







一、消息发布流程
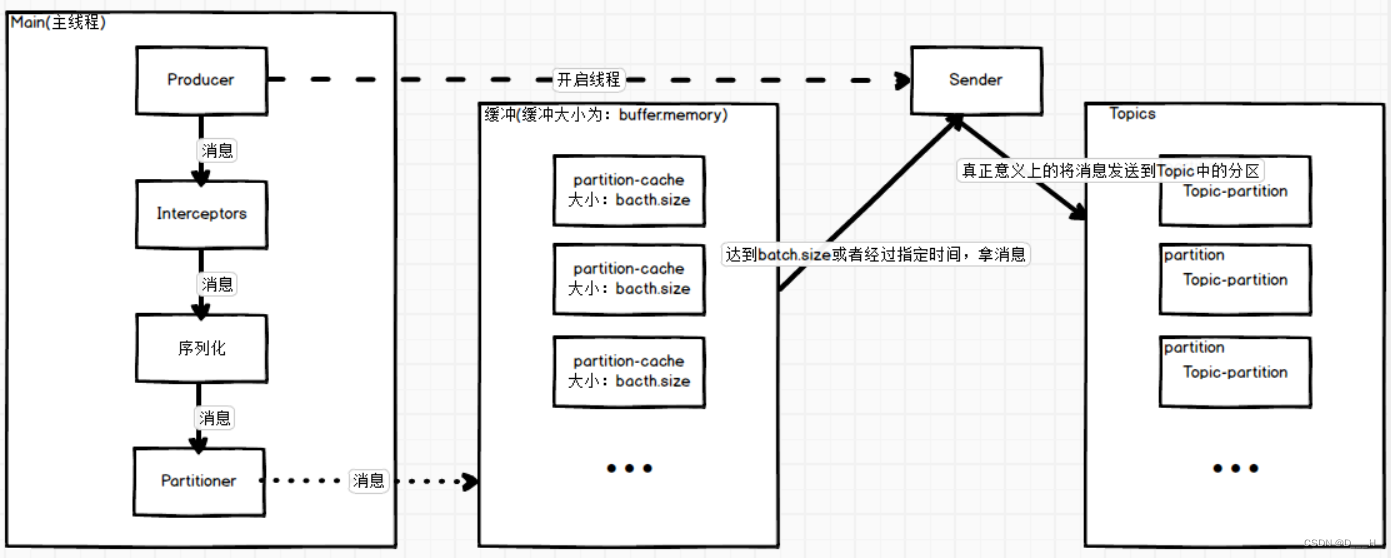
二、Producer
1. 准备工作
(1) 引入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
</dependencies>(2) 于resources下写配置文件log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>
2. 获取Producer操作对象
/*
* 创建生产者的配置对象,Kafka提供了ProducerConfig类用来更方便的指定配置项名称,
* 也可以直接使用字符串进行指定。
*/
Properties prop = new Properties();
// 配置要连接的kafka集群地址
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop101:9092,hadoop102:9092,hadoop103:9092");
// 配置响应等级:0 -> Leader 收到就响应; 1 -> Leader 收到落盘就响应; -1/all -> 所有Partition落盘再响应;
prop.put(ProducerConfig.ACKS_CONFIG, "-1");
// 设置重试次数,当Producer发送消息失败时重试的次数
prop.put(ProducerConfig.RETRIES_CONFIG, "5");
// 消息对应的键值的序列化器,这里采用了字符串的序列化器
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 消息本身对应的序列化器,这里采用了字符串的序列化器
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
/*
* 创建生产者对象
* 创建生产者对象需要指定两个泛型,这两个泛型分别指:该消息对应的键值类型、消息本身的类型
* 这里指定两个类型都是字符串类型
*/
KafkaProducer<String, String> producer = new KafkaProducer<>(prop);3. 拦截器
拦截器代码如下:
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.time.Instant;
import java.util.Map;
/**
* 此处的泛型含义与创建生产者对象的泛型意义完全相同
*/
public class TimeStampInterceptor implements ProducerInterceptor<String, String> {
/**
* 核心方法,在这里可以拦截或者为消息添加内容
* @param producerRecord
* @return
*/
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord) {
/*
* 添加时间戳
*/
long now = Instant.now().getEpochSecond();
String timestampProp = "timestamp:" + now + "\n";
return new ProducerRecord<>(producerRecord.topic(), producerRecord.partition(), producerRecord.key(), timestampProp + producerRecord.value());
}
/**
* 调用时机:(1) 接受到ack;(2) 消息发送失败,抛出异常;
* @param recordMetadata
* @param e
*/
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
if (e == null){
// 消息发送成功,即接受到了ack
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("消息发往的主题为:" + recordMetadata.topic()).append("\n");
stringBuilder.append("消息发往的分区位:" + recordMetadata.partition()).append("\n");
stringBuilder.append("消息逻辑偏移量为:" + recordMetadata.offset()).append("\n");
System.out.print(stringBuilder.toString());
}else {
// 消息发送失败,抛出了异常
System.out.println("消息发送失败:" + e.getMessage());
}
}
/**
* 释放资源
*/
@Override
public void close() {
}
/**
* 读取配置
* @param map
*/
@Override
public void configure(Map<String, ?> map) {
}
}需要在生产者的配置对象中配置拦截器:
// 指定拦截器链,需要将所有拦截器放在一个列表中
List<String> interceptors = new ArrayList<>();
interceptors.add(TimeStampInterceptor.class.getName());
prop.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);4. 分区器
分区器代码如下:
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TimeStampPartitioner implements Partitioner {
/**
* 分区核心方法
* @param topic 消息要发往的主题
* @param key 消息对应的key值
* @param keyBytes key值对应的字节数组
* @param value 消息
* @param valueBytes 消息对应的字节数组
* @param cluster kafka集群,相当于是一个上下文对象
* @return 分区号
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// topic中的分区个数
int partitions = cluster.availablePartitionsForTopic(topic).size();
Pattern pattern = Pattern.compile(".+=[0-9]+$");
Matcher matcher = pattern.matcher((CharSequence) value);
if (matcher.find()){
long timestamp = Long.parseLong(matcher.group().split("=")[1]);
return (int) (timestamp % partitions);
}
// 默认到0号分区
return 0;
}
/**
* 释放资源
*/
@Override
public void close() {
}
/**
* 读取配置
* @param configs
*/
@Override
public void configure(Map<String, ?> configs) {
}
}需要在生产者的配置对象中配置默认使用的分区器:
// 指定分区器,配置后默认分区器不再使用粘性分区,而是使用自定义的分区器
prop.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, TimeStampPartitioner.class.getName());5. 发送消息
