







第八章 XPath解析
8.1 XPath概述
XPath是XML路径语言,它可以在XML文件和HTML文件中进行搜索,可以在爬虫中对相关网站的HTML文件中进行有效信息的抓取。介绍XPath中的常用路径表达式:
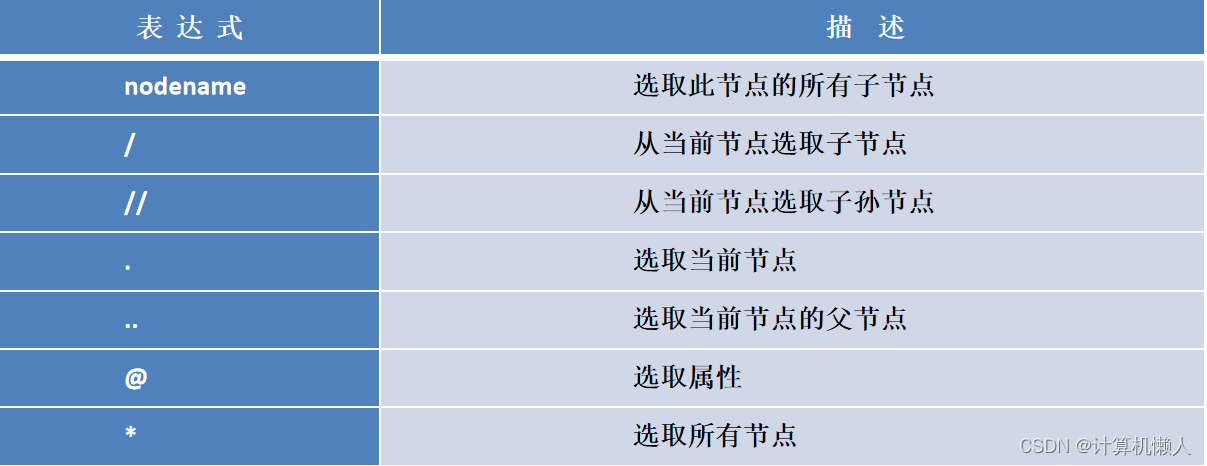
以下解析代码都会运用到这些表达式。
8.2 解析操作
因为XPath提取信息需要第三方库支持,所以需要引入一个第三方模块,在此介绍性能强大的lxml模块,它面向多个文件格式,而且解析效率高,加速爬虫速率。
8.2.1 解析HTML
1.parse()方法
parse()主要用于解析本地的HTML文件,举例如下:
from lxml import etree # 导入etree子模块
parser=etree.HTMLParser() # 创建HTMLParser对象
html = etree.parse('demo.html',parser=parser) # 解析demo.html文件
html_txt = etree.tostring(html,encoding = "utf-8") # 转换字符串类型,并进行编码
print(html_txt.decode('utf-8')) # 打印解码后的HTML代码而实现此方法的,parse函数只能面对本地的文件,即存放在磁盘中的文件,并且需要将代码和文件放在同一个文件夹中。
2.HTML()方法
解析字符串类型的HTML代码。这两种代码本质上并无区别,因为它们都是针对一个相同的HTML代码,但是上一种方法面对的是文件类型,将文件导入进行解析;但是这一种方法是将HTML代码直接加入到解析代码中,如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<title>标题文档</title>
</head>
<body>
<img src="./demo_files/logo1.png" />
<br />
hello 明日科技 ~
</body></html>'''
html = etree.HTML(html_str) # 解析html字符串
html_txt = etree.tostring(html,encoding = "utf-8") # 转换字符串类型,并进行编码
print(html_txt.decode('utf-8')) # 打印解码后的HTML代码8.2.2 获取所有节点
对获取所有节点的情况,需要使用“//*”加入到xpath的函数中,如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li> <a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="Java API文档">Java API文档</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的下载">JDK的下载</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的安装">JDK的安装</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="配置JDK">配置JDK</a> </li>
</ul>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
node_all = html.xpath('//*') # 获取所有节点
print('数据类型:',type(node_all)) # 打印数据类型
print('数据长度:',len(node_all)) # 打印数据长度
print('数据内容:',node_all) # 打印数据内容
# 通过推导式打印所有节点名称,通过节点对象.tag获取节点名称
print('节点名称:',[i.tag for i in node_all])代码先是进行lxml模块的导入,然后就将HTML代码复制进html_str变量中,对这一串字符串类型的HTML代码进行HTML()方法解析,运用xpath对数据进行抓取,符号“//*”表示抓取所有节点,所以程序将会对所有标签进行抓取,如div、ul、li、html等等,具体执行结果如下:
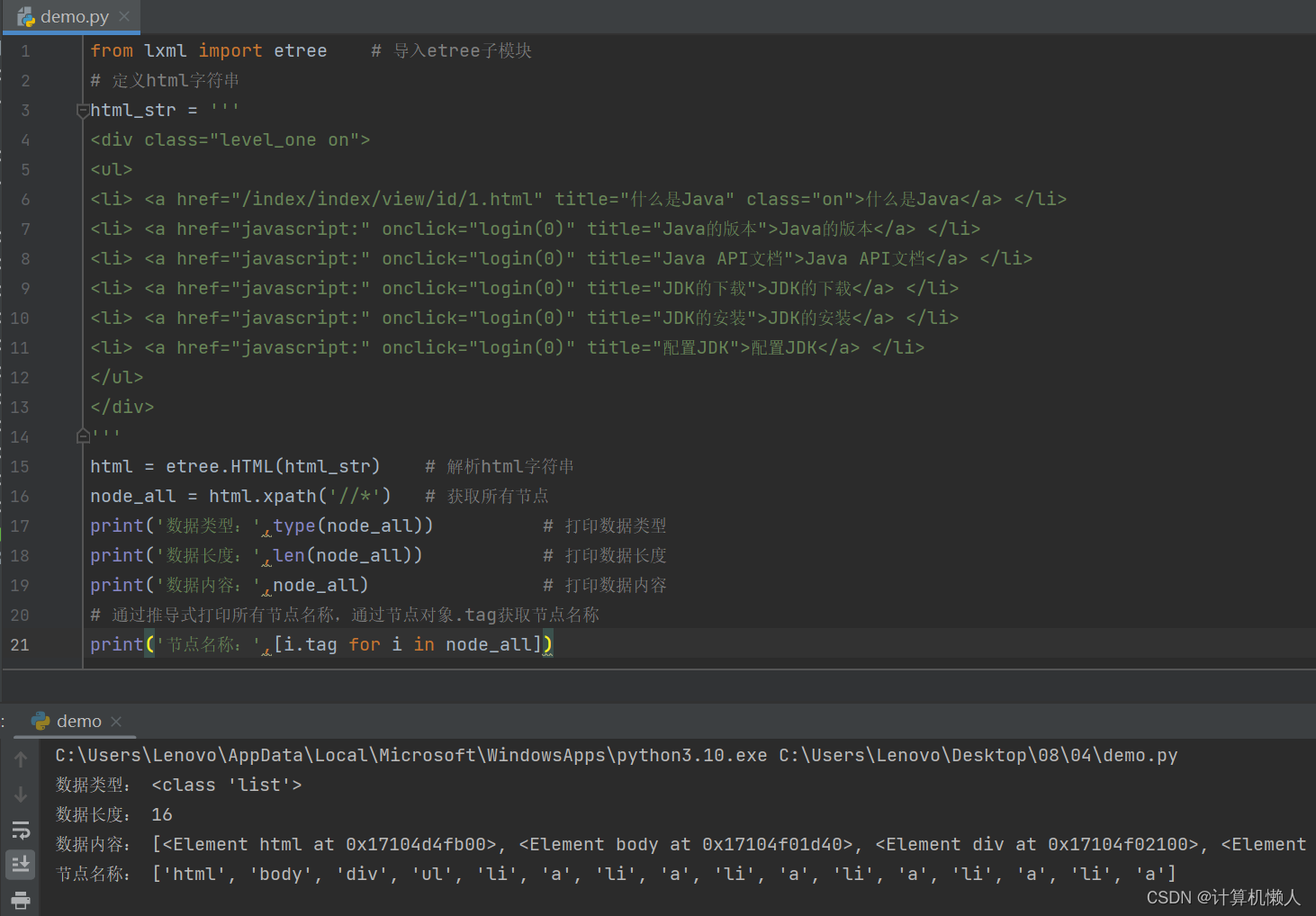
一共有16节点得到抓取,对照源代码可以发现抓取节点中多出了两个节点,分别是body和html,虽然这两个节点在代码中未出现,但是它们是属于HTML文件必备的标签,所以属于默认携带,即抓取所有节点时,也会被抓取。
