






一、安装部署
1. 上传安装包至服务器目录
2. 解压tar -zxvf datax.tar.gz -C data/module/
3. 执行以下代码自检,出现以下图片说明成功
python bin/datax.py job/job.json
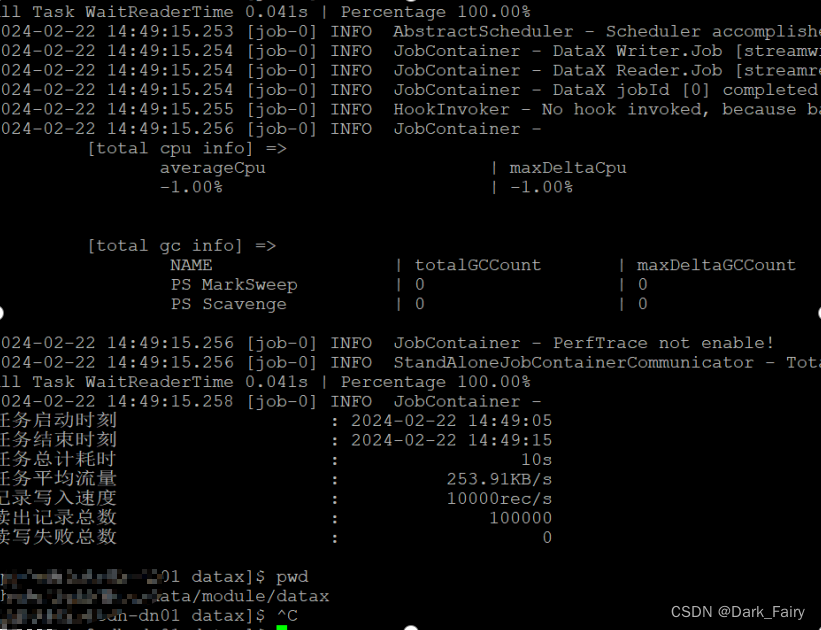
4. 查看DataX配置文件模板:按自己需要填写reader和writer
python bin/datax.py -r mysqlreader -w hdfswriter
5. 格式示例
{
"job": {
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:sqlserver://hadoop103:1433;DatabaseName=test"
],
"table": [
"t_info"
]
}
],
"password": "yH5nm57BSkFjmL8rBpRH",
"username": "sa",
"where": "datediff(day,startTime,getdate())=0",
"column": [
"id",
"order_date",
"purchaser",
"quantity",
"product_id"
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"order_date",
"purchaser",
"quantity",
"product_id"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/test?useUnicode=true&characterEncoding=utf-8",
"table": [
"t_info"
]
}
],
"password": "123321",
"preSql": [
"delete from t_info WHERE order_date = CURDATE();"
],
"session": [],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
二、生成json脚本
1. 生成单个datax 的json任务文件
1. 准备配置文件:datax.ini
将reader和writer的连接信息、需要同步的表、字段及其前置语句等写在配置文件中
vim datax.ini
; section名称
[sqlserver]
url = jdbc:sqlserver://hadoop103:1433;DatabaseName=test
username = sa
password = yH5nm57BSkFjmL8rBpRH
table = t_info
column = id,order_date,purchaser,quantity,product_id
where =
;key 只能是小写
[mysql]
url = jdbc:mysql://hadoop102:3306/test?useUnicode=true&characterEncoding=utf-8
username = root
password = 123321
table = t_info
column = id,order_date,purchaser,quantity,product_id
;preSql = delete from t_info WHERE order_date = CURDATE();
preSql =
writeMode = insert2. 使用python脚本,读取配置文件自动生成datax的json文件config.json
这个json文件即datax的job任务,可以直接运行同步数据
vim generate_json.py
import json
datax_json = {
"job": {
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"column": []
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
def get_config():
import configparser
file = 'prod\datax.ini'
con = configparser.ConfigParser()
con.read(file, encoding='utf-8-sig')
sections = con.sections()
# 获取特定section
items_sqlserver = con.items('sqlserver') # 返回结果为元组
config_sqlserver = dict(items_sqlserver)
items_mysql = con.items('mysql') # 返回结果为元组
config_mysql = dict(items_mysql)
# key 只能是小写
return {'config_sqlserver':config_sqlserver,'config_mysql':config_mysql}
if __name__ == '__main__':
config = get_config()
# sqlserver reader
datax_json['job']['content'][0]['reader']['parameter']['connection'][0]['jdbcUrl'].append(config['config_sqlserver']['url'])
datax_json['job']['content'][0]['reader']['parameter']['connection'][0]['table'].append(config['config_sqlserver']['table'])
datax_json['job']['content'][0]['reader']['parameter']['password'] = config['config_sqlserver']['password']
datax_json['job']['content'][0]['reader']['parameter']['username'] = config['config_sqlserver']['username']
datax_json['job']['content'][0]['reader']['parameter']['where'] = config['config_sqlserver']['where']
datax_json['job']['content'][0]['reader']['parameter']['column'] = list(config['config_sqlserver']['column'].split(','))
# mysql writer
datax_json['job']['content'][0]['writer']['parameter']['connection'][0]['jdbcUrl'] = config['config_mysql']['url']
