






MapReduce三个小案例
回顾一下 wordcount案例中map阶段
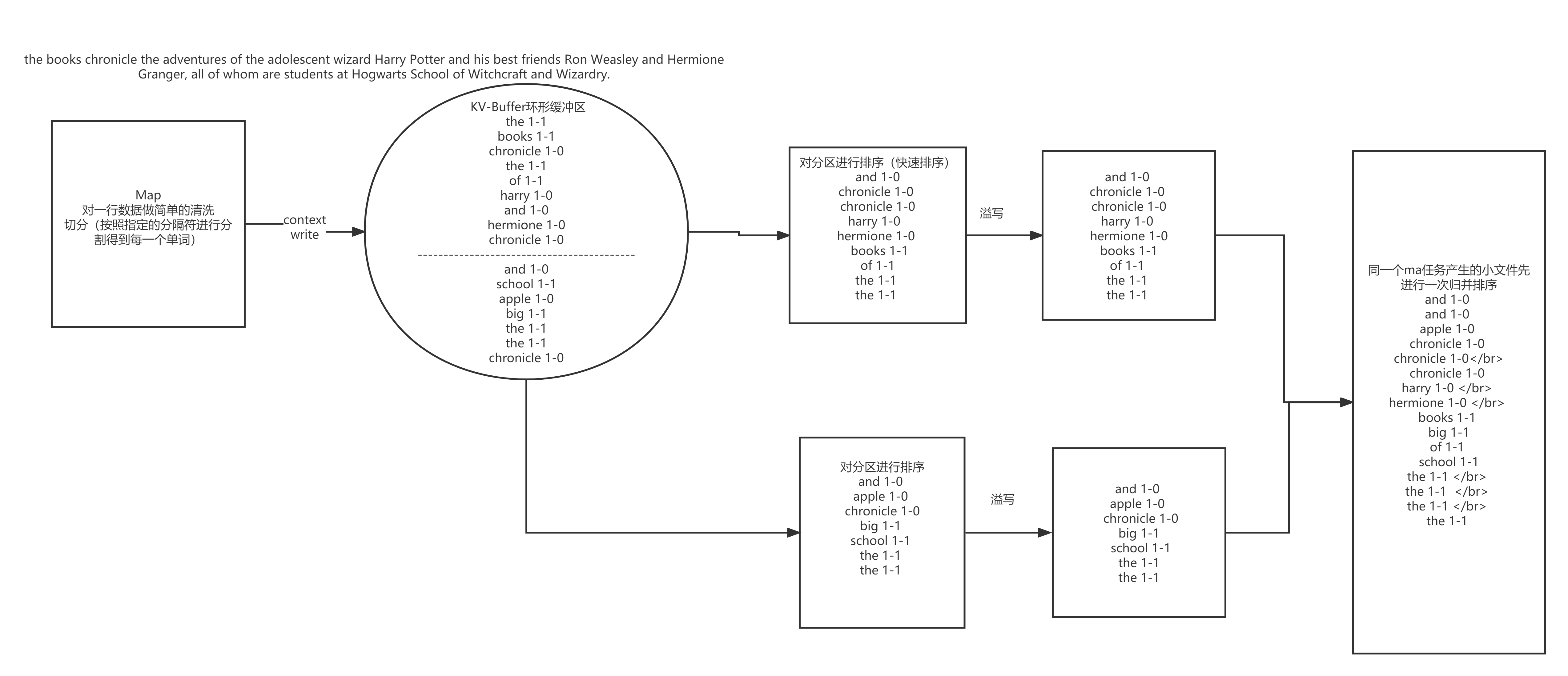
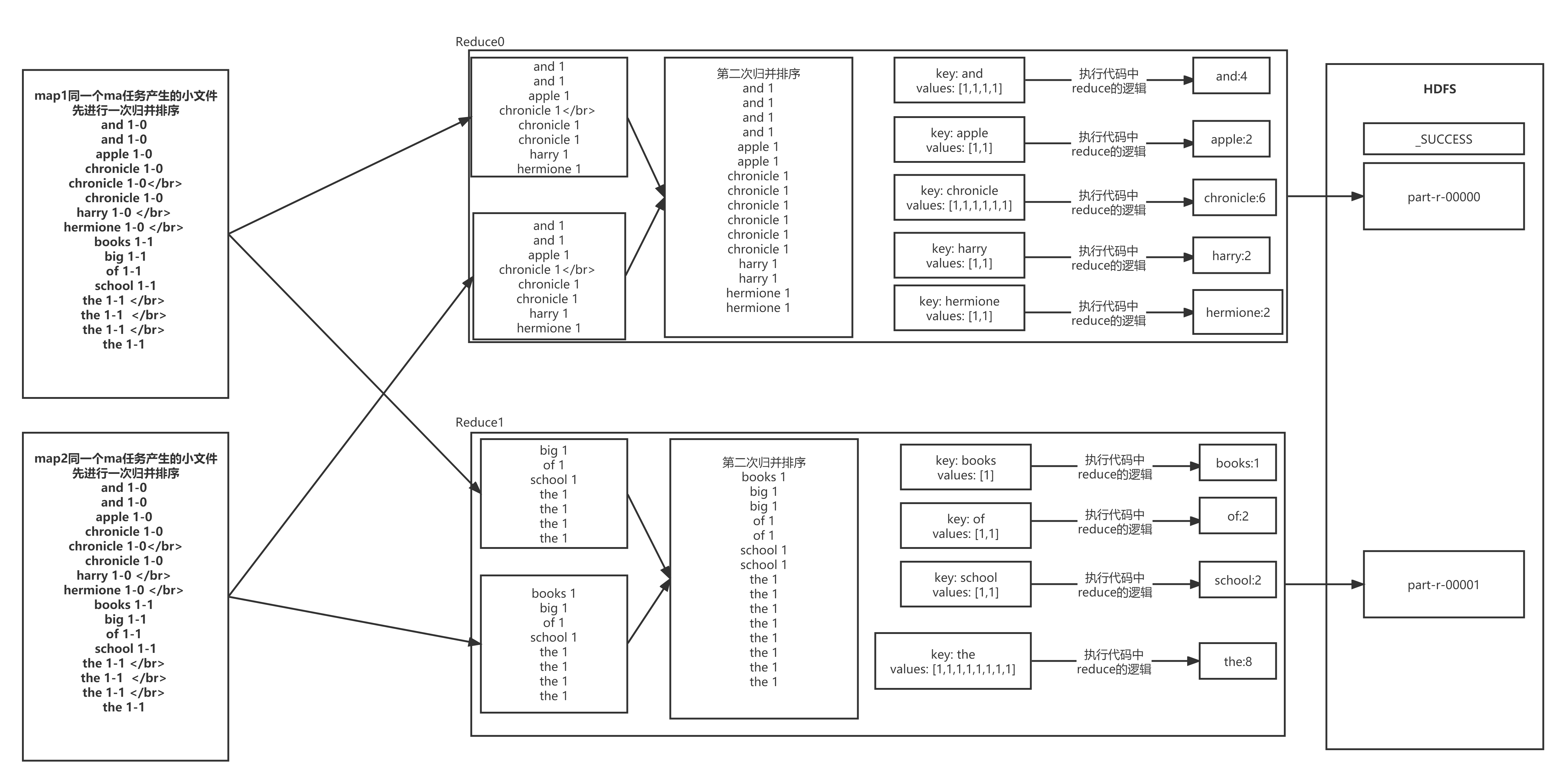
回顾一下 wordcount案例中的reduce阶段
1、IK分词器(统计三国演义指定词语个数)
步骤一:找到ik依赖,并添加到环境中
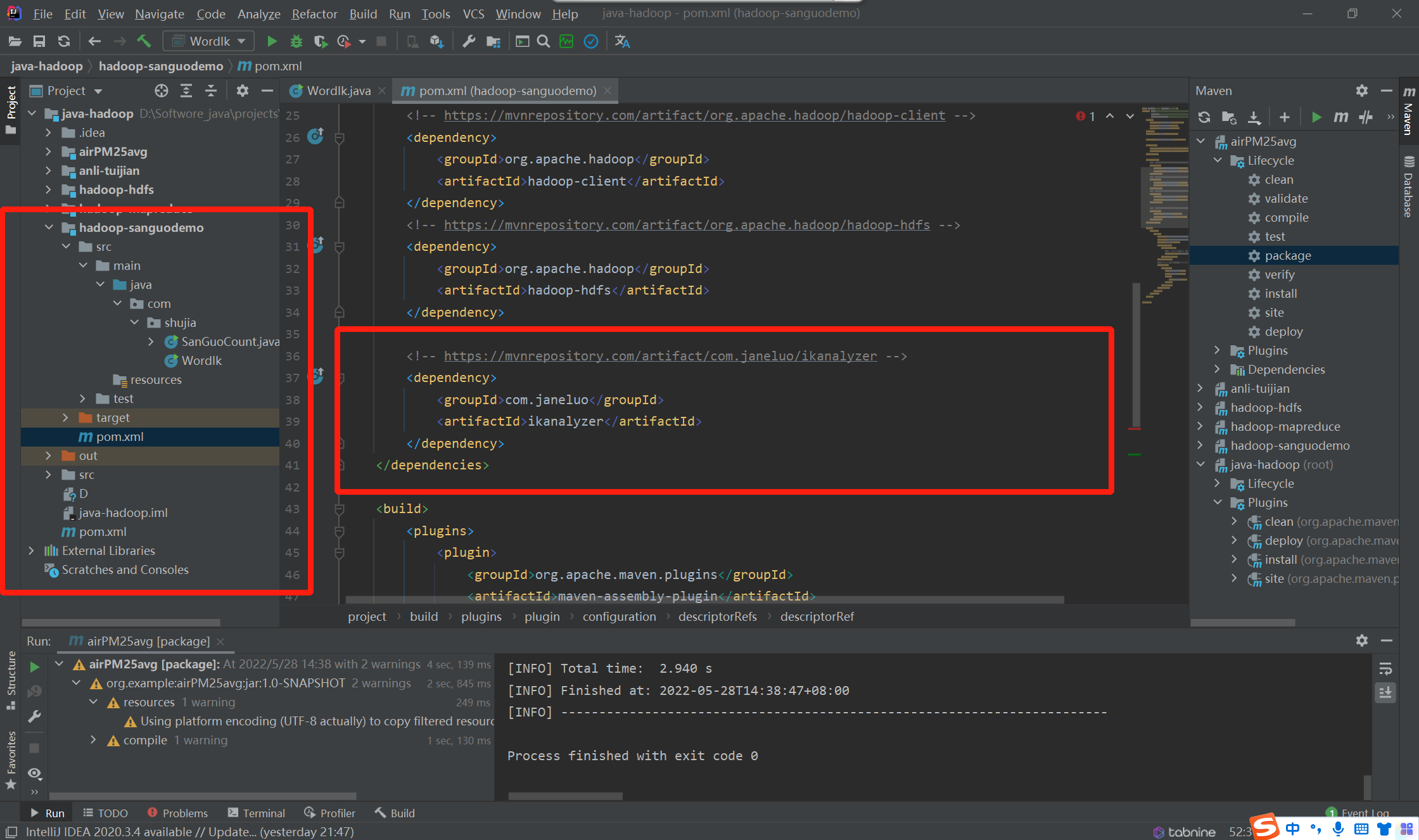
步骤二:在hadoop项目中创建子项目,并添加环境依赖
步骤三:小测试一下,结果如下:
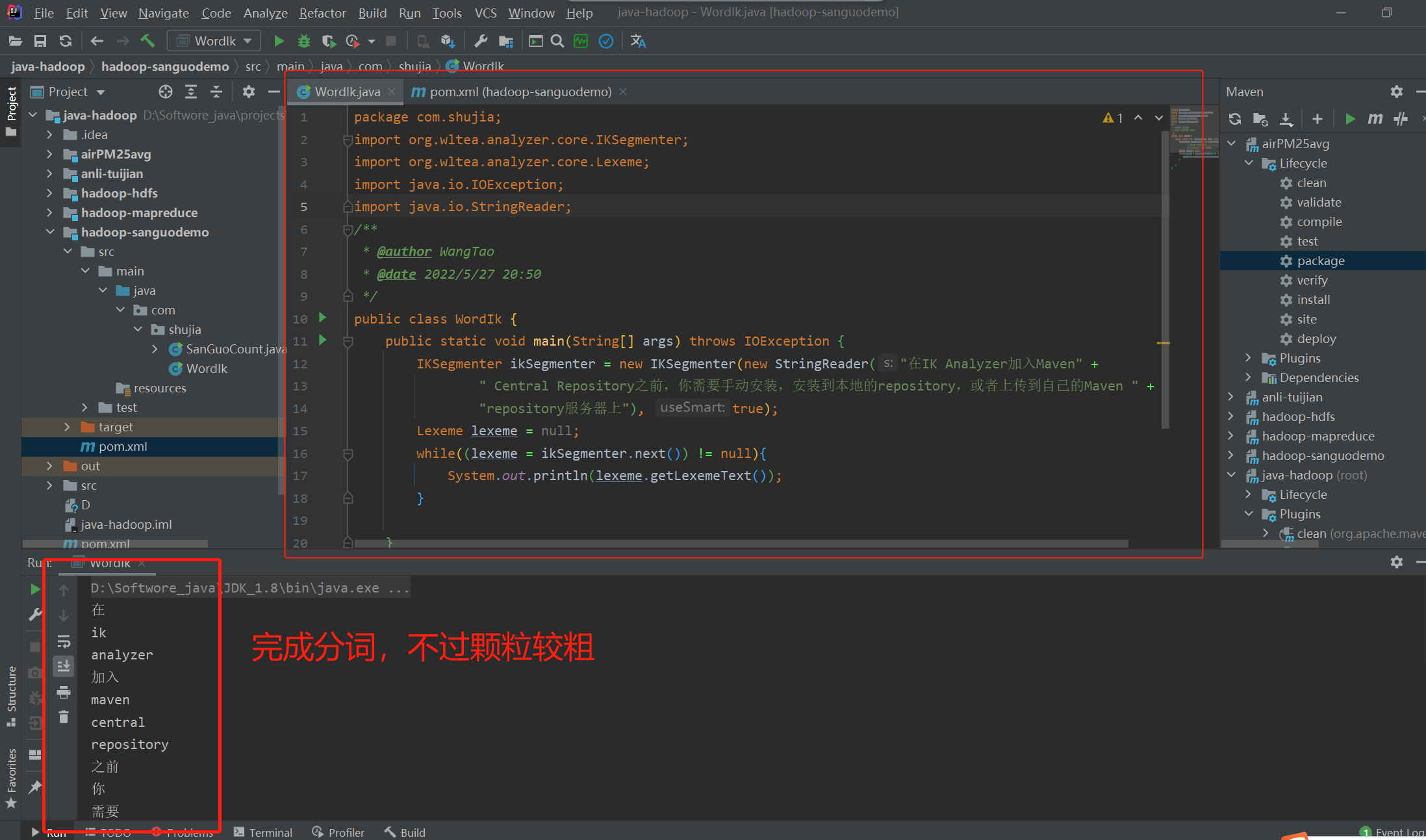
步骤四:通过程序在 HDFS 中的 sgyy.txt 中统计 三国演义出现的次数
《三国演义》是中国文学史上第一部章回小说,是历史演义小说的开山之作,也是第一部文人长篇小说,明清时期甚至有“第一才子书”之称。 [1] 《三国演义》(全名为《三国志通俗演义》,又称《三国志演义》)是元末明初小说家罗贯中根据陈寿《三国志》和裴松之注解以及民间三国故事传说经过艺术加工创作而成的长篇章回体历史演义小说,与《西游记》《水浒传》《红楼梦》并称为中国古典四大名著。该作品成书后有嘉靖壬午本等多个版本传于世,到了明末清初,毛宗岗对《三国演义》整顿回目、修正文辞、改换诗文,该版本也成为诸多版本中水平最高、流传最广
等等 。。。。
首先:配置依赖开始第一次尝试,失败。原因是没有添加能够将 IKanalyzer 打包的依赖。下面是配置了将依赖一起打包的代码
