



hichuStableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On
Jeongho Kim Gyojung Gu Minho Park Sunghyun Park Jaegul Choo KAIST, Daejeon, South Korea {rlawjdghek, gyojung.gu, m.park, psh01087, jchoo}@kaist.ac.kr
2023-12-04,韩国科学技术院发表

Figure 1. Generated results of StableVITON: VITON-HD (the first row), SHHQ-1.0 (the first two images in the second row), and webcrawled images (the last two images in the second row). All results are generated using StableVITON trained on VITON-HD dataset.
摘要
鉴于服装图像和人物形象,基于图像的虚拟试验旨在生成自定义图像,该图像看起来自然,并且可以准确反映服装图像的特征。在这项工作中,我们旨在扩展预训练的扩散模型的适用性,以便可以独立地用于虚拟的尝试任务。主要的挑战是保留服装细节,同时有效地利用预训练模型的可靠生成能力。为了解决这些问题,我们提出了StableVITON,以端对端的方式学习了在预训练的扩散模型的潜在空间内的服装与人体之间的语义对应关系。我们提出的零交叉注意块不仅通过学习语义来保留服装细节,而且还通过在翘曲过程中利用预先训练的模型的固有知识来产生高保真图像。通过我们提出的新型注意力,总变化损失和应用增强,我们获得了尖锐的注意力图,从而更加精确地表示服装细节。 StableVITON在定性和定量评估中优于基准,显示了任意人图像中有希望的质量。我们的代码链接:https://github.com/%20rlawjdghek/StableVTON
该论文的目的是扩展预训练的扩散模型的实用性,用于虚拟试穿任务中,而主要挑战是保留服装细节,同时有效地利用预训练模型的可靠生成能力。因此作者提出StableVITON模型,以端对端的方式学习了在预训练的扩散模型的的潜在空间内的服装与人体之间的语义对应关系。
作者提出零交叉注意力块来学习语义信息以保留服装细节,并且提出总变分损失和应用增强获得尖锐的注意力图,从而更加精确地表示服装细节。
1.引言
基于图像的虚拟尝试的目的是在目标人形象上打扮给定的服装图像。以前的大多数虚拟尝试方法中的大多数[3,7,10,14,15,30,32,34]利用配对的数据集,这些数据集由衣服图像和穿着这些服装的人员图像组成,以用于训练。这些方法通常包括两个模块:(1)翘曲网络,以学习衣服和人体之间的语义对应关系,以及(2)融合扭曲的衣服和人形象的生成器。
