









大家好,从今天开始,我将定期写一些知识分享,把自己在前后端学习过程中觉得有用的知识点分享出来,大家可以关注学习,也欢迎大家和我一起讨论,有问题也可以问我,一定耐心解答,我的想法就是帮助别人不要再走自己踩过的坑。
代码视频链接: 戳这里瞅一瞅.
为什么是线程池
先思考一下,在哪些场景下会用到多线程:
- 阻塞调用(阻塞IO、等待资源、耗时操作)
- 耗时的计算(复杂的计算或者继续请求等操作)
- 高密度的任务(高并发,低延时场景)
总之就是需要耗时的操作,我们不能让进程阻塞在这里等待,就会采用多线程的做法。
搞清楚这点以后,我们又要想了,为什么要线程池啊,我去创建线程调用就是。
好,听我细细道来,这样做会有一些问题: - 创建线程如果较多,系统资源会被浪费,而且创建和销毁都是耗时操作,增加系统负担。
- 创建线程耗时就会导致响应慢,造成速度堪忧,体验差。
- 销毁线程耗时会影响到别的进程使用资源。
- 在越频繁的操作下,这么做会显得程序十分的繁忙。
所以说:我们才能想到,先创建好一些线程,然后不销毁,当有任务需要执行的时候就从这些线程中找出一个空闲的执行操作就好了。听起来就像,我是老板,雇了一批工人,然后让他们有条不紊的帮我干活。
这就是线程池的核心思想,把线程组建在一起构成线程池,然后当有任务的时候,就把任务丢给线程池干活,主线程继续接任务就好,不用干活。
那么我们又想了,主线程(生产者)接任务,线程池(消费者)处理任务。 - 我们如何让生产者和消费者同步,也就是怎么相互通知,这个意思就是大家总要相互联系,有活叫你干,干完告诉我,是这么一个逻辑。
- 任务怎么保存,因为可能生产太快,所以需要保存。
- 生产者之间的怎么同步,消费者之间怎么同步。
我们主要介绍的是单生产者多消费者模式,因为生产容易,干活难,就像老板一般就一个嘛,而员工有好多的嘛,哈哈哈,所以说你懂的。
同步的方式
我总说一句话,多线程主要解决同步问题,多进程解决通信问题,多线程的同步就是相互间通知,主要用条件变量(各线程间通知)+互斥锁(避免资源竞争导致出错)+任务队列(存储任务的)完成。
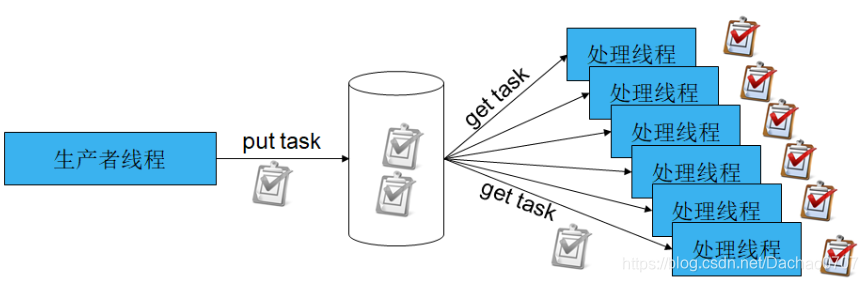
条件变量就是:消费者那边调用等这个条件满足就解阻塞的函数,生产者生产好了改变条件变量,消费者那边就会解阻塞,这就是生产者同步给消费者,对吧,我处理完了,改变条件变量告诉你好了,你可以干活了,消费者那边说我知道了,我干活了。这就是同步。
互斥锁在什么时候用:互斥锁就是,我要从任务队列里面去取任务的时候先锁起来,避免别的线程把任务先抢走了,这就是解决资源竞争的做法。
代码设计如下:
typedef struct queue_task
{
void* (*run)(void *);
void* argv;
}task_t;
typedef struct queue
{
int head;
int tail;
int size;
int capcity;
task_t* tasks;
} queue_t;
typedef struct async_queue
{
pthread_mutex_t mutex;
pthread_cond_t cond;
int waiting_threads;
queue_t* queue;
int quit; // 0 表示不退出 1 表示退出
/* 调试变量 */
long long tasked; // 已经处理完的任务数量
} async_queue_t;
//取任务
task_t* async_cond_queue_pop_head(async_queue_t* q, int timeout)
{
task_t *task = NULL;
struct timeval now;
struct timespec outtime;
pthread_mutex_lock(&(q->mutex));
if (queue_is_empty(q->queue))
{
q->waiting_threads++;
while (queue_is_empty(q->queue) && (q->quit == 0))
{
gettimeofday(&now, NULL);
if (now.tv_usec + timeout > 1000)
{
outtime.tv_sec = now.tv_sec + 1;
outtime.tv_nsec = ((now.tv_usec + timeout) % 1000) * 1000;
}
else
{
outtime.tv_sec = now.tv_sec;
outtime.tv_nsec = (now.tv_usec + timeout) * 1000;
}
pthread_cond_timedwait(&(q->cond), &(q->mutex), &outtime);
}
q->waiting_threads--;
}
task = queue_pop_head(q->queue);
/* 调试代码 */
if (task)
{
q->tasked ++;
static long long precision = 10;
if ((q->tasked % precision ) == 0)
{
time_t current_stm = get_current_timestamp();
precision *= 10;
}
}
pthread_mutex_unlock(&(q->mutex));
return task;
}
这里有一些不足的地方,说明一下:
- 因为Mutex引起线程挂起和唤醒的操作,在IO密集型的服务器上不是特别高效(实测过);
- 条件变量必须和互斥锁相结合使用,使用起来较麻烦;
- 条件变量不能像eventfd一样为I/O事件驱动。
- 管道可以和I/O复用很好的融合,但是管道比eventfd多用了一个文件描述符,而且管道内核还得给其管理的缓冲区,eventfd则不需要,因此eventfd比起管道要高效。
更高效的做法
所以用eventfd + epoll更加高效
队列设计:
typedef struct async_queue
{
queue_t* queue;
int quit; // 0 表示不退出 1 表示退出
int efd; //event fd,
int epollfd; // epoll fd
/* 调试变量 */
long long tasked; // 已经处理完的任务数量
} async_queue_t;
//插入任务
BOOL async_eventfd_queue_push_tail(async_queue_t* q, task_t *task)
{
unsigned long long i = 0xffffffff;
if (!queue_is_full(q->queue)){
queue_push_tail(q->queue, task);
struct epoll_event ev;
int efd = eventfd(0, EFD_CLOEXEC | EFD_NONBLOCK);
if (efd == -1) printf("eventfd create: %s", strerror(errno));
ev.events = EPOLLIN ;// | EPOLLLT;
ev.data.fd = efd;
if (epoll_ctl(q->epollfd, EPOLL_CTL_ADD, efd, &ev) == -1)
{
return NULL;
}
write(efd, &i, sizeof (i));
return TRUE;
}
return FALSE;
}
//取任务
task_t* async_eventfd_queue_pop_head(async_queue_t* q, int timeout)
{
unsigned long long i = 0;
struct epoll_event events[MAX_EVENTS];
int nfds = epoll_wait(q->epollfd, events, MAX_EVENTS, -1);
if (nfds == -1){
return NULL;
}
else
{
read(events[0].data.fd, &i, sizeof (i));
close(events[0].data.fd); // NOTE: need to close here
task_t* task = queue_pop_head(q->queue);
/* 调试代码 */
if (task){
q->tasked ++;
static long long precision = 10;
if ((q->tasked % precision ) == 0){
time_t current_stm = get_current_timestamp();
printf("%d tasks cost : %d\n", precision, current_stm - start_stm);
precision *= 10;
}
}
return task;
}
return NULL;
}
因为eventfd每次在写数据后,只会唤醒一个线程,所以确保了同一时刻只有一个线程取任务。
不足之处在于:上面两种做法都是公用一个方案的做法,所以取任务需要同步,用一个图描述就是:

