






通过SAC-SMA模型模拟了区域的径流深数据,下一步需要进行参数率定,这里学习了一下如何通过模型运作输出的CSV文件,进行相关系数的计算与输出,pandas的操作应该是进行数据分析的基础。
import numpy as np
import pandas as pd
import csv
#以水文模型结果为例,这里xs为模型模拟的径流量,xo为水文站点的径流量
def R2(xs, xo)-> float: #判定系数
# 确定性系数
R = np.corrcoef(xs, xo)[0,1]
R2 = R ** 2 # Corelation coefficient
print("相关性系数平方R2为" + str(R2))
return R2
def DC(xs, xo) -> float: #纳什效率系数
x_mean = xo.mean()
SST = np.sum((xo - x_mean) ** 2)
SSRes = np.sum((xo - xs) ** 2)
DC = 1 - (SSRes / SST)
print("纳什效率系数为"+str(DC))
return DC
i = int(input()) #输入要从第几行开始处理数据,以便剔除前几行作为预热期
Site_file = pd.read_excel(r'H:\WaSSI-C\output\sac-sma\site_runoff.xlsx')#站点文件读取,可修改参数
Xo = Site_file.loc[i:,'runoff']
print('Xo输入站点观测月份数为%d'%len(Xo))
#读输出文件,记得查看预热期的数据是否有包含在XS和XO中
model_file = pd.read_csv(r'H:\WaSSI-C\output\sac-sma\runoffs_sync.csv')
