








目录
我正在参加我的编程语言学习笔记,欢迎大家学习
| Python 基础 (一)Python基本认识与环境搭建 | Python 基础 (一)Python基本认识与环境搭建 |
|---|---|
| Python 基础 (二)Python变量与基本数据类型 | Python 基础 (二)Python变量与基本数据类型 |
| Python 基础 (三)Python基本语句与基本运算 | Python 基础 (三)Python基本语句与基本运算 |
| Python 基础 (四)Python函数 | Python 基础 (四)Python函数 |
| Python 基础 (五)Python包与模块 | Python 基础 (五)Python包与模块 |
| Python 基础 (六)Python的文件模块 | Python 基础 (六)Python的文件模块 |
| Python 基础 (七)Python的异常处理机制 | Python 基础 (七)Python的异常处理机制 |
| Python 基础 (八)Python的类与对象 | Python 基础 (八)Python的类与对象 |
| Python 基础 (九)Python的内置模块 | Python 基础 (九)Python的内置模块 |
| Python 基础 (十)Python实现简单的图书管理系统 | Python 基础 (十)Python实现简单的图书管理系统 |

- 官网:
一 Python 基本信息了解
1.1 Python
Python它是一种直译式,面向对象,解释式的脚本语言。它和Java,C/C++,Go语言一样都是高级语言,但由于它是解释式语言,所以运行速度会比Java,C/C++等语言慢(虽说隔壁Go也是解释式语言,但比它快很多)。不过任何事物有利也有弊,Python因为自身携带了许多库(如:OS、TCP、Urllib、Trutle),语法简单,第三库也有很多(如飞机大战所需的pygame),所以被称为胶水语言,同时也深受开发者青眯。
1.2 应用方面
基本全能,例如:系统运维、图形处理、数学处理、文本处理、数据库编程、网络编程、web编程、多媒体应用、pymo引擎、黑客编程、爬虫编写、机器学习、人工智能等。
主要方面:人工智能,大数据,自动化运维,自动化测试等等
1.3 排名
参考网站:https://pypl.github.io/PYPL.html

1.4 python之父
Python之父:Guido van Rossum,荷兰人。他也是一个比较传奇的人物,1982年 在阿姆斯特丹大学获得计算机和数学科学硕士学位 ,1989年制作Python,1995年Guido van Rossum从荷兰移民到美国,2005年在Google工作,并用Python发明了面向网页的代码浏览工具Mondrian,之后又开发了Rietveld。现在在Dropbox工作。
1.5 优缺点
- 优点:免费开源、无社区限制、可开发应用面广、可跨平台、功能强大、自身携带模块多、第三方模块多、语法简单,代码量少可实现多功能等
- 缺点:运行速度远比C/C++等语言要
1.6 Python学习路线
这里可以根据自己的兴趣进行选择

二 Python基本环境安装
2.1 Python 编译器安装
注意:我这是window安装,学习环境
下载地址:https://www.python.org/ftp/python/3.11.5/python-3.11.5-amd64.exe
无脑安装,一直下一步,直到安装完成,当然我们要验证安装
pyhton

2.2 Pycharm安装
下载地址:https://www.jetbrains.com/pycharm/
这里有社区版和企业版可以根据自己需要进行选择,我这里是企业版

2.3 插件推荐
2.4 第一个程序

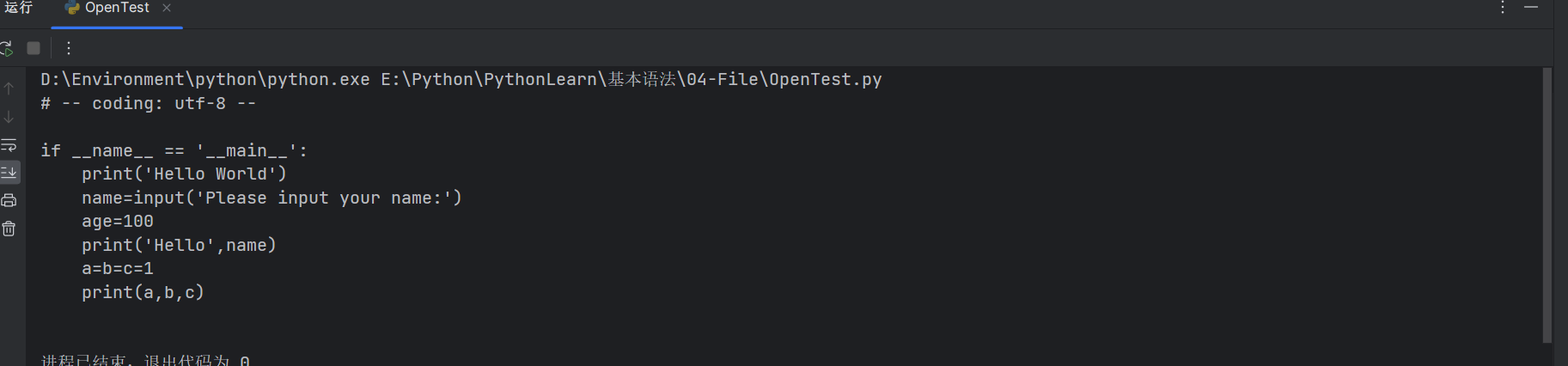
# -- coding: utf-8 --
if __name__ == '__main__':
print('Hello World')
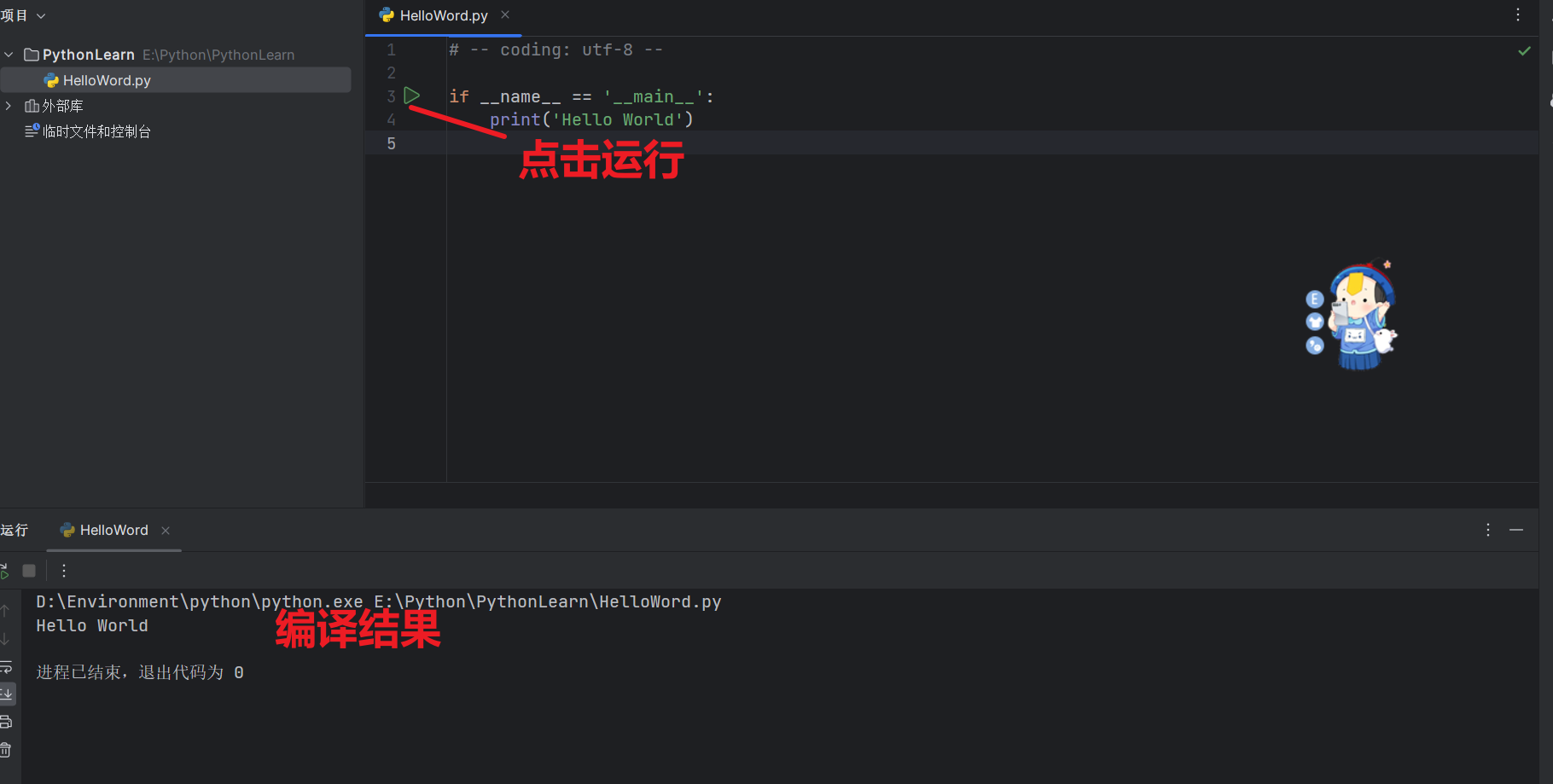
到这我们的第一个程序写好了,是不是十分简单,我们来解释一下程序的第一行:编码
目的是介绍在一个Python源文件中如何声明编码的语法,随后Python解释器会在解释文件的时候用到这些编码信息,最显著的是源文件中对Unicode的解释,使得在一个能识别Unicode的编辑器中使用如FUT-8编码成为可能,当我也推荐在Pycharm中配置
# ---encoding:utf-8---
# @Time : ${DATE} ${HOUR}:${MINUTE}
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : ${SITE}
# @File : ${NAME}.py
当你新建文件是会自定进行声明,效果如下图