尽管取得了重大进步,但先前的方法[3、8、15、32]在实现普遍性方面仍然有局限性,尤其是在任意人形象中保持复杂的背景时。在虚拟试验数据集[3,10,19]中,匹配服装和个人的性质使得在不同环境中收集数据[21]挑战[21],这反过来又导致了生成器生成能力的限制。
同时,大规模预处理扩散模型的最新进展[24,25,28]导致了下游任务的出现[6,8,8,16,20,27,35,37],该任务控制了针对特定任务特定图像产生的预训练扩散模型。由于具有强大的生成能力,几项作品[18,35]成功地使用了预训练的模型来综合高保真人类图像,这表明可能扩展到虚拟的尝试任务。
在本文中,我们旨在扩大预训练的扩散模型的适用性,以为虚拟试验任务提供独立的模型。为了适应虚拟试验预验证的扩散模型,一个重大挑战是保留衣服细节,同时利用预先训练的扩散模型的知识。这可以通过使用提供的数据集学习服装和人体之间的语义对应关系来实现。最近在虚拟试验中采用了预测的扩散模型的最新研究[8,20],由于以下两个问题显示了局限性:(1)可用于学习语义对应关系的空间信息不足[20]和(2)预训练的扩散模型没有得到充分利用,因为它将翘曲服装粘贴在RGB空间中,依赖外部翘曲网络。如[3,7,15,32,34] 对齐输入条件。
以前虚拟试穿的方法一般利用配对的数据集组成,用于训练,且该方法一般有两个模块:1.翘曲网络,以学习衣服和人之间的语义关系;2.融合扭曲的衣服和人的生成器。这些方法在普遍性存在局限,尤其是在任意人形象中保持复杂的背景时。而扩散大模型的下游任务兴起,对特定任务特定图像产生预训练扩散模型可生成高保真人类图像,因此作者使用预训练大模型来实现虚拟试穿,但其中存在的重大挑战是保留衣服的细节。
当前在虚拟试穿中采用预训练扩散模型的研究中存在两个局限性:1.可用于学习语义对应关系的空间信息不足;2.预训练的扩散模型没有得到充分利用,因为它将翘曲服装粘贴在RGB空间中,依赖外部翘曲网络。
为了克服这些问题,我们提出了StableVITON,它在预训练的扩散模型的潜在空间内学习服装与人体之间的语义对应关系。为了融合服装的空间信息用于学习语义对应,我们引入了一个编码器[ 35 ],该编码器以服装作为输入,并通过零交叉注意力块将编码器的中间特征对U - Net进行条件化。在预训练的扩散模型具有以下两个优点:(1)通过学习语义对应关系来保留服装细节; (2)通过利用预先训练的模型在扭曲过程中对人类的固有知识来综合高保真图像。如图2所示,潜在空间中的注意力机制通过激活对应于生成区域内服装对准的每个令牌来执行 patch-wise 翘曲。
为了进一步提高注意力图,我们提出了一种新颖的注意力变分损失并应用增强,从而改善了服装细节的保存。通过不损害预训练的扩散模型,即使提供具有复杂背景的图像,仅使用现有的虚拟试验数据集,该体系结构即使提供了复杂的背景图像也会生成高质量的图像。我们的广泛实验表明,StableViton的表现优于现有的虚拟试验方法,这是一个很大的边距。总而言之,我们的贡献如下:
- 据我们所知,我们提议的StableVITON是在没有独立翘曲过程的预训练的扩散模型上进行的第一个端到端的虚拟试穿方法。
- 我们提出了一个零交叉注意区,该区块学习了衣服和人体之间的语义对应关系,以调节空间编码器中间特征。
- 我们提出了一种新颖的注意总变分损失,并应用增强量以进行进一步的精确语义对应学习。
- StableVITON在定性和定量结果中都显示了现有虚拟试验模型的最新性能。此外,通过评估多个数据集的训练模型,StableVITON在现实环境中展示了其有希望的质量。
预训练模型具有两个优点:1.通过学习语义对应关系来保留服装细节;2.通过利用预先训练的模型在扭曲过程中对人类的固有知识来综合高保真图像。
所以作者首先以交叉注意力块来学习衣服和人体之间的语义对应关系,从而调节空间编码器中间特征,并为了进一步提高注意力图,提出了一种新颖的注意力变分损失并应用增强,从而改善了服装细节的保存。
2.相关工作
基于GAN的虚拟试穿。为了适当地对目标人进行给定的服装图像,基于生成对抗网络(GAN)的现有方法[3,7,15,32]试图使用两阶段的策略来解决虚拟的尝试问题:(1)将衣服变形为提案区域,并(2)通过基于GAN的试穿生成器融合扭曲的服装。为了实现精确的衣服变形,先前的方法[1、7、11、15、32]利用了可训练的网络,该网络估算了密集的流量图[38],以将衣服变形为人体。同时,已经尝试了几种方法[3、7、14、15、32、34],以解决扭曲的衣服与人体之间的错位,例如使用归一化[3]或蒸馏[7,14]。但是,现有方法仍然没有很好地生成,从而导致具有复杂背景的任意人图像的效果降低。在本文中,我们通过提出一种利用预训练模型的强大生成能力的方法来有效地解决此类问题。
基于GAN的虚拟试穿,使用两阶段的策略来解决虚拟的尝试问题:(1)将衣服变形为提案区域,并(2)通过基于GAN的试穿生成器融合扭曲的服装。该方法无法很好地生成。
基于扩散的虚拟尝试。由于具有显着的生成能力,对虚拟试验的研究已广泛讨论了扩散模型的应用。虽然TryOnDiffusion [39]介绍了使用两个U-NET的架构进行试用的架构,但此方法需要一个大规模且挑战性的数据集,该数据集由同一个人组成的图像对组成,以两种不同的姿势穿着相同的衣服。因此,最近的许多研究已将重点转向使用虚拟试验任务中大规模预训练的扩散模型[13、23、25、33]的先验。 LADI-VTON [20]将服装表示为伪词,而DCI-VTON[8]使用一个翘曲网络将衣服作为预训练的扩散模型的条件输入。尽管这两种模型都涉及与背景相关的问题,但由于 CLIP 编码器[20]的空间信息过多丢失以及诸如从独立翘曲网络[8]中继承的错误翘曲的衣服等的缺点,因此它们受到了保留高频细节的影响。另一方面,我们建议通过零交叉块来调节空间编码器的中间特征图,该图可以在翘曲过程中使用预训练模型的先验知识。
