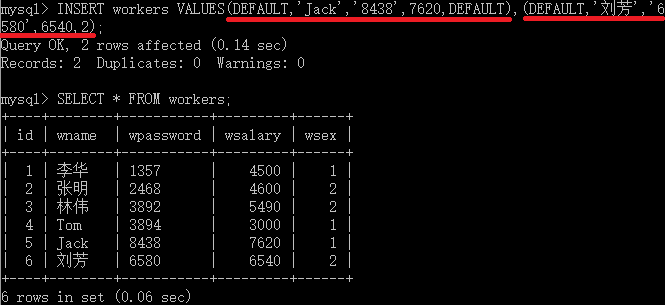
1.1.2 第二种方式
INSERT [INTO] tbl_name SET col_name={expr | DEFAULT},...与第一种方式的区别在于,此方法可以使用子查询(SubQuery),该方法一次只能插入一条记录
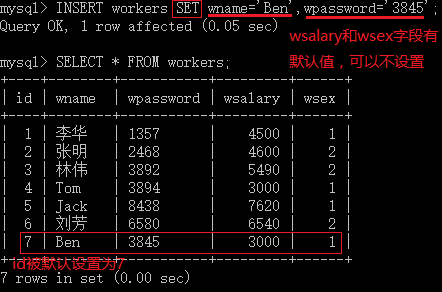
1.1.3 第三种方式
INSERT [INTO] tbl_name [(col_name,...)] SELECT ...此方法可以将查询结果插入到指定数据表
1.2 单表更新记录UPDATE
UPDATE [LOW_PRIORITY] [IGNORE] table_reference SET col_name1={expr1|DEFAULT} [,col_name2={expr|DEFAULT}] ... [WHERE where_condition][WHERE where_condition]指出了更新位置,如果不加该语句,将导致记录全部更新



1.3 单表删除记录DELETE
DELETE FROM tbl_name [WHERE where_condition]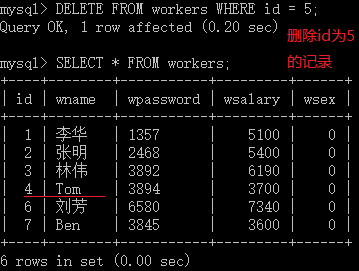
如果重新的插入一条记录,自增字段将在最大数值的基础上增加1,而不会去补充前面确实的数值:
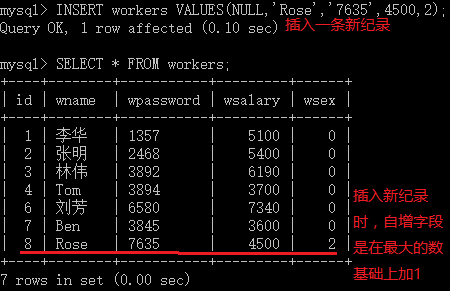
1.4 查询表达式SELECT
SELECT select_expr [,select_expr ...]
[
FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | position} [ASC | DESC], ...]
[HAVING where_condition]
[ORDER BY {col_name | expr | position} [ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
]- 每个表达式表示想要的一列,必须有至少一个
- 多个列之间以英文逗号分隔
- 星号()表示所有列,tbl_name.可以表示命名表的所有列
- 查询表达式可以使用[AS] alias_name 为列赋予别名
- 别名可用于 GROUP BY , ORDER BY或HAVING字句
举例如下:
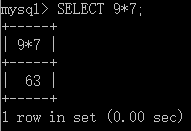
- SELECT 可以计算表达式的结果:
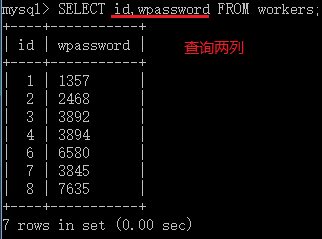
- 查询多列,命令中列的顺序可以和原表中列的顺序不一致,结果的顺序和查询表达式的顺序一致
- 使用tbl_name.colname可以查询多个表的不同列
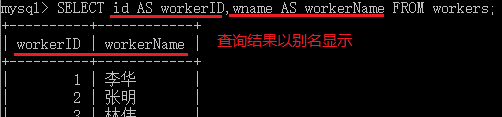
- 使用AS为列赋予别名,AS可以省略,但最好不省略