三 Python 基本规则认识
3.1标识符(取一个名字)
标识符是编程时使用的名字,用于给变量、函数、语句块等命名,Python 中标识符由字母、数字、下划线组成,不能以数字开头,区分大小写,当然你不用多记,在开发编译器中会自动提示
正常:person,username,age,错误:011a
3.2关键字(Python已经使用)
| and | exec | not | assert | finally | or |
|---|---|---|---|---|---|
| break | for | pass | class | from | |
| continue | global | raise | def | if | return |
| del | import | try | elif | in | while |
| else | is | with | except | lambda | yield |
由于Python已经使用我们不能把他作为标识符
3.3 注释 (进行我们的想法描述)
- Python 中单行注释使用 #,多行注释使用三个单引号(‘’')或三个双引号(“”")
# ---encoding:utf-8---
# @Time : 2023/9/1 20:47
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site :
# @File : __init__.py.py
# 我是单行注释
'''
我是多行注释
我是多行注释
'''
"""
我是多行注释
我是多行注释
"""
- 注释单行
(1)方法1:直接在单行代码前边加 #
(2)方法2:选中需要注释的代码,Ctrl+/ 即可注释
- 注释多行代码
选中想要注释的N行代码,直接Ctrl+/ 即可注释
- 取消注释多行代码
选中想要取消注释的N行代码,直接Ctrl+/ 即可注释
小贴士:使用快捷键Ctrl+/时,无论是中文还是英文输入法,都能实现快速注释。
3.3 编码
- Python2 中默认编码为 ASCII,假如内容为汉字,不指定编码便不能正确的输出及读取,比如我们想要指定编码为 UTF-8,Python 中通过在开头加入 # -- coding: UTF-8 -- 进行指定。
- Python3 中默认编码为 UTF-8,因此在使用 Python3 时,我们通常不需指定编码。
3.4 打印
Python 输出使用 print(),内容加在括号中即可
# ---encoding:utf-8---
# @Time : 2023/9/1 20:47
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site :
# @File : __init__.py.py
# 我是单行注释
'''
我是多行注释
我是多行注释
'''
"""
我是多行注释
我是多行注释
"""
if __name__ == '__main__':
print('Hello World')
print("你好,世界")
3.5 行与缩进
- 学习 Python 与其他语言最大的区别就是,Python 的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断。python 最具特色的就是用缩进来写模块。
- 缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:test.py
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
# 没有严格缩进,在执行时会报错
print ("False")
如果是 IndentationError: unexpected indent 错误, 则 python 编译器是在告诉你"Hi,老兄,你的文件里格式不对了,可能是 tab 和空格没对齐的问题",所以 python 对格式要求非常严格。
因此,在 Python 的代码块中必须使用相同数目的行首缩进空格数。
建议你在每个缩进层次使用 单个制表符 或 两个空格 或 四个空格 , 切记不能混用
3.6 多行语句
- Python语句中一般以新行作为语句的结束符,但是我们可以使用斜杠( \)将一行的语句分为多行显示
total = item_one + \
item_two + \
item_three
- 语句中包含 [], {} 或 () 括号就不需要使用多行连接符
days = ['Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday']
3.7 Python引号
- Python 可以使用引号( ’ )、双引号( " )、三引号( ‘’’ 或 “”" ) 来表示字符串,引号的开始与结束必须是相同类型的。
- 其中三引号可以由多行组成,编写多行文本的快捷语法,常用于文档字符串,在文件的特定地点,被当做注释。
word = 'word'
sentence = "这是一个句子。"
paragraph = """这是一个段落。
包含了多个语句"""
了解上面了基本规则,我们就可以进行Python基本的语法学习了
四 Python基本语法
4.1 数据类型
4.1.1 变量赋值
- 变量:变量是存储在内存中的值,这就意味着在创建变量时会在内存中开辟一个空间
基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。
因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符。
- 如何赋值?
每个变量在内存中创建,都包括变量的标识,名称和数据这些信息,每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建,等号 = 用来给变量赋值。
# -- coding: utf-8 --
if __name__ == '__main__':
print('Hello World')
# 利用=进行赋值
name=input('Please input your name:')
age=100
print('Hello',name)
- 多个变量赋值
Python允许你同时为多个变量赋值
# -- coding: utf-8 --
if __name__ == '__main__':
print('Hello World')
name=input('Please input your name:')
age=100
print('Hello',name)
# 多个赋值
a=b=c=1
print(a,b,c)
4.1.2 数据类型
Python有五个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
4.1.2.1 Numbers(数字)
Python支持四种不同的数字类型:
- int(有符号整型)
- long(长整型,也可以代表八进制和十六进制),
- float(浮点型)
- complex(复数)
| 种类 | 描述 | 引导符 |
| — | — | — |
| 二进制 | 由 0 和 1 组成 | 0b 或 0B |
| 八进制 | 由 0 到 7 组成 | 0o 或 0O |
| 十进制 | 默认情况 | 无 |
| 十六进制 | 由 0 到 9、a 到 f、A 到 F 组成,不区分大小写 | 0x 或 0X |
基本使用
# ---encoding:utf-8---
# @Time : 2023/9/2 10:03
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 1、Python中的数字类型
# @File : Numbers.py
if __name__ == '__main__':
# 整数
age=100
print('age',age)
# 打印变量的类型
print(type(age))
# 打印变量的内存地址
print(id(age))
# 浮点数
salary=100.0
print('salary',salary)
# 打印变量的类型
print(type(salary))
# 打印变量的内存地址
print(id(salary))
# 复数
c=1+2j
print('c',c)
# 打印变量的类型
print(type(c))
# 打印变量的内存地址
print(id(c))
# 布尔值
flag=True
print('flag',flag)
# 打印变量的类型
print(type(flag))
# 打印变量的内存地址
print(id(flag))
- 长整型也可以使用小写 l,但是还是建议您使用大写 L,避免与数字 1 混淆。Python使用 L 来显示长整型。
- Python 还支持复数,复数由实数部分和虚数部分构成,可以用 a + bj,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型。
**注意:**long 类型只存在于 Python2.X 版本中,在 2.2 以后的版本中,int 类型数据溢出后会自动转为long类型。在 Python3.X 版本中 long 类型被移除,使用 int 替代。
数学运算:数学模块 math,在我们的开发中会使用
- abs(x) 返回 x 的绝对值
- ceil(x) 返回 x 的上入整数,如:math.ceil(1.1) 返回 2
- floor(x) 返回 x 的下舍整数,如:math.floor(1.1) 返回 1
- exp(x) 返回 e 的 x 次幂
- log(x) 返回以 e 为底 x 的对数
- log10(x) 返回以 10 为底 x 的对数
- pow(x, y) 返回 x 的 y 次幂
- sqrt(x) 返回 x 的平方根
- factorial(x) 返回 x 的阶乘
# ---encoding:utf-8---
# @Time : 2023/9/2 11:09
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : Math数学函数
# @File : MathNumberTest.py
import math
if __name__ == '__main__':
# 取余
print(math.fmod(10, 3))
# 向上取整
print(math.ceil(10.1))
# 向下取整
print(math.floor(10.9))
# 四舍五入
print(round(10.5))
# 绝对值
print(math.fabs(-10))
# 幂运算
print(math.pow(10, 2))
# 平方根
print(math.sqrt(100))
# 三角函数
print(math.sin(10))
随机运算:random 模块对随机数的生成提供了支持
# ---encoding:utf-8---
# @Time : 2023/9/2 11:14
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 随机模块
# @File : RandomNumber.py
import random
if __name__ == '__main__':
# 生成一个随机数
print(random.random())
# 生成一个指定范围的随机数
print(random.randint(1, 10))
# 生成一个指定范围的随机数
print(random.randrange(1, 10))
# 生成一个指定范围的随机数
print(random.uniform(1, 10))
# 生成一个指定范围的随机数
print(random.choice([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]))
# 生成一个指定范围的随机数
print(random.sample([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], k=5))
# 生成一个指定范围的随机数
print(random.shuffle([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]))
# 百分率随机数
print(random.random() * 100)
总结
在Python中,有几种常见的数字类型,包括整数(int)、浮点数(float)、复数(complex)。以下是这些数字类型的基本介绍:
- 整数(int):
- 整数是没有小数部分的数字。
- 例如:
5、-10、0都是整数。 - Python的整数可以表示任意大的整数,不受限制。
- 浮点数(float):
- 浮点数包含小数部分的数字。
- 例如:
3.14、-0.5都是浮点数。 - 浮点数的精度有限,可能会存在舍入误差。
- 复数(complex):
- 复数是具有实部和虚部的数字。
- 例如:
2 + 3j表示实部为2,虚部为3的复数。 - 复数在一些科学和工程计算中非常有用。
Python还提供了一些数字操作和函数,可以用于处理这些数字类型,例如:
- 算术运算:可以使用加法、减法、乘法、除法等操作符对数字进行基本的算术运算。
- 类型转换:你可以使用
int()、float()、complex()等函数将一个数字转换为不同的数字类型。 - 数学函数:Python提供了许多内置的数学函数,如
abs()(绝对值)、round()(四舍五入)、pow()(幂运算)等。 - 数学模块:还有一个名为
math的标准库模块,提供了更多高级的数学函数和常数,例如三角函数、对数函数、π等。
以下是一些示例:
# 整数和浮点数
x = 5
y = 3.14
# 进行算术运算
result = x + y
print(result)
# 类型转换
int_result = int(y)
print(int_result)
# 使用math模块
import math
square_root = math.sqrt(16)
print(square_root)
4.1.2.2 String(字符串)
字符串或串(String)是由数字、字母、下划线组成的一串字符。
# ---encoding:utf-8---
# @Time : 2023/9/2 10:10
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 2、Python中的字符串类型
# @File : String.py
if __name__ == '__main__':
str='Hello World'
print('str',str)
# 打印变量的类型
print(type(str))
# 打印变量的内存地址
print(id(str))
# 字符串的切片
print(str[0:5])
# 字符串的拼接
print(str+'你好')
# 字符串的重复
print(str*3)
# 字符串的长度
print(len(str))
# 字符串的查找
print(str.find('llo'))
# 字符串的替换
print(str.replace('llo','Darwin'))
# 字符串的大小写转换
print(str.upper())
print(str.lower())
# 字符串的首字母大写
print(str.capitalize())
# 字符串的每个单词首字母大写
print(str.title())
# 字符串的判断
print(str.isalpha())
print(str.isdigit())
print(str.isalnum())
# 字符串的分割
print(str.split(' '))
# 字符串的去空格
print(str.strip())
# 字符串的格式化
print('我叫%s,今年%d岁'%('Darwin',18))
print('我叫{0},今年{1}岁'.format('Darwin',18))
print('我叫{name},今年{age}岁'.format(name='Darwin',age=18))
print(f'我叫{"Darwin"},今年{18}岁')
# 字符串的转义
print('Hello\nWorld')
print('Hello\tWorld')
print('Hello\\World')
print('Hello\'World')
print('Hello\"World')
print('Hello\rWorld')
print('Hello\bWorld')
print('Hello\fWorld')
print('Hello\oooWorld')
# 字符串的原始字符串
print(r'Hello\nWorld')
# 字符串的索引
print(str[0])
python的字串列表有2种取值顺序:
- 从左到右索引默认0开始的,最大范围是字符串长度少1
- 从右到左索引默认-1开始的,最大范围是字符串开头
如果你要实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标] 来截取相应的字符串,其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符。
它还有很多常用方法,截取,反转,大小写,占位符参考上面
字符串常用方法总结:
- ▍1、Slicing
slicing切片,按照一定条件从列表或者元组中取出部分元素(比如特定范围、索引、分割值)
- ▍2、strip()
strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
- ▍3、lstrip()
移除字符串左侧指定的字符(默认为空格或换行符)或字符序列。
- ▍4、replace()
把字符串中的内容替换成指定的内容。
- ▍5、split()
对字符串做分隔处理,最终的结果是一个列表。
- ▍6、join()
string.join(seq)。以string作为分隔符,将seq中所有的元素(的字符串表示)合并为一个新的字符串。
- ▍7、upper()
将字符串中的字母,全部转换为大写。
- ▍8、lower()
将字符串中的字母,全部转换为小写。
- ▍9、find()
检测指定内容是否包含在字符串中,如果是返回开始的索引值,否则返回-1。
- ▍10、startswith()
检查字符串是否是以指定内容开头,是则返回 True,否则返回 False。
总结
在Python中,字符串是一种非常常见的数据类型,用于表示文本数据。字符串是不可变的,这意味着一旦创建,就不能直接修改它们的内容,但可以通过创建新的字符串来实现修改。以下是关于Python字符串的基本信息和操作:
- 创建字符串:
- 你可以使用单引号
' '或双引号" "来创建字符串,例如:"Hello, Python!"或'This is a string.' - 你还可以使用三重引号
''' '''或""" """来创建多行字符串。
- 访问字符串中的字符:
- 你可以使用索引来访问字符串中的单个字符,索引从0开始,例如:
my_string[0]。 - 也可以使用负索引从字符串末尾开始访问,例如:
my_string[-1]表示最后一个字符。
- 切片字符串:
- 使用切片操作可以获取字符串的一部分,例如:
my_string[2:5]返回索引2到4的字符。 - 切片操作包括起始索引,但不包括结束索引。
- 字符串拼接:
- 你可以使用
+运算符将两个字符串拼接在一起,例如:first_name + " " + last_name。
- 字符串长度:
- 使用
len()函数可以获取字符串的长度,即字符的数量。
- 字符串方法:
- Python提供了许多字符串方法,用于处理和操作字符串,如
upper()(将字符串转为大写)、lower()(将字符串转为小写)、strip()(去除字符串两端的空白字符)等。
- 字符串格式化:
- 你可以使用字符串的
format()方法或者 f-strings(在字符串前加f)来进行字符串格式化,以便插入变量或表达式的值。
- 字符串转义字符:
- 在字符串中,可以使用反斜杠符号
\来插入特殊字符,例如\n表示换行,\t表示制表符等。
- 字符串方法:
- 字符串有许多内置的方法,用于查找子字符串、替换文本、拆分字符串等操作。例如
find()、replace()、split()等。
以下是一些示例:
# 创建字符串
my_string = "Hello, Python!"
# 访问字符
first_char = my_string[0]
# 切片字符串
substring = my_string[7:13]
# 字符串拼接
first_name = "John"
last_name = "Doe"
full_name = first_name + " " + last_name
# 字符串长度
length = len(my_string)
# 字符串方法
uppercase_string = my_string.upper()
lowercase_string = my_string.lower()
# 字符串格式化
formatted_string = "My name is {} and I am {} years old.".format(name, age)
# 转义字符
escaped_string = "This is a newline.\nThis is a tab:\t\tSee?"
# 字符串方法示例
text = "Hello, World!"
index = text.find("World")
replaced_text = text.replace("World", "Python")
split_text = text.split(",") # 分割成列表
4.1.2.3 List(列表)
- List(列表) 是 Python 中使用最频繁的数据类型。
- 列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
- 列表用 [ ] 标识,是 python 最通用的复合数据类型。
- 列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。
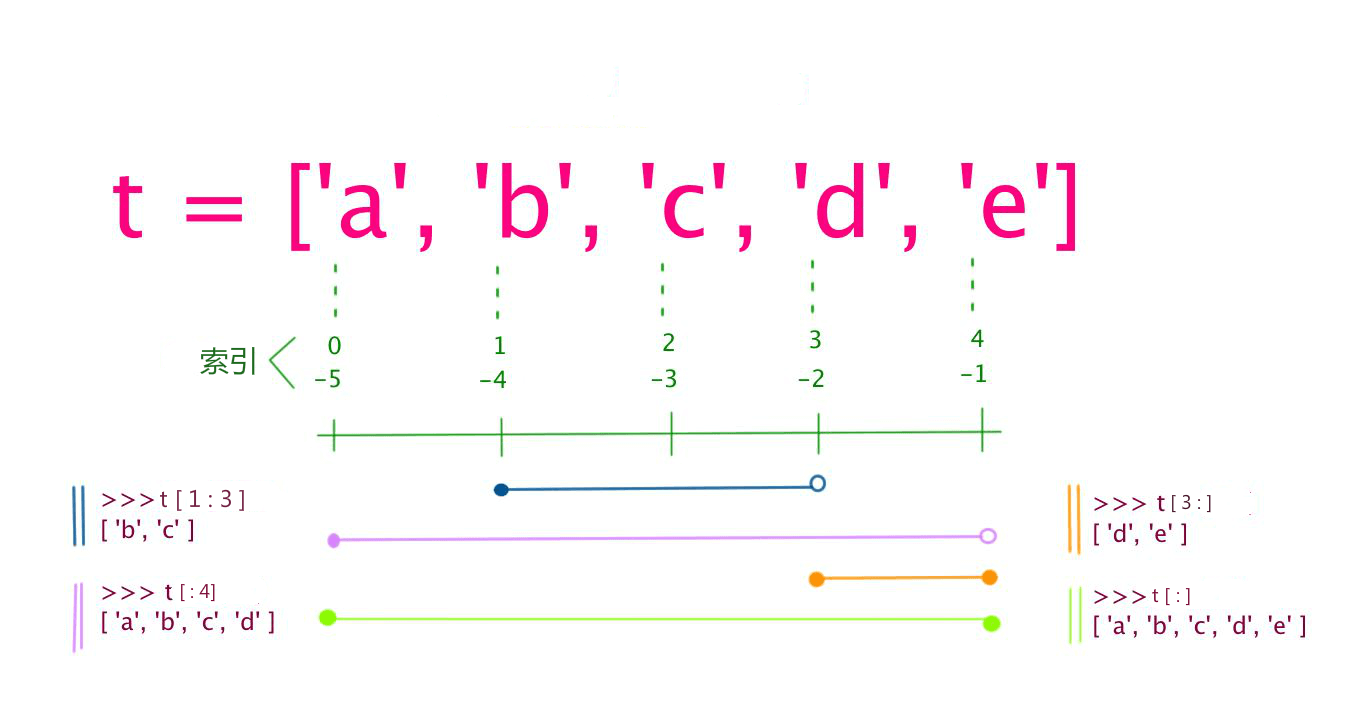
# ---encoding:utf-8---
# @Time : 2023/9/2 10:15
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 3、Python中的列表类型
# @File : List.py
if __name__ == '__main__':
arr=[1,2,3,4,5,6,7,8,9,10]
print('arr',arr)
# 打印变量的类型
print(type(arr))
# 打印变量的内存地址
print(id(arr))
# 列表的切片
print(arr[0:5])
# 列表的拼接
print(arr+[11,12,13,14,15])
# 列表的重复
print(arr*3)
# 列表的长度
print(len(arr))
# 列表的查找
print(arr.index(5))
# 列表的替换
arr[0]=100
print(arr)
# 列表的删除
del arr[0]
print(arr)
# 列表的排序
arr.sort()
print(arr)
# 列表的反转
arr.reverse()
print(arr)
# 列表的追加
arr.append(100)
print(arr)
# 列表的插入
arr.insert(0,100)
print(arr)
# 列表的删除
arr.remove(100)
print(arr)
# 列表的弹出
print(arr.pop())
print(arr)
# 列表的清空
arr.clear()
print(arr)
# 列表的复制
arr=[1,2,3,4,5,6,7,8,9,10]
arr1=arr.copy()
print(arr1)
# 列表的统计
print(arr.count(1))
# 列表的嵌套
arr2=[1,2,3,4,5,6,7,8,9,10,[11,12,13,14,15]]
print(arr2)
# 列表的遍历
for i in arr2:
print(i)
# 列表的推导式
arr3=[i for i in range(1,11)]
print(arr3)
# 列表的推导式
arr4=[i for i in range(1,11) if i%2==0]
print(arr4)
# 列表的推导式
arr5=[i for i in range(1,11) if i%2==0 if i%3==0]
print(arr5)
总结
Python列表是一种有序的数据结构,用于存储一组元素。它们非常灵活,可以包含不同类型的数据,包括整数、字符串、浮点数等。要创建一个Python列表,你可以使用方括号 [] 并在其中放置元素,如下所示:
my_list = [1, 2, 3, 4, 5]
这里是一些常用的列表操作和方法:
- 访问列表元素:你可以使用索引来访问列表中的元素,索引从0开始。例如,要访问第一个元素,可以使用
my_list[0]。 - 切片列表:通过使用切片,你可以获取列表的一部分。例如,
my_list[1:3]返回从索引1到索引2的元素。 - 修改列表元素:你可以通过索引来修改列表中的元素,例如,
my_list[0] = 10会将第一个元素的值修改为10。 - 添加元素:使用
append()方法可以在列表末尾添加元素,例如,my_list.append(6)会将6添加到列表的末尾。 - 删除元素:你可以使用
remove()方法根据元素的值来删除列表中的元素,或者使用del语句根据索引删除元素。 - 长度:使用
len()函数可以获取列表的长度,即其中包含的元素数量。 - 查找元素:你可以使用
in关键字来检查某个元素是否存在于列表中。 - 迭代列表:你可以使用循环来迭代遍历列表中的元素。
方法总结
以下是Python列表的一些基本方法和操作:
- 创建列表:
- 使用方括号
[]创建一个空列表:my_list = [] - 使用元素初始化列表:
my_list = [1, 2, 3]
- 添加元素:
- 使用
append()方法在列表末尾添加元素:my_list.append(4) - 使用
insert()方法在指定位置插入元素:my_list.insert(1, 5)
- 删除元素:
- 使用
remove()方法根据元素的值删除元素:my_list.remove(2) - 使用
pop()方法根据索引删除元素并返回它:removed_element = my_list.pop(0) - 使用
del语句根据索引删除元素:del my_list[1]
- 访问元素:
- 使用索引来访问列表元素,索引从0开始:
first_element = my_list[0]
- 切片列表:
- 使用切片来获取列表的一部分:
my_slice = my_list[1:3]
- 修改元素:
- 使用索引来修改列表中的元素:
my_list[0] = 10
- 查找元素:
- 使用
in关键字来检查元素是否存在于列表中:if 5 in my_list:
- 获取列表长度:
- 使用
len()函数来获取列表中元素的数量:list_length = len(my_list)
- 迭代列表:
- 使用
for循环来遍历列表中的元素:
for item in my_list:
print(item)
4.1.2.4 Tuple(元组)
- 元组是另一个数据类型,类似于 List(列表)。
- 元组用 () 标识,内部元素用逗号隔开,但是元组不能二次赋值,相当于只读列表。
# ---encoding:utf-8---
# @Time : 2023/9/2 10:21
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 4、Python中的元组类型
# @File : Tuple.py
if __name__ == '__main__':
tup=(1,2,3,4,5,6,7,8,9,10)
print('tup',tup)
# 打印变量的类型
print(type(tup))
# 打印变量的内存地址
print(id(tup))
# 元组的切片
print(tup[0:5])
# 元组的拼接
print(tup+(11,12,13,14,15))
# 元组的重复
print(tup*3)
# 元组的长度
print(len(tup))
# 元组的查找
print(tup.index(5))
# 元组的统计
print(tup.count(1))
# 元组的嵌套
tup1=(1,2,3,4,5,6,7,8,9,10,(11,12,13,14,15))
print(tup1)
# 元组的转换
arr=[1,2,3,4,5,6,7,8,9,10]
tup2=tuple(arr)
print(tup2)
# 元组的解包
a,b,c,d,e,f,g,h,i,j=tup2
print(a,b,c,d,e,f,g,h,i,j)
#元组的遍历
for i in tup2:
print(i)
# 元组的比较
tup3=(1,2,3,4,5,6,7,8,9,10)
tup4=(1,2,3,4,5,6,7,8,9,10)
print(tup3==tup4)
print(tup3>tup4)
print(tup3<tup4)
总结
在Python中,元组(Tuple)是一种有序的不可变数据类型,用于存储一组元素。与列表不同,元组一旦创建,其内容就不能被修改。元组通常用圆括号 () 来表示,其中包含逗号分隔的元素。以下是有关Python元组的基本信息和操作:
- 创建元组:
- 你可以使用圆括号
()来创建一个元组,例如:(1, 2, 3)。
- 访问元组元素:
- 你可以使用索引来访问元组中的元素,索引从0开始,例如:
my_tuple[0]访问第一个元素。
- 元组拆包:
- 可以将元组的元素拆包到多个变量中,例如:
x, y, z = my_tuple。
- 不可变性:
- 元组的元素不可被修改,这意味着你不能像列表那样使用索引来赋值新的值。
- 元组的长度:
- 使用
len()函数可以获取元组中元素的数量。
- 元组可以包含不同类型的元素:
- 一个元组可以同时包含整数、字符串、浮点数等不同类型的元素。
- 元组与列表的比较:
- 元组与列表相似,但列表使用方括号
[],并且是可变的,而元组使用圆括号(),是不可变的。
以下是一些示例:
# 创建元组
my_tuple = (1, 2, 3)
# 访问元素
first_element = my_tuple[0]
# 元组拆包
x, y, z = my_tuple
# 元组的长度
tuple_length = len(my_tuple)
# 不可变性
# 以下代码会引发 TypeError: 'tuple' object does not support item assignment
# my_tuple[0] = 10
# 包含不同类型的元素
mixed_tuple = (1, "hello", 3.14)
# 元组与列表的比较
my_list = [1, 2, 3] # 列表
my_tuple = (1, 2, 3) # 元组
元组通常用于存储一组相关的值,它们的不可变性使其适用于某些特定的用途,如用作字典的键或在函数中返回多个值。如果你需要一个有序但可变的数据结构,可以使用列表;如果需要一个不可变的有序数据结构,可以使用元组。
4.1.2.5 Dictionary(字典)
- 字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型,列表是有序的对象集合,字典是无序的对象集合。
- 两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
- 字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
# ---encoding:utf-8---
# @Time : 2023/9/2 10:24
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 5、Python中的字典类型
# @File : Dictionary.py
if __name__ == '__main__':
dict={'name':'Darwin','age':18,'salary':100.0,'flag':True}
print('dict',dict)
# 打印变量的类型
print(type(dict))
# 打印变量的内存地址
print(id(dict))
# 字典的长度
print(len(dict))
# 字典的查找
print(dict['name'])
# 字典的修改
dict['name']='Bossen'
print(dict)
# 字典的删除
del dict['name']
print(dict)
# 字典的清空
dict.clear()
print(dict)
# 字典的复制
dict={'name':'Darwin','age':18,'salary':100.0,'flag':True}
dict1=dict.copy()
print(dict1)
# 字典的遍历
for key in dict:
print(key,dict[key])
# 字典的嵌套
dict2={'name':'Darwin','age':18,'salary':100.0,'flag':True,'dict':{'name':'Bossen','age':18,'salary':100.0,'flag':True}}
print(dict2)
# 字典的键值对
print(dict2.items())
# 字典的键
print(dict2.keys())
# 字典的值
print(dict2.values())
# 字典的更新
dict2.update({'name':'Bossen','age':18,'salary':100.0,'flag':True})
print(dict2)
# 字典的弹出
print(dict2.pop('name'))
print(dict2)
# 字典的弹出随机键值对
print(dict2.popitem())
print(dict2)
# 字典的fromkeys
dict3=dict.fromkeys(['name','age','salary','flag'])
print(dict3)
# 字典的get
print(dict2.get('name'))