基于扩散模型的虚拟试穿,其中两个模型都是涉及与背景相关的问题,但由于 CLIP 编码器的空间信息过多丢失以及从独立翘曲网络中继承的错误翘曲衣服等的缺点,难以保留高频细节。而作者通过零交叉注意力块来条件空间编码器的中间特征图,在翘曲过程中使用预训练模型的先验知识。
3.准备工作
稳定扩散模型。稳定的扩散模型[25]是一种在LAION数据集[29]上训练的大规模扩散模型,该模型构建在潜在扩散模型(LDM)[25]上,该模型[25],在自动码编码器的潜在空间中执行了deno的过程。使用固定的编码器(E),首先将输入图像X转换为潜在特征Z0 = E(x)。给定预定义的方差时间表βT,我们可以在降级后定义潜在空间中的正向扩散概率模型[13]:
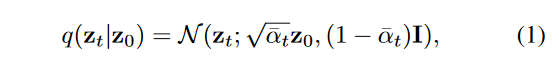
其中t∈{1,...,...,t},t表示向前扩散过程中的步骤数,αT:= 1- = 1 -βT和<1αs:= 1 -βT,和<1αs:作为训练损失,稳定的扩散模型采用了LDM [15]:
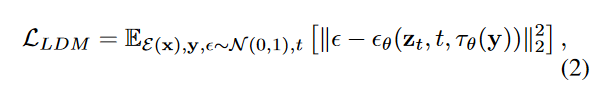
与denoising网络εθ(zt,t,2)文本编码器以调节文本提示y。
4.方法
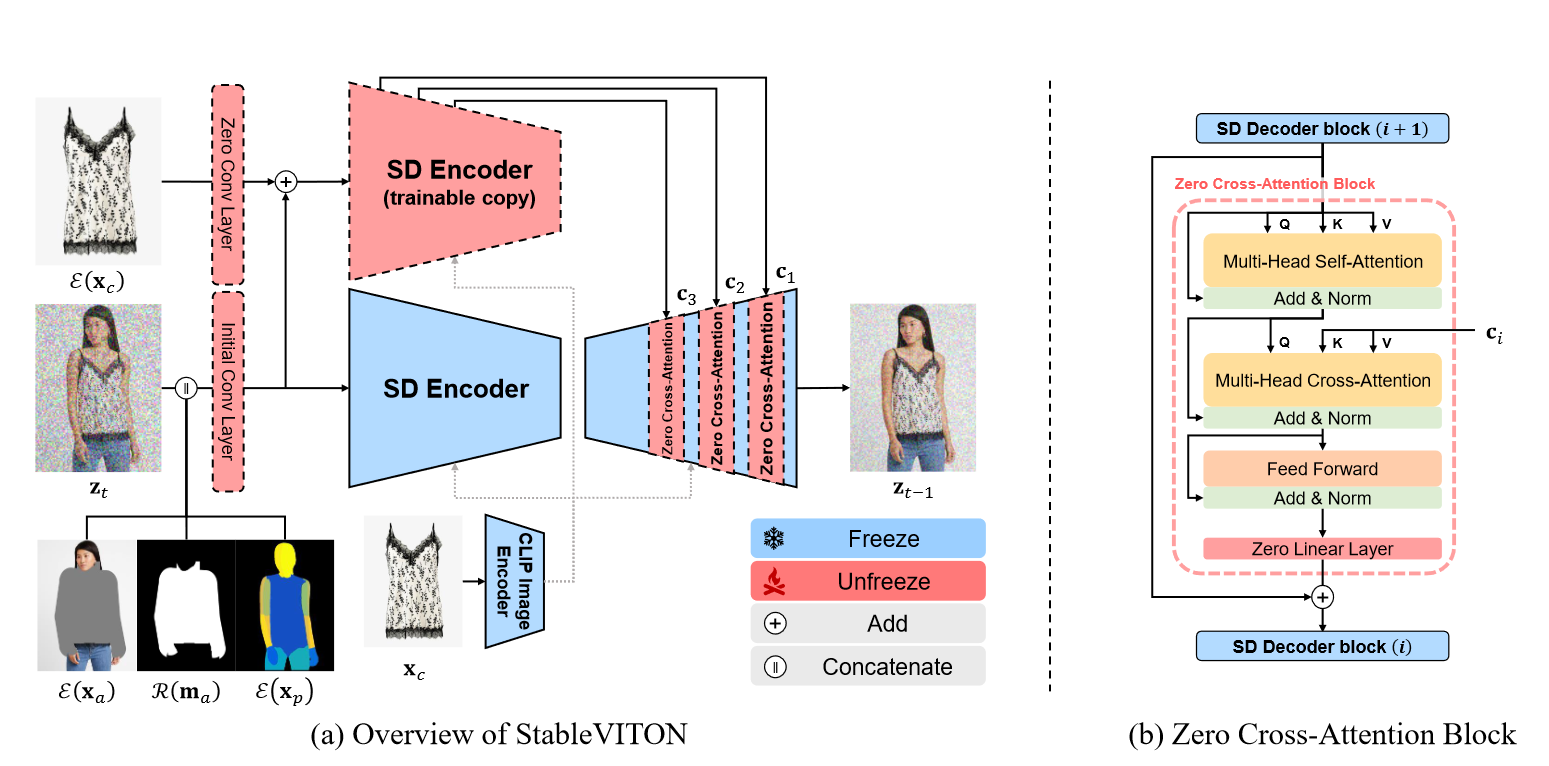
图3。对于虚拟的尝试任务,StableVITON还采用三个条件:不可知论地图,不可知论掩码和致密姿势,作为预训练的U-NET的输入,作为交叉注意的查询(q)。服装的特征图用作交叉注意的钥匙(k)和值(v),并在UNET上进行条件,如(b)所示。
4.1模型概述
图3(a)列出了StableVITON的概述。给定一个人图像x∈Rr×W×3,服装 - 掩码的人表示Xa∈Rhr×W×3(我们称其为“不可知映射”) [3]来消除X中的任何衣服信息。在这项工作中,我们将虚拟试验作为基于典范的图像介入问题[33]接近,以用服装图像Xc填充不可知映射Xa。作为U-NET的输入,我们将四个组成部分加和:(1)噪声(Zt),(2)潜在的不可知映射(E(Xa)),(3)调整大小的服装 - 掩码(Xma),(4)潜在的密集姿势状况(E(Xp))[9]。 为了使输入通道对齐,我们将U-NET的初始卷积层扩展到13(即4+4+1+4 = 13)通道,其卷积层初始化为零重量。对于示例性调节,我们将Xc输入到CLIP图像编码[33]中。为了保留衣服的细节,我们引入了一个空间编码器,该空间编码器将潜在服装(E(Xc))作为输入。该空间编码器复制了预训练的U-NET [35]的Encoder,并通过零跨注意区块调节编码器的中间特征图到U-NET。在训练期间,我们通过提出的注意总变异损失应用进一步增强模型,这使衣服上的注意力区域更加清晰。详细的模型结构在补充材料中描述。
4.2 Stableviton
零跨注意区。我们的目标是将衣服的中间特征图调节到U-NET,与人体正确对齐。由于人体和衣服之间的未对准,将未对齐的服装特征图添加到人类特征图中的操作不足以保留服装细节。因此,我们通过应用注意机制进行调节,提出了一个零的跨注意区块。