1.4.1 WHERE语句进行条件查询
- 条件表达式:对记录进行过滤,如果没有指定WHERE字句,则显示所有记录;在WHERE表达式中,可以使用MySQL支持的函数或运算符
- 在DELETE表达式中省略WHERE条件,将删除所有的记录,在UPDATE表达式中,省略WHERE条件,将更新全部的记录,在SELECT表达式中,将显示全部
1.4.2 GROUP BY语句对查询结果分组
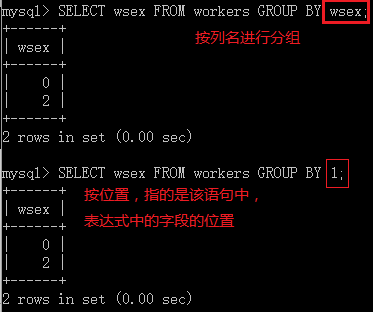
[GROUP BY {col_name | position} [ASC | DESC],...]既可以按照列名(col_name)分组,也可以按照列的位置(position)
分组,ASC(默认)和DESC指定按升序或降序排列
当需要对多个列分组时,在MySQL5.7.5之后,会报如下错误:

这个sql语句违背了sql_mode=only_full_group_by
在网上http://wangzhichao.blog.51cto.com/2643325/1773740搜索到的解决办法:
set@@sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';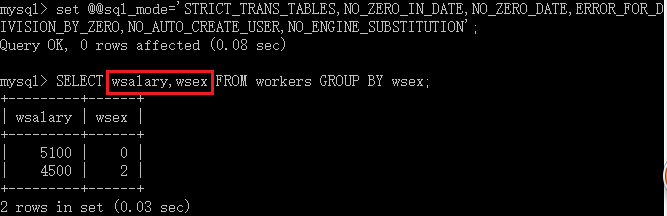
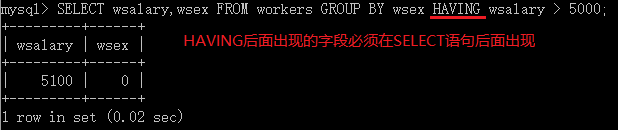
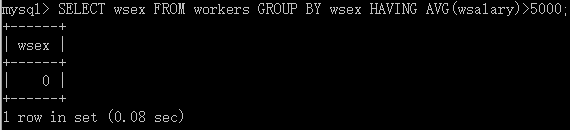
使用HAVING语句设置分组条件
[HAVING where_condition]
HAVING后面也可以跟一个聚合函数:求最大值MAX,求最小值MIN,求平均值AVG,计数COUN,求和SUM等等。
1.4.3 ORDER BY语句对查询结果排序
[ORDER BY {col_name | expr | position} [ASC | DESC],...]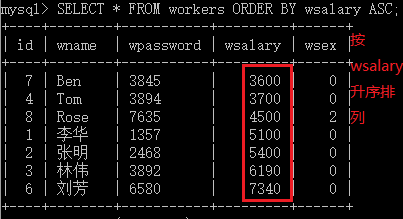