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>java-hadoop</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>hadoop-sanguodemo</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/com.janeluo/ikanalyzer -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<!-- 打包出来的带依赖jar包名称 -->
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<!--下面是为了使用 mvn package命令,如果不加则使用mvn assembly-->
<executions>
<execution>
<id>make-assemble</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>其次:编写主程序(main方法中的代码千篇一律,但是调用的map 和reduce 的代码是关键代码)
package com.shujia;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.IOException;
import java.io.StringReader;
/**
* @author WangTao
* @date 2022/5/27 21:04
*/
class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//使用分词器将一行数据分词
StringReader sr = new StringReader(value.toString());
//使用IK分词器进行分词
IKSegmenter ikSegmenter = new IKSegmenter(sr, true);
Lexeme lexeme = null;
while ((lexeme = ikSegmenter.next())!=null){
String word = lexeme.getLexemeText();
if("三国演义".equals(word)||"曹操".equals(word)){
context.write(new Text(word),new LongWritable(1L));
}
}
}
}
class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
Long sum = 0L;
for (LongWritable value : values) {
long l = value.get();
sum += l;
}
context.write(key,new LongWritable(sum));
}
}
/*
统计sgyy.txt中的 三国演义 出现的次数
*/
public class SanGuoCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setNumReduceTasks(2);
job.setJobName("统计三国中三国演义和曹操出现的此时");
job.setJarByClass(SanGuoCount.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}然后将写好的代码打包,上传到linux中,通过命令运行
hadoop jar <上传的jar包> main方法的 Reference hdfs中源文件的路径 目标路径、
运行结果如下:

2、MapReduce案例
好友推荐系统
固定类别推荐