Xs = model_file.loc[i:,'sum']
simulate_r2 = R2(Xs,Xo)
simulate_nasi = DC(Xs,Xo)
print(type(simulate_nasi))
#将判断系数写入csv文件中
with open(r"H:\WaSSI-C\output\sac-sma\R2_NSE.csv", "w", encoding="gbk", newline="") as f:
csv_writer = csv.writer(f)
# 3. 构建列表头
csv_writer.writerow(["R2", "NSE"])
# 4. 写入csv文件内容
csv_writer.writerow([simulate_r2, simulate_nasi])
print("写入数据成功")
# 5. 关闭文件
f.close()这里模型模拟结果可以以csv/excel等文件读取具体的形式参照以下:
XS和XO的shape必须数量一致
XS:模拟数据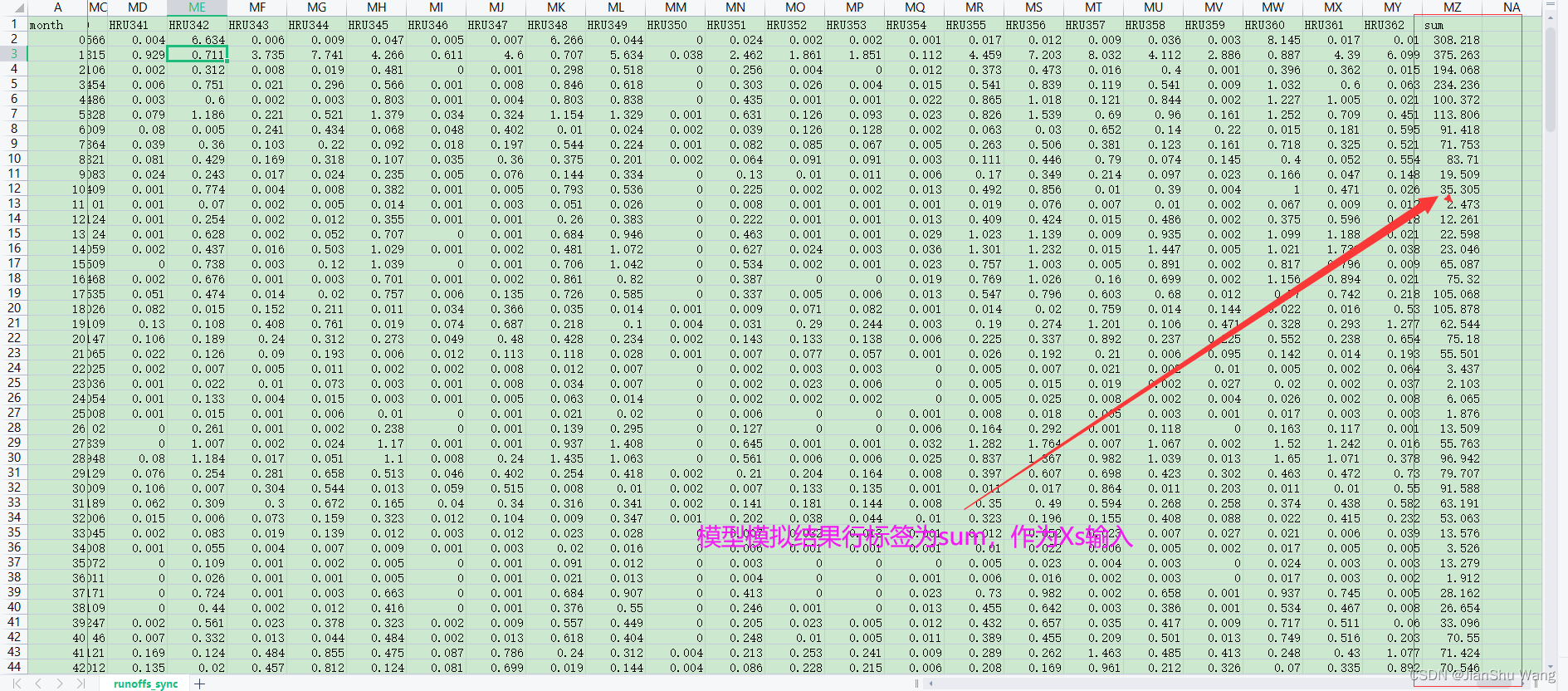
Xo:站点数据
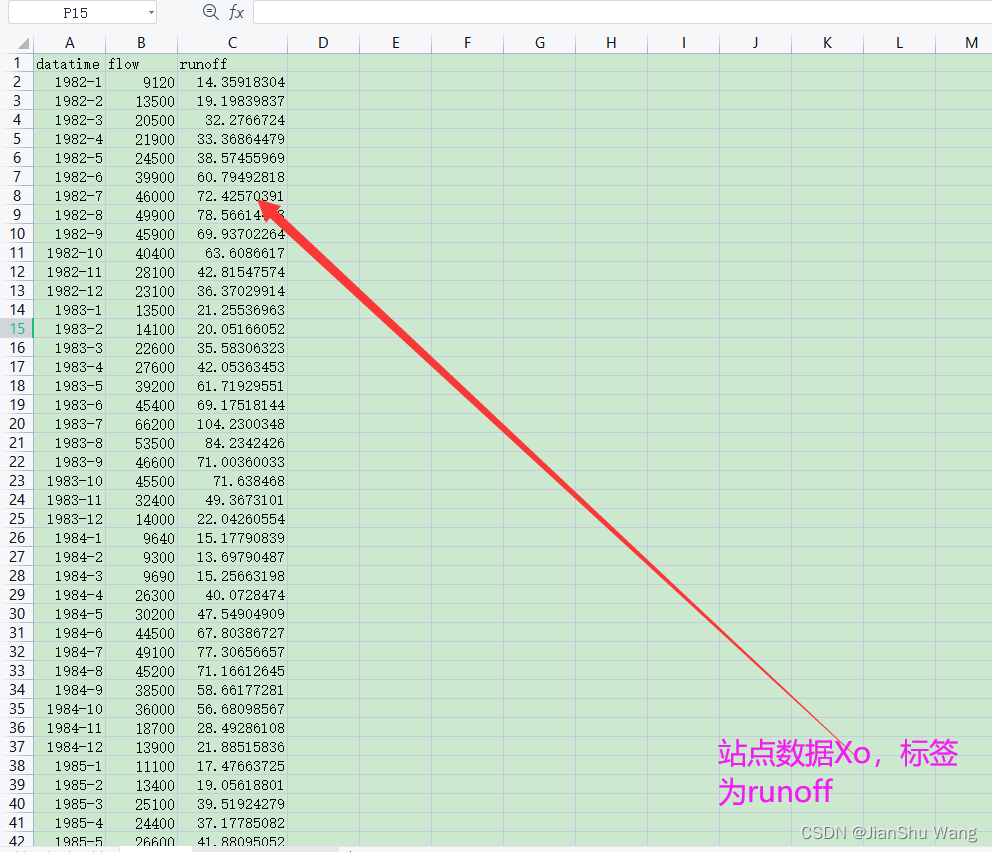
最终文件会以csv格式进行保存,可以用excel打开编辑与浏览
(请忽略模型参数还未调整好的模型运行得到的结果惨不忍睹OoO)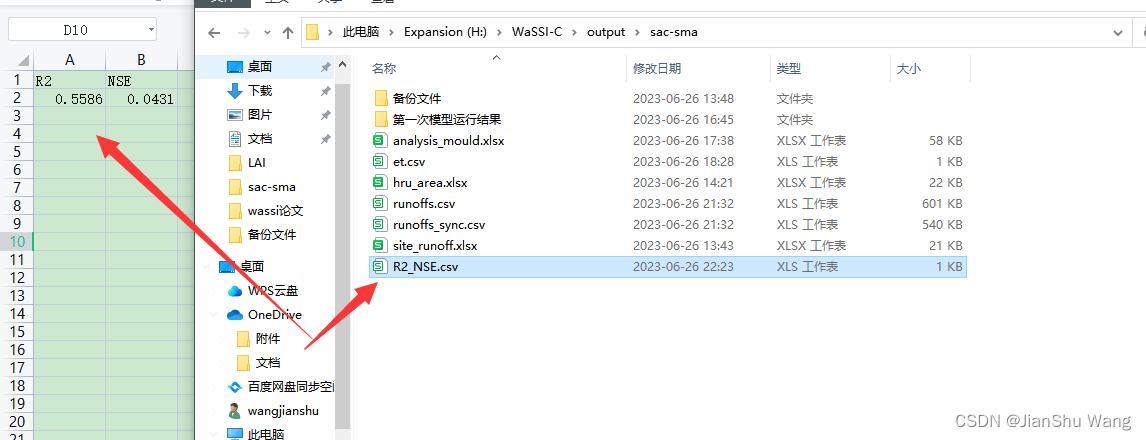
另外模型运行中直接使用pandas进行模型模拟结果(dataframe形式)进行读取,如下,也可以同样更快生成相关系数。
Xs = simulate_runoff.loc['sum',:]















 2424
2424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









