










🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列

论文名:StickMotion : Generating 3D Human Motions by Drawing a Stickman
论文链接:https://arxiv.org/pdf/2503.04829
开源代码:暂无
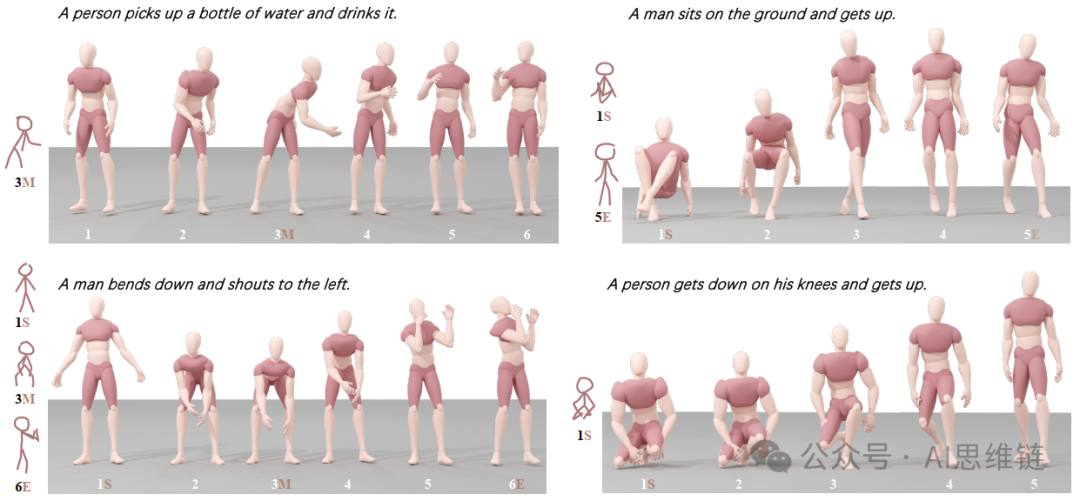
导读
文本到动作生成(Text-to-motion generation)是将文本描述转化为人类动作的技术,它一直面临着从简单文本输入中精准捕捉用户所设想的详细动作的挑战。本文介绍了StickMotion,这是一种专为多条件场景设计的高效基于扩散的网络,它能分别基于传统文本和我们提出的简笔画条件(stickman conditions)生成所需动作,实现对这些动作的全局和局部控制。我们从三个方面应对用户友好型简笔画带来的挑战:1) 数据生成。我们开发了一种算法,可跨不同数据集格式自动生成手绘简笔画。2) 多条件融合。我们提出了一个多条件模块,将其集成到扩散过程中,获取所有可能条件组合的输出,与采用自注意力模块的传统方法相比,降低了计算复杂度并提升了StickMotion的性能。3) 动态监督。我们让StickMotion能够对输出序列中简笔画的位置进行细微调整,通过我们提出的动态监督策略生成更自然的动作。通过定量实验和用户研究,绘制简笔画能为用户节省约的时间,用于生成符合他们想象的动作。我们的代码、演示和相关数据将发布,以促进科学界的进一步研究和验证。
简介
人体运动生成任务在多个不同领域有着广泛的应用,包括影视制作、虚拟现实模拟、游戏行业等等。具体而言,运动生成中热门的子任务——文本到运动任务,可以根据语言描述生成自然的人体运动序列,使动画师 无需手动为3D角色姿态设置关键帧。
方法
概述。StickMotion采用火柴人(stickman)和文本描述作为输入方式。具体而言,用户可以提供四种支持输入的任意组合,包括位于其成像运动序列起点、中间和终点附近的三个火柴人,以及附带的文本描述。例如,用户可以在提供中间火柴人的同时给出文本描述,或者选择起点和终点火柴人而不提供额外的文本信息。此外,StickMotion还允许通过实现扩散过程来控制基于文本或火柴人条件生成运动的倾向。
1. 火柴人表示法
如图1所示,使用火柴人图形避免了在生成所需的人体运动序列时进行大量文本描述的必要性。然而,解决与火柴人图形的生成、编码和应用相关的挑战也至关重要。
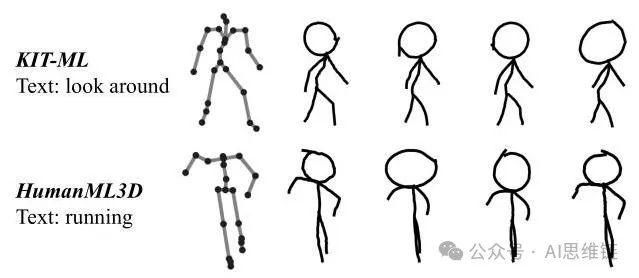
图2. 通过火柴人生成算法在KIT - ML和HumanML3D数据集上生成的火柴人。