# 字典的setdefault
print(dict2.setdefault('name','Darwin'))
print(dict2)
# 遍历字典的键值对
for key,value in dict2.items():
print(key,value)
# 遍历字典的键
for key in dict2.keys():
print(key)
# 遍历字典的值
for value in dict2.values():
print(value)
总结
在Python中,字典(Dictionary)是一种无序的数据结构,用于存储键-值对(key-value pairs)。字典是可变的,允许你添加、删除和修改键值对。字典通常用花括号 {} 来表示,每个键值对由冒号 : 分隔,键和值之间由逗号 , 分隔。以下是有关Python字典的基本信息和操作:
- 创建字典:
- 你可以使用花括号
{}来创建一个空字典:my_dict = {}。 - 或者使用大括号包含键值对来初始化字典:
my_dict = {'name': 'John', 'age': 30}。
- 访问字典的值:
- 你可以使用键来访问字典中的值,例如:
name = my_dict['name']。
- 添加新的键值对:
- 使用赋值语句可以添加新的键值对,例如:
my_dict['city'] = 'New York'。
- 修改键值对的值:
- 通过指定已存在的键,你可以修改其对应的值,例如:
my_dict['age'] = 31。
- 删除键值对:
- 使用
del语句可以删除字典中的键值对,例如:del my_dict['age']。
- 检查键是否存在:
- 使用
in关键字可以检查某个键是否存在于字典中,例如:if 'name' in my_dict:。
- 获取字典的键和值:
- 使用
keys()方法可以获取字典中的所有键,values()方法可以获取所有的值,items()方法可以获取键值对组成的元组。
- 字典的长度:
- 使用
len()函数可以获取字典中键值对的数量。
以下是一些示例:
# 创建字典
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
# 访问值
name = my_dict['name']
# 添加新键值对
my_dict['job'] = 'Engineer'
# 修改值
my_dict['age'] = 31
# 删除键值对
del my_dict['city']
# 检查键是否存在
if 'name' in my_dict:
print(f"Name: {my_dict['name']}")
# 获取键和值
keys = my_dict.keys()
values = my_dict.values()
items = my_dict.items()
# 字典的长度
dict_length = len(my_dict)
字典是一种非常有用的数据结构,常用于存储和检索具有关联性的数据。键必须是不可变的类型,如字符串或数字,而值可以是任何数据类型,包括列表、元组、其他字典等。
4.1.2.6 Set 集合
- 集合(set)是一个无序的不重复元素序列。
- 集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
- 可以使用大括号 { } 创建集合,元素之间用逗号 , 分隔, 或者也可以使用 set() 函数创建集合。
# ---encoding:utf-8---
# @Time : 2023/9/2 14:25
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : Set集合
# @File : Set.py
if __name__ == '__main__':
set1 = {1, 2, 3, 4} # 直接使用大括号创建集合
set2 = set([4, 5, 6, 7]) # 使用 set() 函数从列表创建集合
print(set1)
# 集合的基本操作
# 1.添加元素
set1.add(5)
print(set1)
# 2.删除元素
set1.remove(5)
print(set1)
# 3.集合的并集
print(set1 | set2)
# 4.集合的交集
print(set1 & set2)
# 5.集合的差集
print(set1 - set2)
# 6.集合的对称差
print(set1 ^ set2)
# 7.判断元素是否在集合中
print(1 in set1)
print(1 not in set1)
# 8.判断子集和超集
print(set1 <= set2)
print(set1 >= set2)
# 9.清空集合
set1.clear()
print(set1)
# 10.集合的长度
print(len(set2))
# 11.集合的拷贝
set3 = set2.copy()
print(set3)
# 12.集合的遍历
for item in set2:
print(item)
总结
Python中的集合是一种无序的数据结构,它包含唯一的元素。在Python中,你可以使用set来创建一个集合,或者使用花括号{}来创建一个集合字面量。下面是一些关于Python集合的基本操作和信息:
- 创建集合:
my_set = set() # 创建一个空集合
my_set = {1, 2, 3} # 创建一个包含元素的集合
- 添加元素:
my_set.add(4) # 向集合中添加元素4
- 移除元素:
my_set.remove(2) # 从集合中移除元素2,如果元素不存在会引发KeyError
my_set.discard(3) # 从集合中移除元素3,如果元素不存在不会引发错误
- 集合操作:
- 并集:
union方法或|操作符 - 交集:
intersection方法或&操作符 - 差集:
difference方法或-操作符 - 对称差集:
symmetric_difference方法或^操作符
set1 = {1, 2, 3}
set2 = {3, 4, 5}
union_set = set1.union(set2) # 或者使用 set1 | set2
intersection_set = set1.intersection(set2) # 或者使用 set1 & set2
difference_set = set1.difference(set2) # 或者使用 set1 - set2
symmetric_difference_set = set1.symmetric_difference(set2) # 或者使用 set1 ^ set2
- 其他集合操作方法和函数:
issubset():判断一个集合是否为另一个集合的子集。issuperset():判断一个集合是否为另一个集合的超集。clear():清空集合中的所有元素。copy():复制集合。len():获取集合的元素数量。
4.12.6 类型转换
# ---encoding:utf-8---
# @Time : 2023/9/2 10:27
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 6、Python中的类型转换
# @File : CoverType.py
if __name__ == '__main__':
name='Darwin'
age=18
salary=100.0
flag=True
arr=[1,2,3,4,5,6,7,8,9,10]
tup=(1,2,3,4,5,6,7,8,9,10)
dict={'name':'Darwin','age':18,'salary':100.0,'flag':True}
# int()函数
print(int(salary))
# float()函数
print(float(age))
# complex()函数
print(complex(age))
# bool()函数
print(bool(age))
# str()函数
print(str(age))
# list()函数
print(list(tup))
# tuple()函数
print(tuple(arr))
- 有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
- 以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
| 函数 | 描述 |
| — | — |
| int(x [,base]) | 将x转换为一个整数 |
| long(x [,base] ) | 将x转换为一个长整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个序列 (key,value)元组。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| unichr(x) | 将一个整数转换为Unicode字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
4.2 基本语句
以下是一些Python的基本语句和示例:
- 赋值语句:
x = 5 # 将5赋值给变量x
name = "Alice" # 将字符串赋值给变量name
- 条件语句(if语句):
if x > 0:
print("x是正数")
elif x < 0:
print("x是负数")
else:
print("x是零")
- 循环语句(for循环):
for i in range(5):
print(i) # 打印0到4
- 循环语句(while循环):
i = 0
while i < 5:
print(i) # 打印0到4
i += 1
- 函数定义:
def add(a, b):
return a + b
- 函数调用:
result = add(3, 4) # 调用add函数,返回7
- 列表(List):
numbers = [1, 2, 3, 4, 5]
- 字典(Dictionary):
person = {"name": "Alice", "age": 30}
- 字符串操作:
greeting = "Hello, World!"
print(greeting[0]) # 打印第一个字符 "H"
下面我们来详细看看一些语句
4.2.1 IF语句
当你需要在程序中根据条件来执行不同的代码块时,你可以使用Python中的if语句。if语句的基本语法如下:
if 条件:
# 条件成立时执行的代码块
elif 另一个条件: # 可选
# 如果第一个条件不成立,且这个条件成立时执行的代码块
else: # 可选
# 如果上述条件都不成立时执行的代码块
以下是一个示例,演示了如何使用if语句:
# ---encoding:utf-8---
# @Time : 2023/9/2 13:16
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : IF语句
# @File : IF.py
if __name__ == '__main__':
age = 25
if age < 18:
print("未成年人")
elif age >= 18 and age < 65:
print("成年人")
else:
print("老年人")
在这个示例中,根据年龄的不同,会打印不同的消息。如果age小于18,将打印"未成年人";如果age在18到65之间(包括18但不包括65),将打印"成年人";否则,将打印"老年人"
4.2.2 For循环
for循环是在Python中用于迭代(遍历)序列或可迭代对象的重要工具。它的基本语法如下:
for 变量 in 序列或可迭代对象:
# 在每次迭代中执行的代码块
这里的"变量"是一个临时变量,它在每次迭代中都会取序列或可迭代对象中的下一个值。循环将继续,直到序列中没有更多的元素可供迭代为止。
# ---encoding:utf-8---
# @Time : 2023/9/2 13:20
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : for循环
# @File : FOR.py
if __name__ == '__main__':
# for循环
for i in range(1, 10):
for j in range(1, i + 1):
print('%d*%d=%d' % (j, i, i * j), end='\t')
print()
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
for x in "banana":
print(x)
for x in range(6):
print(x)
以下是一些示例,演示了如何使用for循环:
- 迭代列表(List)中的元素:
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
- 迭代字符串中的字符:
word = "Python"
for letter in word:
print(letter)
- 使用
range()函数创建一系列数字并进行迭代:
for i in range(5): # 从0到4的数字
print(i)
- 迭代字典(Dictionary)的键和值:
person = {"name": "Alice", "age": 30, "country": "USA"}
for key, value in person.items():
print(key, ":", value)
- 迭代集合(Set)中的元素:
colors = {"red", "green", "blue"}
for color in colors:
print(color)
for循环是Python中常用的控制结构之一,它允许你有效地遍历各种数据结构和序列。你可以根据具体的需求来使用for循环。
4.2.3 While
while循环是Python中的一种迭代结构,它在满足特定条件的情况下重复执行一段代码块。循环会一直执行,直到条件不再满足为止。以下是while循环的基本语法:
while 条件:
# 当条件为真时执行的代码块
在每次循环迭代时,程序会检查条件是否为真。只要条件为真,循环就会继续执行。一旦条件变为假,循环就会停止执行。
# ---encoding:utf-8---
# @Time : 2023/9/2 13:26
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : While 循环
# @File : WHILE.py
if __name__ == '__main__':
count = 0
while count < 5:
print(count, "小于5")
count += 1
else:
print(count, "大于或等于5")
print("----------分割线----------")
以下是一个示例,演示了如何使用while循环:
count = 0
while count < 5:
print("当前计数:", count)
count += 1
在这个示例中,循环会持续执行,直到count的值不再小于5。每次迭代中,会打印当前的计数值,并将count增加1。一旦count达到5,循环就会终止。
需要谨慎使用while循环,因为如果条件永远不为假,循环可能会无限循环,导致程序停止响应。确保在循环内部有适当的逻辑来改变条件,以便在适当的时候退出循环。
4.2.4 Pass语句
pass语句是Python中的一个特殊语句,它是一个空操作,用于在语法上需要代码块但不需要执行任何操作的情况下。通常,pass语句用作占位符,以保持代码的结构完整,或者在编写代码时暂时跳过某个部分。
# ---encoding:utf-8---
# @Time : 2023/9/2 13:28
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : PASS语句
# @File : PASS.py
if __name__ == '__main__':
for letter in 'Python':
if letter == 'h':
pass
print('这是pass块')
print('当前字母:', letter)
print('Good Bye')
以下是一些使用pass语句的示例场景:
- 函数或类的占位符:
def my_function():
pass # 暂时没有实现任何功能
class MyEmptyClass:
pass # 空的类,稍后可以添加成员
- 循环中的占位符:
for i in range(5):
pass # 暂时不执行任何操作,保持循环结构
- 条件语句的占位符:
if condition:
pass # 暂时没有条件的处理
pass语句的主要作用是在代码的特定位置保持结构完整,同时允许你将注意力集中在其他部分的实现上。在开发过程中,你可以使用它来标记未来需要实现的部分,以防止因缺少代码而导致语法错误。
需要注意的是,虽然pass语句本身不执行任何操作,但它在语法上是有效的Python代码,不会引发错误。
4.3 基本运算
4.3.1 数学运算
Python支持各种基本数学运算,包括加法、减法、乘法、除法、取余数等。以下是Python中常见的基本运算示例:
- 加法:
x = 5
y = 3
result = x + y # 结果是8
- 减法:
x = 5
y = 3
result = x - y # 结果是2
- 乘法:
x = 5
y = 3
result = x * y # 结果是15
- 除法:
x = 6
y = 2
result = x / y # 结果是3.0(在Python 3中,整数除法会返回浮点数)
- 取整除法:
x = 6
y = 2
result = x // y # 结果是3(返回整数部分)
- 取余数:
x = 7
y = 3
result = x % y # 结果是1
- 幂运算:
x = 2
y = 3
result = x ** y # 结果是8
- 绝对值:
x = -5
result = abs(x) # 结果是5
- 四舍五入:
x = 3.7
result = round(x) # 结果是4
- 比较运算(返回布尔值):
x = 5
y = 3
greater = x > y # 结果是True
less_equal = x <= y # 结果是False
equal = x == y # 结果是False
这些是Python中一些常见的基本数学运算。你可以根据需要使用这些运算符来执行各种数学计算。如果需要更多复杂的数学操作,还可以使用Python的数学库,如math来扩展功能。
4.3.2 赋值运算
赋值运算用于将值赋给变量,使变量持有特定的值。Python支持多种不同的赋值运算符,以下是常见的赋值运算符示例:
- 等号(=)赋值:
x = 5 # 将5赋值给变量x
- 加等于(+=)赋值:
x = 5
x += 3 # 等同于 x = x + 3,将x的值增加3,x现在等于8
- 减等于(-=)赋值:
x = 5
x -= 2 # 等同于 x = x - 2,将x的值减少2,x现在等于3
- 乘等于(=)赋值:** **
x = 5
x *= 4 # 等同于 x = x * 4,将x的值乘以4,x现在等于20
- 除等于(/=)赋值:
x = 10
x /= 2 # 等同于 x = x / 2,将x的值除以2,x现在等于5.0(在Python 3中,除法通常返回浮点数)
- 取整除等于(//=)赋值:
x = 10
x //= 3 # 等同于 x = x // 3,将x的值取整除以3,x现在等于3
- 取余等于(%=)赋值:
x = 10
x %= 3 # 等同于 x = x % 3,将x的值对3取余,x现在等于1
- 幂等于(=)赋值:**
x = 2
x **= 3 # 等同于 x = x ** 3,将x的值做幂运算,x现在等于8
4.3.3 比较运算
比较运算用于比较两个值或表达式,通常返回布尔值(True或False)。Python支持一系列比较运算符,以下是常见的比较运算符以及示例:
- 等于(==):
x = 5
y = 5
result = x == y # 结果是True,因为x和y相等
- 不等于(!=):
x = 5
y = 3
result = x != y # 结果是True,因为x不等于y
- 大于(>):
x = 5
y = 3
result = x > y # 结果是True,因为x大于y
- 小于(<):
x = 5
y = 8
result = x < y # 结果是True,因为x小于y
- 大于等于(>=):
x = 5
y = 5
result = x >= y # 结果是True,因为x大于或等于y
- 小于等于(<=):
x = 5
y = 8
result = x <= y # 结果是True,因为x小于或等于y
这些比较运算符用于比较两个值或表达式,生成一个布尔值结果,指示比较的结果。你可以在条件语句(如if语句)中使用这些运算符,以根据不同的条件执行不同的代码块。
请注意,比较运算的结果是布尔值(True或False),用于确定两个值之间的关系。这些运算符在控制流和条件判断中非常有用。
4.3.4 逻辑运算
逻辑运算用于处理布尔值(True和False)并生成新的布尔值结果。Python支持三种主要的逻辑运算:与(and)、或(or)和非(not)。以下是这些逻辑运算的详细说明和示例:
- 与运算(and):
- 如果所有操作数都为True,结果为True;否则,结果为False。
x = True
y = False
result = x and y # 结果是False,因为其中一个操作数是False
- 或运算(or):
- 如果至少有一个操作数为True,结果为True;只有所有操作数都为False时,结果为False。
x = True
y = False
result = x or y # 结果是True,因为其中一个操作数是True
- 非运算(not):
- 对单个操作数进行取反操作,将True变为False,将False变为True。
x = True
result = not x # 结果是False,因为对True取反
这些逻辑运算符通常在条件语句中使用,以便根据不同的条件执行不同的代码块。它们也在布尔代数中有广泛的应用,用于组合和操作布尔值。
你还可以将多个逻辑运算组合在一起,以构建更复杂的逻辑条件。例如,你可以使用括号来明确运算的优先级。以下是一个示例:
x = True
y = False
z = True
result = (x or y) and (not z) # 结果是False,因为(x or y)为True,但 (not z) 为False
逻辑运算在编程中用于控制流程、筛选数据和实现条件逻辑,是编程中非常重要的一部分。
4.3.5 位移运算
位移运算是对二进制数进行位级别的移动操作,分为左移(<<)和右移(>>)两种。这些运算对整数的二进制表示进行操作,将二进制位向左或向右移动指定的位数,并且在移动过程中填充0或截断。
- 左移运算(<<):
- 将一个整数的二进制表示向左移动指定的位数,右侧用0填充。
x = 5 # 二进制表示为 101
result = x << 2 # 左移2位,结果是20(二进制表示为 10100)
- 右移运算(>>):
- 将一个整数的二进制表示向右移动指定的位数,左侧用原来的最高位填充(正数用0,负数用1)。
x = 20 # 二进制表示为 10100
result = x >> 2 # 右移2位,结果是5(二进制表示为 101)
位移运算通常用于对整数进行高效的乘法和除法操作,特别是在嵌入式系统和底层编程中。左移运算相当于将一个整数乘以2的幂次方,而右移运算相当于将一个整数除以2的幂次方。
需要注意的是,位移运算只能应用于整数,不适用于浮点数。此外,在进行右移运算时,符号位(最高位)的处理方式可能因整数的正负而不同。
4.3.6 运算父优先级
在Python中,运算符具有不同的优先级,它们会影响表达式中运算的执行顺序。以下是一些常见运算符按优先级从高到低的顺序:
- 括号:
(),括号用于强制指定运算的顺序,具有最高的优先级。 - 指数运算:
**,例如,2 ** 3表示2的3次方。 - 正负号:
+和-,用于表示正数和负数。 - 乘法、除法、取整除和取余:
*、/、//、%,这些运算符具有相同的优先级,按从左到右的顺序计算。 - 加法和减法:
+和-,这些运算符也具有相同的优先级,按从左到右的顺序计算。 - 位运算:
<<、>>、&、|、^,位运算符按照它们的运算符号顺序计算,具有较低的优先级。 - 比较运算:
==、!=、<、<=、>、>=、is、is not,比较运算符按从左到右的顺序计算,具有较低的优先级。 - 成员运算:
in和not in,用于检查元素是否在容器中,具有较低的优先级。 - 逻辑运算:
not、and、or,逻辑运算符按照它们的运算符号顺序计算,具有较低的优先级。
注意,优先级较高的运算符在表达式中会优先执行。如果你不确定某个表达式的运算顺序,可以使用括号来明确指定优先级。例如,(2 + 3) * 4确保了加法运算在乘法之前执行。
这个优先级列表可以帮助你理解Python中运算符的执行顺序,但在复杂的表达式中,建议使用括号来明确指定运算的顺序,以避免歧义。
4.3.7 推导式
Python推导式是一种简洁的语法结构,用于创建列表、集合和字典等数据结构。虽然你的用户配置表明你是Java代码辅助开发,但推导式是Python编程的一个重要概念,可能对你有帮助。
# ---encoding:utf-8---
# @Time : 2023/9/2 14:33
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : Python 推导式
# @File : Comprehensions.py
if __name__ == '__main__':
#列表推导式
list1 = [i for i in range(1, 10)]
# 循环打印
for item in list1:
print(item)
#集合推导式
set1 = {i for i in range(1, 10)}
# 循环打印
for item in set1:
print(item)
#字典推导式
dict1 = {i: i + 1 for i in range(1, 10)}
# 循环打印
for item in dict1:
print(item)
#生成器推导式
gen1 = (i for i in range(1, 10))
# 循环打印
for item in gen1:
print(item)
以下是Python中常见的推导式类型:
- 列表推导式(List Comprehensions):
列表推导式用于创建新的列表,通过对现有的列表或可迭代对象中的元素进行处理。示例:
numbers = [1, 2, 3, 4, 5]
squared_numbers = [x**2 for x in numbers]
- 集合推导式(Set Comprehensions):
集合推导式类似于列表推导式,但创建的是集合。它们用花括号{}表示。示例:
numbers = [1, 2, 2, 3, 3, 4, 5]
unique_numbers = {x for x in numbers}
- 字典推导式(Dictionary Comprehensions):
字典推导式用于创建新的字典。它们允许你通过处理现有字典的键值对来生成新的字典。示例:
names = {'Alice': 25, 'Bob': 30, 'Charlie': 35}
age_squared = {name: age**2 for name, age in names.items()}
这些推导式是Python中常用的高效编程工具,可以帮助你简化代码,提高可读性。
4.3.8 迭代器
- 迭代器是一个可以记住遍历的位置的对象。
- 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
- 迭代器有两个基本的方法:iter() 和 next()。
迭代器(Iterator)是 Python 中用于遍历可迭代对象的机制。虽然您的用户资料显示您是Java代码辅助开发,但我可以为您提供有关Python迭代器的信息。
在Python中,迭代器通常用于遍历诸如列表(lists)、元组(tuples)、字典(dictionaries)等可迭代对象的元素。以下是迭代器的基本概念和使用方法:
- 可迭代对象(Iterable):任何实现了
__iter__()方法的对象都被称为可迭代对象。可迭代对象可以通过iter()函数来获得一个迭代器。 - 迭代器对象(Iterator):迭代器是一个具有
__next__()方法的对象,它用于逐个返回可迭代对象中的元素。当没有元素可供返回时,迭代器会引发StopIteration异常。
下面是一个简单的示例,演示如何创建和使用迭代器:
# ---encoding:utf-8---
# @Time : 2023/9/2 14:39
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 迭代器
# @File : IterNext.py
if __name__ == '__main__':
# 创建一个可迭代对象
my_list = [1, 2, 3, 4, 5]
# 获取一个迭代器
my_iter = iter(my_list)
# 使用迭代器遍历元素
try:
while True:
element = next(my_iter)
print(element)
except StopIteration:
pass
在这个示例中,我们首先将一个列表转换为可迭代对象,然后使用iter()函数获取了一个迭代器。接着,我们使用next()函数逐个访问列表中的元素,直到触发StopIteration异常表示没有更多元素可供遍历。
迭代器是Python中强大而灵活的工具,用于处理大型数据集合和生成数据流。
4.3.9 生成器
生成器(Generator)是 Python 中一种强大的迭代器,允许您按需生成数据,而不需要一次性将所有数据存储在内存中。
生成器的主要特点是您可以使用函数来定义生成器,而不必一次性生成所有数据。生成器函数使用yield关键字来产生值,并在每次生成时保留函数的状态,以便在下次生成时继续执行。这使得生成器非常适合处理大型数据集或需要逐个生成数据的情况。
下面是一个简单的生成器函数示例:
def simple_generator():
yield 1
yield 2
yield 3
# 创建生成器对象
my_generator = simple_generator()
# 使用生成器逐个生成值
print(next(my_generator)) # 输出 1
print(next(my_generator)) # 输出 2
print(next(my_generator)) # 输出 3
# 如果再次调用next会引发StopIteration异常
在这个示例中,simple_generator 是一个生成器函数,它通过使用yield关键字来生成值。当我们创建生成器对象my_generator并调用next()函数时,生成器会从上一次yield语句的位置开始执行,并在下一次调用next()时继续执行,直到没有更多的值可生成,此时会引发StopIteration异常。
生成器在处理大型数据集时非常有用,因为它们不会一次性加载所有数据,而是逐个生成,节省了内存空间。您可以在循环中使用生成器,处理文件逐行读取,或者执行任何需要逐个生成数据的操作。
4.4 函数
4.4.1 函数的定义
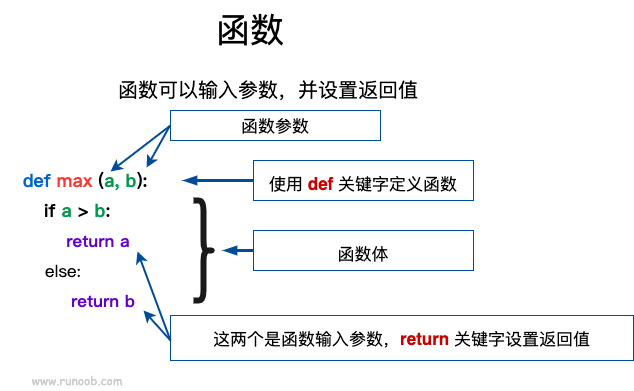
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号 : 起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。
4.4.2 格式
Python 定义函数使用 def 关键字,一般格式如下:
def 函数名(参数列表): 函数体
默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的,下面的案例:
# ---encoding:utf-8---
# @Time : 2023/9/2 15:09
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 函数定义
# @File : DefTest.py
# 函数定义
def printme(str):
print(str)
return
if __name__ == '__main__':
printme('Hello World')
printme('Hello Again')
printme('Hello Python')
4.4.3 参数传递
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- **不可变类型:**变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变 a 的值,相当于新生成了 a。
- **可变类型:**变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- **不可变类型:**类似 C++ 的值传递,如整数、字符串、元组。如 fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a) 内部修改 a 的值,则是新生成一个 a 的对象。
- **可变类型:**类似 C++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后 fun 外部的 la 也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
# ---encoding:utf-8---
# @Time : 2023/9/2 15:14
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 函数参数不可变对象
# @File : NoChangeObject.py
# 函数参数不可变对象
def change(a):
print(id(a)) # 指向的是同一个对象
a = 10
print(id(a)) # 一个新对象
if __name__ == '__main__':
a = 1
print(id(a))
change(a)

