









我的个人博客:https://huaxuan0720.github.io/ ,欢迎访问
数据降维
在很多时候,我们收集的数据样本的维度很多,而且有些维度之间存在某一些联系,比如,当我们想要收集用户的消费情况时,用户的收入和用户的食物支出往往存在一些联系,收入越高往往食物的支出也越高(这里只是举个例子,不一定正确。)。那么在拿到这样的数据的时候,我们首先想到的就是我们需要对其中的信息做一些处理,排除掉一些冗余的维度,保留必要的维度信息。这样一来,我们可以大大减小我们的后期处理的工作量,这就是数据降维的基本要求。
主成分分析PCA
当拿到用户的数据时,如何确定到两个维度之间是否存在联系呢?这个就是我们需要用的协方差矩阵所作的工作。所以在使用PCA之前,我们必须对协方差有个简单的了解。
方差和协方差
我们之前遇到的大多数情况是获取到的都是一维的数据,比如数学课程的考试成绩,每个人都能获得一个分数,这些分数形成了一个一维的数组(向量),如果我们用
X
X
X 表示考试成绩的分布,然后我们可以估计出数学课程的考试成绩的均值
X
ˉ
\bar{X}
Xˉ 和方差
S
2
S^2
S2,如下:
(1)
X
ˉ
=
1
N
∑
i
=
1
N
X
i
\bar{X} = \frac{1}{N} \sum_{i = 1}^{N} X_i \tag{1}
Xˉ=N1i=1∑NXi(1)
(2) S 2 = 1 N − 1 ∑ i = 1 N ( X i − X ˉ ) 2 S^2 = \frac{1}{N - 1} \sum_{i = 1}^{N} (X_i - \bar{X}) ^2 \tag{2} S2=N−11i=1∑N(Xi−Xˉ)2(2)
需要注意的是在求解方差的时候,我们使用的分母是 N − 1 N- 1 N−1,而不是 N N N,这是因为我们以上的数学成绩对真实成绩分布的一次简单抽样,为了获得更为准确的关于原分布的方差估计,我们必须使用这种所谓的“无偏估计”。
以上都是关于单一变量的方差估计,通常,我们记单变量的方差为
v
a
r
(
X
)
var(X)
var(X),于是我们有:
(3)
v
a
r
(
X
)
=
S
2
=
1
N
−
1
∑
i
=
1
N
(
X
i
−
X
ˉ
)
2
var(X) = S^2 = \frac{1}{N - 1} \sum_{i = 1}^{N} (X_i - \bar{X}) ^2 \tag{3}
var(X)=S2=N−11i=1∑N(Xi−Xˉ)2(3)
但是考虑到更普遍的情况,我们不止有数学考试(X),我们还有物理考试(Y),英语考试(Z),我们就需要考虑一个问题,不同的考试的成绩之间是否存在某种联系,于是我们就利用协方差来定义两个随机变量之间的关系。现在我们有两个随机变量,
X
X
X 和
Y
Y
Y的抽样数据分布,我们将他们之间的协方差定义如下:
(4)
c
o
v
(
X
,
Y
)
=
1
N
−
1
∑
i
=
1
N
(
X
i
−
X
ˉ
)
(
Y
i
−
Y
ˉ
)
cov(X, Y) = \frac{1}{N - 1} \sum_{i = 1}^{N} (X_i - \bar{X})(Y_i - \bar{Y}) \tag{4}
cov(X,Y)=N−11i=1∑N(Xi−Xˉ)(Yi−Yˉ)(4)
很明显,这里的分母依然采用的是
N
−
1
N - 1
N−1,是对原分布的无偏估计。对于只有一个变量的情况,我们有:
(5)
c
o
v
(
X
,
X
)
=
1
N
−
1
∑
i
=
1
N
(
X
i
−
X
ˉ
)
(
X
i
−
X
ˉ
)
=
1
N
−
1
∑
i
=
1
N
(
X
i
−
X
ˉ
)
2
=
v
a
r
(
X
)
cov(X, X) = \frac{1}{N - 1} \sum_{i = 1}^{N} (X_i - \bar{X})(X_i - \bar{X}) = \frac{1}{N - 1} \sum_{i = 1}^{N} (X_i - \bar{X})^2 = var(X) \tag{5}
cov(X,X)=N−11i=1∑N(Xi−Xˉ)(Xi−Xˉ)=N−11i=1∑N(Xi−Xˉ)2=var(X)(5)
所以方差算是协方差的一个特例。协方差本质上是对两个随机变量的相关性的考察,当两个随机变量之间的协方差大于0时,表示这两个随机变量正相关;当两个随机变量之间的协方差等于0时,表示这两个随机变量没有相关关系;当两个随机变量之间的协方差小于0时,表示这两个随机变量负相关。