(1) 不带回调 + 异步发送
/*
* 将消息生产到topic中
*/
String baseInfo = "producer produce message-";
for (int i = 0; i < 10; i++) {
// 不带回调,异步发送:不管上一条消息有没有成功落盘,上一条消息发送出去后立刻发送下一条消息
// 使用粘性分区策略或者自定义分区策略(如果要使用自定义的话,必须先配置好分区器)
producer.send(new ProducerRecord<>("test1", baseInfo + i));
}(2) 带回调 + 异步发送
/*
* 将消息生产到topic中
*/
String baseInfo = "producer produce message-";
for (int i = 0; i < 10; i++) {
// 带回调,异步发送:不管上一条消息有没有成功落盘,上一条消息发送出去后立刻发送下一条消息
// 指定key值,使用key值的哈希码区域分区数决定所属分区
producer.send(new ProducerRecord<>("test2", UUID.randomUUID().toString(), baseInfo + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
/*
* 该方法调用的实际为:(1) 消息成功落盘,返回响应;(2) 消息落盘失败,发生异常;
*/
if (exception == null){
// 消息成功落盘,返回响应
String pattern = "消息发往主题为:{0}; 消息发往分区为:{1}; 消息逻辑偏移量为:{2};";
String message = MessageFormat.format(pattern, metadata.topic(), metadata.partition(), metadata.offset());
System.out.println(message);
}else {
// 消息落盘失败,发生异常
System.out.println("消息落盘失败,抛出异常为:" + exception.getMessage());
}
}
});(3) 不带回调 + 同步发送
/*
* 将消息生产到topic中
*/
String baseInfo = "producer produce message-";
for (int i = 0; i < 10; i++) {
// 不带回调,同步发送:当上一条消息成功落盘并返回响应时(响应之前当前线程处于阻塞状态),才会继续发送下一条消息
// 指定key值,使用key值的哈希码区域分区数决定所属分区
Future<RecordMetadata> future = producer.send(new ProducerRecord<>("test2", UUID.randomUUID().toString(), baseInfo + i));
// get()方法等待返回结果,返回之前当前线程处于阻塞
future.get();
}(4) 带回调 + 同步发送
/*
* 将消息生产到topic中
*/
String baseInfo = "producer produce message-";
for (int i = 0; i < 10; i++) {
// 带回调,同步发送:当上一条消息成功落盘并返回响应时(响应之前当前线程处于阻塞状态),才会继续发送下一条消息
// 发送到指定分区
Future<RecordMetadata> future = producer.send(new ProducerRecord<>("test2", i % 3, UUID.randomUUID().toString(), baseInfo + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
/*
* 该方法调用的实际为:(1) 消息成功落盘,返回响应;(2) 消息落盘失败,发生异常;
*/
if (exception == null) {
// 消息成功落盘,返回响应
String pattern = "消息发往主题为:{0}; 消息发往分区为:{1}; 消息逻辑偏移量为:{2};";
String message = MessageFormat.format(pattern, metadata.topic(), metadata.partition(), metadata.offset());
System.out.println(message);
} else {
// 消息落盘失败,发生异常
System.out.println("消息落盘失败,抛出异常为:" + exception.getMessage());
}
}
});
// get()方法等待返回结果,返回之前当前线程处于阻塞
future.get();
}6. 关闭Producer对象
/*
* 关闭生产者对象,释放资源
*/
producer.close();三、Consumer
什么时候会offset重置:
新的消费者组去消费主题时;
消费者组之前消费到主题某一位置的消息已被删除;
1. 准备工作
(1) 引入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
</dependencies>(2) 于resources下写配置文件log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>
2. 获取Consumer操作对象
/*
* 配置对象
*/
Properties prop = new Properties();
// 指定要连接的zk服务器地址
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop101:9092,hadoop102:9092,hadoop103:9092");
// 指定消费者所属的消费者组
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "tp2");
// 配置offser自动提交
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// offset 重置的位置:latest(每个分区中最后的逻辑偏移处), earliest(每个分区中最开始的逻辑偏移处,不一定为0,因为可能之前的消息已经被自动删除了)
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 配置反序列化器,此处为字符串的反序列化器
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
/*
* 创建消费者
* 泛型的含义与生产者一样
*/
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);3. 订阅并消费消息
/*
* 订阅主题并消费数据
* 可以订阅多个主题:使用正则表达式或者列表
*/
Pattern pattern = Pattern.compile("^test[0-9]+$");
consumer.subscribe(pattern);
boolean continued = true;
String messagePattern = "消息来自主题为:{0}; 消息来自分区为:{1}; 消息的逻辑偏移量为:{2}";
while (continued){
// 让消费者每隔2s去主题内消费一部分消息,防止频繁去主题中消费消息,从而导致效率缓慢
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord<String, String> record : consumerRecords) {