如果只想对li这个节点进行全部抓取呢?那就要在符号中的“*”号替换成“li”节点,就可以对所有的li节点进行抓取了,这个在爬虫xpath过程中很常用,如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li> <a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="Java API文档">Java API文档</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的下载">JDK的下载</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的安装">JDK的安装</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="配置JDK">配置JDK</a> </li>
</ul>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串,html字符串为上一示例的html字符串
li_all = html.xpath('//li') # 获取所有li节点
print('所有li节点',li_all) # 打印所有li节点
print('获取指定li节点:',li_all[1]) # 打印指定li节点
li_txt = etree.tostring(li_all[1],encoding = "utf-8") # 转换字符串类型,并进行编码
# 打印指定节点的HTML代码
print('获取指定节点HTML代码:',li_txt.decode('utf-8'))代码中,设置了li_all数组,里面储存了所有抓取的li标签内容,在第二个print函数中,对li标签的位置进行了固定,要求输出li_all数组中的第二个li标签内容,因为数组的计数从0开始,所以1代表了第二个。最后对指定li节点的内部代码进行输出,具体如下:
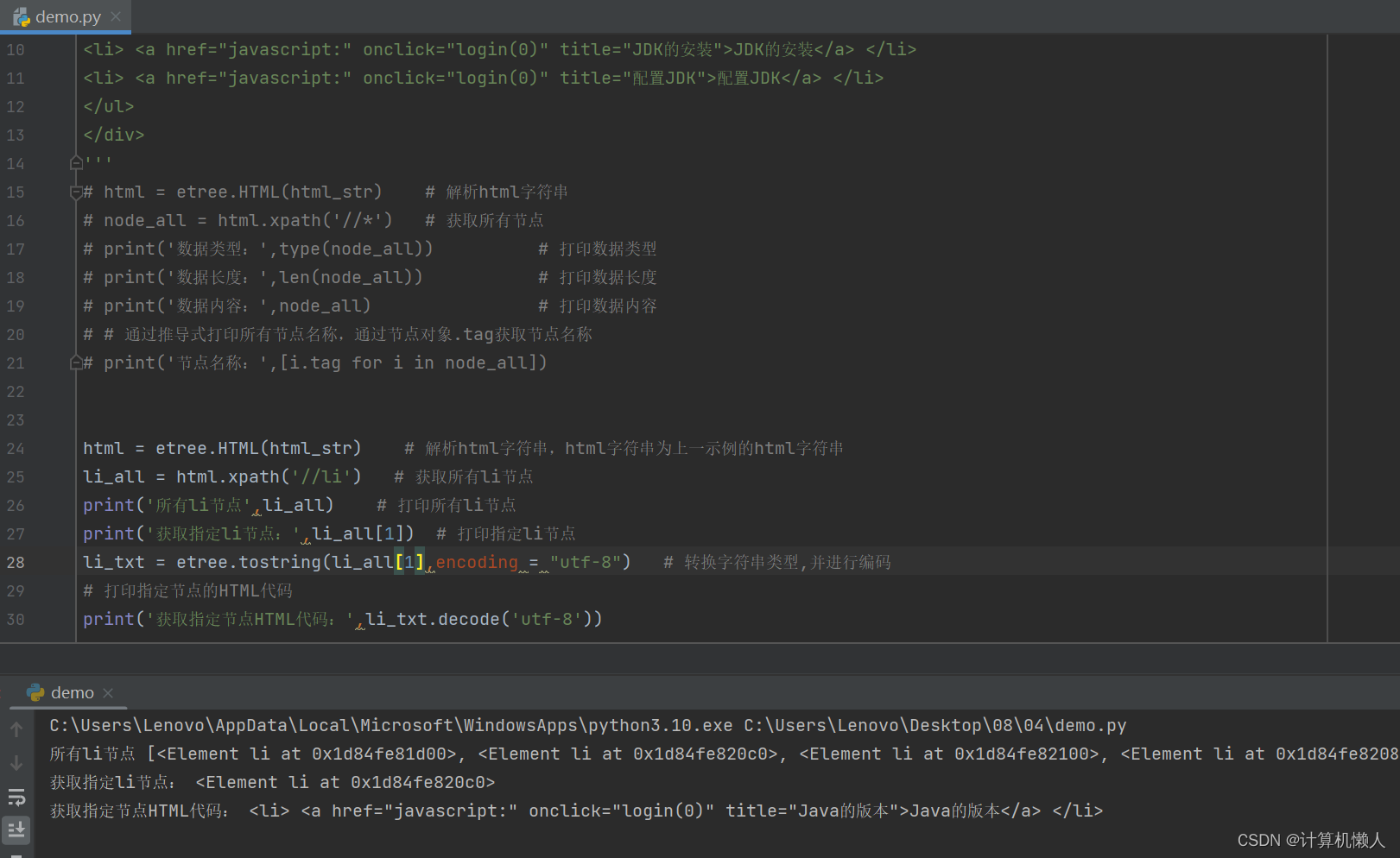
由图可知,输出的结果为第二个li标签中的HTML代码,运行结束。
8.2.3 获取子节点
子节点,就是节点下属的直接节点,需要用“/”来抓取。需要抓取子节点,首先要定位它的上属节点在哪儿。例如,如果要获取li节点下的a子节点,就可以先定位到li标签,即“//li”,然后获取直接子节点a,即“//li/a”。示例如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li>
<a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a>
<a>Java</a>
</li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="Java API文档">Java API文档</a> </li>
</ul>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
a_all = html.xpath('//li/a') # 获取li节点中所有子节点a
print('所有子节点a',a_all) # 打印所有a节点
print('获取指定a节点:',a_all[1]) # 打印指定a节点
a_txt = etree.tostring(a_all[1],encoding = "utf-8") # 转换字符串类型,并进行编码
# 打印指定节点的HTML代码
print('获取指定节点HTML代码:',a_txt.decode('utf-8'))程序运用HTML方法对代码进行解析后,设置a_all数组,用来储存所有a节点。由源代码可知,一共有3个li节点,4个a节点。最后在数组中查找指定a节点,数组[1]代表第二个a节点,所以输出“<a>Java</a>”。
同样,获取子孙节点同上,只是阶层跨越了一层,如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li>
<a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a>
<a>Java</a>
</li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
<li>
<a href="javascript:" onclick="login(0)" title="Java API文档">
<a>a节点中的a节点</a>
</a>
</li>
</ul>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
a_all = html.xpath('//ul//a') # 获取ul节点中所有子孙节点a
