






目录
将jdk和hadoop安装包传到虚拟机(主从机)(使用winSCP)
一、准备文件
所用到 Hadoop3.3.1 、 JDK1.8_271 、CentOs7.x、xshell、winSCP
二、环境准备(安装CentOS7)
打开下载安装好的VMware Workstation
点击做左上角的文件->新建虚拟机->点击下一步
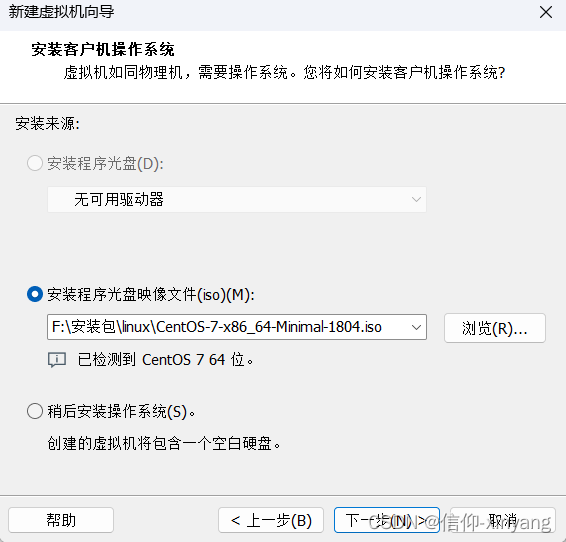
浏览选择下载好的CentOS7->下一步->
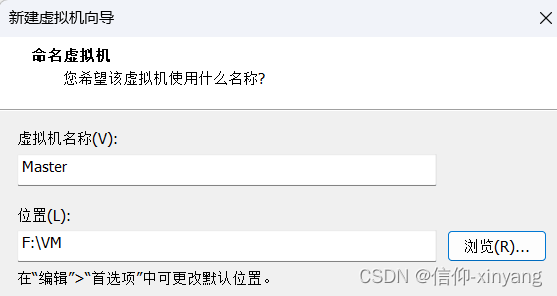
名称Master,位置自己选择一个喜欢的目录->下一步
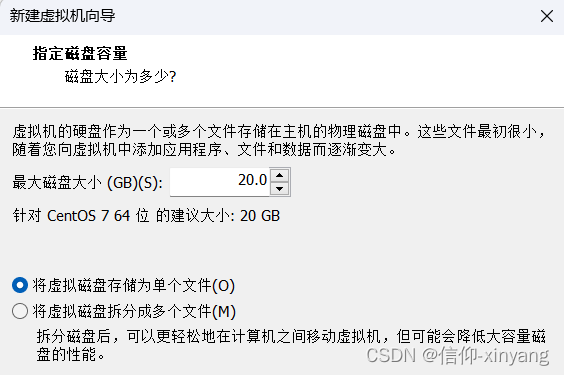
选择自己需要的大小,和储存方式->下一步->完成
安装时出现的界面点enter就行
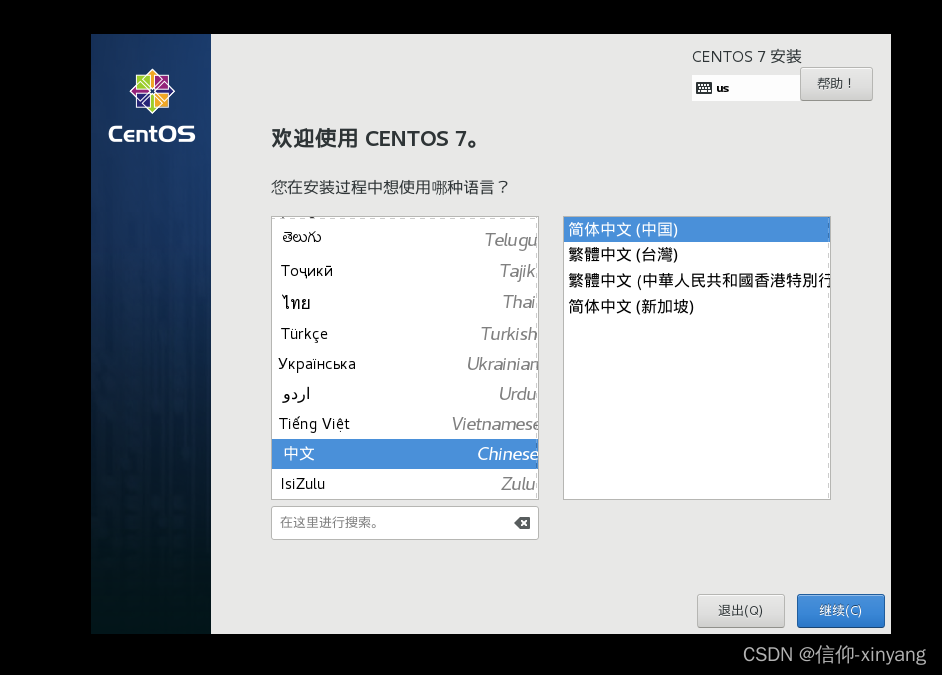
选择自己喜欢的语言,我这里选的是中文简体
选择好点击继续(下面配置网络比较重要)

安装位置选择
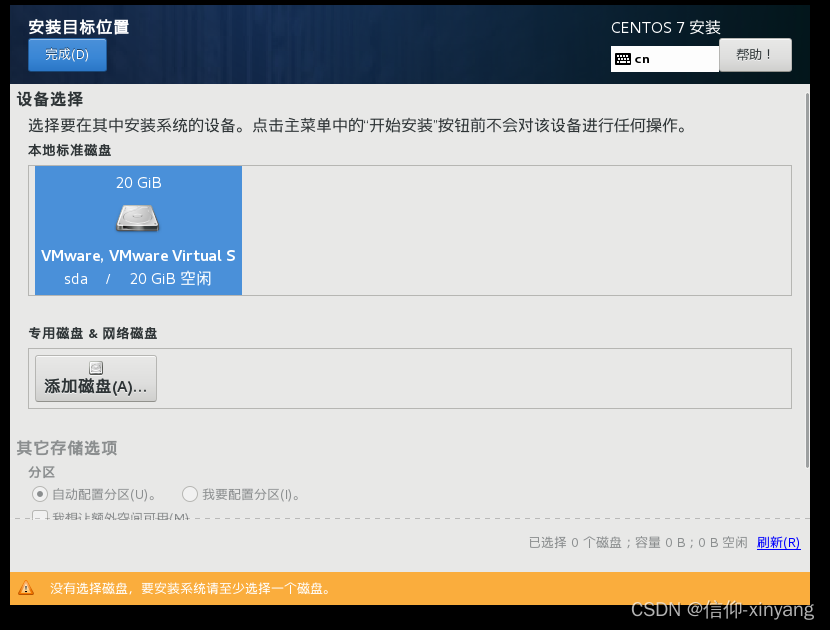
刚刚分配的20GB磁盘,点击完成
点击网络和主机(比较重要)
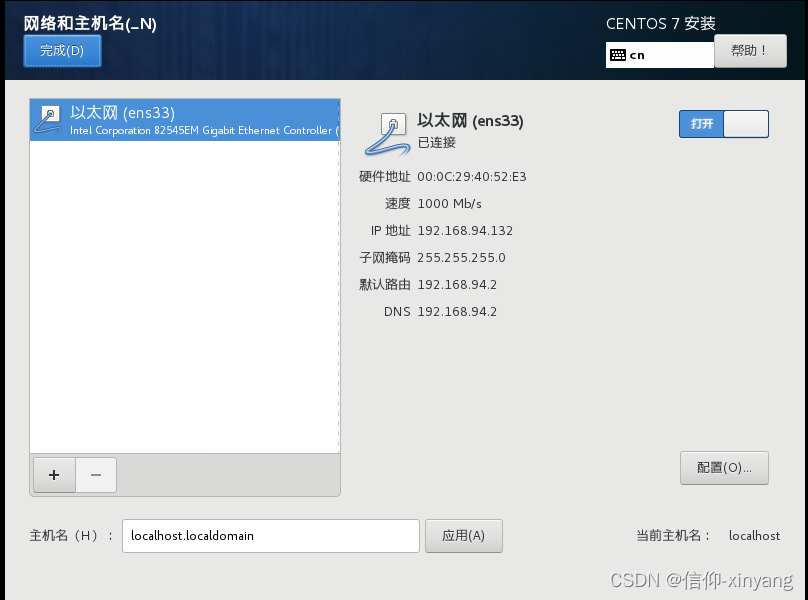
点击右边的打开,就会自动获取p地址(记住这个ip),并显示已连接,如果没链接成功,建议检查虚拟机设置,避免后面的麻烦。
然后点击完成->开始安装
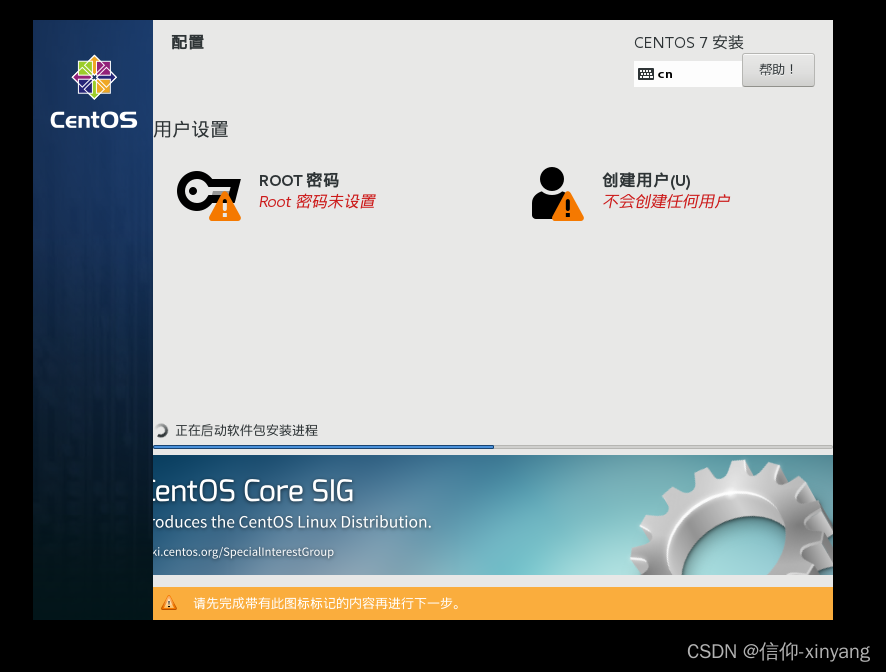
点击设置一个root密码,等待安装完成(泡杯枸杞喝,别整电脑上)
安装完成后点重启
完整完成
这里搭建一主一从,一主多从(类似)
关闭虚拟机, 选择克隆-.下一步->下一步
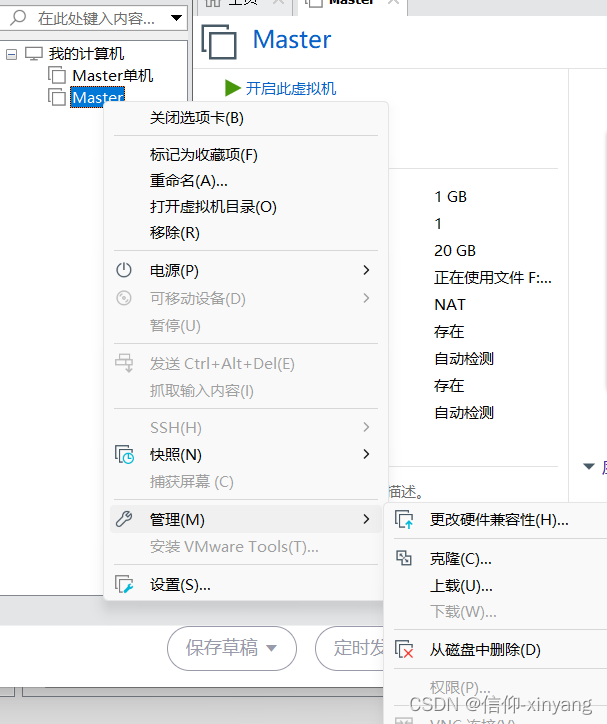
选择自己喜欢的路径点击完成(如果选择了完全克隆时间可能长一点)
完成后启动master和slave1
查看master 和 slave1的ip
ip add
使用xshell 链接虚拟机进行操作(为了方便操作),使用winSCP链接虚拟机(传文件用),
连接好下面在xshell里面进行操作。
三、主机基本设置
-
关闭防火墙(两个都关)
# 在root用户下执行
systemctl stop firewalld
systemctl disable firewalld.service- 更新源(两个都更新)