也可以按两个字段进行排序,按字段出现的顺序选择优先级
1.4.4 LIMIT语句限制查询数量
使用LIMIT子句来限制结果返回的数量
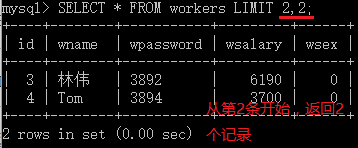
[LIMIT {[offset,] row_count | row_count OFFFSET offset]}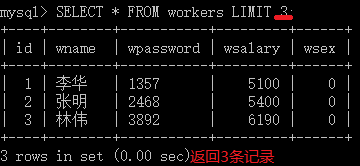
数据表中的记录从0开始计数,只与结果集中记录的顺序有关,和字段无关
使用INSERT SELECT语句将一个数据表中的记录插入到另一个数据表中:
INSERT tbl_name2([col_name,...]) SELECT col_name1,col_name2,... FROM tbl_name1[WHERE expr,....]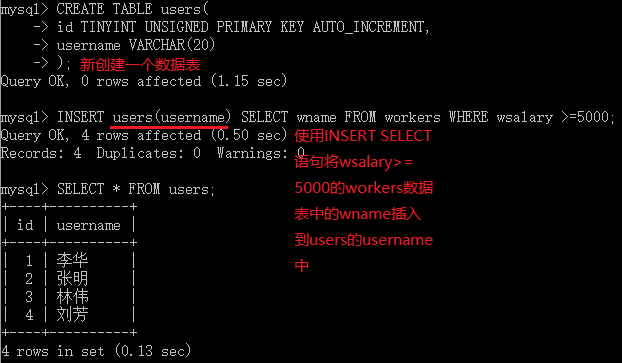
1.5 小结
- 记录的写操作:增(INSERT)、删(DELETE)、改(UPDATE)
- 记录的读操作:查(SELECT)
2 子查询与连接
子查询(Subquery)是指出现在其他SQL语句内的SELECT子句
如:
SELECT * FROM t1 WHERE col1=(SELECT col2 FROM t2);
其中 SELECT * FROM t1 称为Outer Query/Outer Statement
SELECT col2 FROM t2 称为SubQuery
- 子查询指嵌套在查询内部,且必须始终出现在圆括号内;
- 子查询可以包括多个关键字或条件,如
DISTINCT,GROUP BY,ORDER BY,LIMIT,函数等; - 子查询的外层查询可以是:SELECT , INSERT , UPDATE , SET或DO,外层查询并不是指查找,这里是我们所知道的所有SQL命令的统称
- 子查询可以返回标量、一行、一列或还是子查询,得到的结果可以在INSERT、UPDATE或SELECT等语句中使用。
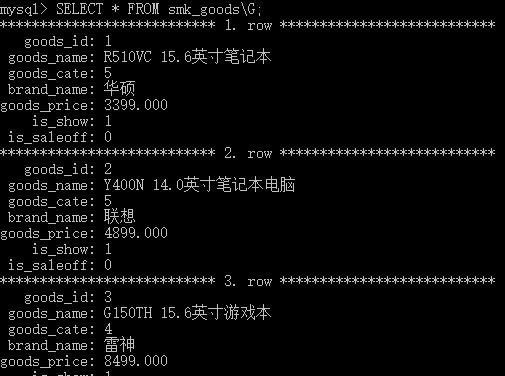