print('所有子节点a',a_all) # 打印所有a节点
print('获取指定a节点:',a_all[4]) # 打印指定a节点
a_txt = etree.tostring(a_all[4],encoding = "utf-8") # 转换字符串类型,并进行编码
# 打印指定节点的HTML代码
print('获取指定节点HTML代码:',a_txt.decode('utf-8'))和获取子节点的代码几乎一样,只是将符号为双“//”号。因为“/”号只用于直接的节点,跨越了一层的节点关系,“/”号无法抓取,所以“li”也需要改成“ul”,因为不能对直接节点使用“//”号,需要选取li标签的上一级。输出结果如下:
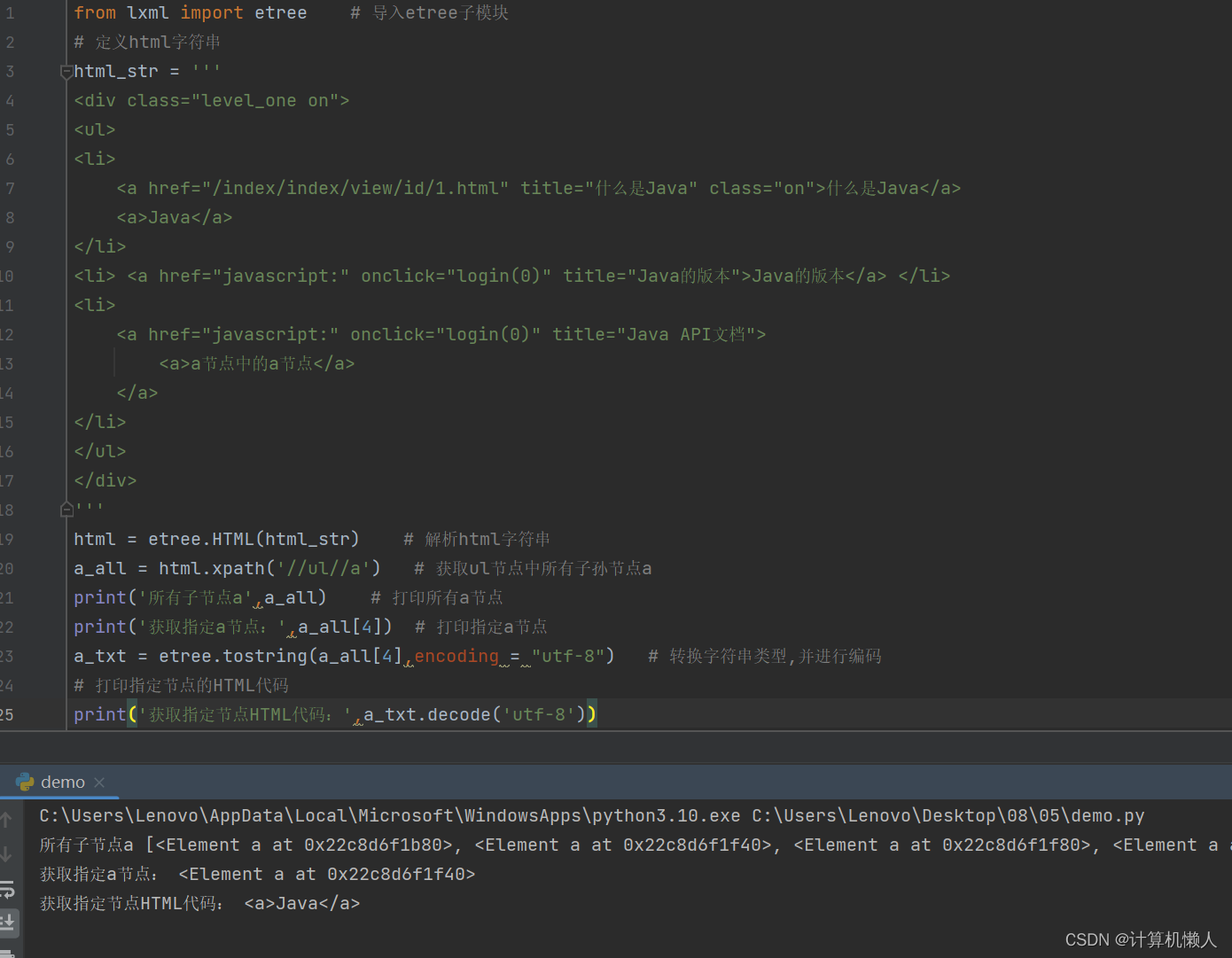
代码中中括号内的数字是4,所以选取第五个a节点,在源代码中发现,一共只有5个a标签,所以程序抓取了最后一个a节点内容,即“<a>a节点中的a节点</a>”。
8.2.4 获取父节点
父节点,也就是节点的上一级,例如li标签下有几个a节点,那么li节点就是a节点的父节点。获取父节点,需要使用“..”符号或者“/parent::*”号。具体实现代码如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li><a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a></li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
</ul>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
a_all_parent = html.xpath('//a/..') # 获取所有a节点的父节点
print('所有a的父节点',a_all_parent) # 打印所有a的父节点
print('获取指定a的父节点:',a_all_parent[0]) # 打印指定a的父节点
a_txt = etree.tostring(a_all_parent[0],encoding = "utf-8") # 转换字符串类型,并进行编码
# 打印指定节点的HTML代码
print('获取指定节点HTML代码:\n',a_txt.decode('utf-8'))按照前述的方法一样,将xpath解析的内容放入设置的数组中,在数组中对指定节点进行选取。此代码数组序号为0,则选取第一个a的父节点,即第一个li节点中的所有内容。
8.2.5 获取文本
获取文字可以使用text()方法,即指定到某个节点时,加上“/text()”来抓取文字。如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li><a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a></li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
</ul>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
a_text = html.xpath('//a/text()') # 获取所有a节点中的文本信息
print('所有a节点中文本信息:',a_text)此时程序抓去了所有a节点的内容,并调用text()方法进行抓取文字,输出结果如下:
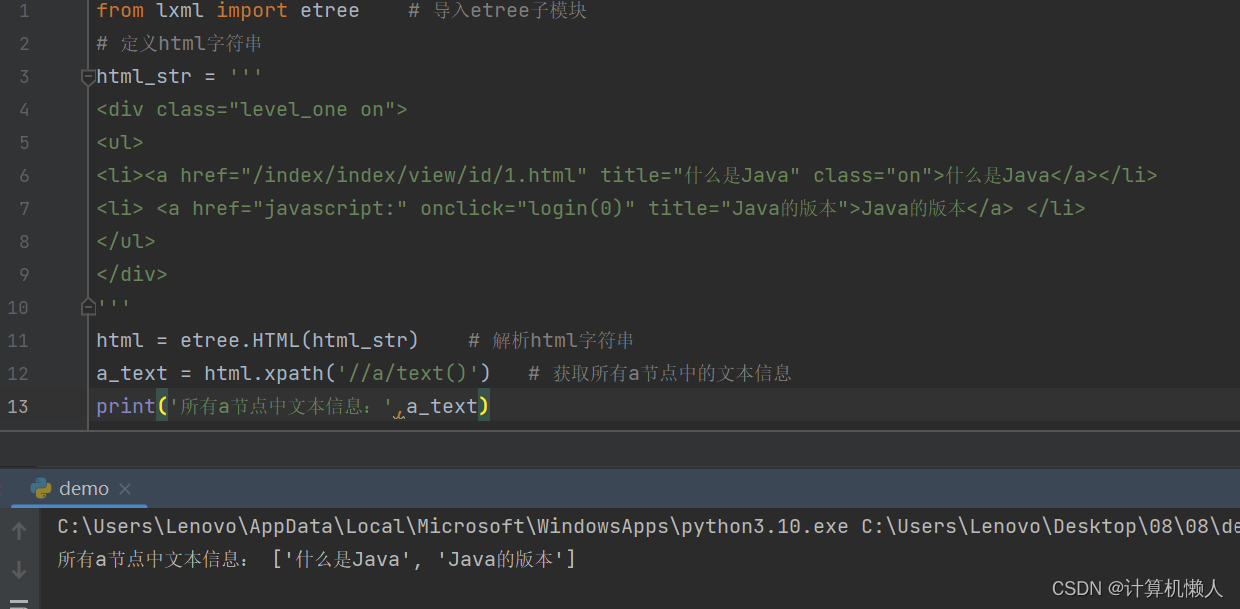
如图所示,程序将a节点中的两段文字全部抓取并输出,但是如果我只想要其中一段文字呢,不要两段文字同时输出,那需要怎么修改代码呢?例,我只想要第二个a节点中的文字,即“Java的版本”,如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li><a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a></li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
</ul>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
a_text = html.xpath('//ul/li[2]/a/text()') # 获取所有a节点中的文本信息
print('所有a节点中文本信息:',a_text)发现上述代码与源代码只差别在了xpath的内部代码,在众多节点中进行选择,也就是标签定位,代码中的“//ul/li[2]/a”就是在进行抓取功能的定位。li[2]代表ul父节点下的第二个li节点,这个地方不是数组,所以计数不是从0开始的,而是从1开始的,所以想要抓取第二个a节点的文字,就要定位在2上。同理,如果想要第一个li节点中a节点的文字,把2修改成1即可。输出如下:
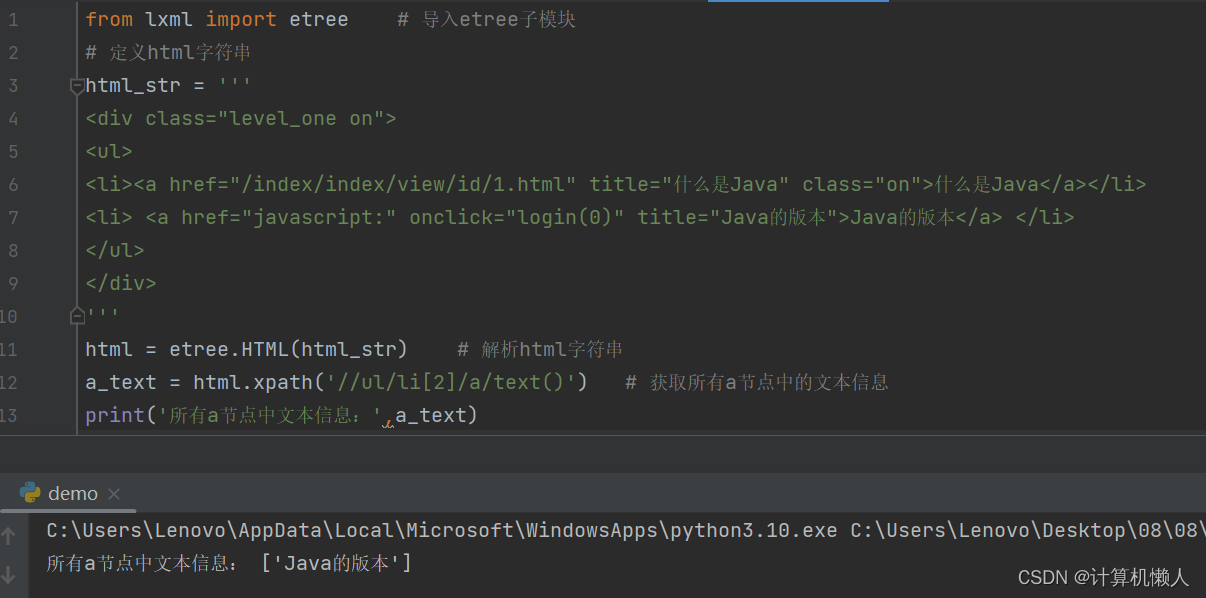
8.2.6 属性匹配及获取属性
1.属性匹配
<div class="video_scroll">
<div class="level">什么是Java</div>
<div class="level">Java的版本</div>
</div>在上述的HTML代码中,class="..."就是属性,而标签定位最常见的就是通过属性进行定位。上述代码,如果我们要获取代码中的两段文字,可以通过简单的定位获取,如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<div class="level">什么是Java</div>
<div class="level">Java的版本</div>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取所有class="level"的div节点中的文本信息
div_one = html.xpath('//div/text()')
print(div_one) # 打印class="level"的div中文本但是这种写法的输出结果并不是我们想要的,如图:
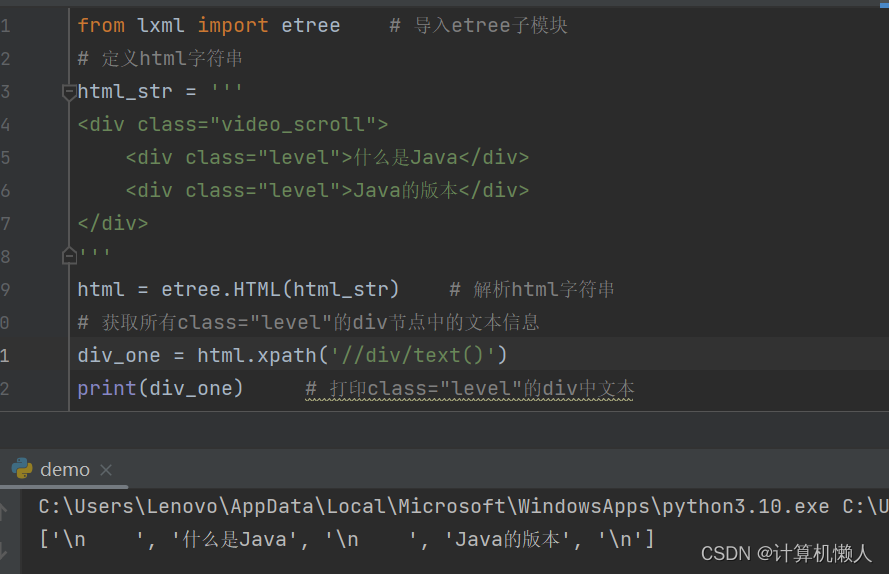
会出现除文字外的其他格式,所以如果想要纯文字的内容输出,就需要进行修改,如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<div class="level">什么是Java</div>
<div class="level">Java的版本</div>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取所有class="level"的div节点中的文本信息
div_one = html.xpath('//div/div/text()')
print(div_one) # 打印class="level"的div中文本当写入两个div后,程序就会知道抓取内部div的内容,而不是从第一个div就开始抓取,所以会出现“\n”符号。当然本节说的是属性匹配,所以用属性匹配更简单,不需要写两个div,因为观察到连个div后都有一个class属性,可以根据属性之间定位div,如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<div class="level">什么是Java</div>
<div class="level">Java的版本</div>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取所有class="level"的div节点中的文本信息
div_one = html.xpath('//div[@class="level"]/text()')
print(div_one) # 打印class="level"的div中文本这样,程序就会对class进行匹配,如果内容相同就会匹配成功,从而对匹配的内容进行解析,省去了复杂定位的麻烦,输出结果如下:
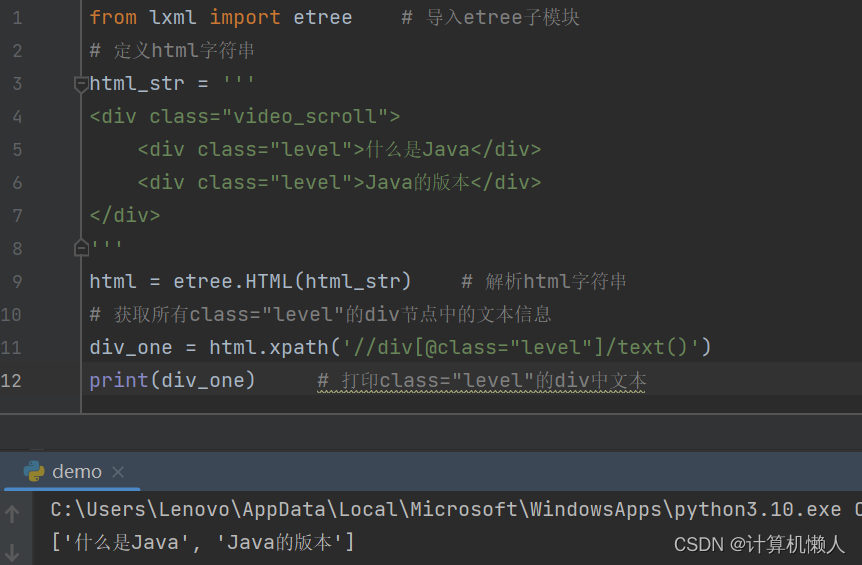
可见输出结果与两个div一致,并且减少了错误。
2.属性多值匹配
和第一点一样,区别在于当class里的属性值不同时,可以利用属性值进行单独文字的选择,如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<div class="level one">什么是Java</div>
<div class="level">Java的版本</div>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取所有class="level one"的div节点中的文本信息
div_one = html.xpath('//div[@class="level one"]/text()')
print(div_one) # 打印class="level one"的div中文本输出结果如下:
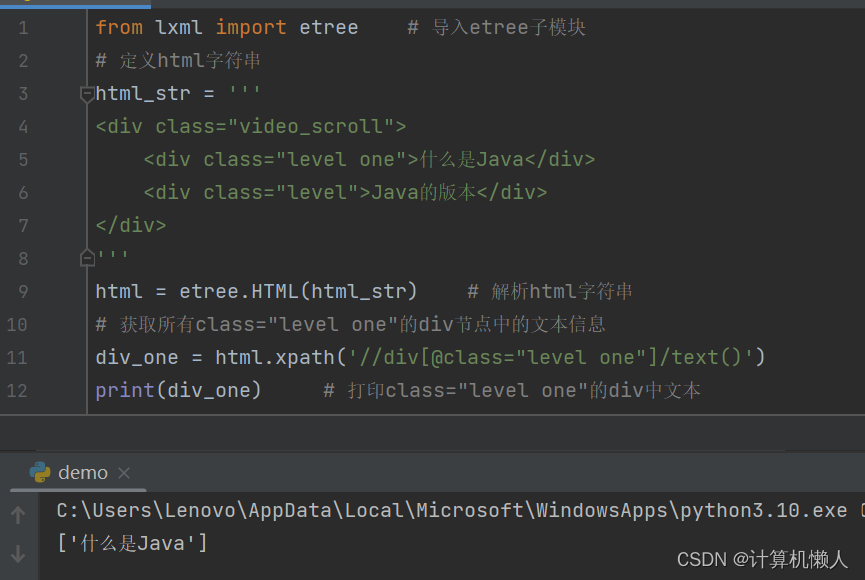