具体而言,如图3(b)所示,UNET解码器块的特征图输入了自我注意力,然后是跨交叉注意层,其中查询(Q)来自先前的自我注意力层,而空间编码器的特征映射则用作键(k)和值(v)。为了消除有害的噪声,我们引入了一个线性层,在进料前进操作后以零重量初始化的线性层[35]。目的是通过交叉注意力成功将衣服与人体部分保持一致,确保关键令牌(衣服)和查询令牌(人体)之间的语义对应至关重要。例如,在处理与右肩相关的查询令牌时,相应的钥匙令牌应在衣服的相应右肩区域显示出更高的注意力分数。在图4(a)中,我们平均32×24分辨率的注意力图,并平行地排列它们。为了进行清晰的可视化,我们将生成的图像简化为32×24的分辨率,然后将其调整回32^2×24^2。随后,我们将此生成的图像叠加在与每个查询令牌相对应的注意力图中。在生成的服装区的上部和中间放大,我们观察到与相应的查询令牌无关的关键令牌(例如衣服的底部)在注意图中被激活。这表明交叉注意力层无法学习查询和钥匙令牌之间的确切语义对应关系,将衣服的几个关键令牌结合在一起,以生成与训练过程中查询令牌相对应的颜色。因此,如图4所示,衣服上的条纹并不明显。

图4。从32分辨率的零跨注意区块的注意图可视化。
增强。为了减轻与要查询的关键令牌无关的关键令牌问题,我们通过应用扩展(包括随机移动到输入条件)来更改特征图。补充材料中描述了详细的增强设置。除了增强输入条件外,我们还使用定义为以下的目标函数训练模型:
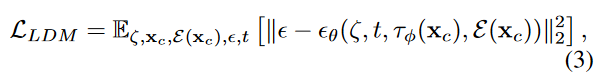
其中ζ= [ZT; e(xa); XMA; e(xp)],τφ是CLIP图像编码器。请注意,我们没有更新原始块的参数,如图3(a)所示。
这种策略背后的理由是迫使模型使用增强性学习细粒的语义对应关系,而不仅仅是适度地注入类似位置的衣服。如图4(b)所示,我们可以确认与查询令牌相关的关键令牌具有很高的注意力分数,这表明跨注意力层已经了解了服装掩码区域和服装之间的高语义对应关系。
注意总变异损失。虽然跨注意力层成功地将衣服与不可知映射对齐,但注意力分数高的点出现在分散位置,如图4(b)的注意图所示。这会导致生成的图像(例如颜色差异)中的细节不正确。
为了解决这一问题,我们提出注意总变化损失。由于注意力分数是输出的权重,因此我们将中心坐标计算为注意图和网格的加权总和。因此,给定HqWq查询令牌和HkWk键令牌,我们计算中心坐标图F∈RHq×Wq×2如下:
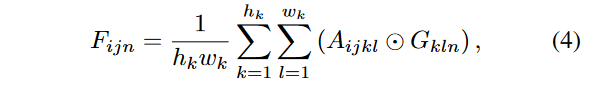
如果我们平均将注意力图上的注意力图映射为A∈RHq×Wq×hk×wk,将其重塑为G∈ [−1,1] hk×wk×2是2D归一化坐标。 ⊙表示元素乘法操作。对于每个服装 - 掩码中的每个查询令牌,中心坐标都应均匀分布,并且注意力变化损失LATV的定义如下:
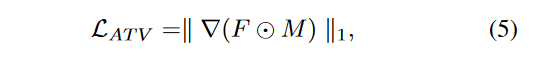