火柴人生成算法。由于现有数据集中缺乏手绘火柴人,我们提出了一种基于现有数据集中人体关节三维坐标的火柴人生成算法(Stickman Generation Algorithm,SGA),以自动生成手绘火柴人。考虑到人类手绘的特点,我们考虑了以下几个方面:1) 笔触平滑度:笔触的平滑度受力度和个人偏好的影响。此外,不同设备上的绘制轨迹在平滑度上可能会有所不同。例如,用鼠标绘制的笔触往往比在iPad上绘制的笔触更抖动。2) 位置偏差:不可避免地,落笔失误会导致这些身体部位出现整体位置偏差。3) 缩放:手绘注重局部细节而忽略全局信息,导致不同身体部位的大小存在差异。图2展示了从不同数据集生成的火柴人。此外,从不同角度观察不同姿势时,火柴人可能看起来相似,因此我们规定,火柴人应通过从正面观察人体姿势获得,即视线大致垂直于姿势的骨盆平面。
信息编码。在处理火柴人信息时,用户便利性和高效计算之间存在权衡。为了准确重建用户的绘图,建议在用户可以自由绘制的情况下,至少收集200个(基于可视化估计)二维坐标点及其连接信息。然而,由于这些数据点之间至少通过网络进行次交互,这种方法需要大量的内存和计算资源。为了减少资源消耗,我们提出了一个指导原则,即用户应按任意顺序描绘代表头部、躯干和四肢的六条一笔画线条。每条线都单独编码,然后使用简单的变压器编码器相互交互,以获得火柴人图形的嵌入表示。这种方法在提高火柴人识别准确性的同时,有效降低了计算需求。
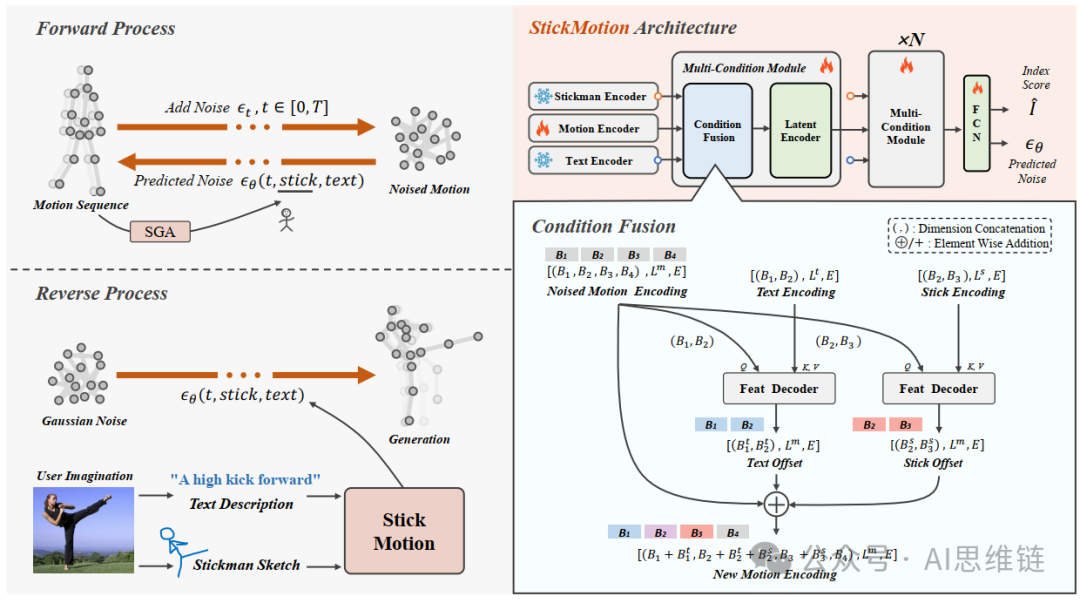
图3. StickMotion框架由左侧的扩散过程和右侧的网络结构组成。1) 扩散过程分为两个部分:前向过程和反向过程。在前向过程中,原始动作会人为地添加高斯噪声,然后输入到StickMotion中,以便它根据数据集中的文本以及通过火柴人生成算法(Stickman Generation Algorithm,SGA)由实际动作生成的火柴人来预测所添加的噪声。在反向过程中,用户的文本描述和火柴人图形会输入到StickMotion中,使其能够根据预测的噪声逐步生成动作序列。2) 关于StickMotion的结构,火柴人编码器和文本编码器保持冻结状态,而其他组件参与训练。对输入数据进行编码后,数据会经过多个多条件模块(Multi - Condition Modules,MCM)以获得噪声预测,这些预测结果随后会在反向过程中用于生成动作序列。
2. 基于扩散的动作生成
基于扩散的模型在人体运动生成领域表现出色。我们选择它作为StickMotion的基础模型,因为它可以根据文本描述或火柴人条件控制生成运动的倾向。扩散模型旨在根据从运动分布中抽取的样本估计模型分布。这里,表示StickMotion中的可学习参数。
如图3所示,扩散模型将此任务分解为前向过程和反向过程,分别涉及向实际运动添加噪声和从噪声中恢复运动。在前向过程中,高斯噪声在从到的时间间隔内逐渐添加到实际运动中,递增序列作为其权重,如公式1所示。
该公式等价于 ,其中 。通过这种方式,我们可以直接从 得到 ,而无需中间变量。上述前向过程用于 StickMotion(棍状运动)的训练。为了在推理过程中使最终生成结果在火柴人(stickman)和文本条件之间达到平衡,我们在扩散过程中采用无分类器扩散引导,并将监督公式设置为
