







一、MapReduce入门
-
核心思想
场景:统计单词的数量,并将以字母a-p和q-z开头的单词分别统计到两个文件中;
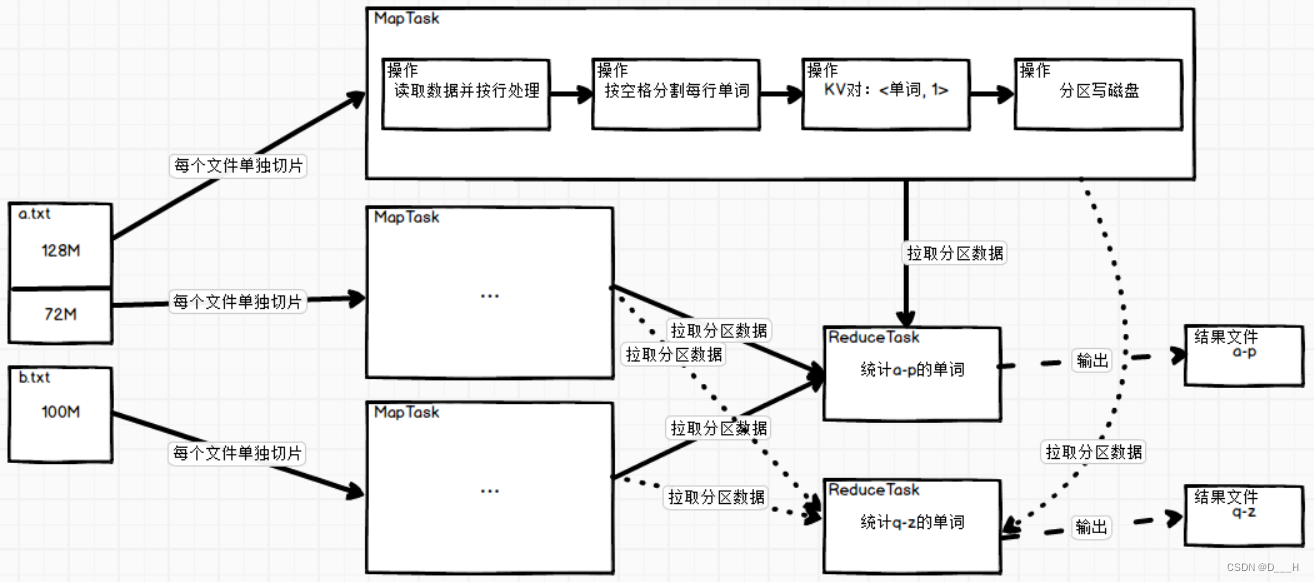
-
Hadoop常用序列化类型Java Hadoop Boolean BooleanWritable Byte ByteWritable Int IntWritable Float FloatWritable Long LongWritable Double DoubleWritable String Text Map MapWritable Array ArrayWritable Null NullWritable -
手写
WordCount案例
(1) 引入依赖<dependencies> <!-- junit测试依赖坐标 --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <!-- 日志依赖坐标 --> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> <version>2.12.0</version> </dependency> <!-- hadoop依赖坐标 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> </dependencies>(2)
resources下写配置文件<!-- 配置文件名为:log4j2.xml --> <?xml version="1.0" encoding="UTF-8"?> <Configuration status="error" strict="true" name="XMLConfig"> <Appenders> <!-- 类型名为Console,名称为必须属性 --> <Appender type="Console" name="STDOUT"> <!-- 布局为PatternLayout的方式, 输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here --> <Layout type="PatternLayout" pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" /> </Appender> </Appenders> <Loggers> <!-- 可加性为false --> <Logger name="test" level="info" additivity="false"> <AppenderRef ref="STDOUT" /> </Logger> <!-- root loggerConfig设置 --> <Root level="info"> <AppenderRef ref="STDOUT" /> </Root> </Loggers> </Configuration>(3)
Mapper类编写import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * Object => Map阶段读入数据的key的数据类型,为偏移量 * Text => Map阶段读入数据的value的数据类型,一行文本 * Text => Map阶段输出数据的key的数据类型, 单词 * IntWritable => Map阶段输出的value的数据类型, 单词个数 */ public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> { private Text keyOut = new Text(); private IntWritable valueOut = new IntWritable(1); /** * 核心处理方法,调用时机:每一行数据都会单独调用一次map方法进行处理 * @param key 偏移量 * @param value 一行文本 * @param context 上下文对象,将k-v输出给reducer * @throws IOException * @throws InterruptedException */ @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { // 以空白符为分隔符,分割单词 String[] words = value.toString().split("\\s"); // 循环输出<单词, 1>的k-v对 for (String word : words) { keyOut.set(word); context.write(keyOut, valueOut); } } }(4)
Reducer类编写import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Text => Map阶段输出数据的key的数据类型,单词 * IntWritable => Map阶段输出数据的value的数据类型,单词个数1 * Text => Reduce阶段输出数据的key的数据类型, 单词 * LongWritable => Reduce阶段输出的value的数据类型, 单词总个数 */ public class WordCountReducer extends Reducer<Text, IntWritable, Text, LongWritable> { private Text keyOut = new Text(); private LongWritable valueOut = new LongWritable(); /** * 用来汇总map阶段的处理结果,调用时机:每一组key-values会调用一次reduce方法处理 * @param key 单词 * @param values 单词个数列表,<word, [1, 1, 1...]> * @param context 上下文对象 * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 设置key keyOut.set(key); // 统计单词个数 int sum = 0; for (IntWritable value : values) { sum += value.get(); } valueOut.set(sum); // 输出 context.write(keyOut, valueOut); } }(5)
Driver类编写import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Arrays; public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 获取job对象 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置driver job.setJarByClass(WordCountDriver.class); // 设置mapper和reducer job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 设置输出数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 设置输入、输出路径 FileInputFormat.setInputPaths(job, Arrays.stream(args).limit(args.length -1).map(Path::new).toArray(Path[]::new)); FileOutputFormat.setOutputPath(job, new Path(args[args.length - 1])); // 提交job给yarn System.exit(job.waitForCompletion(true) ? 0 : 1); } }(6) 打包放到集群上运行