# ---encoding:utf-8---
# @Time : 2023/9/2 15:17
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 函数参数可变对象
# @File : ChangeObject.py
# 可写函数说明
def changeme( mylist ):
"修改传入的列表"
mylist.append([1,2,3,4])
print ("函数内取值: ", mylist)
return
if __name__ == '__main__':
# 调用changeme函数
mylist = [10,20,30]
changeme( mylist )
print ("函数外取值: ", mylist)

简单总结:不可变,值传递,可变,引用传递
总结
在Python中,函数参数传递有两种主要方式:传递参数通过值(传值调用)和传递参数通过引用(传引用调用)。
- 传递参数通过值(Passing Arguments by Value):
在这种情况下,函数接收到的是参数的副本,而不是原始参数本身。这意味着在函数内部对参数的任何更改都不会影响到原始参数。
在上面的示例中,num的值在函数内部增加了1,但在函数外部没有变化。 - 传递参数通过引用(Passing Arguments by Reference):
在Python中,大部分情况下,函数实际上是通过引用传递参数的。这意味着函数接收到的是原始参数的引用,对参数的修改将影响到原始参数。
在这个示例中,my_numbers是一个列表,函数modify_list通过引用访问该列表,并在其末尾添加了一个新元素。
需要注意的是,虽然大多数情况下是通过引用传递参数,但如果在函数内部对参数重新赋值,它将创建一个新的局部变量,不会影响原始参数。这类似于传递参数通过值的行为。
4.4.4 参数
- 必需参数:必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
# ---encoding:utf-8---
# @Time : 2023/9/2 15:09
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 函数定义
# @File : DefTest.py
# 函数定义
def printme(str):
print(str)
return
if __name__ == '__main__':
printme('Hello World')
printme('Hello Again')
printme('Hello Python')
- 关键字参数:关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
- 默认参数:调用函数时,如果没有传递参数,则会使用默认参数。
# ---encoding:utf-8---
# @Time : 2023/9/2 15:09
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 函数定义
# @File : DefTest.py
# 函数定义
def printme(str):
print(str)
return
if __name__ == '__main__':
printme('Hello World')
printme('Hello Again')
printme('Hello Python')
# 关键字参数
printme(str='Hello Python')
# 默认参数
def printinfo(name, age=35):
print('Name:', name)
print('Age:', age)
return
- 不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名。
# ---encoding:utf-8---
# @Time : 2023/9/2 15:09
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 函数定义
# @File : DefTest.py
# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print ("输出: ")
print (arg1)
print (vartuple)
# 调用printinfo 函数
printinfo( 70, 60, 50 )
参数
在Python中,函数参数允许您传递信息给函数,以便函数可以执行特定的任务或操作。Python中的参数可以分为以下几种类型:
- 位置参数(Positional Arguments):
位置参数是最常见的参数类型。它们按照在函数定义中的顺序传递给函数,需要按照相同的顺序传递给函数调用。例如:
def add(a, b):
return a + b
result = add(3, 5)
在这个示例中,a和b是位置参数,分别接收值3和5。
- 关键字参数(Keyword Arguments):
关键字参数允许您通过参数名指定要传递的值,而不需要按照参数定义的顺序。这提高了函数调用的可读性。例如:
def greet(name, message):
print(f"{message}, {name}!")
greet(message="Hello", name="Alice")
在这里,我们明确指定了参数的名称,以便更清晰地了解每个参数的含义。
- 默认参数(Default Arguments):
默认参数是在函数定义时为参数指定的默认值。如果函数调用没有提供特定参数的值,则将使用默认值。例如:
def greet(name, message="Hello"):
print(f"{message}, {name}!")
greet("Bob") # 使用默认的message值
在这个示例中,如果未提供message参数,它将默认为"Hello"。
- 可变长参数:
- **args:这是用于接受可变数量的位置参数的特殊语法。函数将它们作为元组处理。
def add(*args):
result = 0
for num in args:
result += num
return result
total = add(1, 2, 3, 4)
- **kwargs:这是用于接受可变数量的关键字参数的特殊语法。函数将它们作为字典处理。
def display_info(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
display_info(name="Alice", age=30, city="New York")
这些可变长参数允许函数处理不定数量的参数。
- 强制关键字参数:
在Python 3.8及更高版本中,您可以使用*来指定参数后必须使用关键字传递。这样可以强制调用者使用关键字,而不是位置传递。
def greet(name, *, message="Hello"):
print(f"{message}, {name}!")
greet("Alice") # 报错,必须使用关键字参数
greet(name="Alice") # 正确的方式
4.4.5 匿名函数
Python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然 lambda 函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,内联函数的目的是调用小函数时不占用栈内存从而减少函数调用的开销,提高代码的执行速度。
语法
lambda 函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
# ---encoding:utf-8---
# @Time : 2023/9/2 15:26
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 匿名函数
# @File : Lambda.py
# 匿名函数
sum = lambda arg1, arg2: arg1 + arg2
if __name__ == '__main__':
sum(10, 20)
总结
在Python中,匿名函数也被称为lambda函数。它们是一种特殊类型的函数,通常用于定义简单的、一次性的函数。lambda函数的语法非常简洁,通常只包含一个表达式。它们可以在需要函数作为参数的情况下使用,或者在需要一个短小的函数来执行某些操作时很有用。
以下是lambda函数的基本语法和示例:
lambda arguments: expression
lambda关键字用于定义lambda函数。arguments是函数的参数列表。expression是函数的返回值表达式。
示例1:一个简单的lambda函数,用于求平方。
square = lambda x: x ** 2
result = square(5) # 结果为25
示例2:lambda函数作为排序函数的键。
students = [
{"name": "Alice", "score": 80},
{"name": "Bob", "score": 75},
{"name": "Charlie", "score": 90}
]
# 使用lambda函数按照分数对学生列表进行排序
sorted_students = sorted(students, key=lambda student: student["score"], reverse=True)
示例3:lambda函数作为map()函数的参数。
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x ** 2, numbers)) # [1, 4, 9, 16, 25]
4.4.6 总结
当涉及到Python函数时,函数是一种重要的编程概念,用于组织、重用和模块化代码。以下是有关Python函数的详细介绍:
- 定义函数:
在Python中,可以使用关键字def来定义函数。函数通常包括函数名、参数列表、冒号和函数体。例如:
这个函数名为greet,接受一个参数name,然后在函数体中打印一条问候语。
- 调用函数:
要使用函数,只需调用它并传递所需的参数(如果有的话)。例如:
greet("Alice")
这将调用greet函数,并将"Alice"作为参数传递给它。
- 函数参数:
Python函数可以接受零个或多个参数。参数可以是必需的(没有默认值)或可选的(有默认值)。例如:
def add(a, b=0):
return a + b
在这个例子中,add函数接受两个参数,a是必需的,而b是可选的,默认为0。
- 函数返回值:
函数可以使用return语句来返回值。例如:
def multiply(x, y):
result = x * y
return result
调用multiply(2, 3)将返回6。
- 局部变量和作用域:
在函数内部定义的变量是局部变量,只在函数内部可见。这意味着它们在函数外部不可用。函数外部定义的变量是全局变量,在整个程序中可见。 - 文档字符串(Docstring):
函数通常包含文档字符串,以描述函数的功能和参数。这些文档字符串可以通过help()函数或文档工具生成文档。 - 匿名函数(Lambda函数):
Python支持匿名函数,也称为lambda函数。它们通常用于简单的操作,可以使用lambda关键字创建。
add = lambda x, y: x + y
4.5 包与模块
4.5.1 包
- 包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。
- 比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
- 就好像使用模块的时候,你不用担心不同模块之间的全局变量相互影响一样,采用点模块名称这种形式也不用担心不同库之间的模块重名的情况。
- 这样不同的作者都可以提供 NumPy 模块,或者是 Python 图形库。
- 不妨假设你想设计一套统一处理声音文件和数据的模块(或者称之为一个"包")。
Python中的包(Packages)是一种用于组织和管理模块(Modules)的方法。包实际上是一个包含了多个模块的目录,该目录包含一个特殊的__init__.py文件,用于指示Python该目录应该被视为一个包。
以下是创建和使用Python包的基本步骤:
- 创建一个包目录:
首先,您需要创建一个目录,该目录将作为包的根目录。您可以为这个目录选择一个有意义的名称,比如my_package。 - 在包目录中创建模块:
在包的目录下,您可以创建多个模块文件,这些模块可以包含函数、类和变量等Python代码。模块的文件名必须以.py结尾。 - 创建
__init__.py文件:
您需要在包目录中创建一个名为__init__.py的文件,即使它是空的。这个文件用于告诉Python该目录是一个包。 - 使用包中的模块:
现在,您可以在其他Python脚本中使用这个包。例如,如果您有一个叫做module1.py的模块在my_package包中,您可以在其他脚本中这样导入它:
from my_package import module1
- 子包(可选):
您还可以在包中创建子包,即在包目录中再创建一个子目录,并在子目录中放置一个__init__.py文件。这样可以创建多层嵌套的包结构。
示例目录结构:
my_package/
__init__.py
module1.py
module2.py
subpackage/
__init__.py
submodule1.py
注意事项:
- 包名和模块名应该遵循Python的命名规则,通常使用小写字母和下划线。
- 在Python 3.3及更高版本中,
__init__.py文件不再是必需的,但仍然建议使用它以确保向后兼容性。 - 模块的导入方式可以是绝对导入或相对导入,具体取决于您的项目结构和需求。
4.5.2 模块
在Python中,模块(Module)是一个包含Python代码的单个文件。模块可以包含函数、类、变量和语句,用于组织和封装相关的代码。模块的主要目的是将代码分割成可维护和可重用的部分,以便在不同的程序中使用。
以下是关于Python模块的一些重要概念和用法:
- 导入模块:要在Python中使用模块中的代码,您需要使用
import语句将模块导入到您的脚本中。例如,要导入Python标准库中的math模块,可以这样做:
import math
- 使用模块中的函数和变量:一旦导入了模块,您可以使用点运算符(
.)访问模块中的函数、变量或类。例如,使用math模块中的sqrt函数计算平方根:
result = math.sqrt(25)
- 给模块起别名:您可以为导入的模块起一个别名,以简化使用。这在模块名很长或容易混淆时特别有用。例如:
import math as m
result = m.sqrt(25)
- 导入模块中的特定成员:如果您只需要模块中的特定函数或变量,而不想导入整个模块,可以使用
from ... import语句。例如:
from math import sqrt
result = sqrt(25)
- 自定义模块:除了使用Python标准库中的模块,您还可以创建自己的模块。创建模块就是创建一个包含Python代码的
.py文件,并确保它在您的项目目录或Python路径下可用。 - 标准库模块:Python附带了丰富的标准库,包含了许多常用的模块,如
os(操作系统交互)、datetime(日期和时间处理)、json(JSON数据处理)等。 - 第三方模块:除了标准库,Python社区还维护了大量的第三方模块和库,您可以使用工具如
pip来安装这些模块,以扩展Python的功能。
总之,模块是Python中组织代码的重要方式,它们有助于代码的组织、可维护性和重用性。了解如何使用模块是编写更结构化、模块化和可维护的Python代码的关键。
4.5.3 命名空间
在Python中,命名空间(Namespace)是一个包含变量名和它们对应的对象的映射。它用于确定在程序中查找变量名时的范围和可见性。Python中有以下几种类型的命名空间:

命名空间查找顺序:
假设我们要使用变量 runoob,则 Python 的查找顺序为:局部的命名空间 -> 全局命名空间 -> 内置命名空间。
如果找不到变量 runoob,它将放弃查找并引发一个 NameError 异常:
NameError: name 'runoob' is not defined。
- 内置命名空间(Built-in Namespace):
- 这是Python解释器默认提供的命名空间。
- 包含了Python内置的对象和函数,如
print()、len()等。 - 可以在任何地方直接访问内置命名空间的内容。
- 全局命名空间(Global Namespace):
- 在模块级别定义的变量和函数属于全局命名空间。
- 全局命名空间在整个模块中可见,也可以在不同模块之间共享。
- 在一个Python脚本或模块中,全局命名空间就是该脚本或模块的命名空间。
- 局部命名空间(Local Namespace):
- 每个函数调用都会创建一个局部命名空间。
- 局部命名空间包含函数内部定义的变量和参数。
- 局部命名空间只在函数内部可见,函数外部无法直接访问。
- 模块命名空间(Module Namespace):
- 每个模块(.py文件)都有自己的命名空间。
- 模块命名空间包含了模块级别的变量和函数。
- 模块命名空间在整个模块内可见。
- 类命名空间(Class Namespace):
- 每个类定义都有自己的命名空间,用于管理类的属性和方法。
- 类命名空间在类定义中可见。
- 类的实例可以访问类的命名空间。
- 实例命名空间(Instance Namespace):
- 每个类的实例都有自己的命名空间,用于管理实例特有的属性。
- 实例命名空间在实例化时创建,并且可以随着实例的生命周期而改变。
在Python中,命名空间的概念非常重要,它决定了变量和函数的可见性和作用域。当您使用变量时,Python会根据LEGB规则(Local、Enclosing、Global、Built-in)来查找变量,从局部命名空间开始,逐级向外查找,直到找到匹配的变量名或者达到全局和内置命名空间。
理解不同命名空间的作用和范围有助于编写更清晰、可维护的代码,避免变量名冲突,同时充分利用Python的模块化和封装特性。
4.5.4 作用域
在编程中,作用域(Scope)指的是变量的可见性和生命周期。它决定了在程序的哪些部分可以访问某个变量,并且确定了变量何时被创建和销毁。Python中有以下几种常见的作用域:
- 局部作用域(Local Scope):
- 局部作用域是最内层的作用域,通常与函数内部相关联。
- 在函数内定义的变量具有局部作用域,只能在该函数内部访问。
- 变量的生命周期从函数被调用开始,到函数执行结束时结束。
def my_function():
x = 10 # 局部作用域变量
print(x) # 可以在函数内访问
my_function()
print(x) # 会引发 NameError,x 不在全局作用域中
- 嵌套作用域(Enclosing Scope):
- 嵌套作用域与包含它们的函数的局部作用域相关联。
- 如果在函数内部嵌套了另一个函数,内部函数可以访问外部函数的变量。
- 外部函数无法访问内部函数的变量。
def outer_function():
x = 10 # 外部函数的变量
def inner_function():
y = 20 # 内部函数的变量
print(x + y) # 内部函数可以访问外部函数的变量
inner_function()
outer_function()
- 全局作用域(Global Scope):
- 全局作用域是整个程序的最外层作用域。
- 在模块级别定义的变量具有全局作用域,可以在整个模块中访问。
- 变量的生命周期从程序启动时开始,到程序退出时结束。
global_variable = 100 # 全局作用域变量
def my_function():
print(global_variable) # 可以在函数内访问全局变量
my_function()
print(global_variable)
- 内置作用域(Built-in Scope):
- 内置作用域包含了Python内置的函数和对象,如
print()、len()等。 - 这些函数和对象可以在任何地方访问,无需导入模块。
- 内置作用域的变量在Python解释器启动时创建,并在解释器退出时销毁。
print(len("Hello, World!")) # 内置作用域中的函数和对象
理解作用域是编写Python代码的关键,它有助于避免变量名冲突,提高代码的可读性和可维护性。作用域规则决定了在不同位置访问变量时,哪些变量是可见的。通常情况下,变量应尽可能在最小的作用域内定义,以减少潜在的副作用和错误。
4.6 文件
4.6.1 输出
在Python中,您可以使用不同的方法来格式化和输出文本和数据。以下是一些常用的方法和技巧:
- 使用
**print**函数:print函数是最常用的输出文本和数据的方式。您可以将字符串、变量和表达式传递给print函数,并它们将被打印到标准输出(通常是终端)。
name = "Alice"
age = 30
print("Name:", name, "Age:", age)
- 格式化字符串:Python提供了多种字符串格式化方式。一种常见的方式是使用
f-strings(在Python 3.6及更高版本中可用):
name = "Alice"
age = 30
print(f"Name: {name}, Age: {age}")
您还可以使用str.format()方法或百分号格式化符号%。
- 对齐文本:您可以使用字符串的
str.ljust()、str.rjust()和str.center()方法来对齐文本。这些方法可以用于创建美观的输出。
text = "Python"
print(text.ljust(10)) # 左对齐
print(text.rjust(10)) # 右对齐
print(text.center(10)) # 居中对齐
- 数字格式化:如果要格式化数字,可以使用字符串的
format方法或f-strings。例如,控制浮点数的小数点位数:
num = 3.14159265359
formatted_num = "{:.2f}".format(num)
print(formatted_num) # 输出 "3.14"
- 多行文本:如果要输出多行文本,可以使用三重引号(
'''或""")创建多行字符串:
multi_line_text = """
This is a
multi-line
text.
"""
print(multi_line_text)
- 转义字符:要在文本中包含特殊字符,可以使用转义字符,如
\n表示换行,\t表示制表符。
print("Hello\nWorld")
- 文件输出:除了在终端上输出,您还可以将文本写入文件。使用
open()函数打开文件,并使用文件对象的write()方法写入内容。
with open("output.txt", "w") as file:
file.write("Hello, file!")
4.6.2 键盘读取
在Python中,您可以使用内置的input()函数来从键盘读取用户输入。input()函数会等待用户输入一行文本,然后返回用户输入的内容作为字符串。
以下是使用input()函数的基本示例:
user_input = input("请输入您的名字:")
print("您输入的名字是:", user_input)
在这个示例中,input("请输入您的名字:")会显示一个提示信息(在这里是"请输入您的名字:"),然后等待用户输入。用户输入的内容会被存储在变量user_input中,然后用print函数进行输出。
需要注意的是,input()函数返回的始终是字符串,即使用户输入的是数字或其他类型的数据。如果需要将输入转换为其他类型,您可以使用适当的类型转换函数,例如int()或float()。
user_age = input("请输入您的年龄:")
user_age = int(user_age) # 将输入的字符串转换为整数
print("您的年龄是:", user_age)
请注意,input()函数会一直等待用户输入,直到用户按下Enter键。如果需要终止等待,可以通过编写适当的代码来实现,例如按下特定的键或达到某个条件。
另外,对于实际应用中的用户输入,务必要考虑错误处理和异常处理,以确保程序在用户输入不符合预期时能够正确处理。
4.6.3 File对象
open() 将会返回一个 file 对象,基本语法格式如下:
open() 方法
Python open() 方法用于打开一个文件,并返回文件对象。
在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
**注意:**使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode=‘r’)
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
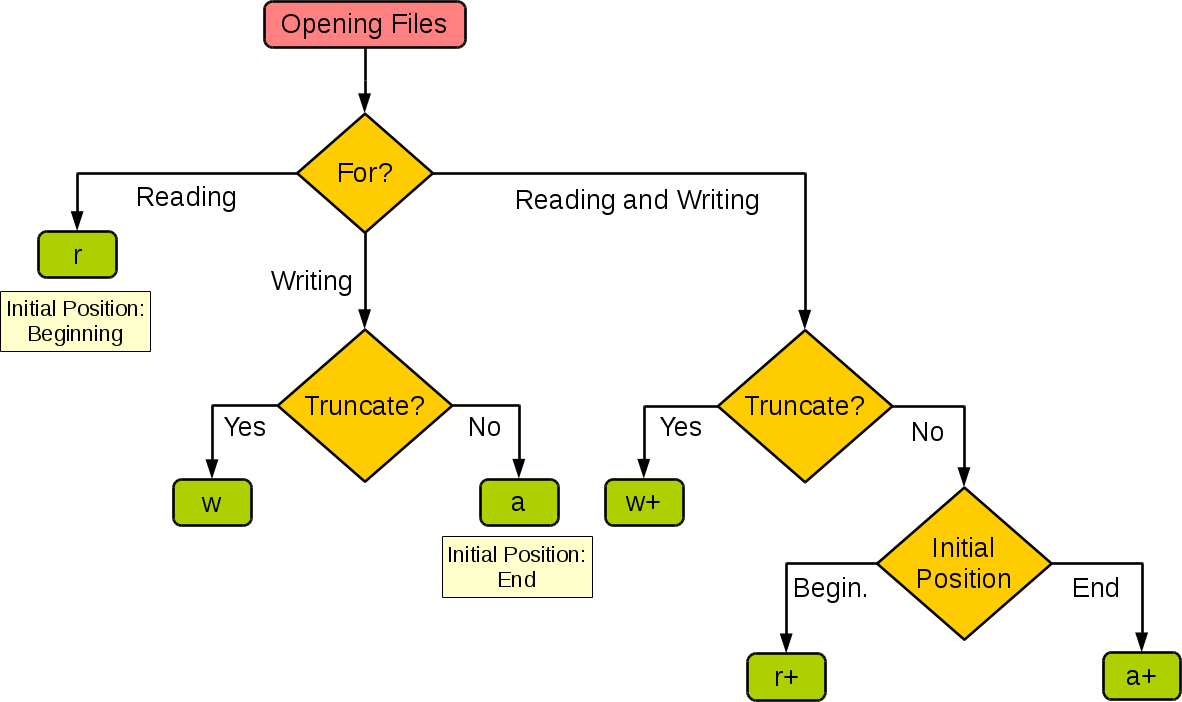
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
下图很好的总结了这几种模式:
f.read()
为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。
# ---encoding:utf-8---
# @Time : 2023/9/2 17:58
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 打开文件
# @File : OpenTest.py
if __name__ == '__main__':
file= open("../HelloWord.py", "r")
# 读取文件
print(file.read())
# 关闭
file.close()
f.write()
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数
# ---encoding:utf-8---
# @Time : 2023/9/2 18:04
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 写入文件
# @File : Write.py
if __name__ == '__main__':
# 打开一个文件
f = open("foo.txt", "w")
num = f.write("Python 是一个非常好的语言。\n是的,的确非常好!!\n")
print(num)
# 关闭打开的文件
f.close()
f.readline()
f.readline() 会从文件中读取单独的一行。换行符为 ‘\n’。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
# ---encoding:utf-8---
# @Time : 2023/9/2 18:06
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 读取某一行
# @File : ReadLine.py
if __name__ == '__main__':
file= open("../HelloWord.py", "r")
# 读取文件
print(file.readline())
# 关闭
file.close()
f.readlines()
f.readlines() 将返回该文件中包含的所有行。
如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
# ---encoding:utf-8---
# @Time : 2023/9/2 18:08
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 读取所有行
# @File : Readlines.py
if __name__ == '__main__':
file= open("../HelloWord.py", "r")
# 读取文件
print(file.readlines())
# 关闭
file.close()
f.tell()
f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。
# ---encoding:utf-8---
# @Time : 2023/9/2 18:10
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 返回文件的当前位置
# @File : Tell.py
if __name__ == '__main__':
file= open("../HelloWord.py", "r")
# 读取文件
print(file.tell())
# 关闭
file.close()
f.seek()
如果要改变文件指针当前的位置, 可以使用 f.seek(offset, from_what) 函数。
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:
- seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符
- seek(x,1) : 表示从当前位置往后移动x个字符
- seek(-x,2):表示从文件的结尾往前移动x个字符
# ---encoding:utf-8---
# @Time : 2023/9/2 18:12
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 移动文件的读取指针到指定位置
# @File : Seek.py
if __name__ == '__main__':
file= open("../HelloWord.py", "r")
# 读取文件
print(file.seek(3))
# 关闭
file.close()
总结
open()方法是Python用于打开文件的内置函数。它允许您指定文件名、文件模式以及其他可选参数,以便在程序中访问和操作文件。以下是open()方法的常见用法和参数:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
file:要打开的文件名(包括文件路径)。可以是相对路径或绝对路径。mode(可选):文件打开模式,默认为'r'(只读文本模式)。常见的模式包括:'r':只读模式(文本文件)。'w':写入模式,如果文件不存在则创建,如果存在则截断文件。'a':追加模式,如果文件不存在则创建,如果存在则在文件末尾追加。'b':二进制模式,与上述模式结合使用,如'rb'、'wb'、'ab'。
buffering(可选):缓冲策略。通常为-1,表示使用默认缓冲,或者可以设置为其他整数,表示缓冲区大小。encoding(可选):指定文件的编码方式,通常用于文本文件。例如'utf-8'。errors(可选):处理编码错误的策略,通常为'strict'(抛出异常)、'ignore'(忽略错误)等。newline(可选):用于处理换行符的方式,通常为None(根据平台自动选择)或''(不转换换行符)。closefd(可选):如果为True,则会在关闭文件时关闭底层文件描述符。opener(可选):自定义文件打开器,通常用于创建自定义文件类的实例。
示例用法:
# 打开一个文本文件以供读取
with open("example.txt", "r") as file:
content = file.read()
print(content)
# 打开一个文本文件以供写入
with open("output.txt", "w") as file:
file.write("Hello, file!")
# 打开一个二进制文件以供读取
with open("binary_data.bin", "rb") as file:
data = file.read()
# 自定义编码和错误处理方式
with open("data.txt", "r", encoding="utf-8", errors="ignore") as file:
content = file.read()
请注意,在使用open()打开文件后,应该使用with语句来确保文件在退出代码块后正确关闭。这有助于避免资源泄漏和确保文件操作的正确性。
Python中的文件对象是通过open()函数创建的,它用于与文件进行交互,包括读取和写入文件内容。以下是文件对象的一些常用方法:
**read(size=-1)**:从文件中读取指定大小的数据,如果未提供size参数或size为负数,则会读取整个文件内容。
with open("example.txt", "r") as file:
data = file.read()
**readline(size=-1)**:读取文件的一行文本,如果提供size参数,则最多读取指定大小的字符。
with open("example.txt", "r") as file:
line = file.readline()
**readlines(hint=-1)**:读取文件的多行文本,返回一个包含行的列表。如果提供hint参数,则最多读取指定数量的字符。
with open("example.txt", "r") as file:
lines = file.readlines()
**write(string)**:将字符串写入文件。如果文件以写入模式打开,则会覆盖文件内容;如果文件不存在,则创建一个新文件。
with open("output.txt", "w") as file:
file.write("Hello, file!")
**writelines(lines)**:将一个包含字符串的列表写入文件,不会自动添加换行符。
lines = ["Line 1\n", "Line 2\n", "Line 3\n"]
with open("output.txt", "w") as file:
file.writelines(lines)
**seek(offset, whence=0)**:移动文件指针到指定位置。offset表示偏移量,whence表示相对位置,默认为0(文件开头)。可以使用常量os.SEEK_SET(开头)、os.SEEK_CUR(当前位置)、os.SEEK_END(文件末尾)来设置whence。
with open("example.txt", "r") as file:
file.seek(10) # 移动到文件的第11个字符位置
**tell()**:返回文件指针的当前位置。
with open("example.txt", "r") as file:
position = file.tell()
**flush()**:刷新文件缓冲区,将缓冲区中的数据写入文件。
with open("output.txt", "w") as file:
file.write("Hello, file!")
file.flush()
**close()**:关闭文件。使用with语句可以自动关闭文件,但在某些情况下,您可能需要显式调用close()方法。
4.6.4 Os模块
os模块是Python标准库中的一个重要模块,它提供了与操作系统交互的功能,包括文件和目录操作、进程管理、环境变量等。以下是一些os模块中常用的函数和方法:
# ---encoding:utf-8---
# @Time : 2023/9/2 18:32
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site :
# @File : Os.py
import os
if __name__ == '__main__':
# 指定目录名称
new_directory = "my_directory"
# 创建新目录
os.mkdir(new_directory)
# 获取当前工作目录
current_directory = os.getcwd()
# 在新目录下创建文件
file1_path = os.path.join(new_directory, "file1.txt")
file2_path = os.path.join(new_directory, "file2.txt")
with open(file1_path, "w") as file1:
file1.write("This is file 1.")
with open(file2_path, "w") as file2:
file2.write("This is file 2.")
# 列出新目录中的文件
files_in_directory = os.listdir(new_directory)
# 打印新目录中的文件列表
print(f"Files in {new_directory}:")
for filename in files_in_directory:
print(filename)
# 获取新目录的绝对路径
new_directory_path = os.path.abspath(new_directory)
print(f"Absolute path of {new_directory}: {new_directory_path}")
# 删除新目录及其内容
os.rmdir(new_directory)
# 检查新目录是否存在
if not os.path.exists(new_directory):
print(f"{new_directory} has been deleted.")
else:
print(f"{new_directory} still exists.")
- 文件和目录操作:
os.getcwd():获取当前工作目录的路径。os.chdir(path):更改当前工作目录为指定路径。os.listdir(path='.'):列出指定目录中的所有文件和子目录。os.mkdir(path):创建一个新目录。os.makedirs(path):递归地创建多级目录。os.remove(path):删除文件。os.rmdir(path):删除目录(只能删除空目录)。os.removedirs(path):递归地删除多级目录。os.rename(src, dst):重命名文件或目录。
- 路径操作:
os.path.join(path1, path2, ...):连接路径中的各个部分。os.path.abspath(path):返回绝对路径。os.path.dirname(path):返回路径中的目录部分。os.path.basename(path):返回路径中的文件名部分。os.path.exists(path):检查路径是否存在。os.path.isfile(path):检查路径是否为文件。os.path.isdir(path):检查路径是否为目录。
- 环境变量:
os.environ:包含系统环境变量的字典。os.getenv(key, default=None):获取指定环境变量的值。
- 执行系统命令:
os.system(command):执行系统命令。
- 进程管理:
os.getpid():获取当前进程的PID。os.getppid():获取父进程的PID。
- 文件权限:
os.chmod(path, mode):修改文件权限。os.access(path, mode):检查对文件的访问权限。
- 文件信息:
os.stat(path):获取文件的状态信息,包括文件大小、创建时间等。
- 路径拆分:
os.path.split(path):拆分路径为目录和文件名。os.path.splitext(path):拆分路径为文件名和扩展名。
- 递归遍历目录:
os.walk(top, topdown=True, onerror=None, followlinks=False):递归遍历目录,返回目录路径、子目录列表和文件列表。
os模块提供了丰富的功能,可以帮助您管理文件系统、操作系统环境和进程。它是编写跨平台的Python程序时的重要工具之一,因为它允许您与底层操作系统交互,执行各种文件和系统操作。
4.7 错误与异常
作为 Python 初学者,在刚学习 Python 编程时,经常会看到一些报错信息,在前面我们没有提及,这章节我们会专门介绍。
Python 有两种错误很容易辨认:语法错误和异常。
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。