更优秀的方案
eventfd + epoll + 多队列的设计,不拿出点东西,还真不行呢。
设计思想在这里:
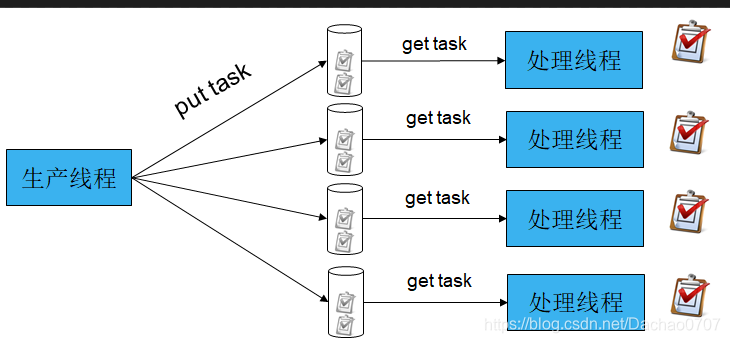
这样每一个线程就独立从一个队列中就取任务处理,非常通畅,他的感觉就是:
对了就是像立交桥一样有条不紊,这个代码是EasyDarwin的源码,但是因为某种原因,EasyDarwin的源码不再共享,我接触过ZeroMQ这个项目,大神Pieter Hintjens的一个观点,“真正的并发就是不共享资源”,太帅了。这种感觉就像每次经过十字路口,看见红绿灯,虽然它能让路口有条不紊,但是也经常出问题,最好的做法就是像立交桥一样,我们不共用资源,我曾想象,把所有的十字路口都做成立交桥一样的结构,要什么红绿灯,这样我们的世界都通畅了。

我会在视频中添加这一段代码的讲解,如果你能领悟其中的思想,想要更进一步,那么听听吧,可能我说的不好,但是肯定你让你学到点什么,我还是很有自信的。
干掉锁把
当我们在第三种方案上,增加了多队列,即每线程每队列时,实际上我们的队列设计变成了一个单生产者单消费者共享的队列,但是这个队列的写指针(tail)仅会被生产者使用,读指针(head)仅会被消费者使用,实际上没有共享任何资源,当然queue_t的size变量,我正在重构把它拿掉。
OK,那么在这种设计下,消费者线程如何“等待”如何“取”任务?
实际上,上面的三种方案对于消费者线程都是被动等待通知,收到通知则去取任务,实际上,我们完全可以设计成“轮询”的方案,就是不停地看自己的任务队列里是否有任务,没有就循环一次,中间当然可以加上sched_yield操作,让其它的线程能够得到调度。
线程池的尺寸
CPU密集型的:N为CPU核数
thread size = N + 1;
IO密集型的:
thread size = 2*N + 1;
当然这不是绝对的,甚至可以把线程池设计成可以动态调整尺寸的。














 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