hadoop.sh start # hadoop jar jar包名 driver全类名 输入路径 输出路径 hadoop jar MRDemo-1.0-SNAPSHOT.jar wordcount.WordCountDriver /input /output
二、Hadoop序列化
- 步骤
(1) 实现Writable接口
(2) 必须要有空参构造方法
(3) 重写接口中的序列化方法write
(4) 重写接口中的反序列化方法readFields
(5) 重写toString方法
(6) 如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口
注意:反序列化的顺序和序列化的顺序完全一致 - 案例:统计手机用户的上行流量、下行流量、总流量
(1) 输入数据文件名为:phone_data.txt
(2) 数据格式为:
(3)封装类id 手机号码 IP地址 上行流量 下行流量 状态码 1 13593031103 120.196.100.99 1164 954 200Flow
(4)import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class Flow implements Writable { // 上行流量 private Integer up = 0; // 下行流量 private Integer down = 0; // 总流量,类内自动计算 private Integer total = 0; // 空参构造方法,必须存在 public Flow(){} public Integer getUp() { return up; } public void setUp(Integer up) { this.up = up; setTotal(); } public Integer getDown() { return down; } public void setDown(Integer down) { this.down = down; setTotal(); } public Integer getTotal(){ return this.total; } private void setTotal(){ this.total = this.up + this.down; } /** * 两个Flow对象想加 * @param f */ public void add(Flow f){ this.setUp(this.up + f.up); this.setDown(this.down + f.down); } // 重写toString,使对象按照指定格式输出到文件中 @Override public String toString() { return this.up + "\t" + this.down + "\t" + this.total; } @Override public void write(DataOutput out) throws IOException { out.writeInt(this.up); out.writeInt(this.down); out.writeInt(this.total); } @Override public void readFields(DataInput in) throws IOException { this.up = in.readInt(); this.down = in.readInt(); this.total = in.readInt(); } }Mapper类
(5)import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class FlowMapper extends Mapper<Object, Text, Text, Flow> { private Text keyOut = new Text(); private Flow valueOut = new Flow(); @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split("\t"); // 设定手机号当key keyOut.set(fields[1]); // 设定flow对象当value valueOut.setUp(Integer.parseInt(fields[fields.length - 3])); valueOut.setDown(Integer.parseInt(fields[fields.length - 2])); // total已经自动计算 // 输出k-v context.write(keyOut, valueOut); } }Reducer类
(6)import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class FlowReducer extends Reducer<Text, Flow, Text, Flow> { private Text keyOut = new Text(); private Flow valueOut = new Flow(); @Override protected void reduce(Text key, Iterable<Flow> values, Context context) throws IOException, InterruptedException { // 设置手机号 keyOut.set(key); // 汇总流量 valueOut.setUp(0); valueOut.setDown(0); for (Flow value : values) { valueOut.add(value); } // 输出 context.write(keyOut, valueOut); } }Driver类
(7) 在import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Arrays; public class FlowDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FlowDriver.class); job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Flow.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Flow.class); FileInputFormat.setInputPaths(job, Arrays.stream(args).limit(args.length -1).map(Path::new).toArray(Path[]::new)); FileOutputFormat.setOutputPath(job, new Path(args[args.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }Idea直接运行或者打包到集群上运行# 集群上运行 hadoop jar MRDemo-1.0-SNAPSHOT.jar flow.FlowDriver /input /output
三、MapReduce详解
-
MapReduce执行流程与组件
(1) 执行流程
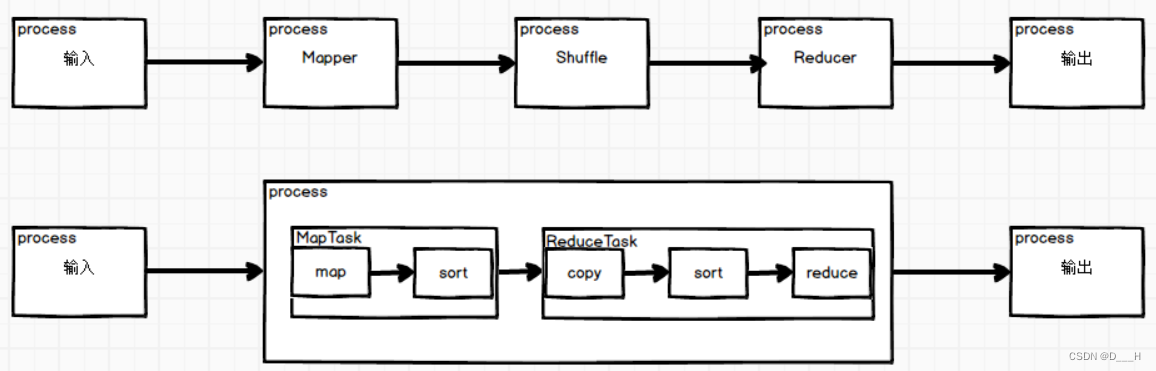
(2) 组件

-
InputFormat
(1) 作用:
a. 切片
b. 实现从切片中读取数据的方式
(2) 继承体系

a.InputFormat、FileInputFormat、CombineFileInputFormat是抽象类;
b.TextInputFormat、CombineTextInputFormat是可直接实例化的类;
