







续 使用Spring整合ES
为使用java代码为ES添加数据
在上次课内容的基础上添加以下数据
在测试类中运行即可代码如下:
@Resource
ItemRepository itemRepository;
@Test
void addItem(){
// Item item=new Item(1L,"华为Mate40","手机"
// ,"华为",4890.0,"/image/11.jpg");
// itemRepository.save(item);
List<Item> list=new ArrayList<>();
list.add(new Item(2L,"小米手机12","手机"
,"小米",4688.0,"/image/11.jpg"));
list.add(new Item(3L,"Vivo手机X40","手机"
,"Vivo",5266.0,"/image/11.jpg"));
list.add(new Item(4L,"小米手机ix3","手机"
,"小米",5655.0,"/image/11.jpg"));
list.add(new Item(5L,"华为P40","手机"
,"华为",4988.0,"/image/11.jpg"));
list.add(new Item(6L,"荣耀V10","手机"
,"荣耀",3280.0,"/image/11.jpg"));
itemRepository.saveAll(list);
}
运行完毕之后可以编写查询代码检测数据是否进入ES
从ES中查询所有数据,代码如下
@Test
void getById(){
//Object item=itemRepository.findById(1L);
Iterable<Item> items= itemRepository.findAll();
for (Item i: items) {
System.out.println(i);
}
//System.out.println(item);
}
实现全文搜索
我们向ES中添加数据不是为了全查的
ES的优势就是将指定的列生成索引库,然后使用分词形成关键字进行查询
这样的查询,我们就称为全文搜索
要实现全文搜索,并不需要之前我们编写的json格式的Http查询,因为我们加入的
Spring-data-elasticsearch依赖有着非常强大的功能
下面我们就来体验一下
springData的根据方法名自动生成查询过程
ItemRepository接口中添加如下方法
//SpringData自动生成实现的查询,我们只需要编写方法即可
//SpringData会根据约定好的方法名,推测要执行的内容
Iterable<Item> queryItemsByTitleMatches(String title);
测试代码如下
@Test
public void questTitle(){
Iterable<Item> items=
itemRepository.queryItemsByTitleMatches("华为");
for(Item i: items){
System.out.println(i);
}
}
上面的查询在ES中实际上执行了如下内容
### 单条件搜索
POST http://localhost:9200/items/_search
Content-Type: application/json
{
"query": {"match": { "title": "手机" }}
}
如果有多条件查询的需求
可以再ItemRepository接口中编写如下代码
这里查询title和brand两个条件
//按两个条件查询
Iterable<Item> queryItemsByTitleMatchesAndBrandMatches(
String title,String brand);
测试代码
@Test
public void questTitle(){
Iterable<Item> items=
itemRepository.
queryItemsByTitleMatchesAndBrandMatches(
"手机","小米");
for(Item i: items){
System.out.println(i);
}
}
ES内部实际执行的代码如下
### 多字段搜索
POST http://localhost:9200/items/_search
Content-Type: application/json
{
"query": {
"bool": {
"must": [
{ "match": { "title": "手机" }},
{ "match": { "brand": "小米"}}
]
}
}
}
如果想进行排序name就在方法最后添加排序规则即可
ItemRepository接口中编写如下代码
//按两个条件查询并按指定字段排序
Iterable<Item>
queryItemsByTitleMatchesAndBrandMatchesOrderByPriceDesc(
String title,String brand);
测试代码如下
@Test
public void questTitle(){
Iterable<Item> items=
itemRepository.