需要注意的是,两个随机变量相互独立和两个随机变量不相关是两个不同的概念,两个随机变量独立则一定有这两个随机变量不相关,但是两个随机变量不相关并不一定有这两个随机变量相互独立。
协方差矩阵
假设我们现在有一张数据统计的表格,每一列的数据都已经去中心化,即每一列的数据都已经减去了该列的均值。如下:
| No. | X 1 X_1 X1 | X 2 X_2 X2 | … | X m X_m Xm |
|---|---|---|---|---|
| 1 | a 11 a_{11} a11 | a 12 a_{12} a12 | … | a 1 m a_{1m} a1m |
| 2 | a 21 a_{21} a21 | a 22 a_{22} a22 | … | a 2 m a_{2m} a2m |
| … | … | … | … | … |
| n | a n 1 a_{n1} an1 | a n 2 a_{n2} an2 | … | a n m a_{nm} anm |
一共有
n
n
n 个样本数据,每个样本数据包括
m
m
m 个统计信息。对于每一列,都是一个随机变量的简单抽样,不妨我们将上面的矩阵记作
X
X
X,于是,我们有:
(6)
X
=
[
a
11
a
12
⋯
a
1
m
a
21
a
22
⋯
a
2
m
⋮
⋮
⋱
⋮
a
n
1
a
n
2
⋯
a
n
m
]
=
[
c
1
c
2
⋯
c
m
]
X = \begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1m} \\ a_{21} & a_{22} & \cdots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nm} \end{bmatrix} = \begin{bmatrix} c_{1} & c_{2} & \cdots & c_{m} \end{bmatrix} \tag{6}
X=⎣⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1ma2m⋮anm⎦⎥⎥⎥⎤=[c1c2⋯cm](6)
其中,
c
i
c_i
ci 表示的是每一个随机变量的取值分布情况,那么,第
i
i
i 个随机变量和第
j
j
j 个随机变量之间的协方差就可以表示为:
(7)
c
o
v
(
c
i
,
c
j
)
=
1
n
−
1
c
i
⋅
c
j
=
1
n
−
1
∑
k
=
1
n
a
k
i
a
k
j
cov(c_i, c_j) = \frac{1}{n-1} c_i \cdot c_j = \frac{1}{n - 1} \sum_{k = 1}^{n} a_{ki} a_{kj} \tag{7}
cov(ci,cj)=n−11ci⋅cj=n−11k=1∑nakiakj(7)
那么每两个随机变量之间的协方差矩阵(不妨叫做
C
o
v
M
a
t
r
i
x
CovMatrix
CovMatrix )可以表示如下:
(8)
C
o
v
M
a
t
r
i
x
=
[
c
o
v
(
c
1
,
c
1
)
c
o
v
(
c
1
,
c
2
)
⋯
c
o
v
(
c
1
,
c
m
)
c
o
v
(
c
2
,
c
1
)
c
o
v
(
c
2
,
c
2
)
⋯
c
o
v
(
c
2
,
c
m
)
⋮
⋮
⋱
⋮
c
o
v
(
c
m
,
c
1
)
c
o
v
(
c
m
,
c
2
)
⋯
c
o
v
(
c
m
,
c
m
)
]
=
[
1
n
−
1
∑
k
=
1
n
a
k
1
a
k
1
1
n
−
1
∑
k
=
1
n
a
k
1
a
k
2
⋯
1
n
−
1
∑
k
=
1
n
a
k
1
a
k
m
1
n
−
1
∑
k
=
1
n
a
k
2
a
k
1
1
n
−
1
∑
k
=
1
n
a
k
2
a
k
2
⋯
1
n
−
1
∑
k
=
1
n
a
k
2
a
k
m
⋮
⋮
⋱
⋮
1
n
−
1
∑
k
=
1
n
a
k
m
a
k
1
1
n
−
1
∑
k
=
1
n
a
k
m
a
k
2
⋯
1
n
−
1
∑
k
=
1
n
a
k
m
a
k
m
]
=
1
n
−
1
[
∑
k
=
1
n
a
k
1
a
k
1
∑
k
=
1
n
a
k
1
a
k
2
⋯
∑
k
=
1
n
a
k
1
