







朴素贝叶斯模型(naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。———统计学习方法(p47)
- 贝叶斯定理
- 特征条件独立假设
- 朴素贝叶斯算法
- 基于NB算法的大写字母识别实现
一.贝叶斯定理
在介绍贝叶斯公式之前,需要介绍几个基本的概念:条件概率,乘法公式,全概率公式。
1.条件概率:
定义:设A,B是随机试验E的两个随机事件,且P(B)>0,称

为在事件B发生的条件下,事件A发生的条件概率。
2.乘法公式:

3.全概率公式:

4.贝叶斯公式

“朴素”的条件独立假设:假设每个特征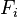 对于其他特征
对于其他特征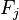 ,
,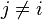 是条件独立的。这就意味着
是条件独立的。这就意味着

特征条件独立假设对于朴素贝叶斯算法是至关重要的,虽然该假设可能会损失了部分准确率,但是对于P(X=x|Y=Ck)的计算提供了很大的便利。
三.朴素贝叶斯算法
假设:所有的训练数据所属的类别为C,对于新的数据x的所属类y的计算公式如下:

所以,朴素贝叶斯的主要步骤是计算{}内的概率值,并去最大情况下的Ck。

由上述的公式推导,计算问题转换为计算以下两部分的数据:

第一部分称为:先验概率
第二部分称为:条件概率
四.基于NB算法的大写字母识别实现
</pre><pre name="code" class="java"></pre><pre name="code" class="java">import java.io.IOException;
public class TestMain {
public static void main(String args[]) throws IOException{
nb n = new nb("letter.txt","sum.txt");
n.initN();
System.out.println("准确度为: "+n.CalculateAccurate()*100+" %");
}
}
letter.txt 数据截图如下所示:

测试数据共19899行 每行数据有16个特征。测试数据100行 准确度 64%
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class nb {
class node implements Comparable<Object> {
public String label;
public int Dimension;
public int value;
node(String label, int Dimension, int value) {
this.label = label;
this.Dimension = Dimension;
this.value = value;
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
return label.hashCode() + Dimension * 1000 + value * 100;
// return super.hashCode();
}
@Override
public boolean equals(Object obj) {
if (compareTo(obj) == 1) {
return true;
}
else
return false;
}
@Override
public int compareTo(Object o) {
node node1 = (node) o;
if (this.label.equals(node1.label)
&& this.Dimension == node1.Dimension
&& this.value == node1.value)
return 1;
else
return -1;
}
}
public String trainDataFile;
public String testDataFile;
public static int TrainSampleCount = 0;
public static final double y = 1.0;
static Map<String, Integer> classCount = new HashMap<String, Integer>();
static List<String> labelList = new ArrayList<String>();
static Map<node, Integer> trainSample = new HashMap<node, Integer>();
nb(String trainDataFile, String testDataFile) {
this.trainDataFile = trainDataFile;
this.testDataFile = testDataFile;
}
void initN() throws IOException {
BufferedReader br = new BufferedReader(new FileReader(trainDataFile));
String line;
while ((line = br.readLine()) != null) {
String[] tokens = line.split("\\s+");
String label = tokens[0]; // 所属类别
for (int i = 1; i < tokens.length; i++) {
node n = new node(label, i, Integer.parseInt(tokens[i]));
if (trainSample.containsKey(n)) {
trainSample.put(n, trainSample.get(n) + 1);
}
else {
trainSample.put(n, 1);
}
}
if (classCount.containsKey(label))
classCount.put(label, classCount.get(label) + 1);
else {
classCount.put(label, 1);
labelList.add(label);
}
TrainSampleCount++; // 训练数据计数
}
}
double CalculateAccurate() throws IOException {
BufferedReader br = new BufferedReader(new FileReader(testDataFile));
int numCorrect = 0;
int TestSampleCount = 0;
String line;
while ((line = br.readLine()) != null) {
String[] tokens = line.split("\\s+");
String label = tokens[0];
int pixels[] = new int[tokens.length - 1];
String TestLabel = null;
for (int i = 1; i < tokens.length; i++)
pixels[i - 1] = Integer.parseInt(tokens[i]);
TestLabel = classify(pixels);
if (label.equals(TestLabel)) {
numCorrect++;
}
TestSampleCount++;
}
return (double) numCorrect / TestSampleCount;
}
String classify(int[] pixels) {
int kk = 0;
double tepSim = 0;
for (int k = 0; k < labelList.size(); k++) { // 对每一 个类别进行计算
String classLabel = labelList.get(k); // 类别
int countClassK = classCount.get(classLabel); // 该类训练数据个数
double pYk = ((double) countClassK) / TrainSampleCount; // 该类数据所占的比例
double Xix = 1.0;
for (int i = 0; i < pixels.length; i++) { // 每一维计算
node n = new node(labelList.get(k), i + 1, pixels[i]);
if (trainSample.containsKey(n)) {
int equlsPixelsOfI = trainSample.get(n);
double tep = ((double) (equlsPixelsOfI + y))
/ (countClassK + y);
Xix = Xix * tep;
} else {
Xix = Xix * (y / (countClassK + y));
}
}
Xix = Xix * pYk;
if (Xix > tepSim) {
kk = k;
tepSim = Xix;
}
}
return labelList.get(kk);
}
}















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