// test方法是自定义的,用来判断record是否满足条件,主要作用是用来指定满足某种条件后,终止循环的
continued = test(record);
if (!continued){
break;
}
System.out.println(MessageFormat.format(messagePattern, record.topic(), record.partition(), record.offset()));
}
}4. Offset提交方式
(1) 自动提交
配置对象指定自动提交即可:
/*
* 配置对象
*/
Properties prop = new Properties();
// 指定要连接的zk服务器地址
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop101:9092,hadoop102:9092,hadoop103:9092");
// 指定消费者所属的消费者组
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "tp2");
// 配置offser自动提交,每隔一段时间自动提交
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// offset 重置的位置:latest(每个分区中最后的逻辑偏移处), earliest(每个分区中最开始的逻辑偏移处,不一定为0,因为可能之前的消息已经被自动删除了)
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 配置反序列化器,此处为字符串的反序列化器
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());(2) 异步手动提交
首先需要关闭自动提交:
/*
* 配置对象
*/
Properties prop = new Properties();
// 指定要连接的zk服务器地址
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop101:9092,hadoop102:9092,hadoop103:9092");
// 指定消费者所属的消费者组
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "tp2");
// 配置offser自动提交
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// offset 重置的位置:latest(每个分区中最后的逻辑偏移处), earliest(每个分区中最开始的逻辑偏移处,不一定为0,因为可能之前的消息已经被自动删除了)
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 配置反序列化器,此处为字符串的反序列化器
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());消费消息后异步手动提交:
/*
* 订阅主题并消费数据
* 可以订阅多个主题:使用正则表达式或者列表
*/
Pattern pattern = Pattern.compile("^test[0-9]+$");
consumer.subscribe(pattern);
boolean continued = true;
String messagePattern = "消息来自主题为:{0}; 消息来自分区为:{1}; 消息的逻辑偏移量为:{2}";
while (continued){
// 让消费者每隔2s去主题内消费一部分消息,防止频繁去主题中消费消息,从而导致效率缓慢
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord<String, String> record : consumerRecords) {
// test方法是自定义的,用来判断record是否满足条件,主要作用是用来指定满足某种条件后,终止循环的
continued = test(record);
if (!continued){
break;
}
System.out.println(MessageFormat.format(messagePattern, record.topic(), record.partition(), record.offset()));
}
// 异步手动提交
consumer.commitAsync();
}(3) 同步手动提交
首先需要关闭自动提交:
/*
* 配置对象
*/
Properties prop = new Properties();
// 指定要连接的zk服务器地址
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop101:9092,hadoop102:9092,hadoop103:9092");
// 指定消费者所属的消费者组
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "tp2");
// 配置offser自动提交
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// offset 重置的位置:latest(每个分区中最后的逻辑偏移处), earliest(每个分区中最开始的逻辑偏移处,不一定为0,因为可能之前的消息已经被自动删除了)
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 配置反序列化器,此处为字符串的反序列化器
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());消费消息后同步手动提交:
/*
* 订阅主题并消费数据
* 可以订阅多个主题:使用正则表达式或者列表
*/
Pattern pattern = Pattern.compile("^test[0-9]+$");
consumer.subscribe(pattern);
boolean continued = true;
String messagePattern = "消息来自主题为:{0}; 消息来自分区为:{1}; 消息的逻辑偏移量为:{2}";
while (continued){
// 让消费者每隔2s去主题内消费一部分消息,防止频繁去主题中消费消息,从而导致效率缓慢
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord<String, String> record : consumerRecords) {
// test方法是自定义的,用来判断record是否满足条件,主要作用是用来指定满足某种条件后,终止循环的
continued = test(record);
if (!continued){
break;
}
System.out.println(MessageFormat.format(messagePattern, record.topic(), record.partition(), record.offset()));
}
// 异步手动提交
consumer.commitSync();
}5. 关闭Consumer对象
/*
* 关闭消费者,释放资源
*/
consumer.close();四、案例
1. 场景:
现在有三个Topic分别为:baidu、iqiyi、other,每一个Topic都拥有两个分区;分别启动一个生产者和一个消费者,生产者负责产生网址消息,并要求每一条网址消息都要附加上时间戳,将时间戳范围在0~11点的消息发往0号分区,11~24点的消息发往1号分区,消费者负责消费多个主题中的数据。
2. 准备工作
(1) 引入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