其中M∈{0,1} Hq×Wq是仅影响服装区域的真实地真掩码。注意力变化损失LATV旨在强制在注意图上均匀分布的中心坐标,从而减轻位于分散位置的注意力分数的干扰。如图(c)所示,这导致产生更清晰的注意力图,从而更准确地反映了衣服的颜色。
最后,我们通过将LATV添加到等式来确定我们的StableVITON。
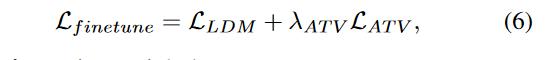
其中λatV是权重的超参数。
5.实验
基线。我们将StableVITON与三种基于GAN的虚拟尝试方法(Viton-HD [3],HRVITON [15]和GP-VTON [32]以及两种基于差异的虚拟试穿方法,Ladi-VTON [20]和DciVTON [8]。我们还评估了一种基于扩散的镶嵌方法,逐个示例[33]。如果有的话,我们使用预训练的权重;否则,我们按照官方代码训练模型。
数据集。我们使用两个公开可用的虚拟尝试数据集VITON-HD[3]和DressCode [19]以及一个人类图像数据集SHHQ-1.0 [5]进行实验。我们分别在DressCode中使用VITON-HD和上身图像训练模型。为了评估SHHQ-1.0,我们使用前2,032张图像,并遵循VITON-HD的预处理指令[3]以获得输入条件,例如不可知映射或密集姿势。
评估。我们评估两个测试设置中的性能。具体而言,配对设置使用一对人和原始衣服进行重建,而未配对的设置涉及用不同的衣服更改人物的衣服。作为先前的工作[3],单个数据集中的培训和评估称为“单个数据集评估”。另一方面,我们将评估扩展到其他数据集(例如SHHQ-1.0)上,我们将其称为“跨数据集评估”。该评估可以深入评估该模型在处理任意人图像中的普遍性,并在现实世界中证明了适用性。我们的模型能够以1024×768的分辨率进行训练,但是对于基准进行了公平评估,我们使用了以512×384分辨率训练的模型。补充材料中描述了有关实验的更多结果和详细信息。
5.1。定性结果单数据集评估。

图5。在单个数据集设置(Viton-HD / Viton-HD)中与基线的定性比较。放大时最好查看。

图6。与基线的定性比较(Viton-HD / DressCode)中的基线。放大时最好查看。
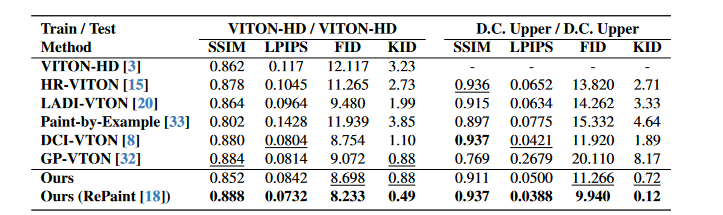
表1。单个数据集设置,Viton-HD和Dress Code上身(D.C. Upper)数据集中的定量比较。加粗和下划线分别表示最佳和第二好的结果。
如图5所示,StableVITON生成了逼真的图像,并有效地保留了与六种基线方法相比的文本和衣物纹理。具体而言,在图5的第一行中,基于GAN的方法(例如GP-Vton)努力自然地产生目标人的臂。此外,其他基于扩散的模型要么无法保留文本(示例和Ladi-VTON),要么显示服装与目标人(DCI-VTON)之间的重叠人工制品。另一方面,尽管手臂的某些部分被衣服覆盖,但我们的模型仍会产生高保真的结果,从而省略了“LOVE”中的“ L”。交叉数据集评估。