其中 表示运动序列的长度。训练中考虑的火柴人条件表示为 (火柴人),概率为 ,而文本条件表示为 表示来自火柴人运动(StickMotion)的预测噪声。我们在训练过程中设置 。
在反向过程中,训练良好的火柴人运动(StickMotion)逐渐从 中去除噪声以获得真实的运动序列。根据去噪扩散概率模型(DDPM),可以通过公式从 中采样得到 。
其中 是来自StickMotion(StickMotion)的预测噪声, 是加权高斯噪声。在从 到 0 的逆过程中,我们可以得到偏向于不同条件组合的输出,如下所示。
遵循保留输出统计信息的原则,我们结合火柴人(stickman)和文本条件的特点,提出了一种高效的条件混合方法。首先,在时间区间的起始阶段确定近似运动序列,条件混合遵循公式。这里,1) 常数用于调整条件采样强度;2) 确保火柴人(stickman)和文本的融合协调一致。3) ,其中控制生成运动对火柴人(stickman)条件的偏好。4) 控制输出的常数分布。在最后阶段,我们设置以使用所有条件,进一步细化起始阶段得到的初步结果。最后,在逆向过程中生成与火柴人(stickman)条件和文本条件相对应的运动序列。更多细节可参见第4.3节和补充材料。
3. StickMotion架构
扩散模型为StickMotion提供了简单的训练和可控的生成过程。然而,设计一种能够在扩散过程中有效处理人体骨架(stickman)和文本条件的网络架构同样至关重要。如图3右侧所示,StickMotion包含三个输入编码器和多条件模块(Multi - Condition Modules,MCM),用于生成运动序列的最终预测噪声和人体骨架索引分数。输入编码器将含噪运动、文本和人体骨架转换为向量,随后将这些向量输入到多条件模块中,以在多种条件组合下生成最终输出,即(文本)、(文本,人体骨架)、(人体骨架)和(无)。
输入。输入数据由含噪运动序列、火柴人图形和文本组成,它们分别被编码为和的形式。这里,表示输入编码的长度,表示编码中每个标记的维度。我们采用一个简单的线性层对运动序列进行编码。我们使用CLIP ViT - B/32进行文本编码,它包含个参数。对于火柴人图形,我们使用一个具有六个编码器层的标准Transformer编码器。然而,根据实验结果,我们发现对火柴人编码器进行预训练并冻结其参数能显著提升StickMotion的性能。因此,我们为火柴人条件训练了一对自编码器模型:一个火柴人编码器和一个特征到姿态解码器。火柴人编码器将火柴人编码为特征嵌入。同时,特征到姿态解码器从这个特征向量中重建原始姿态,以确保姿态信息得以保留。