a
k
m
∑
k
=
1
n
a
k
2
a
k
1
∑
k
=
1
n
a
k
2
a
k
2
⋯
∑
k
=
1
n
a
k
2
a
k
m
⋮
⋮
⋱
⋮
∑
k
=
1
n
a
k
m
a
k
1
∑
k
=
1
n
a
k
m
a
k
2
⋯
∑
k
=
1
n
a
k
m
a
k
m
]
=
1
n
−
1
[
a
11
a
21
⋯
a
n
1
a
12
a
22
⋯
a
n
2
⋮
⋮
⋱
⋮
a
1
m
a
2
m
⋯
a
n
m
]
[
a
11
a
12
⋯
a
1
m
a
21
a
22
⋯
a
2
m
⋮
⋮
⋱
⋮
a
n
1
a
n
2
⋯
a
n
m
]
=
1
n
−
1
X
T
X
\begin{aligned} CovMatrix &= \begin{bmatrix} cov(c_1, c_1) & cov(c_1, c_2) & \cdots & cov(c_1, c_m) \\ cov(c_2, c_1) & cov(c_2, c_2) & \cdots & cov(c_2, c_m) \\ \vdots & \vdots & \ddots & \vdots \\ cov(c_m, c_1) & cov(c_m, c_2) & \cdots & cov(c_m, c_m) \\ \end{bmatrix} \\ &= \begin{bmatrix} \frac{1}{n - 1} \sum_{k = 1}^{n} a_{k1} a_{k1} & \frac{1}{n - 1} \sum_{k = 1}^{n} a_{k1} a_{k2}& \cdots & \frac{1}{n - 1} \sum_{k = 1}^{n} a_{k1} a_{km} \\ \frac{1}{n - 1} \sum_{k = 1}^{n} a_{k2} a_{k1} & \frac{1}{n - 1} \sum_{k = 1}^{n} a_{k2} a_{k2}& \cdots & \frac{1}{n - 1} \sum_{k = 1}^{n} a_{k2} a_{km} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{1}{n - 1} \sum_{k = 1}^{n} a_{km} a_{k1} & \frac{1}{n - 1} \sum_{k = 1}^{n} a_{km} a_{k2}& \cdots & \frac{1}{n - 1} \sum_{k = 1}^{n} a_{km} a_{km} \\ \end{bmatrix} \\ &= \frac{1}{n - 1} \begin{bmatrix} \sum_{k = 1}^{n} a_{k1} a_{k1} & \sum_{k = 1}^{n} a_{k1} a_{k2}& \cdots & \sum_{k = 1}^{n} a_{k1} a_{km} \\ \sum_{k = 1}^{n} a_{k2} a_{k1} & \sum_{k = 1}^{n} a_{k2} a_{k2}& \cdots & \sum_{k = 1}^{n} a_{k2} a_{km} \\ \vdots & \vdots & \ddots & \vdots \\ \sum_{k = 1}^{n} a_{km} a_{k1} & \sum_{k = 1}^{n} a_{km} a_{k2}& \cdots & \sum_{k = 1}^{n} a_{km} a_{km} \\ \end{bmatrix} \\ &= \frac{1}{n - 1} \begin{bmatrix} a_{11} & a_{21} & \cdots & a_{n1} \\ a_{12} & a_{22} & \cdots & a_{n2} \\ \vdots & \vdots & \ddots & \vdots \\ a_{1m} & a_{2m} & \cdots & a_{nm} \\ \end{bmatrix} \begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1m} \\ a_{21} & a_{22} & \cdots & a_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nm} \\ \end{bmatrix} \\ &= \frac{1}{n - 1} X^T X \end{aligned} \tag{8}