class里的值不同,所以需要哪一段文字,就可以将xpath中的匹配值换成哪个,十分简便。同时还诞生了一个问题,这种情况选择单个容易,如果需要全部文字呢?class值不同,怎么样进行全部选取呢?这就需要采用contains()方法,它中有两个参数,一是规定属性名称,如class,二是规定属性值,不同的是这个属性值不是一定的,只要被匹配的属性值中含有该规定属性值,就可以成功匹配。而代码中,两段文字的属性值中都含有level,所以可以把level作为规定属性值,具体代码如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<div class="level one">什么是Java</div>
<div class="level">Java的版本</div>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取所有class属性值中包含level的div节点中的文本信息
div_all = html.xpath('//div[contains(@class,"level")]/text()')
print(div_all) # 打印所有符合条件的文本信息输出结果如下:
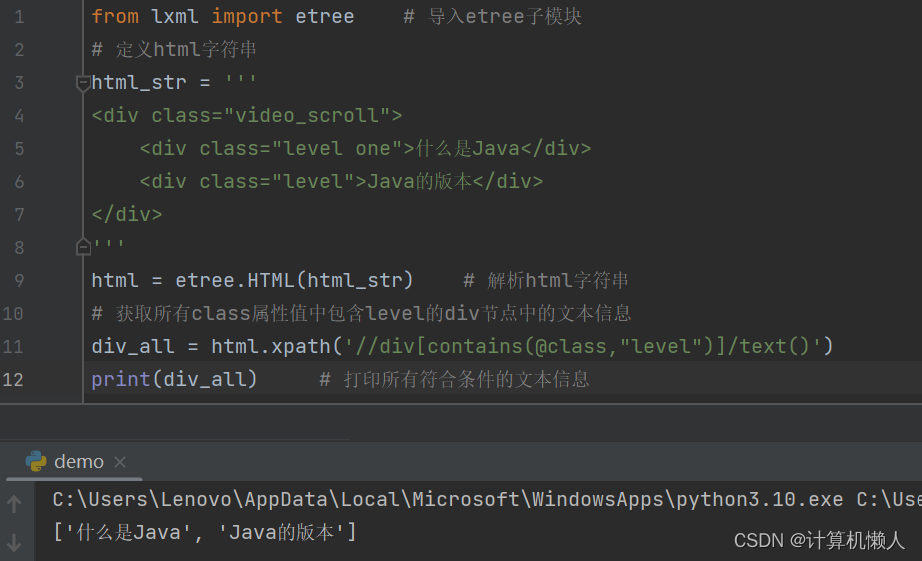
3.多属性匹配
我们在爬虫的过程中,通常也会遇到多属性的问题,例如class和id等等。如果我们只对一个属性进行规定,那么无法做到精准定位,可能会获取很多代码,所以为了确保无误,应该同时匹配很多值,才能精准获取指定节点的内容。如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<div class="level" id="one">什么是Java</div>
<div class="level">Java的版本</div>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取所有符合class="level与id="one"的div节点中的文本信息
div_all = html.xpath('//div[@class="level" and @id="one"]/text()')
print(div_all) # 打印所有符合条件的文本信息可以看到代码的div的子节点的属性有相同的部分,如果此处只对class属性进行规定,那就会出现情况:
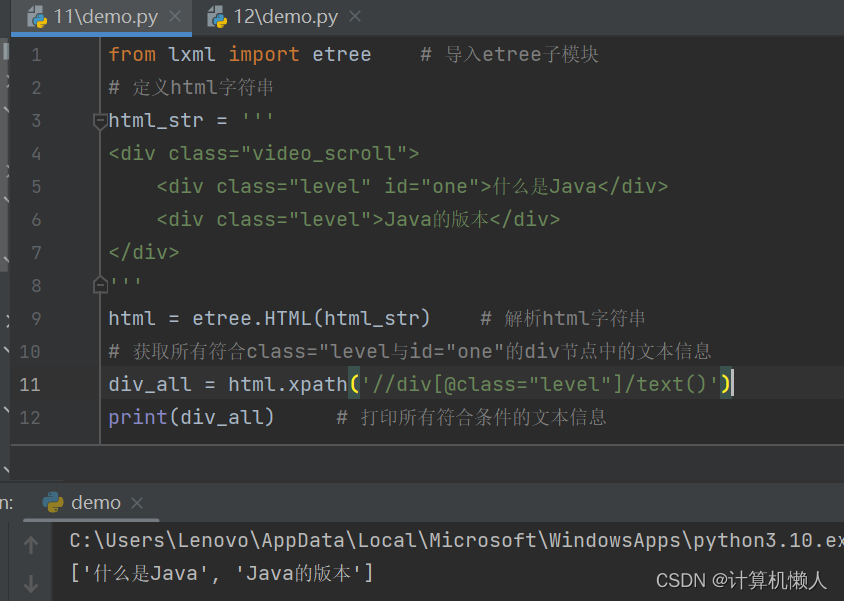
会把两段文字全部输出,但是我们只需要第一行的文字,那么就需要多属性匹配,把id也匹配,就会成功得到第一行文字内容,如下:
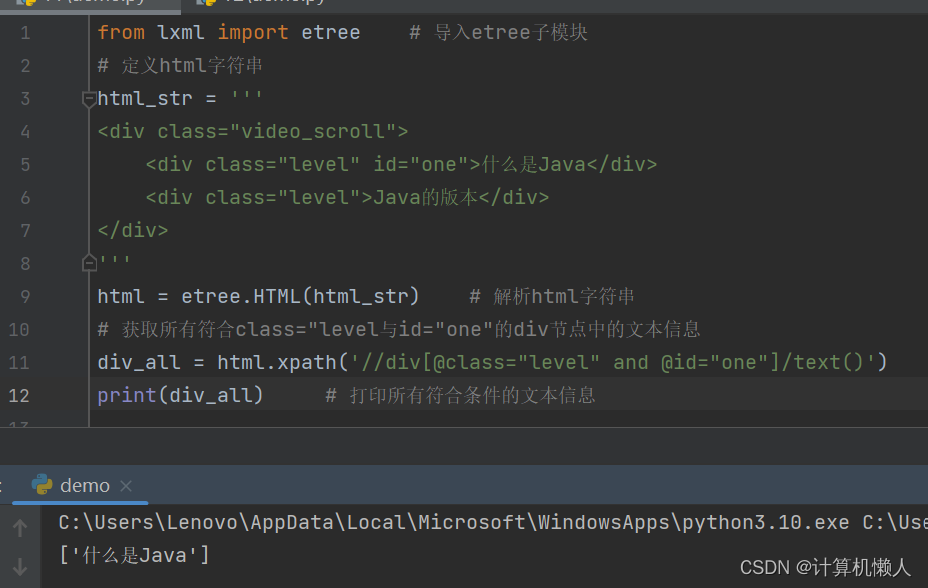
上述代码中出现了and运算符,and将两个属性串联在一起,表示同时满足。xpath中还提供了很多运算符,如下图:
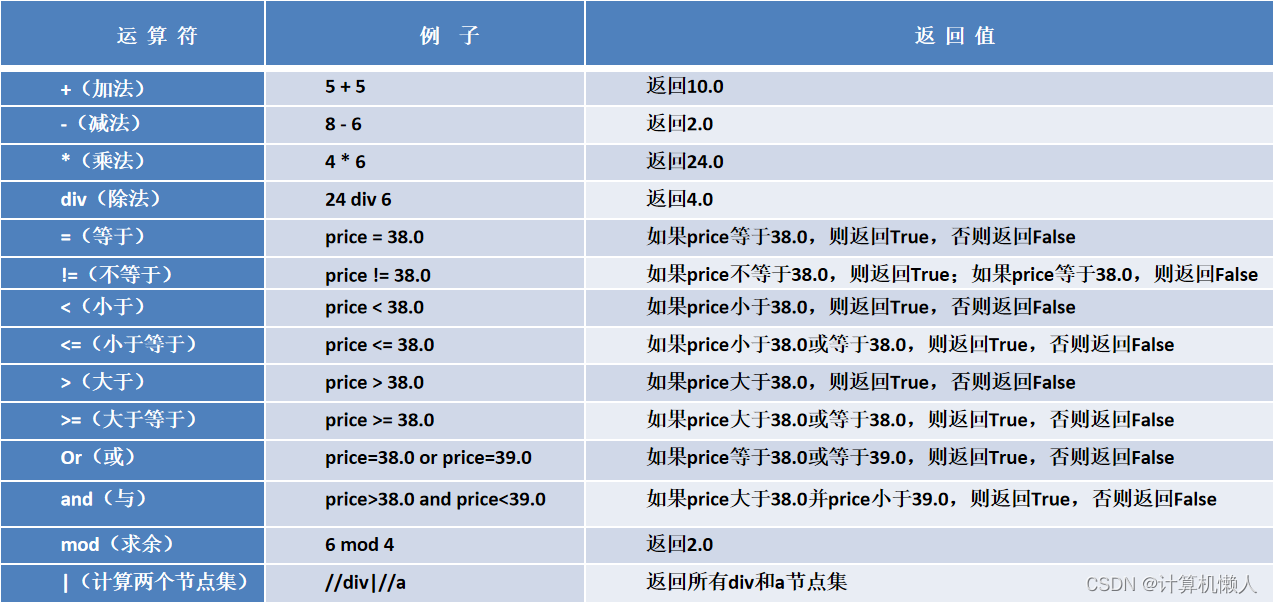
具体功能不做解释,用到时会进行说明。
4.获取属性
属性不光可以被匹配,也可以被获取,同样,也是使用“@”号,如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<li class="level" id="one">什么是Java</li>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取li节点中的class属性值
li_class = html.xpath('//div/li/@class')
# 获取li节点中的id属性值
li_id = html.xpath('//div/li/@id')
print('class属性值:',li_class)
print('id属性值:',li_id)标签定位到属性所属的标签后,使用“@”号对属性值进行抓取,但是一般用不到,主要作用是用来匹配属性。运行结果如下:
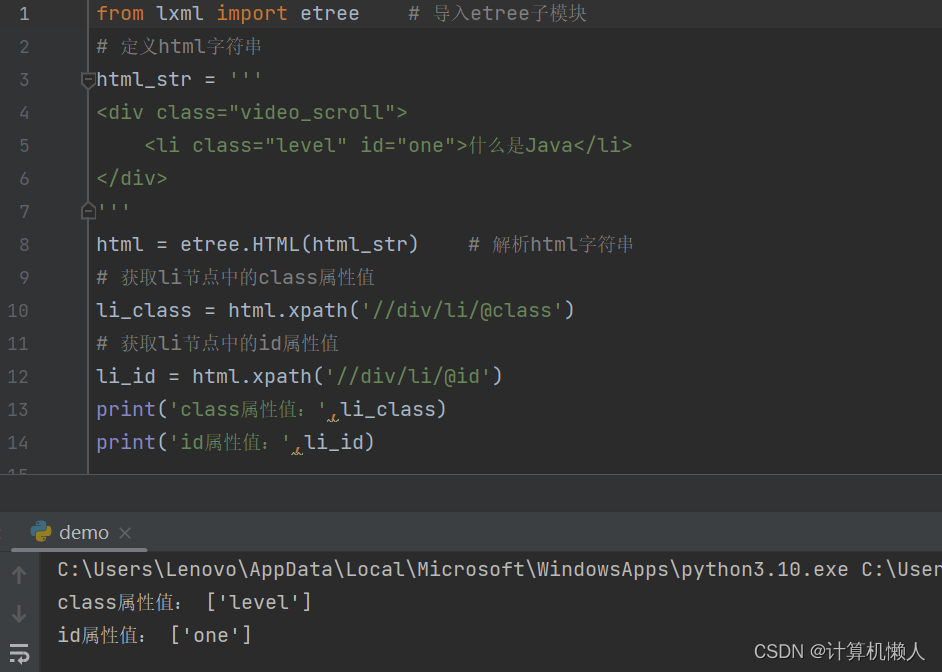
8.2.7 按序获取
按序来获取信息,在之前的内容中已经有所提及,在8.2.5中,对获取文本的拓展需要使用到这个方法,所以这里不过多描述,最后强调一个重点:xpath中的索引,也就是按序获取是从1开始的,而不是python的数组或列表,从0开始。案例代码如下:
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<li> <a href="javascript:" onclick="login(0)" title="Java API文档">Java API文档</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的下载">JDK的下载</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的安装">JDK的安装</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="配置JDK">配置JDK</a> </li>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取所有li/a节点中title属性值