我们分别可视化在图6和图7中分别在VITON-HD上训练用于DressCode和SHHQ-1.0数据集的模型的生成图像。结果清楚地表明了StableVITON生成高保真图像,同时保留衣服的细节。基于GAN的方法尤其显示出对目标人的重要文物,并且无法保持背景。尽管基于扩散的方法会产生自然图像,但它们无法保留服装细节或衣服的形状。此外,即使应用了dci-vton的增强,如图7所示,也没有实现翘曲网络的性能显着改善,但未能保留服装细节。

图7。在跨数据集设置中与基线的定性比较(Viton-HD / SHHQ-1.0)。放大时最好查看。
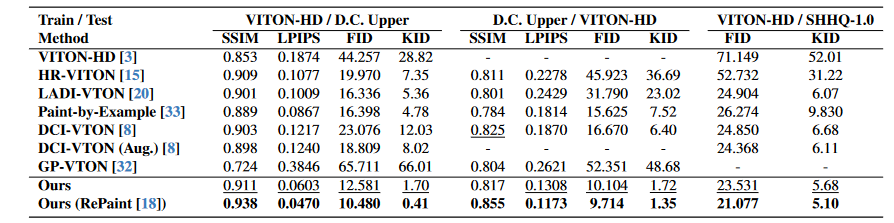
表2。交叉数据集设置中的定量比较。我们在Viton-HD和DressCode上身(D.C. Upper)数据集上训练模型,并在不同的数据集上对其进行评估。大胆和下划线分别表示最佳和第二好的结果。
5.2。定量结果指标。
指标。为了进行定量评估,我们在配对设置中使用SSIM [31]和LPIPS [36]。在不配对的环境中,我们使用FID [12]和KID [2]得分评估现实主义。我们遵循评估范式[20]进行实施[4,22]。
单个数据集评估。我们在单个数据集设置上评估了我们的StableVITON和现有基线,并在表1中报告结果。在未配对的设置(即FID和KID)中,StableVITON胜过所有基线。我们观察到,由于不可知映射的自动编码器的重建误差,配对设置中的性能降解发生。为了减轻此问题,我们适应了RePaint[18],该[18]采样了已知区域(即不可知映射),并在Dci-VTON中使用的推理过程中的每个denoising步骤中取代它。应用RePaint,StableVITON优于所有评估指标的基准。由于重新启动极大地有助于维持与服装无关的区域,因此在配对环境中表现出显着的性能提高。然而,即使没有重新paint,我们的方法在与基线相比,在未配对的环境中,在FID和KID方面都表现出了出色的表现。
交叉数据集评估。表2列出了我们的StableVITON显示了所有评估指标的最先进性能。基于GAN的方法无法保持背景一致性,从而导致高FID和KID得分明显。尽管基于扩散的方法表现出更好的性能,这是由于预先训练的扩散模型实现了合理的产生结果,但它们无法保留服装细节。因此,与我们的方法相比,它们在配对设置(即SSIM和LPIP)中表现出较低的相似性评分。
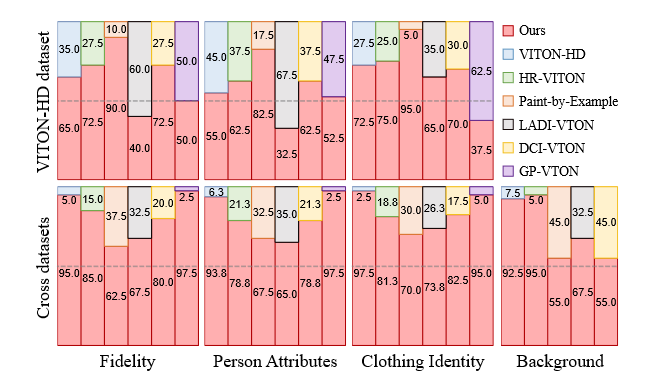
图8。用户研究结果。我们将StableITON与六个基线进行比较,涉及40名参与者。
5.3。用户研究
在VITON-HD数据集培训的模型的用户研究中,我们对40名参与者进行了用户研究。向每个参与者显示了一个由基线生成的图像,而则由我们的模型显示。他们被要求根据三个标准选择更好的图像:(1)保真度,(2)人属性,(3)服装身份。我们添加了一个问题关于交叉数据集设置的(4)背景质量。可以在补充材料中找到详细的问题。如图8所示,在大多数标准中,尤其是在交叉数据集设置中,StableVITON优于表现,我们的方法在人类评估中都令人震惊。尽管Ladi-VTON在Viton-HD数据集上对忠诚度和人属性的评估表现出更好的偏好,但它无法保留服装细节,从而导致服装身份标准偏爱35%。