多条件模块。条件组合对于融合这些条件的扩散过程至关重要。这些组合通过StickMotion中的多条件模块(Multi - Condition Module,MCM)来实现。在每个MCM中,使用条件融合模块将火柴人(stickman)和文本条件纳入潜在空间中的运动编码。随后,修改后的运动编码由潜在编码器进行重新编码以实现进一步融合。具体而言,我们沿着批次维度将所有数据划分为四个片段,代表文本和火柴人条件的四种组合,即(文本)、(文本,火柴人)、(火柴人)和(无)。如图3所示,在条件扩散中,两个名为特征解码器(Feat Decoder)的标准Transformer解码器层分别仅考虑批次和的文本输入和火柴人输入。通过沿着批次维度将这些预测偏移量与其对应的运动编码相加,如图3所示,我们仅使用两个特征解码器就获得了三种条件组合的新运动编码。随后,新的运动编码在潜在编码器中进行重新编码以促进进一步的信息融合。与使用自注意力模块通过对条件输入进行部分掩码操作来完成所有条件组合的传统方法相比,MCM降低了计算复杂度并提升了StickMotion的性能,如4.3节所示。此外,我们在特征解码器和潜在编码器中都采用了高效注意力机制以进一步降低计算复杂度。
输出。StickMotion会为有噪声的动作输出预测噪声,并为输入火柴人的位置输出索引分数。索引分数对于火柴人的用户交互和训练监督至关重要:1) 在训练过程中,索引分数可以明确地监督并最小化动态分配的姿势与火柴人之间的距离,从而使结果更接近第3.4节中所呈现的火柴人。2) 索引分数指示了生成的动作序列中火柴人的位置,使用户能够自由决定是否朝着火柴人形象或文本描述的方向调整生成结果。
4. 动态监督
与以往的工作不同,StickMotion在确定生成的动作序列的火柴人索引时面临着额外的挑战。允许用户手动指定每个火柴人的索引会给他们带来额外的负担,让他们去考虑合适的索引,由于多个火柴人形象的位置设置不当,可能会导致生成结果不够自然。为了解决这个问题,我们指定了三个位置,即起始、中间和结束位置,用户可以从中选择。网络将动态调整这些指定位置附近火柴人的索引,以优化生成结果的自然度并使其符合文本描述。
具体而言,我们首先分别在范围(其中表示运动序列的长度)内的起始、中间和结束位置随机采样人体姿态。然后,我们为每个火柴人随机创建一个掩码,以模拟用户的随机输入。整体损失函数分为以下两部分。
(5)
在生成的运动序列中,第 帧的火柴人预测索引得分记为 。第 帧的最高得分表明 StickMotion 认为输入的火柴人属于该特定帧。 指的是在 (火柴人,文本) 和 (火柴人,) 条件组合下生成的运动序列。在第 帧,所有条件组合下的预测姿态记为 。这里, 表示真实运动序列在第 帧的姿态,而火柴人是通过火柴人生成算法由真实运动序列中的姿态 生成的。这样, 确保输出序列中得分最高的指定姿态 受到真实姿态 的监督。起始、中间和结束火柴人的监督分别记为 和 。如公式 2 所示,StickMotion 中扩散过程的监督用 表示。
实验
实验设置