li_all = html.xpath('//div/li/a/@title')
print('所有属性值:',li_all)
# 获取第1个li/a节点中title属性值
li_first = html.xpath('//div/li[1]/a/@title')
print('第一个属性值:',li_first)
# 获取第4个li/a节点中title属性值
li_four = html.xpath('//div/li[4]/a/@title')
print('第四个属性值:',li_four)li标签就是为了获取所有的li节点内容,li[1]就是获取第一个li节点的内容,li[4]就是获取第四个li节点的内容,输出结果如下:
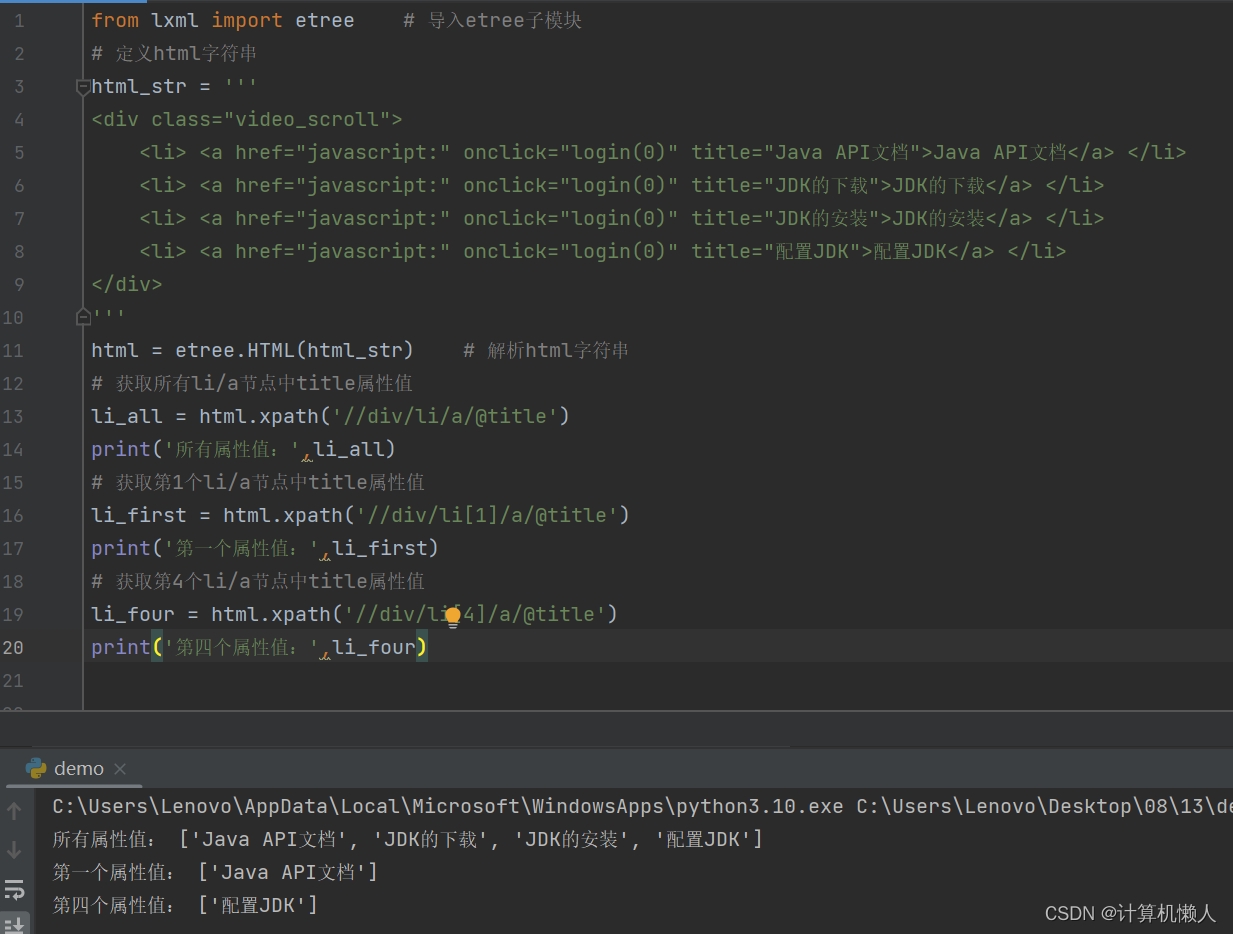
xpath中也可以运用函数进行位置定位,last()和position()分别指最后一个节点和与任意节点的关系,如position()=1就是第一个节点,position()>1就是位置大于1的节点,也就是2,3,4等。简单易懂,就不做代码分析了。
8.2.8 节点轴获取
这个方法很少使用,不过多解释,将案例代码附上,供自我学习。
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<li><a href="javascript:" onclick="login(0)" title="Java API文档">Java API文档</a></li>
<li><a href="javascript:" onclick="login(0)" title="JDK的下载">JDK的下载</a></li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的安装">JDK的安装</a> </li>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取li[2]所有祖先节点
ancestors = html.xpath('//li[2]/ancestor::*')
print('li[2]所有祖先节点名称:',[i.tag for i in ancestors])
# 获取li[2]祖先节点位置为body
body = html.xpath('//li[2]/ancestor::body')
print('li[2]指定祖先节点名称:',[i.tag for i in body])
# 获取li[2]属性为class="video_scroll"的祖先节点
class_div = html.xpath('//li[2]/ancestor::*[@class="video_scroll"]')
print('li[2]class="video_scroll"的祖先节点名称:',[i.tag for i in class_div])
# 获取li[2]/a所有属性值
attributes = html.xpath('//li[2]/a/attribute::*')
print('li[2]/a的所有属性值:',attributes)
# 获取div所有子节点
div_child = html.xpath('//div/child::*')
print('div的所有子节点名称:',[i.tag for i in div_child])
# 获取body所有子孙节点
body_descendant = html.xpath('//body/descendant::*')
print('body的所有子孙节点名称:',[i.tag for i in body_descendant])
# 获取li[1]节点后的所有节点
li_following = html.xpath('//li[1]/following::*')
print('li[1]之后的所有节点名称:',[i.tag for i in li_following])
# 获取li[1]节点后的所有同级节点
li_sibling = html.xpath('//li[1]/following-sibling::*')
print('li[1]之后的所有同级节点名称:',[i.tag for i in li_sibling])
# 获取li[3]节点前的所有节点
li_preceding = html.xpath('//li[3]/preceding::*')
print('li[3]之前的所有节点名称:',[i.tag for i in li_preceding])运行结果如下:
li[2]所有祖先节点名称: ['html', 'body', 'div']
li[2]指定祖先节点名称: ['body']
li[2]class="video_scroll"的祖先节点名称: ['div']
li[2]/a的所有属性值: ['javascript:', 'login(0)', 'JDK的下载']
div的所有子节点名称: ['li', 'li', 'li']
body的所有子孙节点名称: ['div', 'li', 'a', 'li', 'a', 'li', 'a']
li[1]之后的所有节点名称: ['li', 'a', 'li', 'a']
li[1]之后的所有同级节点名称: ['li', 'li']
li[3]之前的所有节点名称: ['li', 'a', 'li', 'a']这种方法较复杂,涉及到祖先节点和子孙节点等跨度很大的节点概念,容易造成定位错误,所以很少使用,不过多叙述。
8.3 案例:爬取豆瓣电影Top250
首先,编写爬虫需要导入模块,本程序需要lxml、requests模块这两个主要模块,time和random模块为了暂停时间和随机数生成,不是主要内容。下一步,爬虫需要上网进行在线爬取信息,所以进入网站的后台查看User-Agent,而每个浏览器的User-Agent不一样,需要进入特定页面查找。我使用的是火狐浏览器,而火狐的User-Agent需要打开一个页面,然后右击“检查”,进入网络,重新加载页面后,点击生成的post或get,往下寻找即可,如下图:
查找完后,需要在代码中的header中写入,作为爬虫的请求头信息,执行爬虫时,它就像是人为操作一样,对浏览器发送访问请求,浏览器同意后,就自动进入了网页进行爬虫工作。
然后,我们需要设置一个函数processing函数,用来对HTML代码进行处理。因为HTML代码中很多空格,所以需要把空格消除,设计了代码,如下:
def processing(strs):
s = '' # 定义保存内容的字符串
for n in strs:
n = ''.join(n.split()) # 去除空字符
s = s + n # 拼接字符串
return s # 返回拼接后的字符串s是字符型变量,strs是从HTML代码中获取的文字信息,是含有空格的。定义了字符串n,让n在strs中一一选择,将含有空格的句子利用split()函数进行切割,分成一个个字符串,然后利用join()函数再回到n变量中,而s是循环加n变量,也就是将一个个独立的字符串和s连接,从而消去空格。
接着就是设置终点爬虫代码部分。首先,运用requests模块对浏览器模拟发送请求,成功访问后会出现该网页的HTML代码,所以需要运用HTML方法进行解析。如下:
response = requests.get(url,headers=header) # 发送网络请求
html = etree.HTML(response.text) # 解析html字符串
下面进行xpath的数据抓取工作。
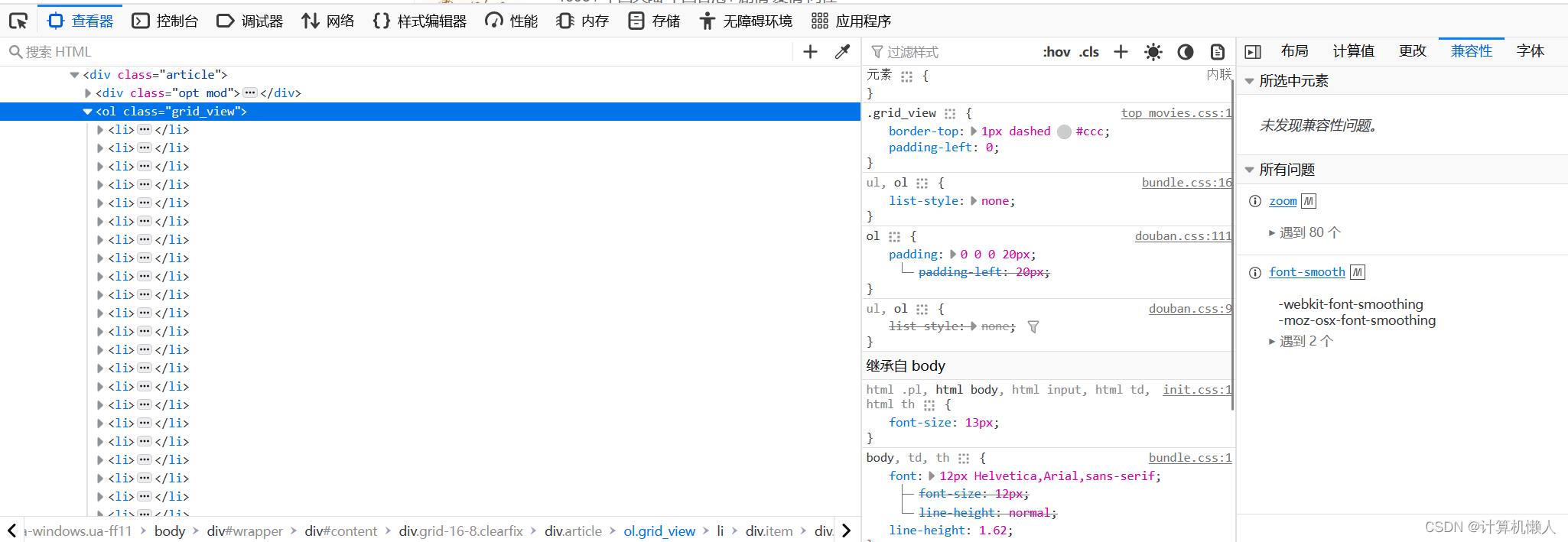
对页面进行检查操作后,可以发现代码中有25个li节点,而本页面中也正好有25个电影,所以说明一个li节点就对应一个电影。对于我们想要选择的文字,用左上角的选择对页面文本选择,即可得到文本在HTML代码中的位置,如下:

根据要求,我需要的是电影的介绍等信息,所以可以锁定在这个div节点的内容中。我们的任务就是把其中的内容给抓取出来,所以要用xpath进行抓取。首先设置数组,储存div节点下的HTML代码,利用属性匹配对class="info"进行定位,将25个里节点下的该属性节点下的内容全部抓取,放入准备的数组中,再利用循环,对每一个div内容进行抓取。
电影内容的HTML代码如下:
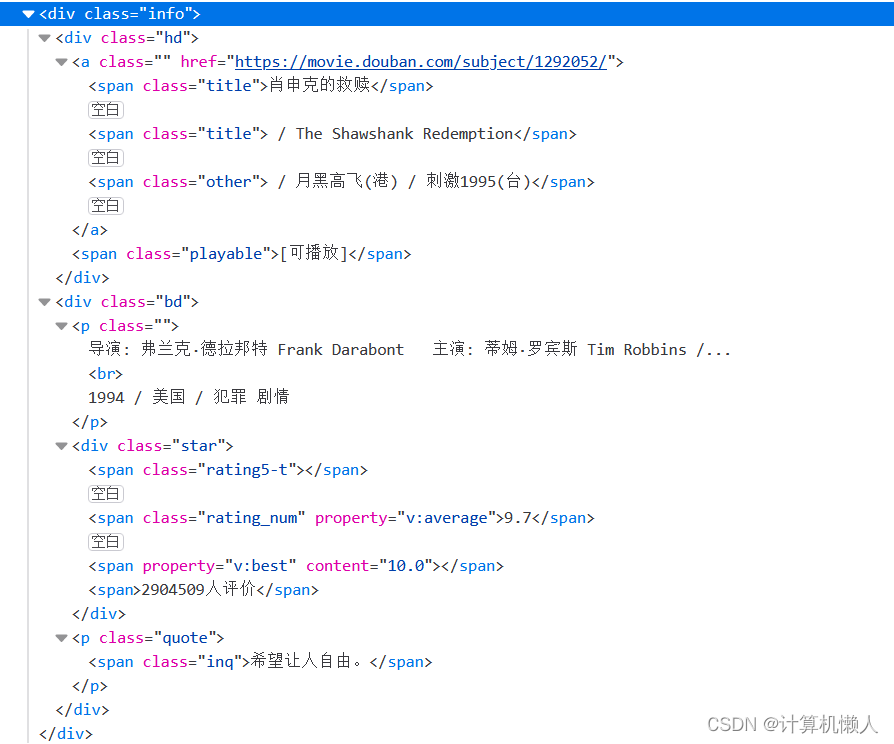
循环中的内容就是电影的具体信息了。我们需要四个信息,也就需要四次xpath解析,首先就是电影的名字。电影的名字在a节点中,并且是在第二个div节点下,所以电影的名字的位置我们可以这样定位:./div[@class="hd"]/a/span/text()。因为这个定位是基于原先的div节点而来的,所以用“./”来表示,省略了第一个div节点。以此类推,电影的导演和主演在class="bd"的属性的div中的p标签下,可以这样定位:./div[@class="bd"]/p/text()。电影的评分也在这个div中,是在div子节点中的第二个span标签中,那么就要用到按需获取了,要进行索引,可以这样定位:./[@class="bd"]/div/span[2]/text()。那么剩下的那一个也是一个道理,如:./div[@class="bd"]/p[@class="quote"]/span/text()。最后对结果进行修饰和处理,就可以输出了。