首先新建一个smk的数据库,在其中新建smk_goods的表
(goods_name,goods_cate,brand_name,goods_price,is_show,is_saleoff)
插入22条记录:
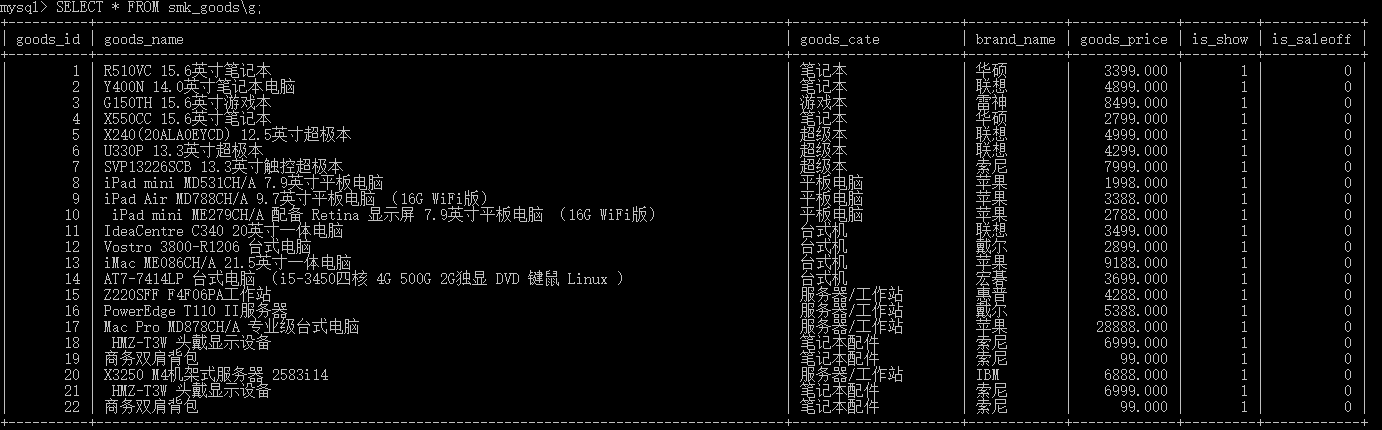
备注:设置编码格式:SET NAMES 编码格式
2.1 引发子查询的三种情况
operand:操作数
comparison_operator:运算符
- 使用比较运算符的子查询
- 使用比较运算符的子查询
=、>、<、>=、<=、<>、!=、<=> - 语法结构
operand comparison_operator subquery
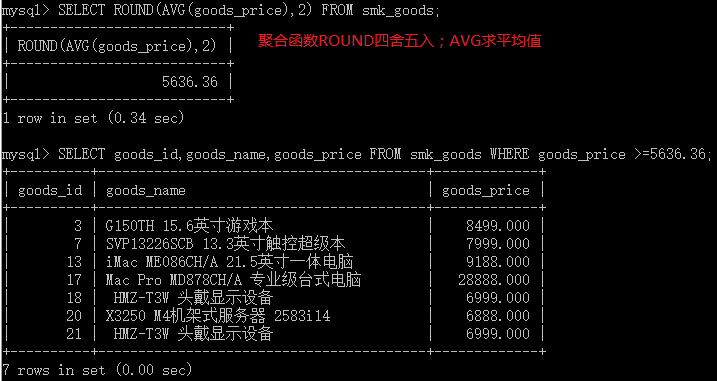
其中,聚合函数ROUND用于四舍五入,AVG用于求平均值。第二条语句显示了产品价格大于所有商品平均价格的商品,其中的5636.36用子查询代替:
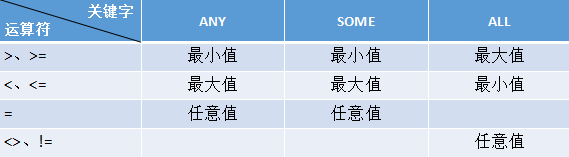
- 用ANY、SOME或ALL修饰比较运算法
如下语句,子查询返回的结果返回了多行,应该明确告诉系统大于哪一个数值
所以在这里需要使用ANY、SOME或ALL:
operand comparison_operator ANY(subquery)
operand comparison_operator SOME(subquery)
operand comparison_operator ALL(subquery)
SOME和ANY是等价的。
- 使用比较运算符的子查询
使用[NOT ] IN的子查询
- 语法结构
operand comparion_operator [NOT] IN (subquery)
其中:
= ANY 运算符与IN等效
!=ALL或<>ALL运算符与NOT IN等效
- 语法结构
使用[NOT] EXISTS的子查询
如果子查询返回任何行,EXISTS将返回TRUE;否则为FALSE。使用较少