我们在下载软件时,可能会因为网络原因而下载失败,因此我们选择更新软件源,输入以下命令更新软件源:
yum -y update # 更新源
-
修改主机配置文件
vi /etc/hosts
# 添加以下内容
192.168.94.132 Master
192.168.94.133 Slave1-
修改主机名和从机名(改为Master和Slave1)
# 使用以下的命令
vi /etc/hostname-
创建用户(Master和Slave1都创建)
# 2、创建用户,在root用户下
useradd hadoop
passwd hadoop-
创建目录
cd /usr/local
# 存放安装好的软件
mkdir server
# 存放安装包
mkdir software
# 给server和software授权
chown -R hadoop:hadoop ./server
chown -R hadoop:hadoop ./software
# 其他两个节点做以上相同的操作-
配置当前非root用户具有root的权限
vi /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL-
ssh免密登录
# 在命令行输入,根据提示输入密码即可
ssh localhost
# 切换到~/.ssh目录下
cd ~/.ssh
# 输入以下命令,期间连续按三次回车
ssh-keygen -t rsa
# 分发密钥,期间在输入密码即可免密登录
ssh-copy-id Master
ssh-copy-id Slave1
# 三个节点依次按照以上命令操作,再次输入ssh 相应的主机名,已经不需要密码登录master、slave1、slave2节点了
#在Msater 主机下输入
ssh Slave1
#在Slave1下输入ssh Master
#如果不需要输入密码,则成功
#不成功重启机器,重新设置免密登录,或者检查前面设置的主机名,和地址-
将jdk和hadoop安装包传到虚拟机(主从机)(使用winSCP)
四、JDK的安装
-
卸载系统自带的JDK(主机从机都卸载)
# 查看系统自带的jdk
rpm -qa | grep jdk
#没有内容则跳过下面的操作
# 卸载找到的jdk
yum -y remove 找到的jdk
# 或者使用以下的命令删除
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps-