莫扎特---->钢琴---->贝多芬----->命运交响曲
数据量
QQ好友推荐--->
每个QQ200个好友
5亿QQ号
解决思路:
需要按照行进行计算
将相同推荐设置成相同的key,便于reduce统一处理
数据:
tom hello hadoop cat world hello hadoop hive cat tom hive mr hive hello hive cat hadoop world hello mr hadoop tom hive world hello hello tom world hive mr
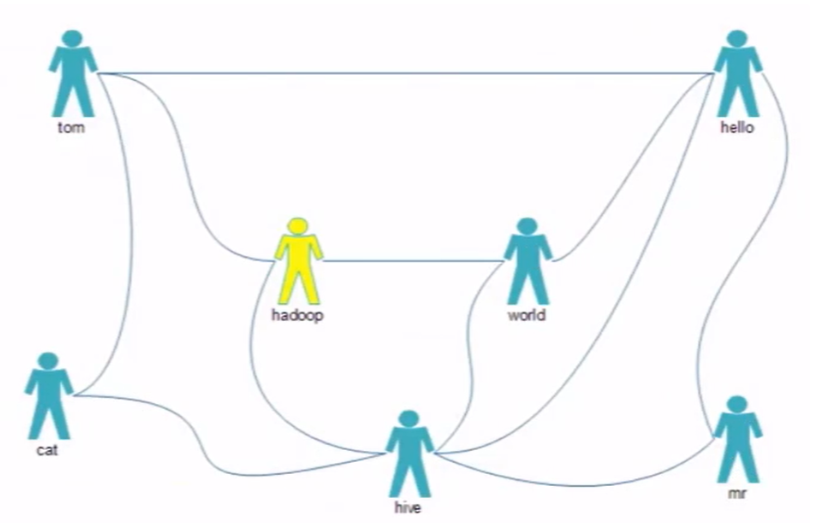
分析:
我们需要在map阶段根据用户的直接联系和间接关系列举出来,map输出的为tom:hadoop 1,hello:hadoop 0,0代表间接关系,1代表直接关系。在Reduce阶段把直接关系的人删除掉,再输出。
具体实现
环境代码
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>java-hadoop</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>anli-tuijian</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
</dependency>
</dependencies>
</project>主程序代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
private Text mkey = new Text();