queryItemsByTitleMatchesAndBrandMatchesOrderByPriceDesc(
"手机","小米");
for(Item i: items){
System.out.println(i);
}
}
上面的测试相当于运行了ES代码如下
### 多字段搜索
POST http://localhost:9200/items/_search
Content-Type: application/json
{
"query": {
"bool": {
"should": [
{ "match": { "title": "手机" }},
{ "match": { "brand": "小米"}}
]
}
},"sort":[{"price":"desc"}]
}
上面查询已经涵盖了一般情况下数据库的类似操作
要显示问题列表就差分页功能了
要想实现分页功能,也异常简单
只需要在方法的最后一个参数中添加独特的类型即表示要实行分页查询
这个类型是Pageable
ItemRepository接口中编写如下代码
//实行分页查询
//返回值不再是Iterable而变为了Page
Page<Item>
queryItemsByTitleMatches(String title,Pageable pageable);
Pageable的全类名是:org.springframework.data.domain.Pageable;
测试代码如下
@Test
public void page(){
//设置分页对象
//PageRequest.of([从0开始为第一页的页码],[每页条数])
Pageable pageable=PageRequest.of(0,2);
Page<Item> page=itemRepository
.queryItemsByTitleMatches("手机",pageable);
//Page类和我们之前学习的PageInfo类似
//除了查询出的信息,还包含分页信息
//想从Page类中获得查询出的信息,需要调用getContent方法返回List
//所以遍历如下
List<Item> items=page.getContent();
for(Item i:items){
System.out.println(i);
}
//除此之外还可以输出Page类中包含的分页信息
System.out.println("总页数:"+page.getTotalPages());
System.out.println("每页条数:"+page.getSize());
System.out.println("是不是第一页:"+ page.isFirst());
System.out.println("是不是最后页:"+ page.isLast());
System.out.println("当前页:"+page.getNumber());
}
到此为止,ES相关的操作和Spring整合ES的操作就介绍到这
下面我们要开始在稻草项目中真正去使用ES
使用ES实现稻草问答的问题搜索功能
实现问题搜索的流程
- 先要将数据库中Question表中的数据,导入Es索引库中
- 查询时先根据用户输入的关键字进行查询
- 将查询结果显示在浏览器中问题列表的位置
- 再有新的问题发布并保存到数据库时,同时将这个问题保存到ES中
微服务架构的流程如下
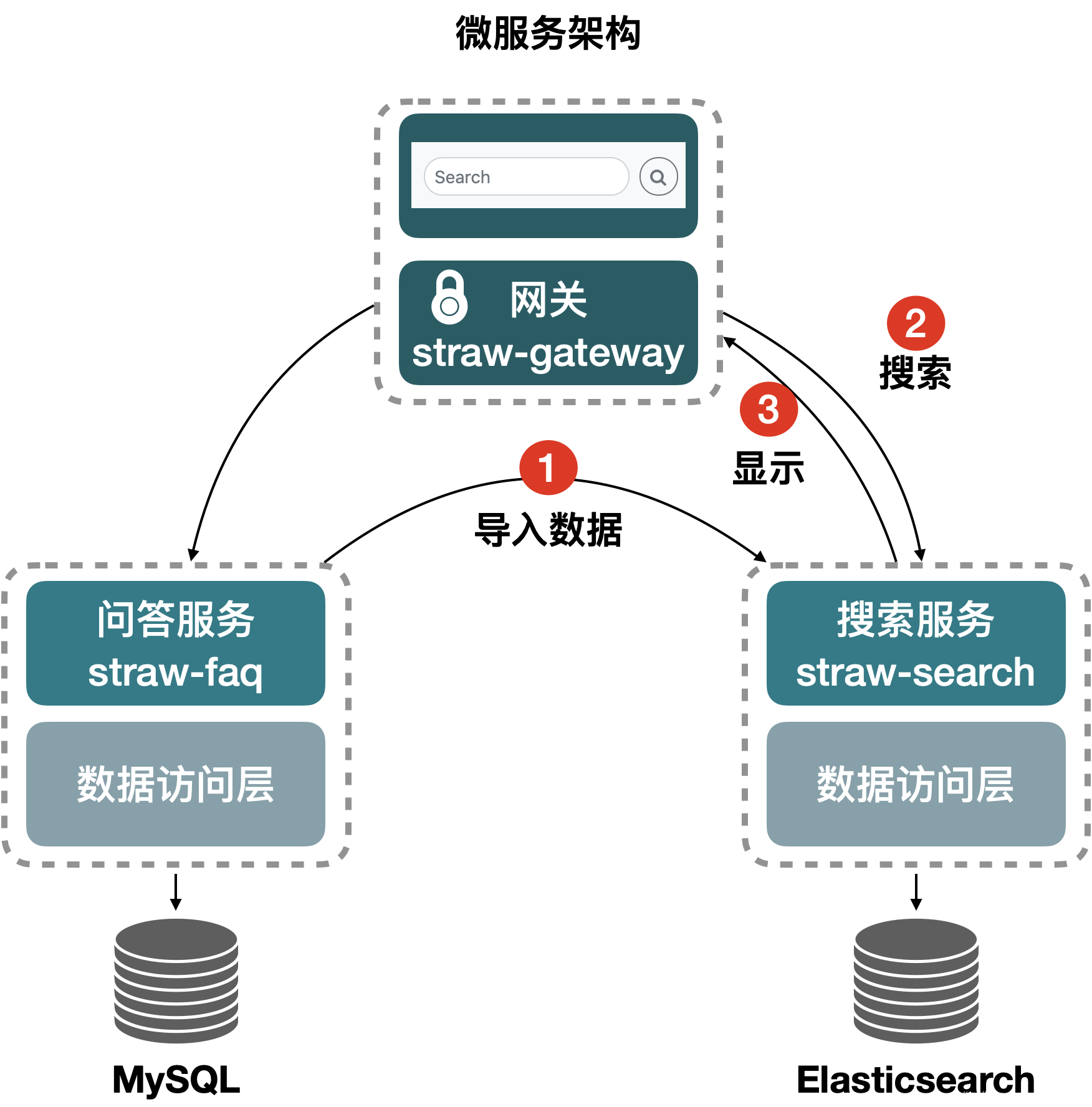
search模块开始
开始通用配置
pom.xml
<dependency>
<groupId>cn.tedu</groupId>
<artifactId>straw-commons</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
application.properties
spring.elasticsearch.rest.uris=http://localhost:9200
server.port=8066
logging.level.cn.tedu.straw.search=debug
# 设置ES内部的日志输出门槛
logging.level.org.elasticsearch.client.RestClient=debug;