c. 默认情况下,使用TextInputFormat类切片和从切片中读取数据,该类中切片的方式是按照单个文件分别切片、读取数据的方式是按行读取,切片逻辑于FileInputFroamt中实现,读取数据逻辑该类内提供实现;CombineTextInputFormat的切片机制利于处理多个小文件、读取数据的方式是按行读取,切片逻辑于CombineFileInputFormat中实现,读取数据逻辑该类内提供实现(等同于TextInputFormat类中读取数据的实现)。
(3)FileInputFormat中的getSplits方法/* * 1. 初始化minSize、maxSize * 2. 获取要处理的文件列表 * 3. 遍历文件列表,计算每一个可以进行切片的文件的切片大小 * 4. 切片 * 5. 最后返回切片列表 */ public List<InputSplit> getSplits(JobContext job) throws IOException { // 计时器 StopWatch sw = new StopWatch().start(); /* * 计算minSize和maxSize,这两个值可以用来计算切片大小 * * 1. minSize * minSize=Math.max(1, job.getConfiguration().getLong("mapreduce.input.fileinputformat.split.minsize", 1L)) * mapred-default.xml中默认配置mapreduce.input.fileinputformat.split.minsize=0 * 所以minSize=1 * 当mapreduce.input.fileinputformat.split.minsize取值大于等于1时 * 可以认为:minSize=mapreduce.input.fileinputformat.split.minsize * * 2.maxSize * maxSize=context.getConfiguration().getLong("mapreduce.input.fileinputformat.split.maxsize", Long.MAX_VALUE) * mapred-default.xml中没有配置mapreduce.input.fileinputformat.split.maxsize * 所以maxSize=Long.MAX_VALUE * 只要mapreduce.input.fileinputformat.split.maxsize配置小于等于Long.MAX_VALUE的值 * 就可以近似认为:maxSize=mapreduce.input.fileinputformat.split.maxsize */ long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); long maxSize = getMaxSplitSize(job); // 存放切片的集合,最后返回该集合 List<InputSplit> splits = new ArrayList<InputSplit>(); // 获取要处理的文件列表 List<FileStatus> files = listStatus(job); // 忽略文件夹 boolean ignoreDirs = !getInputDirRecursive(job) && job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false); // 遍历文件 for (FileStatus file: files) { // 跳过文件夹 if (ignoreDirs && file.isDirectory()) { continue; } // 获取文件路径 Path path = file.getPath(); // 获取文件大小 long length = file.getLen(); // 略过空文件 if (length != 0) { // 获取文件块的元数据信息 BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { FileSystem fs = path.getFileSystem(job.getConfiguration()); blkLocations = fs.getFileBlockLocations(file, 0, length); } // 略过不可以切片的文件 if (isSplitable(job, path)) { // 获取文件的块大小 long blockSize = file.getBlockSize(); /* * 计算切片大小 * splitSize=Math.max(minSize, Math.min(blockSize, maxSize)) * 默认情况下:splitSize=blockSize * 1. 调整 切片大小<块大小 <=> 只调整 mapreduce.input.fileinputformat.split.maxsize<块大小 * 2. 调整 切片大小>块大小 <=> 只调整 mapreduce.input.fileinputformat.split.minsize>块大小 */ long splitSize = computeSplitSize(blockSize, minSize, maxSize); // 文件剩余大小,初始值是文件的大小 long bytesRemaining = length; /* * 源码中定义:SPLIT_SLOP = 1.1 * 只有当文件剩余大小超过切片大小的1.1倍时,才会进行切片 */ while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { // 切片,并将切好的片放入集合中 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); // 更新文件剩余大小 bytesRemaining -= splitSize; } // 如果文件没有被正好切片,就把剩余的小部分文件单独切一片 if (bytesRemaining != 0) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); } } else { // 不能切片的文件 if (LOG.isDebugEnabled()) { // Log only if the file is big enough to be splitted if (length > Math.min(file.getBlockSize(), minSize)) { LOG.debug("File is not splittable so no parallelization " + "is possible: " + file.getPath()); } } // 不切分,单独成一片 splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(), blkLocations[0].getCachedHosts())); } } else { //Create empty hosts array for zero length files splits.add(makeSplit(path, 0, length, new String[0])); } } // Save the number of input files for metrics/loadgen job.getConfiguration().setLong(NUM_INPUT_FILES, files.size()); sw.stop(); if (LOG.isDebugEnabled()) { LOG.debug("Total # of splits generated by getSplits: " + splits.size() + ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS)); } // 返回切片集合 return splits; }(4)