private LongWritable mvalue = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//tom hello hadoop cat
/**
* tom:hello 1
* tom:hadoop 1
* tom:cat 1
*
* hello:hadoop -1
* hello:cat -1
* hadoop:cat -1
*/
//hadoop tom hive world hello
/**
* hadoop:tom 1
* hadoop:hive 1
* hadoop:world 1
* hello:hadoop 1
*/
//将value类型的数据转换成String类型
String line = value.toString();
String[] strings = line.split(" ");
for (int i = 1; i < strings.length; i++) {
//处理直接好友
mkey.set(orderFriend(strings[0],strings[i]));
mvalue.set(1L);
context.write(mkey,mvalue);
//处理间接好友
for(int j =i+1; j < strings.length; j++) {
mkey.set(orderFriend(strings[i],strings[j]));
mvalue.set(-1L);
context.write(mkey, mvalue);
}
}
}
public static String orderFriend(String f1,String f2){
int i = f1.compareTo(f2);
if(i>0){
return f1+":"+f2;
}else{
return f2+":"+f1;
}
}
}
class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//hadoop:hello 1
//hadoop:hello -1
int flag = 0;
Long sum = 0L;
for (LongWritable value : values) {
if (value.get() == 1) {
flag = 1;
}
sum += value.get();
}
if (flag == 0) {
context.write(key, new LongWritable(-1L));
} else {
context.write(key, new LongWritable(0L));
}
}
}
/**
* @author WangTao
* @date 2022/5/28 10:07
*/
/*
计算出给出的数据中有多少直接关系的组合和间接关系的组合,
将组合作为key
直接关系,value是1
间接关系,value是-1
*/
public class TuiJianDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(TuiJianDemo.class);
job.setNumReduceTasks(1);
job.setJobName("推荐任务");
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}结果如下:
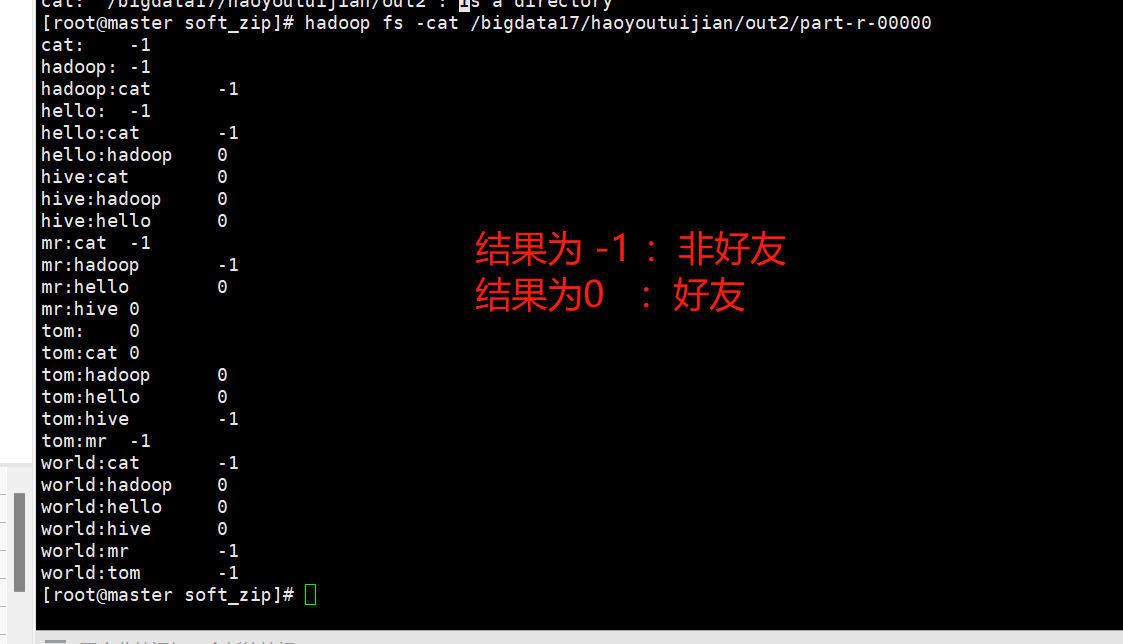
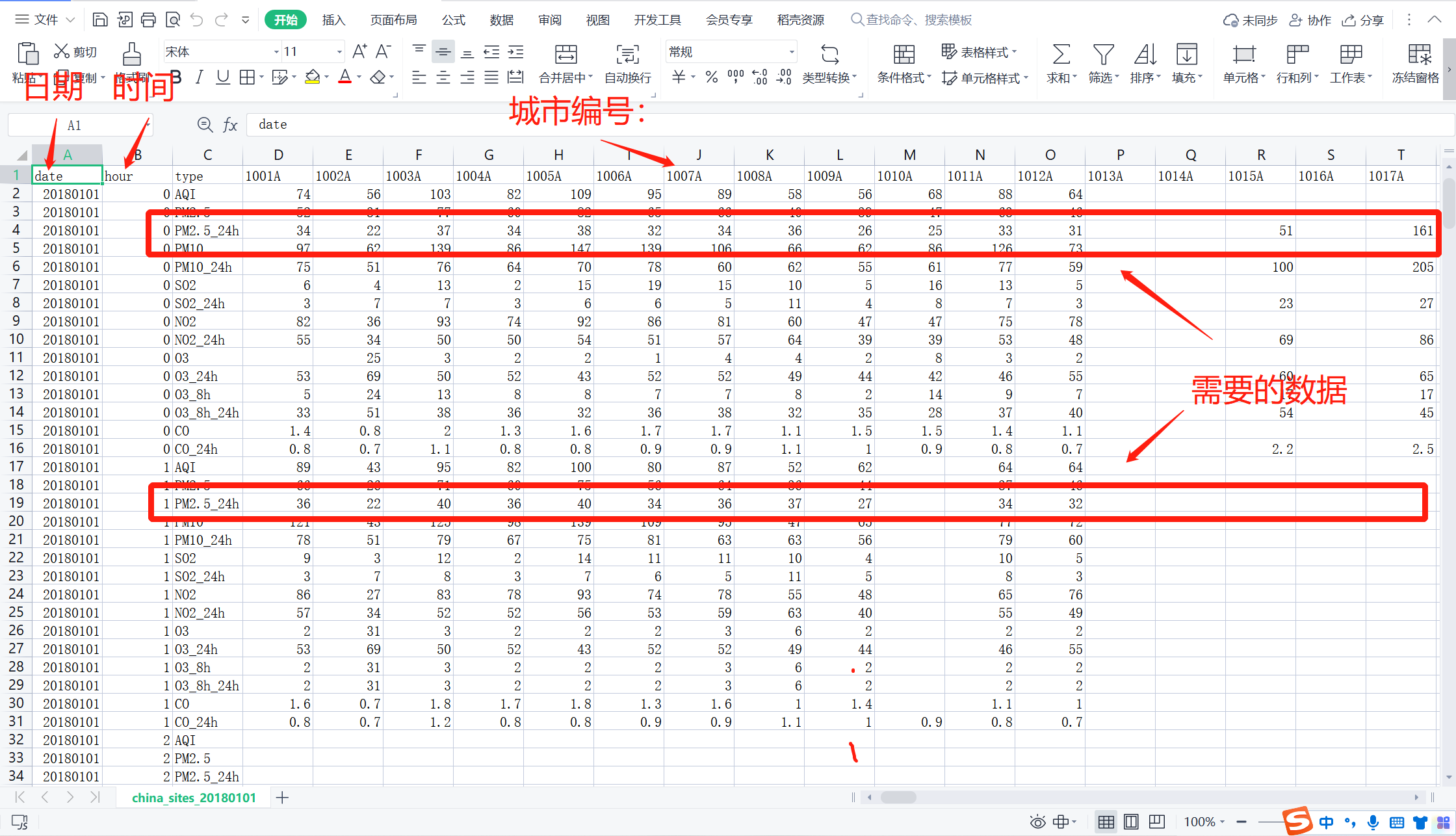
4 PM2.5平均值
表格如下:.csv结尾的都是以 , 间隔的