spring.application.name=search-service
eureka.instance.prefer-ip-address=false
eureka.instance.hostname=localhost
eureka.instance.ip-address=127.0.0.1
eureka.instance.instance-id=${spring.application.name}:${eureka.instance.hostname}:${server.port}
主方法
@SpringBootApplication
@EnableEurekaClient
public class StrawSearchApplication {
public static void main(String[] args) {
SpringApplication.run(StrawSearchApplication.class, args);
}
}
将Question数据导入到ES
1.创建一个对应ES文档的QuestionVo实体类(值对象)
2.faq模块中提供查询Question的服务
3.search模块中调用faq提供的服务,得到所有Question
4.执行ES方法名添加到ES索引库
步骤1:
转到faq模块
IQuestionService中编写一个方法分页查询question
之所以也要分页,是因为大量数据不可能一次性全查询出来
//为ES分页查询所有问题的方法
PageInfo<Question> getQuestion(
Integer pageNum,Integer pageSize);
步骤2:
编写这个接口的实现
QuestionServiceImpl添加实现方法如下
@Override
public PageInfo<Question> getQuestion(
Integer pageNum, Integer pageSize) {
PageHelper.startPage(pageNum,pageSize);
List<Question> list=
questionMapper.selectList(null);
return new PageInfo<Question>(list);
}
可以测试…
@Resource
private IQuestionService questionService;
@Test
public void ques(){
PageInfo<Question> list=
questionService.getQuestion(1,10);
for(Question q:list.getList()){
System.out.println(q);
}
}
步骤3:
在faq模块的控制器层提供查询问题的Rest接口
QuestionController中编写调用上面测试的方法的代码
还有一个获得总页数的方法也要写出来
//search模块调用这个方法获得所有问题
@GetMapping("/page")
public List<Question> questions(
Integer pageNum,Integer pageSize){
PageInfo<Question> pageInfo=
questionService.getQuestion(pageNum,pageSize);
return pageInfo.getList();
}
//这个方法也是用于search调用的
//目的是返回按照指定每页的条数能查出多少页
@GetMapping("/page/count")
public Integer pageCount(Integer pageSize){
//count()方式是MybatisPlus自带的方法
Integer totalCount=questionService.count();
return totalCount%pageSize==0?totalCount/pageSize
:totalCount/pageSize+1;
//或
//return (totalCount+pageSize-1)/pageSize;
}
步骤4:
转到search模块!!