图9。在两个不同的输入条件下我们的StableViton和ControlNets之间的比较:(1)衣服和(2)翘曲的衣服[15](ControlNet-W)。放大时最好查看。

图10。根据我们的培训组件进行视觉比较。放大时最好查看。

表3。我们的零交叉分节块和控制网之间的定量比较结果。我们用衣服和翘曲的衣服训练控制网[15](Controlnet-W)。我们将增强功能应用于培训中的所有模型。
5.4。消融研究与控制网的比较。为了证明Stableviton在解决对准问题方面的有效性[35],我们在两个不同的输入条件下训练ControlNet:(1)衣服和(2)翘曲的衣服[15](称为ControlNetNet-W)。在训练期间,我们将提议的扩展应用于这两种模型。使用翘曲网络对齐衣服有助于控制网络捕获粗糙的特征,例如徽标的整体形状和颜色,如图9(b)和(c)所示。但是,由于在训练阶段,扭曲的衣服和人体之间仍然存在不一致,因此ControlNet-W努力将更精细的服装细节反映给生成结果。这些观察结果表明,ControlNet对整个输入的微妙错位高度敏感,这是由于控制网络在调节中的直接添加操作的局限性。相比之下,如图9(d)所示,零跨注意区块,不受比对约束,成功保留了徽标和图案,并引导质量性能改善,如表3所示。
训练组件的效果。我们研究了训练过程中两个成分的效果:增强和注意力全变化损失。在图10中,我们在逐步引入所提出的训练组件时可视化生成的图像。与图10(a)和(b)相比,我们观察到应用增强时的详细特征,例如徽标和衣服的图案。但是,由于注意图没有足够的不同,我们观察到生成的图像中的不准确性,例如错误地描绘了“ puma”中的“ m”或模糊的线,如图10(b)所示。在我们提出的关注总变化损失方面进行了填充之后,这些细节得到了显着改善。如表4所示,这种视觉增强对应于定量性能的改进。
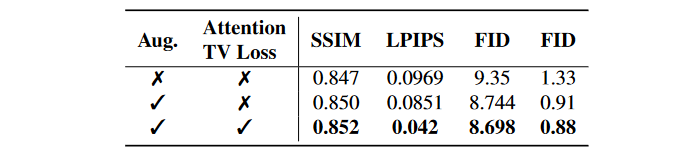
表4。我们在Viton-HD数据集上提出的培训组件的消融研究。
6.结论
我们提出了使用预训练的扩散模型的StableVITON,这是一种基于图像的新型虚拟Try-on方法。我们提出的零跨意见区块学习了衣服和人体之间的语义对应关系,从而在潜在特征空间中尝试了。新颖的关注总变化损失和增强旨在更好地保留服装细节。包括交叉数据集评估在内的广泛实验清楚地表明,与现有方法及其在现有方法中相比,StableVITON显示了最先进的性能。

















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