4.7.1 语法错误
Python 的语法错误或者称之为解析错,是初学者经常碰到的,如下实例
# ---encoding:utf-8---
# @Time : 2023/9/3 10:11
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 语法错误
# @File : ErrorTest.py
if __name__ == '__main__':
while True print('Hello world')
SyntaxError: invalid syntax
这个例子中,函数 print() 被检查到有错误,是它前面缺少了一个冒号 : 。
语法分析器指出了出错的一行,并且在最先找到的错误的位置标记了一个小小的箭头。
4.7.2 异常
即便 Python 程序的语法是正确的,在运行它的时候,也有可能发生错误。运行期检测到的错误被称为异常。
# ---encoding:utf-8---
# @Time : 2023/9/3 10:13
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 常见异常
# @File : ErrorTest02.py
if __name__ == '__main__':
# 算术异常
print(10/0)
# 索引异常
arr=[1,2,3,4,5,6,7,8,9,10]
print(arr[10])
# 键异常
dict={"name":"Darwin","age":18}
print(dict('hhj'))
# 类型异常
print(10+"hello")
# 值异常
print(int("hello"))
# 文件异常
f=open("hello.txt","r")
print(f.read())
4.7.3 异常处理
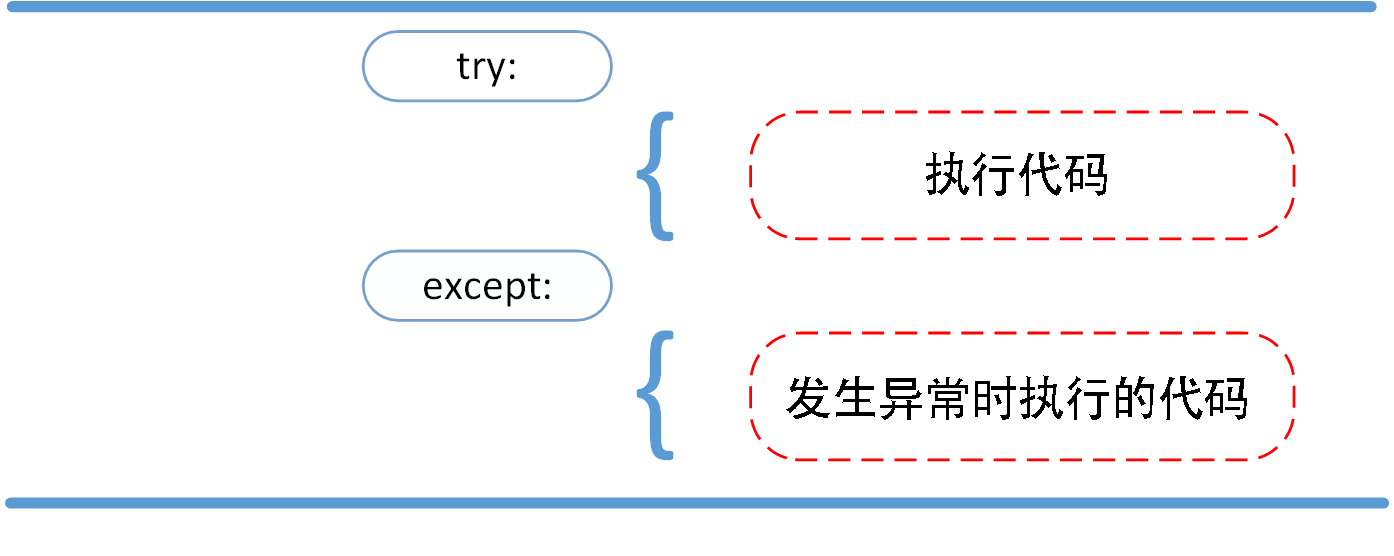
try/except
异常捕捉可以使用 try/except 语句
# ---encoding:utf-8---
# @Time : 2023/9/3 10:17
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 异常处理
# @File : ErrorTest03.py
if __name__ == '__main__':
try:
print(10/0)
except Exception as e:
print(e)
finally:
print("程序执行完毕")
try 语句按照如下方式工作;
- 首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)。
- 如果没有异常发生,忽略 except 子句,try 子句执行后结束。
- 如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。
- 如果一个异常没有与任何的 except 匹配,那么这个异常将会传递给上层的 try 中。
try/except…else
try/except 语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后,else 子句将在 try 子句没有发生任何异常的时候执行。
# ---encoding:utf-8---
# @Time : 2023/9/3 10:19
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 异常处理: try/except...else
# @File : ErrorTest04.py
if __name__ == '__main__':
try:
print(10/1)
except Exception as e:
print(e)
else:
print("程序执行完毕")