datax_json['job']['content'][0]['writer']['parameter']['connection'][0]['table'].append(config['config_mysql']['table'])
datax_json['job']['content'][0]['writer']['parameter']['password'] = config['config_mysql']['password']
datax_json['job']['content'][0]['writer']['parameter']['username'] = config['config_mysql']['username']
datax_json['job']['content'][0]['writer']['parameter']['preSql'].append(config['config_mysql']['presql']) # 配置里面key只能识别为小写
datax_json['job']['content'][0]['writer']['parameter']['writeMode'] = config['config_mysql']['writemode']# 配置里面key只能识别为小写
datax_json['job']['content'][0]['writer']['parameter']['column'] = list(config['config_mysql']['column'].split(','))
with open ('prod\config.json', 'w') as f:
f.write(json.dumps(datax_json))
print(datax_json)
3. 按照步骤2生成的json文件如下所示:
{
"job": {
"content": [{
"reader": {
"name": "sqlserverreader",
"parameter": {
"connection": [{
"jdbcUrl": ["jdbc:sqlserver://hadoop103:1433;DatabaseName=test"],
"table": ["t_info"]
}],
"password": "yH5nm57BSkFjmL8rBpRH",
"username": "sa",
"column": ["id", "order_date", "purchaser", "quantity", "product_id"],
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["id", "order_date", "purchaser", "quantity", "product_id"],
"connection": [{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/test?useUnicode=true&characterEncoding=utf-8",
"table": ["t_info"]
}],
"password": "123321",
"preSql": [""],
"session": [],
"username": "root",
"writeMode": "insert"
}
}
}],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
4. 将3中的json文件放在服务器运行
将json文件放在datax的job目录下,命名为:sqlserver2mysql.json,然后执行以下命令:
python /data/module/datax/bin/datax.py --jvm="-Xms8G -Xmx8G" /data/module/datax/job/sqlserver2mysql.json
确认没有报错即证明脚本没有问题,可以继续编写批量生成脚本。
2. 批量生成datax的json任务文件
1. 首先需要批量生成配置文件:datax.ini
分析:其中连接信息一般不会改变,但是库、表可能有所变化,所以需要灵活变动的是以下信息
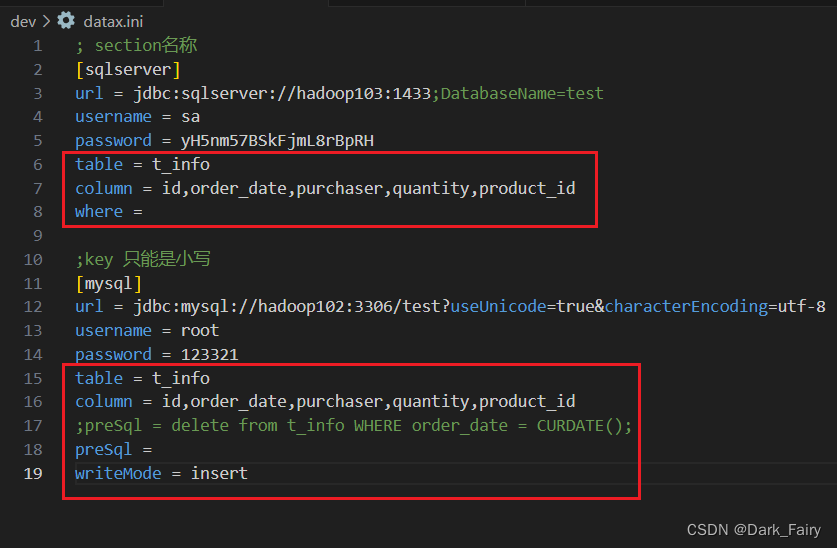
表名可按需填写,字段名
vim generate_ini.py
待完成......
三、批量执行json job任务
1. 安装服务:yum install crontabs (一般自带)
2. crontab服务操作
- 启动 service crond start
- 关闭 service crond stop
- 重启service crond restart
- 重载配置 service crond reload
- 查看状态 service crond status
- 列出定时文件:crontab -l
3. 列出定时文件
若crontab -l 显示:

以上表明从未创建过定时任务,需要创建定时文件,但如果已有定时文件,则修改或增加定时任务即可。
4. 创建定时文件
创建定时任务,并将日志写入/data/module/datax/crontab_logs/目录
vim crontabdatax
0 1 * * * python /data/module/datax/bin/datax.py /data/module/datax/job/sqlserver2mysql.json >> /data/module/datax/crontab_logs/log.`date +\%Y\%m\%d\%H\%M\%S` 2>&1
表示每天凌晨1点执行这个任务
四、附达梦 datax reader 示例
{
"job": {
"content": [
{
"reader": {
"name": "rdbmsreader",
"parameter": {
"column": ["SENID","TS"],
"connection": [
{
"jdbcUrl": ["jdbc:dm://hadoop102:5236?schema=SYSDBA"],
"table": ["RTSQ"]
}
],
"password": "dm123321",
"username": "dm",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["senid","ts"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/test?useUnicode=true&characterEncoding=utf-8",
"table": ["ods_rtsq"]
}
],
"password": "123321",
"preSql": [""],
"session": [],
"username": "root",
"writeMode": "update"
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}















 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