需要编写一个对应ES的Question的实体类
QuestionVo
代码如下
@Data
@Accessors(chain = true)
//为了防止ES中出现重复的数据,添加上EqualsAndHashCode方法
@EqualsAndHashCode(callSuper = false)
@Document(indexName = "questions")
public class QuestionVo implements Serializable {
private static final long serialVersionUID=1L;
public static final Integer POSTED=0;
public static final Integer SOLVING=1;
public static final Integer SOLVED=2;
@Id
private Integer id;
@Field(type = FieldType.Text,analyzer = "ik_smart",
searchAnalyzer = "ik_smart")
private String title;
@Field(type = FieldType.Text,analyzer = "ik_smart",
searchAnalyzer = "ik_smart")
private String content;
@Field(type = FieldType.Text,analyzer = "ik_smart",
searchAnalyzer = "ik_smart")
private String tagNames;
@Field(type = FieldType.Keyword)
private String userNickName;
@Field(type = FieldType.Integer)
private Integer userId;
@Field(type = FieldType.Integer)
private Integer status;
@Field(type = FieldType.Integer)
private Integer pageViews;
@Field(type = FieldType.Integer)
private Integer publicStatus;
@Field(type = FieldType.Integer)
private Integer deleteStatus;
@Field(type = FieldType.Date,
format = DateFormat.basic_date_time)
private LocalDateTime createtime;
@Field(type = FieldType.Date,
format = DateFormat.basic_date_time)
private LocalDateTime modifytime;
@Transient//临时的和ES无关
private List<Tag> tags;
}
步骤5:
创建Question对应的ES操作的接口
创建repository包
相当于对应数据库的Mapper接口
这里我们叫QuestionRepository接口
@Repository
public interface QuestionRepository extends
ElasticsearchRepository<QuestionVo,Integer> {
}
步骤6:
我们即将调用faq模块提供的服务,那么search模块应该设置支持RestTemplate的调用
打开主方法类,添加这个RestTemplate的注入
@SpringBootApplication
@EnableEurekaClient
public class StrawSearchApplication {
public static void main(String[] args) {
SpringApplication.run(StrawSearchApplication.class, args);
}
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
步骤7:
search创建业务逻辑层
创建IQuestionService接口在接口给中添加同步数据库到ES的方法
代码如下
public interface IQuestionService {
//同步数据库和ES的方法
//synchronized 的缩写
void sync();
}
步骤8:
开始实现业务
在service包下创建impl
并在impl下创建QuestionServiceImpl类实现上面的接口和方法
代码如下
@Service
@Slf4j
public class QuestionServiceImpl implements IQuestionService {
@Resource
QuestionRepository questionRepository;
@Resource
RestTemplate restTemplate;
@Override
public void sync() {
//先确定循环次数(确定数据一共有多少页)
String url=
"http://faq-service/v1/questions/page/count?pageSize={1}";
Integer page=restTemplate.getForObject(
url,Integer.class,10);
for(int i=1;i<=page;i++){
//循环调用分页查询Question的方法
url= "http://faq-service/v1/questions/page?" +
"pageNum={1}&pageSize={2}";
QuestionVo[] questions=restTemplate.getForObject(
url,QuestionVo[].class,i,10);
//增加到ES中
questionRepository.saveAll(Arrays.asList(questions));