CovMatrix=⎣⎢⎢⎢⎡cov(c1,c1)cov(c2,c1)⋮cov(cm,c1)cov(c1,c2)cov(c2,c2)⋮cov(cm,c2)⋯⋯⋱⋯cov(c1,cm)cov(c2,cm)⋮cov(cm,cm)⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡n−11∑k=1nak1ak1n−11∑k=1nak2ak1⋮n−11∑k=1nakmak1n−11∑k=1nak1ak2n−11∑k=1nak2ak2⋮n−11∑k=1nakmak2⋯⋯⋱⋯n−11∑k=1nak1akmn−11∑k=1nak2akm⋮n−11∑k=1nakmakm⎦⎥⎥⎥⎤=n−11⎣⎢⎢⎢⎡∑k=1nak1ak1∑k=1nak2ak1⋮∑k=1nakmak1∑k=1nak1ak2∑k=1nak2ak2⋮∑k=1nakmak2⋯⋯⋱⋯∑k=1nak1akm∑k=1nak2akm⋮∑k=1nakmakm⎦⎥⎥⎥⎤=n−11⎣⎢⎢⎢⎡a11a12⋮a1ma21a22⋮a2m⋯⋯⋱⋯an1an2⋮anm⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1ma2m⋮anm⎦⎥⎥⎥⎤=n−11XTX(8)
故,对于上述的矩阵
X
X
X ,我们可以求得它的协方差矩阵为:
(10)
C
o
v
M
a
t
r
i
x
=
1
n
−
1
X
T
X
CovMatrix = \frac{1}{n - 1} X^T X \tag{10}
CovMatrix=n−11XTX(10)
其中,
n
n
n 为样本数目,
X
T
X^T
XT 表示矩阵
X
X
X 的转置。
在处理表格时,我们已经先做了去中心化的操作,目的是使得协方差公式中的
X
ˉ
\bar{X}
Xˉ 为0,这样的话可以直接进行矩阵的相乘,不必在求解协方差的时候一个一个去计算。
特征值和特征向量
在很多时候,我们需要对一个矩阵求解它的特征值和特征向量,特征值和特征向量的定义是,对于一个对称方阵
A
A
A ,如果存在一个值
λ
\lambda
λ 和一个向量
x
x
x 满足如下的条件:
(11)
A
x
=
λ
x
Ax = \lambda x \tag{11}
Ax=λx(11)
那么我们就将
λ
\lambda
λ 称为该矩阵的特征值,对应的
x
x
x 则称之为特征向量。
根据线性代数的相关知识,我们可以知道,对于一个实对称矩阵
A
A
A,一定存在
n
n
n 个相正交的特征向量,其中
n
n
n 为该矩阵的行数(或者说列数)。那么如果我们将对称矩阵的特征值按照从大到小的顺序进行排列,同时,我们对特征向量也按照其对应特征值的大小进行排列,于是,我们有如下的排列:
λ
1
,
λ
2
,
⋯
 
,
λ
n
x
1
,
x
2
,
⋯
 
,
x
n
\lambda_1, \lambda_2, \cdots, \lambda_n \\ x_1, x_2, \cdots, x_n
λ1,λ2,⋯,λnx1,x2,⋯,xn
对于上面的每一对特征值和特征向量,我们都能满足等式(11)。于是,我们可以将所有的特征向量组合成一个矩阵,记作
W
W
W,将所有的特征值依次放入一个
n
n
n 阶的全零方阵的对角线元素中,记作
Σ
\Sigma
Σ,于是,我们可以获得下面的等式:
(12)
A
W
=
W
Σ
AW = W\Sigma \tag{12}
AW=WΣ(12)
在上面的式子右边同时乘以
W
−
1
W^{-1}
W−1 ,有:
(13)
A
=
W
Σ
W
−
1
A = W \Sigma W^{-1} \tag{13}
A=WΣW−1(13)
现在我们发现对于矩阵
W
W
W ,我们可以得到下面的式子:
(14)
W
W
T
=
E
W W^T = E \tag{14}
WWT=E(14)
有以上式子的原因是因为我们对所有的特征向量进行了规范化,使得所有的特征向量模长为1,而且由于
A
A
A是实对称矩阵,所以
A
A
A的特征向量两两正交,所以有以下的两个式子:
(15)
λ
i
⋅
λ
i
=
1
λ
i
⋅
λ
j
=
0
,
i
≠
j
\lambda_i \cdot \lambda_i = 1 \\ \lambda_i \cdot \lambda_j = 0, \quad i \ne j \tag{15}
