









2245: [SDOI2011]工作安排
Time Limit: 20 Sec Memory Limit: 512 MB
Submit: 1356 Solved: 647
[Submit][Status][Discuss]
Description
你的公司接到了一批订单。订单要求你的公司提供n类产品,产品被编号为1~n,其中第i类产品共需要Ci件。公司共有m名员工,员工被编号为1~m员工能够制造的产品种类有所区别。一件产品必须完整地由一名员工制造,不可以由某名员工制造一部分配件后,再转交给另外一名员工继续进行制造。
我们用一个由0和1组成的m*n的矩阵A来描述每名员工能够制造哪些产品。矩阵的行和列分别被编号为1~m和1~n,Ai,j为1表示员工i能够制造产品j,为0表示员工i不能制造产品j。
如果公司分配了过多工作给一名员工,这名员工会变得不高兴。我们用愤怒值来描述某名员工的心情状态。愤怒值越高,表示这名员工心情越不爽,愤怒值越低,表示这名员工心情越愉快。员工的愤怒值与他被安排制造的产品数量存在某函数关系,鉴于员工们的承受能力不同,不同员工之间的函数关系也是有所区别的。
对于员工i,他的愤怒值与产品数量之间的函数是一个Si+1段的分段函数。当他制造第1~Ti,1件产品时,每件产品会使他的愤怒值增加Wi,1,当他制造第Ti,1+1~Ti,2件产品时,每件产品会使他的愤怒值增加Wi,2……为描述方便,设Ti,0=0,Ti,si+1=+∞,那么当他制造第Ti,j-1+1~Ti,j件产品时,每件产品会使他的愤怒值增加Wi,j, 1≤j≤Si+1。
你的任务是制定出一个产品的分配方案,使得订单条件被满足,并且所有员工的愤怒值之和最小。由于我们并不想使用Special Judge,也为了使选手有更多的时间研究其他两道题目,你只需要输出最小的愤怒值之和就可以了。
Input
第一行包含两个正整数m和n,分别表示员工数量和产品的种类数;
第二行包含n 个正整数,第i个正整数为Ci;
以下m行每行n 个整数描述矩阵A;
下面m个部分,第i部分描述员工i的愤怒值与产品数量的函数关系。每一部分由三行组成:第一行为一个非负整数Si,第二行包含Si个正整数,其中第j个正整数为Ti,j,如果Si=0那么输入将不会留空行(即这一部分只由两行组成)。第三行包含Si+1个正整数,其中第j个正整数为Wi,j。
Output
仅输出一个整数,表示最小的愤怒值之和。
Sample Input
2 3
2 2 2
1 1 0
0 0 1
1
2
1 10
1
2
1 6
Sample Output
24
HINT
Source
第一轮day2
题解:
做这个题的时候,用到了之前总结的方法,先暴力建图,然后进行简化
开始是这样想的:
源到各人连容量为inf,费用为0;
各人分成si+1份,每个人的主点连各分点,容量为t,费用为w;
每个分点根据a向各工作连边,容量为inf,费用为0;
每个工作连向汇,容量为c,费用为0
这样子建图,发现有很多多余点,可以优化,于是有了如下建图:
源向每个工作连流量c[i]的边,费用0
每个人向汇点连s[i]+1条边
流量t[i][j]-t[i][j-1],费用w[i][j]
然后工作和人根据A矩阵互相连边
这样点数和边数就小了,剩下的就是费用流了
code:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<queue>
using namespace std;
int read()
{
int x=0,f=1; char ch=getchar();
while (ch<'0' || ch>'9') {if (ch=='-') f=-1; ch=getchar();}
while (ch>='0' && ch<='9') {x=x*10+ch-'0'; ch=getchar();}
return x*f;
}
int n,m,S,T;long long ans=0;
int a[300][300],c[300];
struct data{int s,t[20],w[20];}ang[300];
struct dat{int to,next,cap,cost;}edge[500010];
int head[1010],cnt=1;
void add(int u,int v,int w,int c)
{
cnt++; edge[cnt].cap=w; edge[cnt].cost=c;