log.debug("第{}页新增完毕",i);
}
}
}
步骤9:
最终要运行上面的方法才能执行同步过程
那么最好的方法就是通过测试类调用这个方法
所以这个虽然称为测试,但是必须执行
测试类中运行
@Resource
IQuestionService questionService;
@Test
public void go(){
questionService.sync();
}
需要注意新版数据库中modifytime列中有一个日期需要去掉
否则运行时会报错 2020-5-30 日期的问题
将所有modifytime列的值都设置为空
代码如下
UPDATE question SET modifytime=NULL
开发搜索功能业务层
Es中已经有了和数据库中一样的问题数据
现在需要使用Es进行高效的查询来让它起作用了
在这里插入图片描述
上面图中的英文含义
must:必须
should:应该
match:匹配(这里指内容匹配)
term:完全相等
bool:布尔类型,套在must\should外面
我们要执行的查询可以大概编写代码如下
### 条件搜索,查询用户12 或者 公开的 同时 标题或者内容中包含Java的问题
POST http://localhost:9200/questions/_search
Content-Type: application/json
{
"query": {
"bool": {
"must": [{
"bool": {
"should": [{"match": {"title": "java"}}, {"match": {"content": "java"}}]
}
}, {
"bool": {
"should": [{"term": {"publicStatus": 1}}, {"term": {"userId": 12}}]
}
}]
}
}
}
如果想看到查询结果需要满足下面条件
- 如果标题中包含java字样或者内容包含java字样
并且
- 题目的发布人是登录用户或题目本身是公开的
满足上面条件就查询出来
步骤1:
在QuestionRepository接口中声明上面条件的查询方法
查询的条件比较复杂,已经不能使用SpringData提供的使用方法名来表示的形式
所以要使用上面ES的查询语法来查询
代码如下
@Query("{\n" +
" \"bool\": {\n" +
" \"must\": [{\n" +
" \"bool\": {\n" +
" \"should\": [{\"match\": {\"title\": \"?0\"}}, {\"match\": {\"content\": \"?1\"}}]\n" +
" }\n" +
" }, {\n" +
" \"bool\": {\n" +
" \"should\": [{\"term\": {\"publicStatus\": 1}}, {\"term\": {\"userId\": ?2}}]\n" +
" }\n" +
" }]\n" +
" }\n" +
"}")
public Page<QuestionVo> queryAllByParams(String title,
String content, Integer userId, Pageable pageable);
步骤2:
上面的方法推荐测试一下
@Test
public void getQuery(){
Page<QuestionVo> page=questionRepository
.queryAllByParams("java","java",
11,PageRequest.of(0,5));
for(QuestionVo q: page.getContent()){
System.out.println(q);
}
}
步骤3:
因为现在QuestionRepository接口中方法返回的是Page类型
所以我们可能需要考虑html页面的兼容问题,html和vue一直处理的类型都是PageInfo
所以如果能够在业务逻辑层将Page类型转换成PageInfo类型,那么我们就减少了html和vue的工作量,非常值得这么做
我们现在需要写一个将Page类型转换成PageInfo类型的方法
新建一个类Pages
代码如下
public class Pages {
//将Page类型转换成PageInfo类型
public static <T> PageInfo<T> pageInfo(Page<T> page){
int pageNum=page.getNumber()+1;
int pageSize=page.getSize();
int totalPage=page.getTotalPages();
//当前页面实际大小
int size=page.getNumberOfElements();
//当前页的第一行,在数据库中的行号 行号从0开始
int startRow=page.getNumber()*pageSize;
//当前页的最后一样,在数据库中的行号 行号从0开始
int endRow=page.getNumber()*pageSize+size-1;
//查询总条数
long totalCount=page.getTotalElements();
PageInfo<T> pageInfo=new PageInfo<>(page.getContent());
pageInfo.setPageNum(pageNum);
pageInfo.setPageSize(pageSize);
pageInfo.setPages(totalPage);
pageInfo.setStartRow(startRow);
pageInfo.setEndRow(endRow);
pageInfo.setSize(size);
pageInfo.setTotal(totalCount);
//从新计算所有其他属性
pageInfo.calcByNavigatePages(PageInfo.DEFAULT_NAVIGATE_PAGES);
return pageInfo;
}
}














 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