数据集与指标。我们在两个人体运动生成领域的重要数据集上进行了实验,即KIT - ML数据集和HumanML3D数据集。我们采用了Guo等人的相同评估方法,以便能够与现有的文本到运动生成方法进行全面比较。该评估方法包括通过预训练的对比量化评估模型将输入文本和生成的运动序列编码为嵌入向量,然后参与计算以下指标。 精确率。给定一个预测的运动序列,将其对应的文本与测试集中的其他31个不相关文本组合成一个集合,然后通过预训练的运动 - 文本对比模型计算该运动序列与文本集合之间的前k准确率。弗雷歇 inception 距离(Frechet Inception Distance,FID)。通过对比模型分别从真实运动序列和生成的运动序列中生成运动嵌入向量,然后计算这两批嵌入向量分布之间的差异。FID与生成质量相关,但受对比模型性能的限制。多模态距离(Multimodal Distance,MM Dist)。运动嵌入向量与其文本嵌入向量之间的欧几里得距离。 多样性。生成的运动序列的可变性和丰富度。多模态性。给定指定文本时生成的运动序列的方差。
实现细节。StickMotion使用4块A800 GPU进行训练,批量大小为1024,同时采用80个数据加载器工作进程通过SGA生成火柴人。对于扩散过程,我们将噪声步数设为。并且的范围是从0.9999到0.9800。可训练的StickMotion模型在KIT - ML数据集上包含四个MCM(多组件模块,Multi - Component Module),在HumanML3D数据集上包含五个MCM,参数数量分别为和。
2. 定量分析
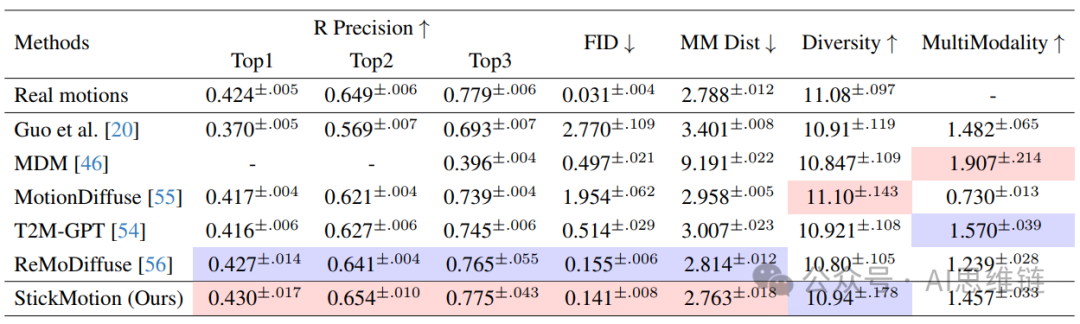
与最先进方法的比较。我们采用与文本到动作方法相同的评估方式,基于KIT - ML数据集和HumanML3D数据集来展示StickMotion的性能。此外,评估中使用的简笔画生成方法与第3.4节中描述的训练过程类似,并且使用了真实序列三个位置的所有简笔画。与传统方法不同,StickMotion需要同时与文本描述和简笔画图形对齐。如第4.3节所述,这两个条件存在对抗关系,可能会对StickMotion的性能产生负面影响。因此,我们通过设置和 来调整第3.2节中提到的反向过程,使生成结果更倾向于简笔画条件。如表1和表2所示,与以往的文本到动作工作相比,我们的方法表现出色。然而,评估生成的动作中融入了多少简笔画信息至关重要。因此,我们提出了一种名为简笔画相似度的新指标,将在下文进行讨论。
表1. 在HumanML3D测试集上的比较。我们将最佳结果标记为红色,将次佳结果标记为蓝色
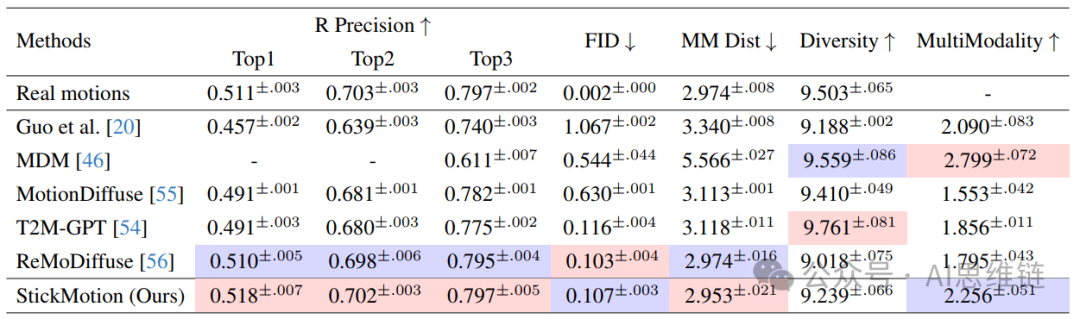
表2. KIT - ML测试集上的比较。
新指标:火柴人相似度(StiSim)。在评估中,火柴人是通过从真实序列中采样一个姿态生成的,而生成序列中的相应姿态则由StickMotion生成的索引分数确定。因此,采样的真实姿态与索引分数最高的生成姿态之间的欧几里得距离(称为火柴人距离,StickmanDistance)表明了StickMotion从输入火柴人中学到了多少。此外,我们使用平均距离(MeanDistance)来表示采样的真实姿态与所有生成姿态之间欧几里得距离的平均值。因此,火柴人相似度(StickmanSimilarity,StiSim)可以计算为1 - (火柴人距离 | 平均距离)。对于HumanML3D数据集和KIT - ML数据集,火柴人距离、平均距离和火柴人相似度的值分别为(0.24, 和 )。