edge[cnt].to=v; edge[cnt].next=head[u]; head[u]=cnt;
}
void insert(int u,int v,int w,int c)
{
add(u,v,w,c); add(v,u,0,-c);
}
//add edge
bool mark[1010];int dis[1010];
#define inf 0x7fffffff
bool spfa()
{
queue<int>q;
memset(mark,0,sizeof(mark));
for (int i=S; i<=T; i++) dis[i]=inf;
q.push(T); dis[T]=0; mark[T]=1;
while (!q.empty())
{
int now=q.front(); q.pop();
for (int i=head[now]; i; i=edge[i].next)
if (edge[i^1].cap && dis[now]-edge[i].cost<dis[edge[i].to])
{
dis[edge[i].to]=dis[now]-edge[i].cost;
if (!mark[edge[i].to])
{
q.push(edge[i].to);
mark[edge[i].to]=1;
}
}
mark[now]=0;
}
return dis[S]!=inf;
}
int dfs(int loc,int low)
{
mark[loc]=1;
if (loc==T) return low;
int w,used=0;
for (int i=head[loc]; i; i=edge[i].next)
if (!mark[edge[i].to] && edge[i].cap && dis[edge[i].to]==dis[loc]-edge[i].cost)
{
w=dfs(edge[i].to,min(low-used,edge[i].cap));
used+=w; ans+=w*edge[i].cost;
edge[i].cap-=w; edge[i^1].cap+=w;
if (used==low) return low;
}
return used;
}
void zkw()
{
int tmp=0;
while (spfa())
{
mark[T]=1;
while (mark[T])
{
memset(mark,0,sizeof(mark));
tmp+=dfs(S,inf);
}
}
}
//Maxflow Mincost
void make()
{
S=0; T=1001;
for(int i=1; i<=n; i++)
insert(0,i,c[i],0);
for(int i=1; i<=m; i++)
for(int j=1; j<=n; j++)
if(a[i][j]) insert(j,n+i,inf,0);
for(int i=1; i<=m; i++)
for(int j=1; j<=ang[i].s+1; j++)
insert(n+i,T,ang[i].t[j]-ang[i].t[j-1],ang[i].w[j]);
}
//build
int main()
{
m=read(),n=read();
for (int i=1; i<=n; i++) c[i]=read();
for (int i=1; i<=m; i++)
for (int j=1; j<=n; j++)
a[i][j]=read();
for (int i=1; i<=m; i++)
{
ang[i].s=read();
for (int j=1; j<=ang[i].s; j++)
ang[i].t[j]=read();
ang[i].t[ang[i].s+1]=inf;
for (int j=1; j<=ang[i].s+1; j++)
ang[i].w[j]=read();
}
make(); zkw();
printf("%lld\n",ans);
return 0;
}
PS:
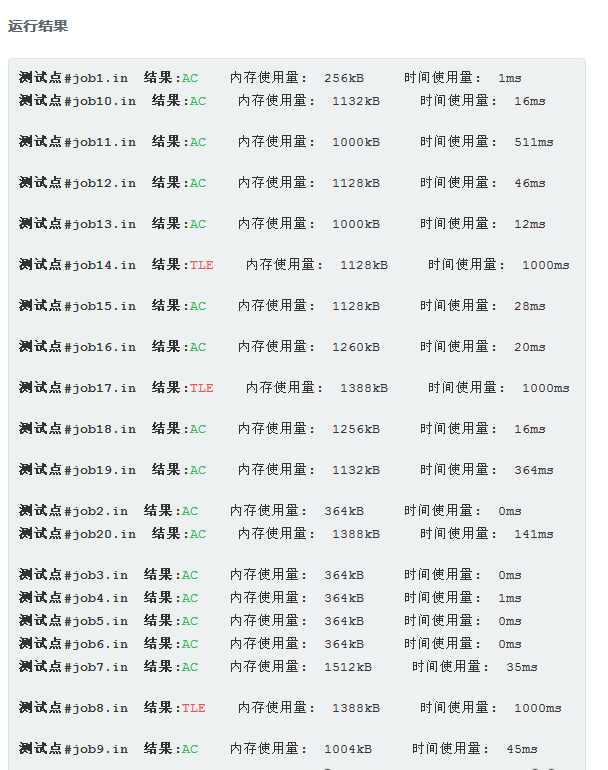
zkw费用流好像跑的很慢诶….
codevs上T3组,BZOJ上跑过,但总时间不快
















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