添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>java-hadoop</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>airPM25avg</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
</dependency>
</dependencies>
</project>代码如下:
package com.shujia.airPM25;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//20220527:1001 20
//20220527:1001 30
//20220527:1001 40
//...
class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//将一行的数据转换成 String 类型的
String line = value.toString();
String[] strings = line.split(",");
//过滤出 Pm2.5 的对应的数据
if(strings.length>=4 && "PM2.5".equals(strings[2])){
for(int i = 3, j = 1001;i < strings.length;i++,j++){
//对一行的数据进行清洗,因为有的时间没有监控到PM2.5的值
if("".equals(strings[i]) || strings[i] ==null || " ".equals(strings[i])){
strings[i] = "0";
}
context.write(new Text("date:"+strings[0]+"-城市编号:"+j),new LongWritable(Long.parseLong(strings[i])));
}
}
}
}
class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
Long sum = 0L;
for (LongWritable value : values) {
long l = value.get();
sum += l;
}
//除以 24 得到该城市当天的 PM2.5 平均值
long avg = sum/24;
context.write(key,new LongWritable(avg));
}
}
/**
* @author WangTao
* @date 2022/5/28 14:11
*/
public class AirPm25avg {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(AirPm25avg.class);
job.setNumReduceTasks(2);
job.setJobName("计算每个城市每天的pm2.5的平均值");
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}注意:args[] 的位置不仅可以填写文件,而且可以填写文件夹
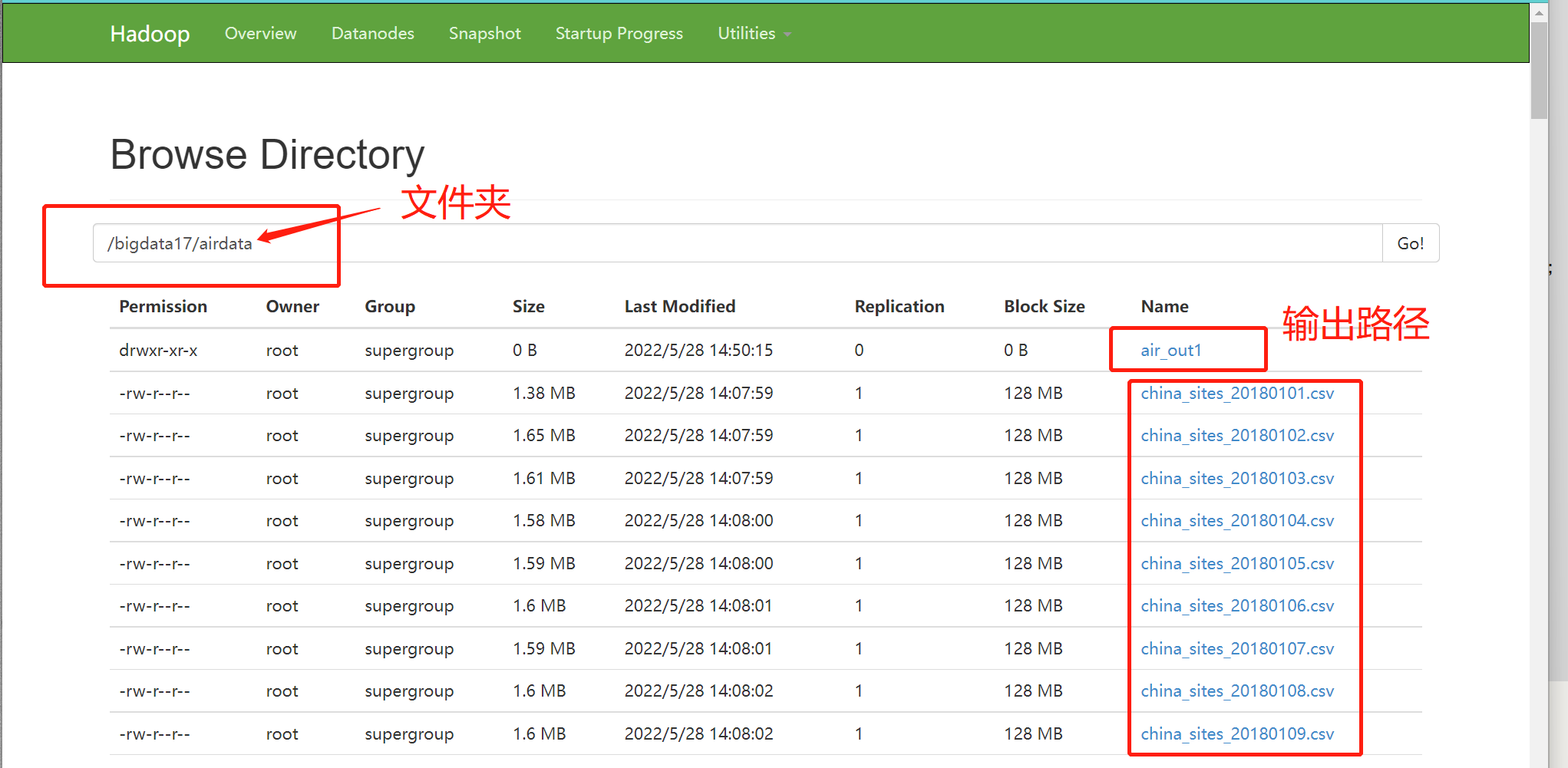
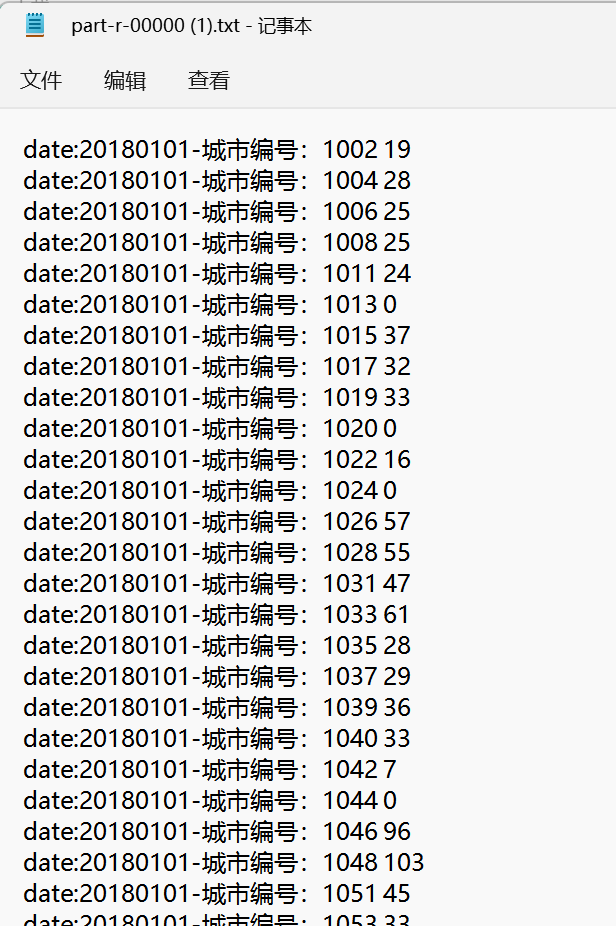
结果:














 2895
2895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









