






一、场景:
数据中台基于hadoop构建了ODS,DWD,DIM,DWS,ADS五层数仓模型,有实时任务和离线任务。数据类型包括结构化数据、非结构化数据,最后形成的ADS层指标数据写入mysql指标数据库,由于业务原因需要将mysql进行迁移,以下涉及的迁移是指涉及指标数据库mysql的迁移。
二、前提条件
确保数据中台集群与新mysql 的连通性:
telnet 数据库IP 3306
三、具体步骤
1. 批量工具同步库表结构及其历史数据
选择时间进行历史数据迁移(如2023-12-10 12:00:00 A时点)
1.1 旧数据库所有表结构及历史数据导出:
mysqldump -h 旧数据库IP -u用户名 -p密码 -A > /data/all.sql (导出路径)1.2 all.sql复制到新数据库所在服务器中,在新数据库执行:
source /路径/all.sql2. MySQL在中台的相关任务迁移(B时点)
2.1 离线任务
修改ADS层每个任务的输出配置为新mysql的新表,若为统一配置,只需修改一次配置即可,更新任务。
注意:任务迁移完成后需手动执行一次观察效果,查看数据是否写入到新表中,测试完成为避免数据重复需将表清空
2.2 实时任务
场景:kafka集群需换成另一个kafka集群,IP 地址有变化
任务链路:kafka->写入mysql
- 先在目标mysql创建对应表(第一步已完成则无需手动再创建)
- 在新kafka集群创建相同名称的topic,并测试写入数据是否正常
- 修改实时任务配置的kafka IP地址,并联合2测试改实时任务是否正常写入新mysql表
- 确认无误将mysql中测试数据删除即可,实时任务无需变更
注意:需要通知原kafka集群的所有生产者和消费者更改kafka IP配置
3. A-B时间段内任务新增数据手动迁移
3.1 对于离线任务
只要当天完成则无新增数据,无需处理。若确实有新增数据,手动执行离线任务即可。
3.2 对于实时任务
可以根据数据入库时间(需要表中有该字段)过滤出新数据,同步至新数据库。
3.3 如有需要,批量手动同步某表任务(数据量较大时)
以下命令场景是我将历史数据写入到新数据库中的临时表中,而实时任务写入的mysql表已经更改为正式表,由于此表数据量较大,使用load data命令将临时表的历史数据批量同步至正式表,虽然两张表都在新数据库,可以使用insert select 命令导入,但由于数据量较大,执行效率低,容易超时失败,所以使用load命令更高效。
注意:使用这个命令要确保导入导出的文件在secure-file-priv 变量指定的路径下,否则会报错。使用以下命令查看此安全路径。
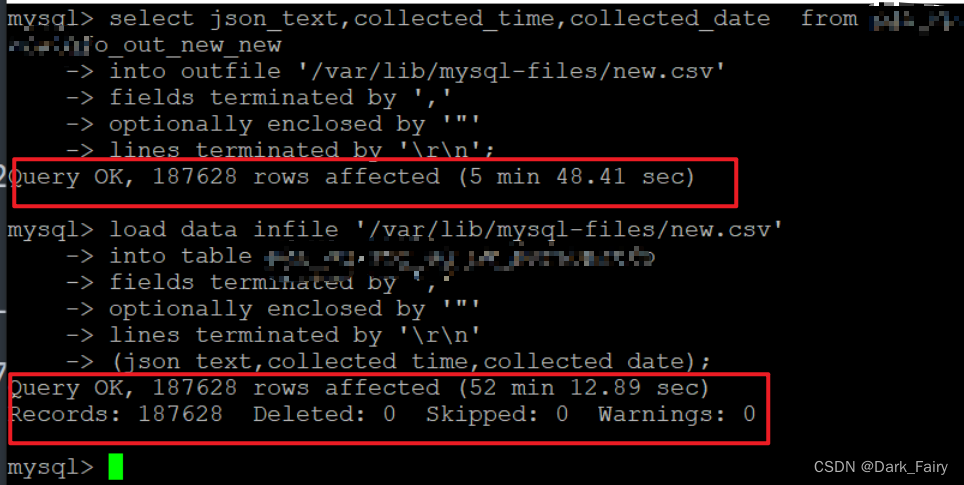
show variables like '%secure%'; a 导出临时表数据
select json_text,collected_time,collected_date -- 插入指定字段,全选可以写*
from 临时表
into outfile '/var/lib/mysql-files/new.csv'
fields terminated by ','
optionally enclosed by '"'
lines terminated by '\r\n';b 导入到正式表
load data infile '/var/lib/mysql-files/new.csv'
into table 正式表
fields terminated by ','
optionally enclosed by '"'
lines terminated by '\r\n'
(json_text,collected_time,collected_date); -- 插入指定字段,全选可以不写这一行执行效率可看下图:
近19万条数据,数据大小24G,导出用时接近6min,导入正式表用时52min。















 1265
1265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