2.2 使用INSERT…SELECT插入记录
在smk_goods中,单元中存储了许多重复信息如goods_cate和goods_name,为了避免过多重复信息占据过多存储,可以使用外键,首先新建一张表smk_goods_cates:

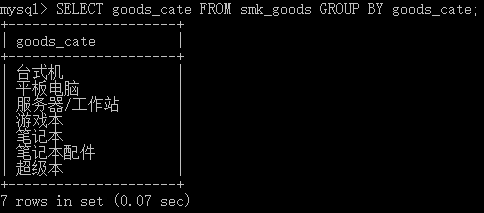
将smk_goods中的分类信息goods_cate插入到smk_goods_cates中:
先对goods_cate进行分组
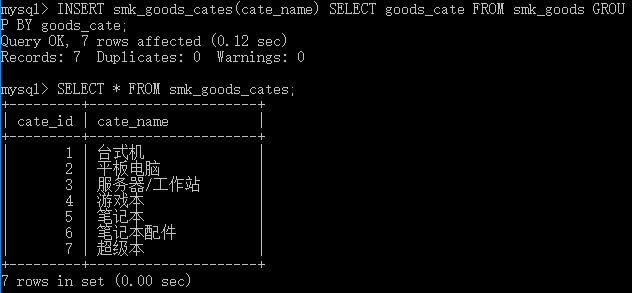
然后将得到的信息一次性插入到smk_goods_cate中,将查询的结果写入数据表:
INSERT [INTO] tbl_name[(col_name,...)] SELECT ...
但是这样smk_goods中仍然没有更新信息,接下来,我们应该参照分类表smk_goods_cates来更新产品表smk_goods。
2.3 多表更新
UPDATE table_references
SET col_name1 = {expr1|DEFAULT}
[,col_name1 = {expr1|DEFAULT}]...
[WHERE where_condition]其中,table_references指的是表的参照关系(2.3.2节)
2.3.1 连接类型
- INNER JOIN,内连接
- 在MySQL中,JOIN,CROSS JOIN和INNER JOIN等价
- LEFT [OUTER] JOIN,左外连接
- RIGHT [OUTER] JOIN,右外连接
2.3.2 表的参照关系
table_references是指如下代码:
table_reference
{[INNER | CROSS] JOIN | {LEFT|RIGHT} [OUTER] JOIN}
table_reference
ON conditional_expr其中,conditional_expr是指连接的条件

已经更新完毕:
2.4 多表更新——一步到位
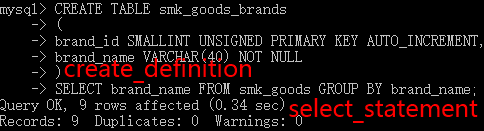
创建数据表同时将查询结果写入数据表
CREATE TABLE [IF NOT EXISTS] tbl_name
[(create_definition,...)]
select_statement再创建一个数据表smk_goods_brands,将商品品牌放入一个数据表:
和2.3节类似,参照品牌表更新商品表:

其中,连接条件中使用了两个表中相同名字的brand_name,所以要给两张表其别名以避免错误。
但是,可以发现smk_goods中brand_name和goods_cate的属性仍然是字符型,可使用CHANGE修改:

这里,外键不一定是物理的,即加“FOREIGN KEY”,这种形式的外键成为事实的外键,而且是我们常用的形势
2.5连接的语法结构
在2.3和2.4节已经用到了连接,MySQL在SELECT语句、多表更新、多表删除语句中支持JOIN操作,连接肯定是至少需要两张表。
table_reference1 //数据表参照
{[INNER|CROSS] JOIN | {LEFT|RIGHT} [OUTER] JOIN} //连接条件
table_reference2 //数据表参照
ON conditional_expr //连接条件数据表参照table_reference
tbl_name [[AS] alias] | table_subquery [AS] alias- 为了避免两张数据表中属性名相同,数据表可以使用tbl_name AS alias_name 或 tbl_name alias_name 赋予别名,来进行查询
- table_subquery可以作为子查询使用在FROM子句中,这样的子查询必须为其赋予别名
连接条件
使用ON关键字来设定连接条件,也可以使用WHERE来代替。
(通常使用ON关键字来设定连接条件,使用WHERE关键字进行结果集记录的过滤 )- 内连接:仅显示左表和右表符合连接条件的记录
- 左外连接:显示左表的全部记录及右表符合连接条件的记录
- 右外连接:显示右表的全部记录及左表符合连接条件的记录
2.5.1多表连接
实现三张表的连接,将smk_goods中的brand_name和goods_cate用另外两个表中的数据表示并显示出来:
2.5.2 关于连接的几点说明