try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码

# ---encoding:utf-8---
# @Time : 2023/9/3 10:21
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : try-finally
# @File : ErrorTest05.py
if __name__ == '__main__':
# 读取文件
try:
f = open("hello.txt", "r")
print(f.read())
except Exception as e:
print(e)
finally:
if f:
f.close()
print("程序执行完毕")
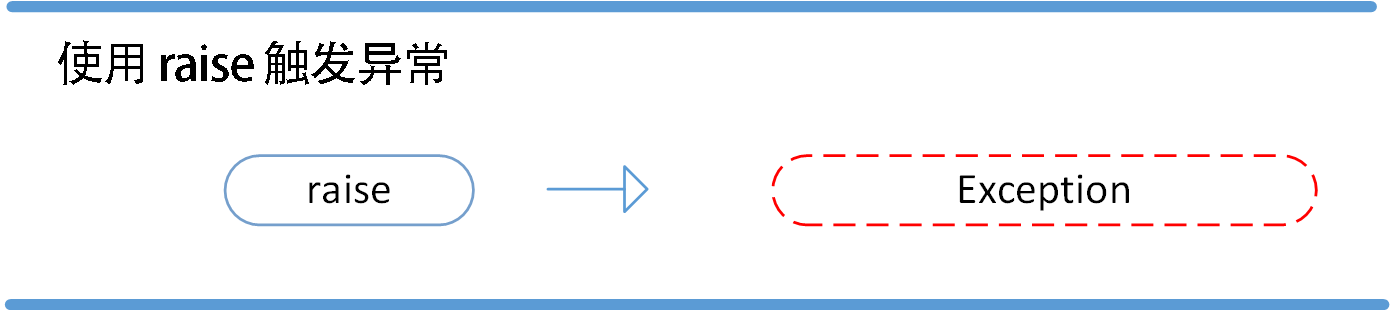
4.7.4 抛出异常
Python 使用 raise 语句抛出一个指定的异常。
# ---encoding:utf-8---
# @Time : 2023/9/3 10:24
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : raise 异常
# @File : ErrorTest06.py
if __name__ == '__main__':
try:
print(10/0)
except Exception as e:
raise e
finally:
print("程序执行完毕")
4.7.5 用户自定义异常
- 你可以通过创建一个新的异常类来拥有自己的异常。异常类继承自 Exception 类,可以直接继承,或者间接继承
# ---encoding:utf-8---
# @Time : 2023/9/3 10:26
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 自定义异常
# @File : ErrorTest07.py
# 自定义异常
class MyException(Exception):
def __init__(self, msg):
self.msg = msg
def __str__(self):
return self.msg
if __name__ == '__main__':
try:
raise MyException("自定义异常")
except MyException as e:
print(e)
finally:
print("程序执行完毕")
4.7.6 总结
Python的异常机制是一种处理程序中出现错误的方式。异常是在程序执行过程中检测到的错误或异常情况,它们可以阻止程序正常运行。Python使用try和except语句来处理异常,以下是异常处理的基本结构:
try:
# 可能会引发异常的代码
result = 10 / 0 # 这里故意引发了一个除零异常
except ZeroDivisionError:
# 处理特定类型的异常
print("除零错误发生了!")
except Exception as e:
# 处理其他类型的异常,并可以访问异常对象
print(f"发生了异常:{e}")
else:
# 如果没有异常发生,执行此块
print("没有发生异常。")
finally:
# 无论是否发生异常,都会执行此块
print("无论如何都会执行的代码块。")
上述代码示例中,程序尝试执行可能引发异常的代码块(在try块内)。如果异常发生,程序会跳转到匹配的except块进行处理。如果没有异常发生,将执行else块。最后,不管是否发生异常,都会执行finally块。
Python提供了多种内置异常类型,例如ZeroDivisionError(除零异常)、TypeError(类型错误)、ValueError(值错误)等。你可以根据需要捕获和处理这些异常,或者创建自定义异常类以处理特定情况下的异常。
4.8 类与对象
4.8.1 面向对象
Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的。
- **类(Class): **用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- **方法:**类中定义的函数。
- **类变量:**类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- **数据成员:**类变量或者实例变量用于处理类及其实例对象的相关的数据。
- **方法重写:**如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- **局部变量:**定义在方法中的变量,只作用于当前实例的类。
- **实例变量:**在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
- **继承:**即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- **实例化:**创建一个类的实例,类的具体对象。
- **对象:**通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
4.8.2 类定义
类(Class)是面向对象编程中的重要概念,它用于定义对象的模板,描述了对象的属性和方法。在Python中,类的定义通常遵循以下结构:
class ClassName:
# 类的属性
class_variable = value
# 构造函数,初始化对象的属性
def __init__(self, parameter1, parameter2, ...):
self.instance_variable1 = parameter1
self.instance_variable2 = parameter2
# 更多初始化操作
# 类的方法
def method1(self, arg1, arg2, ...):
# 方法的实现
# 可以访问实例变量和类变量
# 可以执行各种操作
def method2(self, arg1, arg2, ...):
# 另一个方法的实现
# 可以访问实例变量和类变量
# 可以执行不同的操作
让我解释一下上述代码的各个部分:
class ClassName::这是类的定义语句,用于创建一个名为ClassName的类。class_variable = value:这是类变量(或静态变量),它在类的所有实例之间共享。您可以在类中定义各种属性,它们对于该类的所有对象都是相同的。def __init__(self, parameter1, parameter2, ...)::这是构造函数,用于初始化对象的属性。构造函数会在创建对象时自动调用,通常用于将传递给类的参数分配给对象的实例变量。self.instance_variable1 = parameter1:在构造函数中,使用self来引用对象本身,然后将参数值分配给对象的实例变量。这些实例变量将在整个对象的生命周期内存储数据。def method1(self, arg1, arg2, ...)::这是类的方法,用于定义对象可以执行的操作。方法通常以self作为第一个参数,以便可以访问实例变量和其他方法。方法可以执行各种操作,包括修改实例变量、调用其他方法等。
通过定义类和类的方法,您可以创建类的实例并使用它们来执行特定的任务。例如:
# 创建类的实例
obj = ClassName(parameter1_value, parameter2_value)
# 调用对象的方法
obj.method1(arg1_value, arg2_value)
obj.method2(arg1_value, arg2_value)
# ---encoding:utf-8---
# @Time : 2023/9/3 13:30
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 类定义
# @File : Person.py
# 类的定义格式:
class Person:
# 类属性
name = ""
age = 0
# 初始化方法
def __init__(self, name, age):
self.name = name
self.age = age
# 类方法
def say(self):
print("my name is {0}, I am {1} years old".format(self.name, self.age))
# 类方法
def __str__(self):
return "my name is {0}, I am {1} years old".format(self.name, self.age)
# 类方法
def __del__(self):
print("对象被回收了")
def __new__(cls, *args, **kwargs):
print("创建对象")
return super().__new__(cls)
def __call__(self, *args, **kwargs):
print("对象被调用了")
def __getitem__(self, item):
print("获取对象的索引值")
return item
if __name__ == '__main__':
Person("Darwin", 18).say()