最后,要开始编写开始程序,之前那些都是函数,需要套用在运行函数中。要考虑的是,250部电影,每页只有25部,需要10页,那么翻页的操作怎么完成呢?那就需要观察每一页的网址,有什么特点,如下:
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
https://movie.douban.com/top250?start=75&filter=可以发现,除了黄色的数字不同外其他都相同,并且这些数字也有一定规律,都是隔25个数字,所以我们可以这样编写:'https://movie.douban.com/top250?start={page}&filter='.format(page=i)。其中format()函数可以理解为代入函数,用循环语句控制i变量,然后令page=i,将值代入到网址中,实现翻页效果。再利用random模块对程序执行时间暂停效果,防止数据抓取太快,影响运行结果。
经过分析,完整代码如下:
from lxml import etree # 导入etree子模块
import time # 导入时间模块
import random # 导入随机模块
import requests # 导入网络请求模块
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/116.0'}
# 处理字符串中的空白符,并拼接字符串
def processing(strs):
s = '' # 定义保存内容的字符串
for n in strs:
n = ''.join(n.split()) # 去除空字符
s = s + n # 拼接字符串
return s # 返回拼接后的字符串
# 获取电影信息
def get_movie_info(url):
response = requests.get(url,headers=header) # 发送网络请求
html = etree.HTML(response.text) # 解析html字符串
div_all = html.xpath('//div[@class="info"]')
for div in div_all:
names = div.xpath('./div[@class="hd"]/a/span/text()') # 获取电影名字相关信息
name = processing(names) # 处理电影名称信息
infos = div.xpath('./div[@class="bd"]/p/text()') # 获取导演、主演等信息
info = processing(infos) # 处理导演、主演等信息
score = div.xpath('./div[@class="bd"]/div/span[2]/text()') # 获取电影评分
evaluation = div.xpath('./div[@class="bd"]/div/span[4]/text()') # 获取评价人数
# 获取电影总结文字
summary = div.xpath('./div[@class="bd"]/p[@class="quote"]/span/text()')
print('电影名称:',name)
print('导演与演员:',info)
print('电影评分:',score)
print('评价人数:',evaluation)
print('电影总结:',summary)
print('--------分隔线--------')
if __name__ == '__main__':
for i in range(0,250,25): # 每页25为间隔,实现循环,共10页
# 通过format替换切换页码的url地址
url = 'https://movie.douban.com/top250?start={page}&filter='.format(page=i)
get_movie_info(url) # 调用爬虫方法,获取电影信息
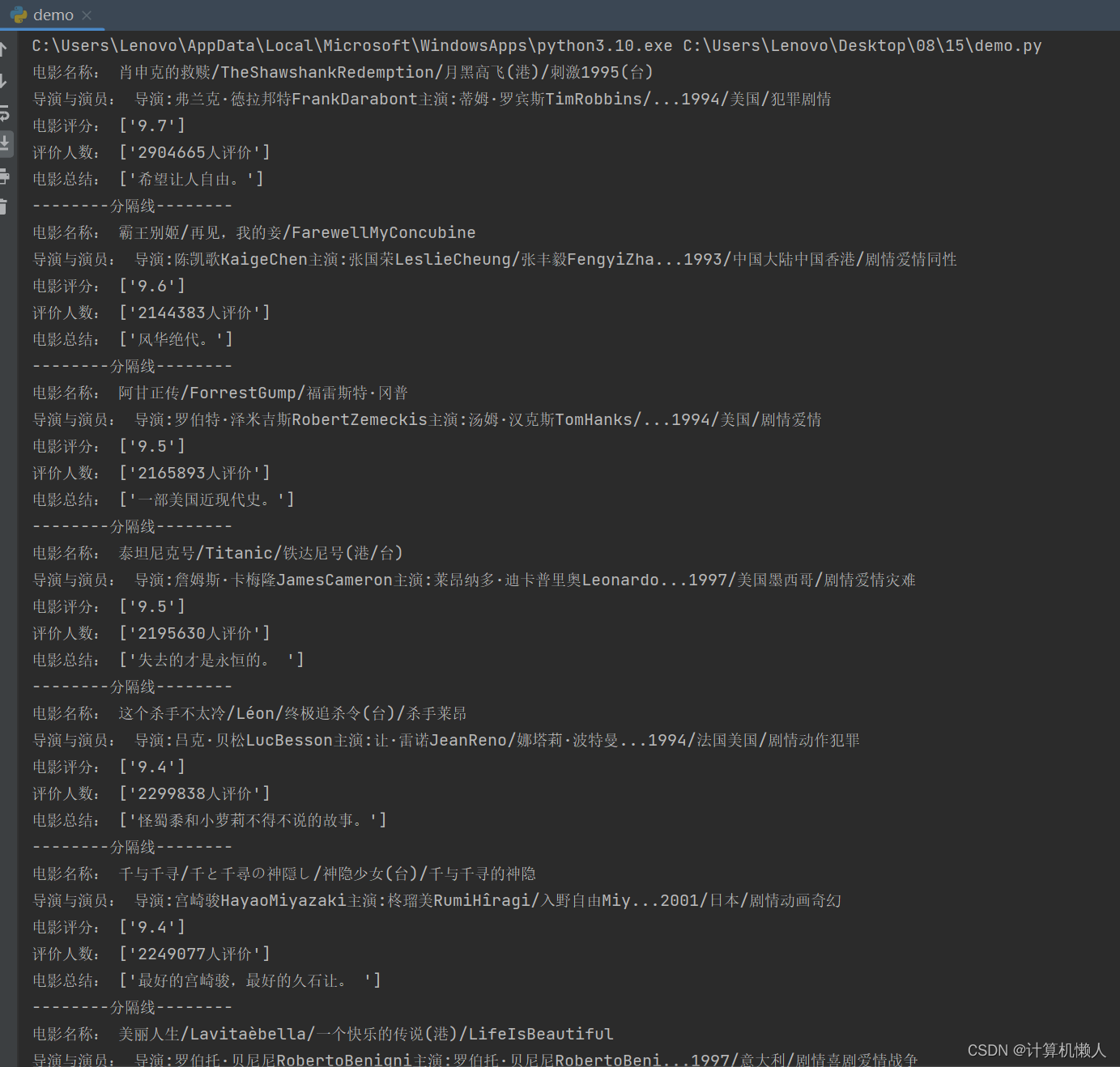
time.sleep(random.randint(1,3)) # 等待1至3秒随机时间运行部分结果如下:
8.4 小结
本章学习使用lxml模块的etree子模块,该模块可以解析HTML与XML内容。XPath表达式可以通过属性、按序以及节点轴的方式进行节点的获取。最后通过一个爬取豆瓣电影Top 250的案例演示了XPath提取数据的整个过程。
注:下一篇文章将介绍scrapy框架。
















 1901
1901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