λi⋅λi=1λi⋅λj=0,i̸=j(15)
由公式(14),我们就可以得到:
(16)
W
T
=
W
−
1
W^T = W^{-1} \tag{16}
WT=W−1(16)
故,我们重写式(13),有:
(17)
A
=
W
Σ
W
T
A = W \Sigma W^T \tag{17}
A=WΣWT(17)
需要注意的是,上述的公式需要满足的条件是
A
A
A是一个实对称方矩。
主成分分析
很明显,我们需要对原始的数据进行处理,我们希望是两个不同的数据维度之间的相关性越小越好,而同一个维度内部的方差越大越好,因为只有这样,我们才有很好的排除数据维度的相关性并进行数据的降维操作。我们这里设
Y
Y
Y是经过我们变换之后的数据矩阵,那么我们的要求就是
Y
Y
Y的协方差矩阵是一个对角矩阵,其中所有的非对角线上的元素都是0,而在对角线上的元素是可以为非0的。同时,我们可以设矩阵
P
P
P是一组线性变换的相互正交的单位基,按照列进行排列。那么对于原始的数据矩阵,我们可以有:
(18)
Y
=
X
P
Y = XP \tag{18}
Y=XP(18)
上面的式子表示的是
X
X
X矩阵映射到以矩阵
P
P
P为基的线性变换。我们假设原始数据
X
X
X的协方差矩阵为
B
B
B,经过变化之后的数据
Y
Y
Y的协方差矩阵为
D
D
D,那么我们可以有:
(19)
D
=
1
n
−
1
Y
T
Y
=
1
n
−
1
(
X
P
)
T
(
X
P
)
=
1
n
−
1
P
T
X
T
X
P
=
1
n
−
1
P
T
(
X
T
X
)
P
=
P
T
(
1
n
−
1
X
T
X
)
P
=
P
T
B
P
\begin{aligned} D &= \frac{1}{n - 1}Y^T Y \\ &= \frac{1}{n - 1}(XP)^T (XP) \\ &= \frac{1}{n - 1}P^T X^T XP \\ &=\frac{1}{n - 1}P^T (X^T X) P \\ &= P^T (\frac{1}{n - 1}X^T X) P \\ &= P^T B P \end{aligned} \tag{19}
D=n−11YTY=n−11(XP)T(XP)=n−11PTXTXP=n−11PT(XTX)P=PT(n−11XTX)P=PTBP(19)
从上面的式子中我们不难发现,我们需要找的是这样的一种变换,
D
D
D是一个对角矩阵,不妨这里假设对角矩阵
D
D
D的对角线上的元素是从大到小排列的,
B
B
B是原始数据矩阵的协方差矩阵,因此,我们需要的找到的变换
P
P
P可以将
B
B
B映射成对角矩阵
D
D
D。
此时,我们考虑到对于一个实对称矩阵
A
A
A,我们有
A
=
W
Σ
W
T
A = W \Sigma W^T
A=WΣWT,其中,
Σ
\Sigma
Σ是矩阵
A
A
A的特征值组成的对角矩阵,
W
W
W是矩阵
A
A
A的特征向量按照对应特征值的排列组成的特征向量矩阵,所以,结合上面的推导,我们不难发现,
D
D
D矩阵就可以对应于这里的
Σ
\Sigma
Σ矩阵,
W
W
W矩阵就可以对应于我们问题中的
P
P
P矩阵。
D
=
P
T
B
P
(
P
T
)
−
1
D
P
−
1
=
B
D = P^T B P \\ (P^T)^{-1}DP^{-1} = B \\
D=PTBP(PT)−1DP−1=B
考虑到
P
P
P矩阵是由一组正交单位基组成的,所以满足:
P
T
P
=
E
P^T P = E
PTP=E
所以有:
P
T
=
P
−
1
P^T = P^{-1}
PT=P−1
代入上面的式子,我们有:
(
P
T
)
−
1
D
P
−
1
=
P
D
P
T
=
B
(P^T)^{-1}DP^{-1} = P D P^T = B
(PT)−1DP−1=PDPT=B
我们可以发现,我们需要的变换矩阵
P
P
P就是由
B
B
B的特征向量组成的。因此,问题就转换成了求解
B
B
B的特征值和特征向量,而
B
B
B又是原始矩阵
X
X
X的协方差矩阵。
由于我们这里主要关心的是维度之间的相关性的大小,而且在后面的处理中,我们需要求解协方差矩阵的特征向量,所以我们可以将求解协方差矩阵的系数省略。 在后面的代码中,我们就直接省略了协方差矩阵的前系数,进一步简化了计算。
数据降维
