







朴素贝叶斯是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定 的训练数据集,首先基于特征条件的独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出 y。
生成模型与判别模型
例如有C1以及C2两种类别,我们需要判断样本属于哪一个class:
判别式模型:要确定一个样本是属于C1还是C2,用判别模型的方法是从历史数据中学习到模型,然后通过提取该样本的特征来预测出该样本属于C1的概率以及C2的概率。
生成式模型:根据C1的特征首先学习出一个C1的模型,然后根据C2的特征学习出一个C2的模型,然后从该样本中提取特征,放到C1模型中看概率是多少,然后再放到C2模型中看概率是多少,哪个大就是哪个。
判别模型之所以称为判别模型,就是因为它只是简单地判别就好了。根据样本X来判别它所属的类别,直接就求出了p ( y ∣ x ) p(y|x)p(y∣x)的大小
而生成模型,在概率生成模型(Probabilistic Generative Model)与朴素贝叶斯(Naive Bayes)中我们可以看到,我们要求:

P(C1)与P(C2)很好求,我们要求的是P(x|C1)以及P(x|C2),也就是说我们要先求得C1与C2的具体分布,也就是上面说的,分别根据C1与C2的特征学得两个模型,得到模型之后代入,若P(C1|x)>P(C2|x)那x就属于C1,否则属于C2。
简述贝叶斯定理
公式如下;
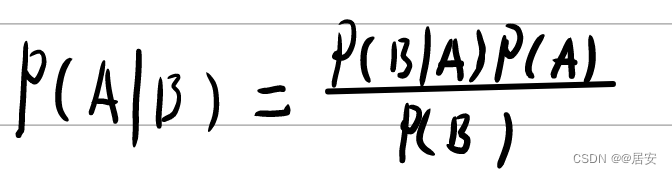
我们可以换个更贴切的描述;

P(A)是先验概率,表示每种类别分布的概率
P(A|B)是条件概率,表示在某种类别前提下,某事发生的概率;该条件概率可通过统计而得出
P(A|B)是后验概率,表示某事发生了,并且它属于某一类别的概率,有了这个后验概率,便可对样本进行分类。后验概率越大,说明某事物属于这个类别的可能性越大,便越有理由把它归到这个类别下。
朴素贝叶斯分类器
朴素贝叶斯法通过训练数据集学习联合概率分布 P ( X , Y ) P(X,Y)P(X,Y),其实就是学习先验概率分布和条件概率分布:
- 在之前的几个例子中,为了便于理解,当 B 作为 A 的条件出现时,我们假定它总共只有一个特征。
- 但在实际应用中,很少有一件事只受一个特征影响的情况,往往影响一件事的因素有多个。假设,影响 B 的因素有 n 个,分别是 b1,b2,…,bn。公式如下;
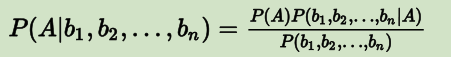
上面那些先验概率和条件概率如何得到呢?通过在训练样本中间做统计,就可以直接获得了!
对于我们的正类反类P(b1,b2,b3....)都是存在的我们可以计算的时候不用带入了。
极简单的朴素贝叶斯分类器
上式中的 b1 到 bn 是特征(Feature),而 A 则是最终的类别(Class),所以,我们换一个写法:
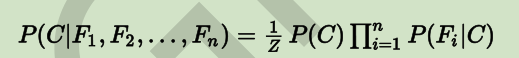
朴素贝叶斯分类的优缺点
优点:
算法逻辑简单,易于实现(算法思路很简单,只要使用贝叶斯公式转化一下即可!)
分类过程中时空开销小(假设特征相互独立,只会涉及到二维存储)
缺点:
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
后验概率最大化的含义
朴素贝叶斯法将实例分到后验概率最大的类中。这等价于期望风险最小化。
具体推导可以去查看李航大佬的统计学习方法。剩下的后面了补吧
















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