4.8.3 Self
在Python的类定义中,self是一个特殊的参数,用于表示对象本身。它在方法定义中作为第一个参数出现,通常被称为"self",但实际上您可以使用任何名称,尽管约定俗成的做法是使用"self"。
以下是关于self的一些重要信息和用法:
- 表示对象:
self代表了类的实例或对象本身。在类的方法内部,通过self可以访问和操作对象的属性(实例变量)和其他方法。 - 访问实例变量:通过
self,您可以访问对象的实例变量。例如,self.variable_name表示访问对象的特定实例变量。 - 调用其他方法:通过
self,您可以调用对象的其他方法。这是因为self允许您在类的方法内部引用同一对象的其他方法。 - 必须作为第一个参数:在类的方法定义中,
self必须作为第一个参数出现。这是Python的约定,用于指示该方法是对象的一部分。
以下是一个简单的示例,演示了self的使用:
class MyClass:
def __init__(self, value):
self.my_value = value # 创建实例变量
def display_value(self):
print("The value is:", self.my_value) # 访问实例变量
def update_value(self, new_value):
self.my_value = new_value # 修改实例变量
# 创建类的实例
obj = MyClass(42)
# 调用对象的方法
obj.display_value() # 输出:The value is: 42
# 更新实例变量的值
obj.update_value(99)
# 再次调用方法
obj.display_value() # 输出:The value is: 99
在上述示例中,self被用于访问和操作MyClass对象的实例变量my_value以及调用方法display_value和update_value。这种方式使您能够在类的方法中处理对象的状态和行为。
4.8.4 继承
继承是面向对象编程中的重要概念,它允许一个类(子类或派生类)从另一个类(父类或基类)继承属性和方法。Python支持类的继承,允许您创建一个新类,从一个或多个现有类派生出来,并继承其特性。
以下是关于继承的一些基本概念和示例:
- 父类和子类:在继承中,父类是被继承的类,子类是继承父类的类。
- 继承语法:在Python中,使用以下语法来创建子类并继承父类的属性和方法:
子类的定义中,将父类作为参数传递给子类的名称。 - 访问父类方法:在子类中,您可以通过使用
super()函数来访问父类的方法。这允许您在子类中扩展或修改父类的方法。 - 覆盖方法:子类可以覆盖(重写)父类中的方法,以便实现特定于子类的行为。方法覆盖是多态性的一部分。
以下是一个简单的示例,演示了继承的基本概念:
# 父类
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
pass
# 子类继承父类
class Dog(Animal):
def speak(self):
return f"{self.name} says Woof!"
class Cat(Animal):
def speak(self):
return f"{self.name} says Meow!"
# 创建子类的实例
dog = Dog("Buddy")
cat = Cat("Whiskers")
# 调用子类方法
print(dog.speak()) # 输出:Buddy says Woof!
print(cat.speak()) # 输出:Whiskers says Meow!
在上述示例中,Dog和Cat是Animal的子类,它们继承了Animal类的name属性和speak方法。然后,它们覆盖了speak方法,以实现特定于子类的行为。
- 继承允许您创建具有层次结构的类,提高代码的可重用性和组织性。
- 父类可以定义通用的属性和方法,而子类可以根据需要进行扩展或修改。
4.8.5 super函数
super()是一个内置函数,常用于在子类中调用父类的方法。在Python中,当您创建子类并希望继承父类的行为时,super()函数非常有用,它允许您在子类中调用父类的构造函数和方法。
super()函数的一般语法如下:
super().method_name(arguments)
这里是关于super()函数的一些重要信息和用法:
- 在构造函数中调用父类的构造函数:当您在子类中定义构造函数时,通常希望初始化子类特有的属性,并且还希望调用父类的构造函数来初始化从父类继承的属性。使用
super().__init__(arguments)来实现这一点。 - 在子类方法中调用父类方法:在子类中,如果您覆盖了父类的方法,但仍希望在子类方法中调用父类版本的方法,可以使用
super().method_name(arguments)来调用父类的方法。
以下是一个示例,演示了super()函数的用法:
class Parent:
def __init__(self, name):
self.name = name
def display(self):
print(f"Name: {self.name}")
class Child(Parent):
def __init__(self, name, age):
super().__init__(name) # 调用父类的构造函数
self.age = age
def display(self):
super().display() # 调用父类的方法
print(f"Age: {self.age}")
# 创建子类的实例
child = Child("Alice", 25)
# 调用子类的方法
child.display()
在上述示例中,Child类继承自Parent类,并且在构造函数和display方法中使用了super()来调用父类的构造函数和方法。这允许子类初始化自己的属性并访问父类的方法。
注意:super()函数的使用可能会根据Python版本和具体情况略有不同,特别是在多重继承的情况下。但通常情况下,它用于在子类中调用父类的方法。
4.8.6 类属性与方法
私有属性
在Python中,类的私有属性是指仅在类的内部访问的属性,外部无法直接访问。私有属性的命名约定是在属性名前面添加一个或多个下划线(例如,_private_attribute或__private_attribute)。有两种方式来定义私有属性:
- 单下划线前缀:在属性名前面加一个下划线,例如
_private_attribute。这是一种约定,用于指示该属性是私有的,但实际上仍然可以在类的外部访问。
虽然这个属性不是真正的私有属性,但它是一种向其他开发人员传达属性意图的方式。 - 双下划线前缀:在属性名前面加两个下划线,例如
__private_attribute。这种方式更严格,Python会对属性名称进行名称修饰,以防止外部直接访问。但实际上,它仍然可以通过名称修饰来访问,如_ClassName__private_attribute。
class MyClass:
def __init__(self):
self.__private_attribute = 42
obj = MyClass()
# 以下方式可以访问,但不建议这样做
print(obj._MyClass__private_attribute)
请注意,即使使用双下划线前缀也不能完全防止访问私有属性,因为Python允许通过特定的名称修饰来访问它们。然而,这是一种不建议的做法,应避免在实际代码中使用。
私有方法
在Python中,私有方法是指只能在类的内部调用,外部无法直接访问的方法。通常,私有方法的命名约定是在方法名前面加一个或多个下划线(例如,_private_method或__private_method)。虽然Python不像某些其他编程语言那样提供严格的私有方法访问控制,但是通过命名约定,可以达到限制对方法的直接访问的目的。
以下是使用命名约定创建私有方法的示例:
class MyClass:
def __init__(self):
self.public_variable = "I am a public variable"
def _private_method(self):
print("This is a private method")
def public_method(self):
print("This is a public method")
self._private_method() # 在类的内部调用私有方法
# 创建类的实例
obj = MyClass()
# 调用公共方法
obj.public_method() # 输出:This is a public method
# 调用私有方法(虽然不建议)
obj._private_method() # 输出:This is a private method
在上述示例中,_private_method被定义为私有方法,因为它的名称以单下划线开头。虽然可以从外部调用它,但是通过命名约定,它被视为私有,并且开发人员通常不应该直接访问私有方法。
虽然Python不强制限制私有方法的访问,但是开发人员通常遵循命名约定,以防止不必要的外部访问。如果要确保方法不被外部调用,可以使用更强大的封装技巧,如属性方法和属性装饰器,以提供更好的控制和封装。
类的专有方法
在Python中,类的专有方法(也称为魔法方法或特殊方法)是以双下划线开头和结尾的方法,例如__init__、__str__、__eq__等。这些方法具有特殊的含义和用途,它们定义了类在特定情况下如何行为,从而使类更加强大和灵活。
以下是一些常见的类的专有方法和它们的用途:
__init__(self, ...): 初始化方法,也称为构造函数。在创建类的实例时自动调用,用于初始化对象的属性。__str__(self): 字符串表示方法,用于返回对象的字符串表示。通常在使用str(obj)或print(obj)时调用。__repr__(self): 返回对象的可打印表示。通常在交互式解释器中直接输入对象名称时调用。__len__(self): 返回对象的长度,通常用于支持len(obj)。__getitem__(self, key): 获取对象的元素,通常用于支持索引访问,如obj[key]。__setitem__(self, key, value): 设置对象的元素,通常用于支持索引赋值,如obj[key] = value。__delitem__(self, key): 删除对象的元素,通常用于支持索引删除,如del obj[key]。__iter__(self): 返回一个可迭代对象,通常用于支持迭代。__next__(self): 定义迭代过程中的下一个值,通常与__iter__一起使用。__eq__(self, other): 定义对象相等性比较,通常用于支持obj1 == obj2。__ne__(self, other): 定义对象不相等性比较,通常用于支持obj1 != obj2。__lt__(self, other): 定义小于比较,通常用于支持obj1 < obj2。__le__(self, other): 定义小于等于比较,通常用于支持obj1 <= obj2。__gt__(self, other): 定义大于比较,通常用于支持obj1 > obj2。__ge__(self, other): 定义大于等于比较,通常用于支持obj1 >= obj2。
这些专有方法可以让您自定义类的行为,使其更符合特定的需求。例如,您可以定义__eq__方法来使两个对象的比较更有意义,或者定义__str__方法以便在打印对象时提供易于理解的输出。
示例:
class MyClass:
def __init__(self, value):
self.value = value
def __str__(self):
return f"MyClass instance with value: {self.value}"
def __eq__(self, other):
if isinstance(other, MyClass):
return self.value == other.value
return False
# 创建类的实例
obj1 = MyClass(42)
obj2 = MyClass(42)
# 使用专有方法
print(obj1) # 输出:MyClass instance with value: 42
print(obj1 == obj2) # 输出:True
4.8.7 重载
在面向对象编程中,方法重载是指在一个类中定义多个方法,这些方法具有相同的名称但不同的参数列表。在Python中,方法重载的概念与某些其他编程语言不同,因为Python不支持方法的多态参数类型,而是根据方法的名称来决定哪个方法被调用。这意味着在Python中,只有最后定义的方法会覆盖之前定义的同名方法。
以下是一个示例,演示了在Python中方法重载的原理:
class MyClass:
def my_method(self, x):
print(f"Method with one argument: {x}")
def my_method(self, x, y):
print(f"Method with two arguments: {x}, {y}")
obj = MyClass()
obj.my_method(1, 2) # 输出:Method with two arguments: 1, 2
在上述示例中,MyClass定义了两个名为my_method的方法,一个接受一个参数,另一个接受两个参数。但是,由于Python只根据方法名称来选择方法,因此最后一个定义的方法会覆盖之前的方法。
要实现真正的方法重载,您可以使用不定长参数或默认参数。例如,您可以使用默认参数来处理不同数量的参数:
class MyClass:
def my_method(self, x, y=None):
if y is None:
print(f"Method with one argument: {x}")
else:
print(f"Method with two arguments: {x}, {y}")
obj = MyClass()
obj.my_method(1) # 输出:Method with one argument: 1
obj.my_method(1, 2) # 输出:Method with two arguments: 1, 2
在这个示例中,my_method方法接受两个参数,其中y有一个默认值None,这样您可以根据参数的存在与否来执行不同的操作。这种方式允许您模拟方法重载的行为,根据传递的参数数量和类型执行不同的逻辑。
4.9 内置模块
4.9.1 OS模块
Python的os模块是用于与操作系统交互的模块,它提供了许多函数来执行与文件和目录操作相关的任务。
os模块的一些常见功能包括:
- 获取当前工作目录:
import os
current_directory = os.getcwd()
print(current_directory)
- 列出目录内容:
import os
directory_contents = os.listdir("/path/to/directory")
print(directory_contents)
- 创建目录:
import os
os.mkdir("/path/to/new/directory")
- 删除文件或目录:
import os
os.remove("/path/to/file")
os.rmdir("/path/to/directory")
- 文件重命名:
import os
os.rename("old_file.txt", "new_file.txt")
- 检查文件或目录是否存在:
import os
if os.path.exists("/path/to/file_or_directory"):
print("存在")
else:
print("不存在")
4.9.2 Sys模块
sys模块是Python的一个内置模块,它提供了与Python解释器和运行时环境相关的功能和变量。
以下是一些常见的sys模块功能:
- 获取Python解释器的版本信息:
import sys
print(sys.version)
- 获取Python解释器的版本信息以及编译信息:
import sys
print(sys.version_info)
- 获取命令行参数:
import sys
args = sys.argv
print(args)
- 设置递归深度限制(默认为1000):
import sys
sys.setrecursionlimit(1500)
- 强制刷新标准输出:
import sys
sys.stdout.flush()
- 退出Python解释器:
import sys
sys.exit()
- 获取默认的编码:
import sys
print(sys.getdefaultencoding())
sys模块通常用于获取有关Python解释器和运行时环境的信息,以及与命令行参数交互。
4.9.3 Time模块
time模块是Python的一个内置模块,它提供了与时间相关的功能,允许你在Python程序中进行时间测量、等待和处理。
以下是一些常见的time模块功能:
- 获取当前时间戳(从1970年1月1日开始的秒数):
import time
current_timestamp = time.time()
print(current_timestamp)
- 将时间戳转换为时间元组:
import time
timestamp = time.time()
time_tuple = time.localtime(timestamp)
print(time_tuple)
- 格式化时间元组为可读的字符串:
import time
time_tuple = time.localtime()
formatted_time = time.strftime("%Y-%m-%d %H:%M:%S", time_tuple)
print(formatted_time)
- 休眠(暂停执行)一段时间:
import time
time.sleep(2) # 休眠2秒
- 计算程序执行时间:
import time
start_time = time.time()
# 执行一些代码
end_time = time.time()
elapsed_time = end_time - start_time
print(f"程序执行时间:{elapsed_time} 秒")
time模块允许你在Python程序中进行时间相关的操作,包括测量、等待和格式化时间。
4.9.4 Datetime 模块
datetime模块是Python的一个内置模块,它提供了处理日期和时间的功能,允许你在Python程序中进行日期和时间的操作。
以下是一些常见的datetime模块功能:
- 获取当前日期和时间:
import datetime
current_datetime = datetime.datetime.now()
print(current_datetime)
- 获取当前日期:
import datetime
current_date = datetime.date.today()
print(current_date)
- 创建自定义日期和时间:
import datetime
custom_datetime = datetime.datetime(2023, 9, 3, 15, 30, 0) # 年、月、日、时、分、秒
print(custom_datetime)
- 格式化日期和时间为字符串:
import datetime
current_datetime = datetime.datetime.now()
formatted_datetime = current_datetime.strftime("%Y-%m-%d %H:%M:%S")
print(formatted_datetime)
- 解析字符串为日期和时间对象:
import datetime
date_string = "2023-09-03"
parsed_date = datetime.datetime.strptime(date_string, "%Y-%m-%d")
print(parsed_date)
- 计算日期差异:
import datetime
date1 = datetime.date(2023, 9, 3)
date2 = datetime.date(2023, 9, 10)
delta = date2 - date1
print(delta.days)
datetime模块允许你在Python程序中轻松处理日期和时间,包括创建、格式化、解析和计算日期差异等操作。
4.9.5 Random模块
random模块是Python的一个内置模块,它提供了生成随机数和进行随机操作的功能。
以下是一些常见的random模块功能:
- 生成随机整数:
import random
random_int = random.randint(1, 100) # 生成1到100之间的随机整数
print(random_int)
- 生成随机浮点数:
import random
random_float = random.uniform(0, 1) # 生成0到1之间的随机浮点数
print(random_float)
- 从列表或序列中随机选择元素:
import random
my_list = [1, 2, 3, 4, 5]
random_choice = random.choice(my_list)
print(random_choice)
- 随机打乱列表的顺序:
import random
my_list = [1, 2, 3, 4, 5]
random.shuffle(my_list)
print(my_list)
- 随机种子设置(用于复现随机数序列):
import random
random.seed(42) # 设置随机种子为42
random模块允许你在Python程序中生成随机数,进行随机选择和操作,以及控制随机数生成的种子。
4.9.6 Math 模块
math模块是Python的一个内置模块,它提供了许多数学函数和常量,允许你在Python程序中进行各种数学操作。
以下是一些常见的math模块功能:
- 求平方根:
import math
square_root = math.sqrt(25)
print(square_root)
- 求绝对值:
import math
absolute_value = math.fabs(-10)
print(absolute_value)
- 求对数:
import math
logarithm = math.log(100, 10) # 求以10为底的100的对数
print(logarithm)
- 求指数:
import math
exponent = math.exp(2) # 求e的2次方
print(exponent)
- 求最大值和最小值:
import math
max_value = math.max(5, 10)
min_value = math.min(5, 10)
- 进行三角函数计算:
import math
sine = math.sin(math.radians(30)) # 计算30度的正弦值
cosine = math.cos(math.radians(60)) # 计算60度的余弦值
math模块提供了许多数学函数和常量,可用于在Python程序中执行各种数学运算。
4.9.7 Re 模块
re 模块是 Python 的内置模块,用于处理正则表达式。正则表达式是一种强大的文本匹配和搜索工具,允许你在文本中查找、替换和验证模式。
以下是一些常见的 re 模块功能:
- 导入模块:
import re
- 使用正则表达式进行匹配:
import re
pattern = r'\d+' # 匹配一个或多个数字
text = '123 abc 456'
match = re.search(pattern, text)
if match:
print(match.group()) # 输出匹配的字符串 '123'
- 查找所有匹配:
import re
pattern = r'\d+' # 匹配一个或多个数字
text = '123 abc 456'
matches = re.findall(pattern, text)
print(matches) # 输出所有匹配的数字 ['123', '456']
- 替换匹配的文本:
import re
pattern = r'\d+' # 匹配一个或多个数字
text = '123 abc 456'
replaced_text = re.sub(pattern, 'X', text)
print(replaced_text) # 输出 'X abc X'
- 分割文本:
import re
pattern = r'\s+' # 匹配一个或多个空白字符
text = 'apple banana cherry'
parts = re.split(pattern, text)
print(parts) # 输出分割后的单词列表 ['apple', 'banana', 'cherry']
re 模块允许你使用正则表达式来处理文本,执行匹配、替换、查找和分割等操作。
4.9.8 Json模块
json 模块是 Python 的内置模块,用于处理 JSON(JavaScript Object Notation)格式的数据。JSON 是一种常用的数据交换格式,通常用于在不同编程语言之间传输和存储数据。json 模块允许你将 Python 数据结构转换为 JSON 格式,以及将 JSON 数据解析为 Python 数据结构。
以下是一些常见的 json 模块功能:
- 导入模块:
import json
- 将 Python 字典转换为 JSON 格式的字符串:
import json
data = {"name": "John", "age": 30, "city": "New York"}
json_string = json.dumps(data)
print(json_string)
- 将 JSON 字符串解析为 Python 字典或列表:
import json
json_string = '{"name": "John", "age": 30, "city": "New York"}'
data = json.loads(json_string)
print(data)
- 将 Python 对象保存为 JSON 文件:
import json
data = {"name": "John", "age": 30, "city": "New York"}
with open("data.json", "w") as json_file:
json.dump(data, json_file)
- 从 JSON 文件加载数据到 Python 对象:
import json
with open("data.json", "r") as json_file:
data = json.load(json_file)
print(data)
json 模块允许你在 Python 程序中轻松处理 JSON 数据,包括转换、解析和读写 JSON 格式的文件。
4.9.9 Urllib 模块
urllib 模块是 Python 的标准库之一,用于处理 URL 相关的操作,包括发送 HTTP 请求、获取网页内容、处理 URL 编码等。这个模块允许你在 Python 程序中与网络资源进行交互。以下是一些常见的 urllib 模块功能:
- 导入模块:
import urllib.request
- 发送 HTTP GET 请求并获取网页内容:
import urllib.request
url = 'https://www.example.com'
response = urllib.request.urlopen(url)
html = response.read()
print(html)
- 发送 HTTP POST 请求:
import urllib.request
import urllib.parse
url = 'https://www.example.com'
data = urllib.parse.urlencode({'param1': 'value1', 'param2': 'value2'})
data = data.encode('utf-8')
request = urllib.request.Request(url, data)
response = urllib.request.urlopen(request)
html = response.read()
- 处理 URL 编码和解码:
import urllib.parse
encoded_url = urllib.parse.quote('https://www.example.com/query?name=John Doe')
decoded_url = urllib.parse.unquote(encoded_url)
urllib 模块提供了一组工具来处理网络请求和 URL 操作。请注意,Python 3 将 urllib 分成了几个子模块,如 urllib.request、urllib.parse 等,以提供更模块化和清晰的方式来执行不同的任务。
4.10 简单练习图书管理系统
简单的图书管理系统的实现,主要功能如下:
- 定义了一个
Library类,用于管理图书馆中的书籍。 - 提供了添加书籍、删除书籍、查找书籍、修改书籍、显示所有书籍、保存书籍、加载书籍和排序书籍等功能。
- 通过文件操作,可以将书籍信息保存到名为 “book.txt” 的文本文件中,以及从该文件加载书籍信息。
- 提供了一个命令行菜单,允许用户选择不同的操作,如添加、删除、查找、修改、显示、保存、加载和排序书籍。
- 使用了
Book类来表示书籍的信息,包括书名、作者、价格、出版社、出版日期、评分、评论数和链接。
用户可以通过输入相应的操作序号来执行不同的操作,从而管理图书馆中的书籍。
- 图书类
# ---encoding:utf-8---
# @Time : 2023/9/3 19:30
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 书籍类
# @File : Book.py
class Book:
# 书籍类
def __init__(self, name, author, price, publish, date, score, comment, url):
self.name = name
self.author = author
self.price = price
self.publish = publish
self.date = date
self.score = score
self.comment = comment
self.url = url
# 重写str方法
def __str__(self):
return "书名:" + self.name + "\n作者:" + self.author + "\n价格:" + self.price + "\n出版社:" + self.publish + "\n出版日期:" + self.date + "\n评分:" + self.score + "\n评论数:" + self.comment + "\n链接:" + self.url
- Library类
# ---encoding:utf-8---
# @Time : 2023/9/3 19:32
# @Author : Darwin_Bossen
# @Email :3139066125@qq.com
# @Site : 图书类
# @File : Library.py
from Book import Book
# 图书馆类
class Library:
def __init__(self):
self.book_list = []
def __str__(self):
return str(len(self.book_list)) + "本书"
# 显示所有书籍
def showBook(self):
for book in self.book_list:
print(book)
print("--------------------------------------------------")
# 添加书籍
def addBook(self, book):
self.book_list.append(book)
# 删除书籍
def delBook(self, book):
if book in self.book_list:
self.book_list.remove(book)
print("删除成功")
else:
print("删除失败")
# 查找书籍
def findBook(self, name):
for book in self.book_list:
if book.name == name:
print(book)
return book
print("查无此书")
return None
# 修改书籍
def modifyBook(self, book):
if book in self.book_list:
self.book_list.remove(book)
self.book_list.append(book)
print("修改成功")
else:
print("修改失败")
# 保存书籍
def saveBook(self):
with open("book.txt", "w", encoding="utf-8") as f:
for book in self.book_list:
f.write(book.name + "," + book.author + "," + book.price + "," + book.publish + "," + book.date + "," + book.score + "," + book.comment + "," + book.url + "\n")
print("保存成功")
# 加载书籍
def loadBook(self):
with open("book.txt", "r", encoding="utf-8") as f:
while True:
line = f.readline()
if line == "":
break
book = line.split(",")
self.book_list.append(book)
print("加载成功")
# 排序
def sortBook(self):
self.book_list.sort(key=lambda book:book.score, reverse=True)
print("排序成功")
if __name__ == '__main__':
library = Library()
while True:
print("1.添加书籍")
print("2.删除书籍")
print("3.查找书籍")
print("4.修改书籍")
print("5.显示所有书籍")
print("6.保存书籍")
print("7.加载书籍")
print("8.排序")
print("0.退出")
num = input("请输入操作序号:")
if num == "1":
name = input("请输入书名:")
author = input("请输入作者:")
price = input("请输入价格:")
publish = input("请输入出版社:")
date = input("请输入出版日期:")
score = input("请输入评分:")
comment = input("请输入评论数:")
url = input("请输入链接:")
book = Book(name, author, price, publish, date, score, comment, url)
library.addBook(book)
elif num == "2":
name = input("请输入书名:")
book = library.findBook(name)
library.delBook(book)
elif num == "3":
name = input("请输入书名:")
library.findBook(name)
elif num == "4":
name = input("请输入书名:")
book = library.findBook(name)
if book != None:
author = input("请输入作者:")
price = input("请输入价格:")
publish = input("请输入出版社:")
date = input("请输入出版日期:")
score = input("请输入评分:")
comment = input("请输入评论数:")
url = input("请输入链接:")
book = Book(name, author, price, publish, date, score, comment, url)
library.modifyBook(book)
elif num == "5":
library.showBook()
elif num == "6":
library.saveBook()
elif num == "7":
library.loadBook()
elif num == "8":
library.sortBook()
elif num == "0":
break
- 效果
到此我们Python的基础知识就完了,下面Python的进阶知识,线程,














 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