以左外连接为例,A LEFT JOIN B join_condition:
- 数据表B的结果集依赖于数据表A
- 数据表A的结果集根据左连接条件依赖于除B表以外的所用数据表
- 左外连接条件决定如何检索数据表B(在没有指定WHERE条件的情况下)
- 如果数据表A的某条记录符合WHERE条件,但是在数据表B不存在符合连接条件的记录,将生成一个所有列为空的额外的B行。
如果使用内连接查找的记录在连接数据表中不存在,并且在WHERE子句中尝试了一下操作:col_name IS NULL时,如果col_name被定义为NOT NULL,MySQL将在找到符合连接条件的记录后停止搜索更多的行。
2.6 无限级分类表设计
在许多数据中,每种分类下还有许多子类,每个子类下还有子类,往往是无限做分类,那么无限分类的数据表如何设计,随着分类的增多,我们不可能去设计无限张表,一般我们才用如下形式的数据表:
ATE TABLE smk_goods_types(
type_id SMALLINT UNSIGNED PRIMARY KEY AUOT_INCREMENT,
type_name VARCHAR(20) NOT NULL,
parent_id SMALLINT UNSIGNED NOT NULL DEFAULT 0
);至少存在三个字段:分类的ID,分类的名称和它父类的ID。
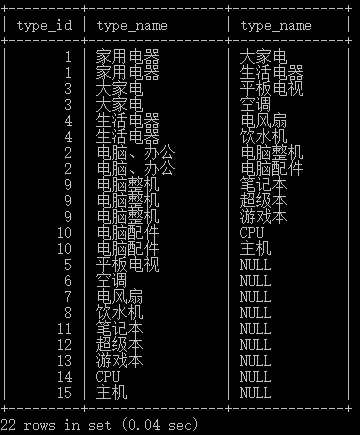
创建上述数据表,并插入了如下数据:
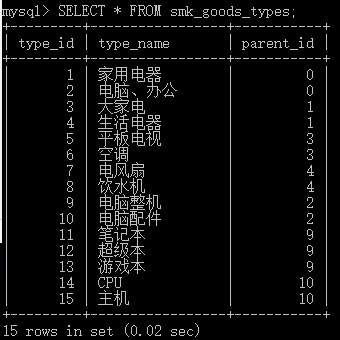
上述表明:
- 家用电器、电脑办公等为顶级分类,它没有父节点
- 大家电、生活家电等属于家用电器的子类,平板电视、空调等又属于大家电的子类
- 以此类推
这样又产生了一个问题,我们如何进行查找:自身连接(同一个数据表对其自身进行连接),自身连接其实和两张表连接是一样的。

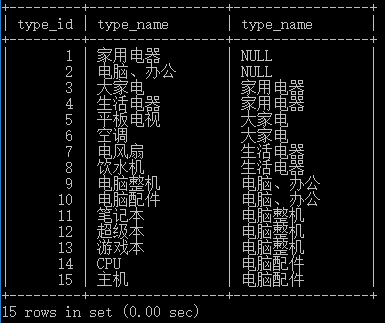
我们得到了子类和其对应的父类,同样的我们也可以得到父类和它的子类:

2.7 多表删除
DELETE tbl_name [.*] [,tbl_name[.*]] ...
FROM table_references
[WHERE where_condition]在smk_goods数据表中,有些商品的名字是相同,使用如下语句:

将商品按商品名分类,并选出数量大于1(即重复)的商品。
这样我们可以参照这张表将smk_goods中重复的商品删除:
















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