安装JDK(主从机)
第一步,执行下面命令进入hadoop用户
su hadoop第二步,执行以下命令解压缩JDK文件(注意:当前登录用户名是hadoop),如下所示:
cd /usr/local/software # 进入存放软件的目录
sudo mkdir -p /usr/lib/jvm # 创建/usr/lib/jvm目录用来存放JDK文件
sudo tar -zxvf jdk-8u271-linux-x64.tar.gz -C /usr/lib/jvm # 把JDK文件解压到/usr/lib/jvm目录下
JDK 文件解压成功后,可以执行以下命令进行查看:
cd /usr/lib/jvm # 进入/usr/lib/jvm目录下
ls #查看当前目录(即/usr/lib/jvm)的文件
可以看到,/usr/lib/jvm 目录下有一个 jdk1.8.0_131 目录
第三步,执行以下命令配置环境变量(注意:当前登录用户名是 hadoop),如下所示:
cd ~ # 进入用户家目录,注意:~ 等价于 /home/hadoop
sudo vi ~/.bash_profile # 编辑当前hadoop用户的环境变量配置文件(该文件只影响当前用户)
打开文件后,在文件末尾处添加以下内容( jdk 版本根据个人安装版本进行填写),保存并退出:
[hadoop@Master ~]$ sudo vi ~/.bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATH
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_271
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
~
~
~
~
~
~
~
~
~
~
~
~
~
~
"/home/hadoop/.bash_profile" 12L, 193C
继续执行以下命令使环境变量配置生效:
source ~/.bash_profile
然后可以执行以下命令查看是否安装成功:
java -version
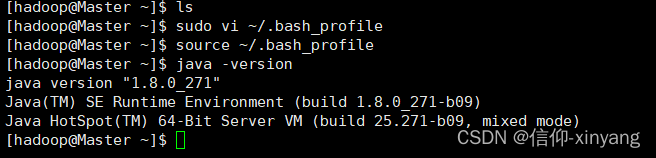
如果屏幕上返回如下信息,则说明安装成功:
五、安装 Hadoop 3.3.1
第二步,执行以下命令解压缩 hadoop3.3.1 文件(注意:当前登录用户名是 hadoop),如下所示:
cd /usr/local/software #进入安装包目录