TextInputFormat中的createRecordReader方法
CombineTextInputFormat中的createRecordReader也是按行读取@Override public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) { String delimiter = context.getConfiguration().get( "textinputformat.record.delimiter"); byte[] recordDelimiterBytes = null; if (null != delimiter) recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8); // Line=>按行读取,返回按行读取的记录读取器对象 return new LineRecordReader(recordDelimiterBytes); }(5)
CombineFileInputFormat(CombinTextInputFormat) 中的切片机制
处理小文件使用

a.3.2M≤4M=>3.2M;
b.4M<5.6M≤2*4M=>2.8M,2.8M;
c.12.6M>2*4M=>4M,8.6M;8.6M继续采用c规则;4.6M采用b规则;
d.3.2M<4M=>3.2M+2.8M≥4M=>6M;以此类推…
(6)CombineTextInputFormat使用
只需要在Driver中添加如下代码://虚拟存储切片最大值设置4M(默认单位字节) CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); // 如果不设置InputFormat,它默认用的是TextInputFormat.class job.setInputFormatClass(CombineTextInputFormat.class); -
Shuffle机制
(1) 原理图


(2)Partition分区
选择分区器的策略:/* * 该方法定义于MapTask类中的内部类NewOutputCollector中 * 该方法定义了选择分区器的策略 */ NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext, JobConf job, TaskUmbilicalProtocol umbilical, TaskReporter reporter ) throws IOException, ClassNotFoundException { collector = createSortingCollector(job, reporter); // 获取开启reduce的个数,将reduce的个数看作分区数 partitions = jobContext.getNumReduceTasks(); if (partitions > 1) { /* 如果分区数大于1: * (1) 创建默认类型(HashPartitioner)的分区器对象 * (2) 创建用户自定义的分区器对象 */ partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>) ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job); } else { // 如果分区数指定为1,永远返回0号分区 partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() { @Override public int getPartition(K key, V value, int numPartitions) { return partitions - 1; } }; } }HashPartitioner分区器:/* * 定义于HashPartitioner类中 * 该方法用于获取分区号 */ public int getPartition(K2 key, V2 value, int numReduceTasks) { // 分区号 = 使用key的哈希值 % 分区个数 return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; }(3) 分区案例
a. 读取用户流量的数据文件,将手机号码以135、136、137、其他的用户流量记录分别输出到不同文件。
b. 代码如下
引入依赖<dependencies> <!-- junit测试依赖坐标 --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <!-- 日志依赖坐标 --> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> <version>2.12.0</version> </dependency> <!-- hadoop依赖坐标 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> </dependencies>resources下写配置文件<!-- 配置文件名为:log4j2.xml --> <?xml version="1.0" encoding="UTF-8"?> <Configuration status="error" strict="true" name="XMLConfig"> <Appenders> <!-- 类型名为Console,名称为必须属性 --> <Appender type="Console" name="STDOUT"> <!-- 布局为PatternLayout的方式, 输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here --> <Layout type="PatternLayout" pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" /> </Appender> </Appenders> <Loggers> <!-- 可加性为false --> <Logger name="test" level="info" additivity="false"> <AppenderRef ref="STDOUT" /> </Logger> <!-- root loggerConfig设置 --> <Root level="info"> <AppenderRef ref="STDOUT" /> </Root> </Loggers> </Configuration>Flowimport org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class Flow implements Writable { // 上行流量 private Integer up = 0; // 下行流量 private Integer down = 0; // 总流量,类内自动计算 private Integer total = 0; // 空参构造方法,必须存在 public Flow(){} public Integer getUp() { return up; } public void setUp(Integer up) { this.up = up; setTotal(); } public Integer getDown() { return down; } public void setDown(Integer down) { this.down = down; setTotal(); } public Integer getTotal(){ return this.total; } private void setTotal(){ this.total = this.up + this.down; } /** * 两个Flow对象想加 * @param f */ public void