</dependencies>(2) 于resources下写配置文件log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>
(3) 创建主题
kafka-ops.sh topics --create --topic baidu --partitions 2 --replication-factor 3
kafka-ops.sh topics --create --topic iqiyi--partitions 2 --replication-factor 3
kafka-ops.sh topics --create --topic other--partitions 2 --replication-factor 33. 编码
拦截器TimestampInterceptor类的编写,用于为每一条消息添加时间戳:
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.time.Instant;
import java.util.Map;
public class TimestampInterceptor implements ProducerInterceptor<String, String> {
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
Long now = Instant.now().getEpochSecond();
return new ProducerRecord<>(record.topic(), record.partition(), record.key(), "timestamp=" + now + "\n" + record.value());
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}分区器TimestampPartitioner类编写,用于将消息分区存放:
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TimestampPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
int partition = -1;
Pattern pattern = Pattern.compile(".+=[0-9]+[^\\n]");
Matcher matcher = pattern.matcher((CharSequence) value);
if (matcher.find()){
Long timestamp = Long.parseLong(matcher.group().split("=")[1]);
Instant instant = Instant.ofEpochSecond(timestamp);
LocalDateTime dateTime = LocalDateTime.ofInstant(instant, ZoneId.systemDefault());
if (dateTime.getHour() >= 0 && dateTime.getHour() <= 11){
partition = 0;
}else {
partition = 1;
}
}
return partition;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}生产者代码:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.UUID;
public class WebsiteProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop101:9092,hadoop102:9092,hadoop103:9092");
properties.put(ProducerConfig.RETRIES_CONFIG, "5");
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, TimestampInterceptor.class.getName());
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, TimestampPartitioner.class.getName());
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
String topic = "";
String website = "";
for (int i = 0; i < 1000; i++) {
if (i % 3 == 0){
topic = "baidu";
website = "https://www.baidu.com/" + UUID.randomUUID().toString();
}else if (i % 3 == 1){
topic = "iqiyi";
website = "https://www.iqiyi.com/" + UUID.randomUUID().toString();
}else {
topic = "other";
website = "https://www." + UUID.randomUUID().toString() + ".com/" + UUID.randomUUID().toString();
}
producer.send(new ProducerRecord<>(topic, website));
}
producer.close();
}
}消费者代码:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.text.MessageFormat;
import java.time.Duration;
import java.util.Properties;
import java.util.regex.Pattern;
public class WebsiteConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop101:9092.hadoop102:9092,hadoop103:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "tp");
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Pattern.compile("(baidu|iqiyi|other)"));
String pattern = "topic: {0}; partition: {1}; offset: {2}; value: {3}";
boolean continued = true;
while (continued){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord<String, String> record : records) {
continued = test(record);
if (!continued){
break;
}
System.out.println(MessageFormat.format(pattern, record.topic(), record.partition(), record.offset(), record.value()));
}
}
consumer.close();
}
public static boolean test(ConsumerRecord record){
return true;
}
}














 2214
2214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