sudo tar -zxf hadoop-3.3.1.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/ # 进入/usr/local目录下
sudo mv ./hadoop-3.3.1/ ./hadoop # 将hadoop-3.3.1文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用,输入以下命令检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop # 进入/usr/local/hadoop目录 ./bin/hadoop version # 查看hadoop版本信息

配置PATH变量
这样就可以在任意目录中直接使用hadoop、hdfs等命令了。如果还没有配置PATH变量,那么需要在Master节点上进行配置。 首先执行命令“vi ~/.bashrc”,也就是使用vi编辑器打开“~/.bashrc”文件,然后,在该文件最上面的位置加入下面一行内容:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
保存后执行命令“source ~/.bashrc”,使配置生效。
六、配置集群/分布式环境
在配置集群/分布式模式时,需要修改“
cd /usr/local/hadoop/etc/hadoop”目录下的配置文件,这里仅设置正常启动所必须的设置项,包括workers 、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml共5个文件,更多设置项可查看官方说明。
(1)修改文件workers
需要把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点),所以,在伪分布式配置时,就采用了这种默认的配置,使得节点既作为名称节点也作为数据节点。在进行分布式配置时,可以保留localhost,让Master节点同时充当名称节点和数据节点,或者也可以删掉localhost这行,让Master节点仅作为名称节点使用。
vi workers本教程让Master节点仅作为名称节点使用,因此将workers文件中原来的localhost删除,只添加如下一行内容:
Slave1
(2)修改文件
vi core-site.xml请把core-site.xml文件(<configuration>标签) 改为下面的内容)修改为如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
(3)修改文件hdfs-site.xml
对于Hadoop的分布式文件系统HDFS而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本。但是,本教程只有一个Slave节点作为数据节点,即集群中只有一个数据节点,数据只能保存一份,所以 ,dfs.replication的值还是设置为 1。hdfs-site.xml具体内容如下:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
(4)修改文件mapred-site.xml
“/usr/local/hadoop/etc/hadoop”目录下有一个mapred-site.xml.template,需要修改文件名称,把它重命名为mapred-site.xml,然后,把mapred-site.xml文件配置成如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>
(5)修改文件 yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
上述5个文件全部配置完成以后,需要把Master节点上的“/usr/local/hadoop”文件夹复制到各个节点上
七、将hadoop分发到slave1节点
Master节点上执行如下命令:
cd /usr/local
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz Slave1:/home/hadoop
然后在Slave1节点上执行如下命令:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop现在就可以启动Hadoop了,启动需要在Master节点上进行,执行如下命令:
hdfs namenode -format
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
通过命令jps可以查看各个节点所启动的进程。如果已经正确启动
















 2571
2571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