add(Flow f){ this.setUp(this.up + f.up); this.setDown(this.down + f.down); } // 重写toString,使对象按照指定格式输出到文件中 @Override public String toString() { return this.up + "\t" + this.down + "\t" + this.total; } @Override public void write(DataOutput out) throws IOException { out.writeInt(this.up); out.writeInt(this.down); out.writeInt(this.total); } @Override public void readFields(DataInput in) throws IOException { this.up = in.readInt(); this.down = in.readInt(); this.total = in.readInt(); } }Partitionerimport org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class PhonePartitioner extends Partitioner<Text, Flow> { @Override public int getPartition(Text text, Flow flow, int numPartitions) { int partition; String phone = text.toString(); switch (phone.subSequence(0, 3).toString()){ case "135": partition = 0; break; case "136": partition = 1; break; case "137": partition = 2; break; default: partition = 3; break; } return partition; } }Mapperimport org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class FlowMapper extends Mapper<Object, Text, Text, Flow> { private Text keyOut = new Text(); private Flow valueOut = new Flow(); @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split("\t"); // 设定手机号当key keyOut.set(fields[1]); // 设定flow对象当value valueOut.setUp(Integer.parseInt(fields[fields.length - 3])); valueOut.setDown(Integer.parseInt(fields[fields.length - 2])); // total已经自动计算 // 输出k-v context.write(keyOut, valueOut); } }Reducerimport org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class FlowReducer extends Reducer<Text, Flow, Text, Flow> { private Text keyOut = new Text(); private Flow valueOut = new Flow(); @Override protected void reduce(Text key, Iterable<Flow> values, Context context) throws IOException, InterruptedException { // 设置手机号 keyOut.set(key); // 汇总流量 valueOut.setUp(0); valueOut.setDown(0); for (Flow value : values) { valueOut.add(value); } // 输出 context.write(keyOut, valueOut); } }Driverimport org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Arrays; public class FlowDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FlowDriver.class); job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Flow.class); // 设置分区器 job.setPartitionerClass(PhonePartitioner.class); // 设置分区个数 job.setNumReduceTasks(4); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Flow.class); FileInputFormat.setInputPaths(job, Arrays.stream(args).limit(args.length -1).map(Path::new).toArray(Path[]::new)); FileOutputFormat.setOutputPath(job, new Path(args[args.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }(4) 排序
key只有实现WritableComparable接口,重写其中的方法后,才可以实现排序。无论是实现该接口,还是提供WritableComparator比较器对象,Hadoop都是使用比较器对象,实现排序数据间的比较,如果只实现了WritableComparable接口、没有提供比较器对象,Hadoop底层会自己创建比较器对象。/* * 该方法定义于:JobConf * 该方法用于返回key的比较器对象 */ public RawComparator getOutputKeyComparator() { // 获取用户配置于job中的比较器类型 Class<? extends RawComparator> theClass = getClass( JobContext.KEY_COMPARATOR, null, RawComparator.class); if (theClass != null) // 用户已经设置比较器对象,直接用反射创建 return ReflectionUtils.newInstance(theClass, this); // 用户没有设置比较器对象,Hadoop负责创建 return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class), this); }Hadoop创建比较器对象/* * 只列出该类中的部分属性和方法 */ public class WritableComparator implements RawComparator, Configurable { // 一个Map,用来记忆Hadoop自定义的序列化类型和对应的比较器的映射关系 private static final ConcurrentHashMap<Class, WritableComparator> comparators = new ConcurrentHashMap<Class, WritableComparator>(); // registry /* * 当用户没有指定比较器时,获取比较器对象的逻辑 * 在类加载的时候,会把自定义的序列化类型和对应的比较器放在comparators中(通过静态代码块实现) */ public static WritableComparator get( Class<? extends WritableComparable> c, Configuration conf) { // 获取自定义的序列化类型所对应的比较器 WritableComparator comparator = comparators.get(c); if (comparator == null) { // 获取失败,可能由于某些因素导致GC回收 // 强制重新类加载,执行静态代码块中的内容 forceInit(c); // 再次尝试获取自定义的序列化类型所对应的比较器 comparator = comparators.get(c); // if not, use the generic one if (comparator == null) { // 获取失败,说明要比较的对象类型不是Hadoop自定义的序列化类型 // Hadoop负责直接创建该类型的比较器对象 comparator = new WritableComparator(c, conf, true); } } // Newly passed Configuration objects should be used. ReflectionUtils.setConf(comparator, conf); return comparator; } }(5) 排序案例
Flowimport org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class Flow implements WritableComparable<Flow> { private Integer up = 0; private Integer down = 0; private Integer total = 0; // 无惨构造方法,必须存在 public Flow(){} public Integer getUp() { return up; } public void setUp(Integer up) { this.up = up; setTotal(); } public Integer getDown() { return down; } public void setDown(Integer down) { this.down = down; setTotal(); } public Integer getTotal(){ return this.total; } private void setTotal(){ this.total = this.up + this.down; } /** * 两个Flow对象想加 * @param f */ public void add(Flow f){ this.setUp(this.up + f.up); this.setDown(this.down + f.down); } // 重写toString,使对象按照指定格式输出到文件中 @Override public String toString() { return this.up + "\t" + this.down + "\t" + this.total; } @Override public void write(DataOutput out) throws IOException { out.writeInt(this.up); out.writeInt(this.down); out.writeInt(this.total); } @Override public void readFields(DataInput in) throws IOException { this.up = in.readInt(); this.down = in.readInt(); this.total = in.readInt(); } @Override public int compareTo(Flow o) { return total.compareTo(o.total); } }Comparatorimport org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; public class FlowComparator extends WritableComparator { public FlowComparator(){ // 绑定该比较器是Flow类型的比较器 super(Flow.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { return b.compareTo(a); } }Driverimport org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Arrays; public class FlowDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FlowDriver.class); job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); job.setMapOutputKeyClass(Flow.class); job.setMapOutputValueClass(Text.class); // 设置比较器对象,就会使用比较器对象进行比较排序 // 不设置比较器对象,Hadoop负责创建,会使用接口中的逻辑进行比较排序 job.setSortComparatorClass(FlowComparator.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Flow.class); FileInputFormat.setInputPaths(job, Arrays.stream(args).limit(args.length -1).map(Path::new).toArray(Path[]::new)); FileOutputFormat.setOutputPath(job, new Path(args[args.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }其他内容与
(3)分区案例一样
(6)Combiner
实际上就是Reducer,提早处理数据,减少数据传输,提高效率,在Driver中如下设置即可:job.setCombinerClass(YourReducer.class);-
OutputFormat
(1) 作用
a. 检查输出路径是否合法;
b. 定义数据输出的方式;
(2) 继承体系

OutputFormat是接口;
FileOutputFormat是抽象类;
TextOutputFormat是可实例化的类;
checkOutputSpecs方法于FileOutputFormat实现,用来判断输出路径不为null并且输出路径原本不存在,否则抛出异常;getRecordWriter方法用户获取记录输出器,按行输出内容到Hadoop预定义分分区文件中;
(3) 案例
a. 需求:过滤文件中的网址,将含有baidu的网址内容输出到baidu.log文件中,其内容输出到other.log文件中
b. 输入格式:输入文件中,一个网址占一行
c. 代码:
引入依赖<dependencies> <!-- junit测试依赖坐标 --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <!-- 日志依赖坐标 --> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> <version>2.12.0</version> </dependency> <!-- hadoop依赖坐标 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> </dependencies>resources下写配置文件<!-- 配置文件名为:log4j2.xml --> <?xml version="1.0" encoding="UTF-8"?> <Configuration status="error" strict="true" name="XMLConfig"> <Appenders> <!-- 类型名为Console,名称为必须属性 --> <Appender type="Console" name="STDOUT"> <!-- 布局为PatternLayout的方式, 输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here --> <Layout type="PatternLayout" pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" /> </Appender> </Appenders> <Loggers> <!-- 可加性为false --> <Logger name="test" level="info" additivity="false"> <AppenderRef ref="STDOUT" /> </Logger> <!-- root loggerConfig设置 --> <Root level="info"> <AppenderRef ref="STDOUT" /> </Root> </Loggers> </Configuration>Mapperimport org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class LogMapper extends Mapper<Object, Text, Text, NullWritable> { private Text keyOut = new Text(); private NullWritable valueOut = NullWritable.get(); @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { keyOut.set(value); context.write(keyOut, valueOut); } }Reducerimport org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class LogReducer extends Reducer<Text, NullWritable, Text, NullWritable> { private Text keyOut = new Text(); private NullWritable valueOut = NullWritable.get(); @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { keyOut.set(key); for (NullWritable value : values) { context.write(keyOut, valueOut); } } }自定义
RecordWriterimport org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import java.io.IOException; import java.net.URI; import java.nio.charset.StandardCharsets; /** * 自定义记录输出器 * 泛型为Reducer输出的泛型 */ public class LogRecordWriter extends RecordWriter<Text, NullWritable> { private FileSystem fs; private FSDataOutputStream baiduOutputStream; private FSDataOutputStream otherOutputStream; public LogRecordWriter(JobContext jobContext){ try { // 使用jobContext中的配置获取文件系统对象 fs = FileSystem.get(jobContext.getConfiguration()); baiduOutputStream = fs.create(new Path(URI.create("baidu.log")), true); otherOutputStream = fs.create(new Path(URI.create("other.log")), true); } catch (IOException e) { e.printStackTrace(); } } @Override public void write(Text key, NullWritable value) throws IOException, InterruptedException { String website = key.toString(); if (website.contains("baidu")){ baiduOutputStream.writeBytes(new String((website + "\n").getBytes(StandardCharsets.UTF_8))); }else { otherOutputStream.writeBytes(new String((website + "\n").getBytes(StandardCharsets.UTF_8))); } } @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { IOUtils.closeStreams(baiduOutputStream, otherOutputStream, fs); } }自定义
OutputFormatimport org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class LogOutputFormat extends FileOutputFormat<Text, NullWritable> { @Override public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { return new LogRecordWriter(job); } }Driverimport org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Arrays; public class LogDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(LogDriver.class); job.setMapperClass(LogMapper.class); job.setReducerClass(LogReducer.class); // 设置OutputFormat job.setOutputFormatClass(LogOutputFormat.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, Arrays.stream(args).limit(args.length -1).map(Path::new).toArray(Path[]::new)); // 设置SUCCESS标志文件的输出路径 FileOutputFormat.setOutputPath(job, new Path(args[args.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
-















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