在前面的式子中,我们并没有对数据的维度进行操作,即我们保留了所有的数据维度,但是并不是所有的数据维度都是足够必要的。由于矩阵的特征值往往会有比较大的差距,当我们求解出了原始数据的协方差矩阵的特征值和特征向量之后,我们可以舍弃掉太小的特征值以及对应的特征向量,这是因为特征值太小,转换之后的对应的数据维度的方差就会很小,也就是说该维度数据之间的差距不大,不能帮我们很好的区分数据之间的差别,舍弃之后也不会丢失太多的信息,舍弃之后反而可以减小数据的维度信息,更好的节省数据的占用空间,这对于一些大量数据的处理是十分有益的。
我们求出原始数据矩阵的协方差矩阵的特征值和特征向量之后,我们将特征向量进行从大到小进行排序,并按照特征值的顺序将特征向量进行排序。我们可以取前 K K K个特征值和特征向量,并将这些向量组合成一个变换矩阵。将这个变换矩阵应用到原始数据矩阵上即可对原始数据进行降维。这里的 K K K按照任务的要求可以有不同的取值。还有一种选取特征值的方法就是选取前 K K K个特征值,这些特征值之和占全部特征值之和的90%或者95%以上。
PCA实例
接下来就是一个PCA的实例,在sklearn的python包中,有一个鸢尾花数据集,包括了150组鸢尾花的数据,分为三类,每一组数据包含四个数据维度,我们的目标就是将这个数据集的数据维度减少到两维以便我们可以在二维平面上进行绘制。
这里使用了numpy自带的特征值和特征向量的求解函数,代码如下:
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import numpy as np
def load_data():
data = load_iris()
y = data.target
x = data.data
return x, y
def pca(x, dimensions=2):
x = np.array(x)
assert len(x.shape) == 2, "The data must have two dimensions."
# 求解协方差矩阵
matrix = np.matmul(np.transpose(x), x)
# 求解特征值和特征向量
values, vectors = np.linalg.eig(matrix)
# 按照从大到小的顺序给特征值排序
index = np.argsort(values)[::-1]
# 选取前几个特征值较大的特征向量,并组成一个变换矩阵
vectors = vectors[:, index[:dimensions]]
# 应用变换矩阵,将原始数据进行映射
x_dimension_reduction = np.matmul(x, vectors)
return x_dimension_reduction
def draw(x, y):
red_x, red_y = [], []
blue_x, blue_y = [], []
green_x, green_y = [], []
for i in range(len(x)):
if y[i] == 0:
red_x.append(x[i][0])
red_y.append(x[i][1])
elif y[i] == 1:
blue_x.append(x[i][0])
blue_y.append(x[i][1])
else:
green_x.append(x[i][0])
green_y.append(x[i][1])
plt.scatter(red_x, red_y, c='r', marker='x')
plt.scatter(blue_x, blue_y, c='b', marker='D')
plt.scatter(green_x, green_y, c='g', marker='.')
plt.show()
if __name__ == '__main__':
x, y = load_data()
# 去中心化
x = x - np.mean(x, 0)
x_dimension_reduction = pca(x, 2)
draw(x_dimension_reduction, y)
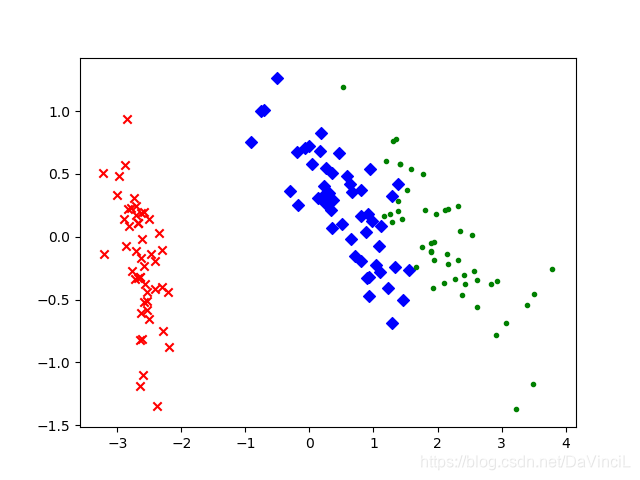
结果如下。可以看到,数据被较好地区分开了,其中一组数据已经完全和其他的两组数据脱离,另外两组数据也有了明显的分隔界限。这证明我们的PCA方法是正确的。














 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