3. 消融研究
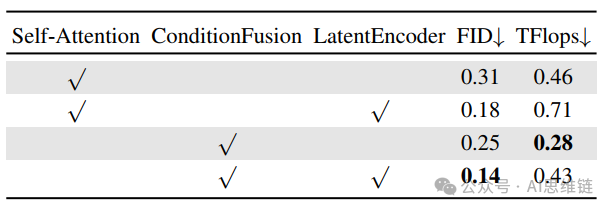
StickMotion模块分析。我们首先使用KIT - ML数据集对多条件模型(Multi - Condition Model,MCM)中的条件融合(Condition Fusion)和潜在编码器(Latent Encoder)模块进行消融实验。我们用传统的自注意力机制替换条件融合模块,同时确保MCM仍然支持多条件组合。此外,我们计算了批量大小为的MCM的浮点运算次数(Flops)。如表3所示,与通过掩码操作使用自注意力模块进行条件组合的传统方法相比,结合条件融合和潜在编码器能取得更好的性能,因为传统方法在为掩码条件计算注意力时会引入不必要的计算。
表3. 训练/前向传播过程中条件融合和潜在编码器的消融研究。
条件混合分析。如公式4所示,条件混合控制如何根据人体骨架(stickman)和文本条件的四种组合来混合输出,从而使生成的输出偏向于人体骨架或文本。(接下来将讨论三个不同位置人体骨架的组合,因为在本节中我们仅从更宏观的层面关注这些条件。)如3.2节所述,决定了在逆向过程的初始阶段,粗略生成结果偏向于人体骨架条件的程度。在这里,在最后阶段根据这些条件组合对这些粗略生成结果进行细化。根据表4,人体骨架条件和文本条件之间存在对抗关系。
表4. 推理/逆向过程中条件混合的消融研究。
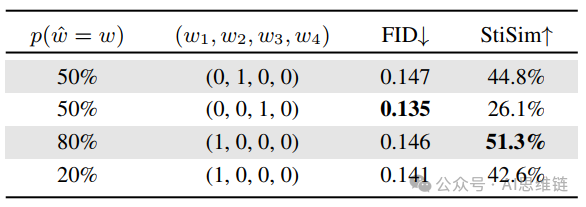
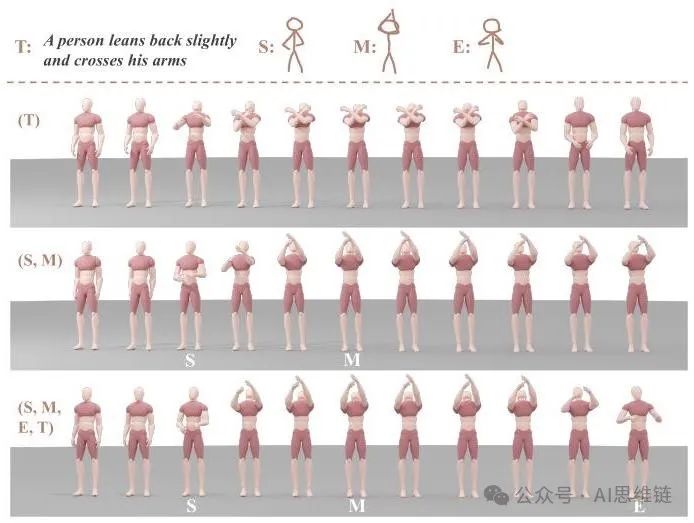
图4. 各种输入组合的可视化。
输入组合分析。用户可以提供多种输入组合,包括文本描述以及位于运动序列不同阶段(开始、中间或结束)的三个简笔人物。在和设置下,这些组合的生成质量可在表5中观察到。需要注意的是,文本描述对StickMotion(简笔人物运动生成系统)的性能影响最为显著,因为文本到运动的评估仅考虑生成的运动序列的语义信息。我们还在图4中展示了部分组合的可视化结果。
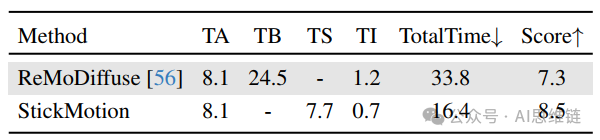
用户研究。我们招募了20名无关联的志愿者参与StickMotion和传统文本到动作生成工作ReMoDiffuse的用户研究。这些参与者被要求想象一个持续约10秒(相当于120帧)的特定人类动作,然后提供一个整体文本描述(A)、详细文本描述(B),以及一个代表想象动作中特征姿势的简笔人物图(S)。将(A,B)组合输入到ReMoDiffuse中,而将(A,S)组合输入到StickMotion中。然后,参与者对两种方法生成的结果进行0到10分的评分。关于时间消耗和用户评分的最终结果如表6所示,可视化结果如图5所示。我们的StickMotion在生成与用户想象一致的动作时,为用户节省了约51.5%的时间。
表5. 生成过程中条件组合的消融研究。有四个输入,包括处于“起始”“中间”和“结束”位置的简笔人物图以及文本描述。
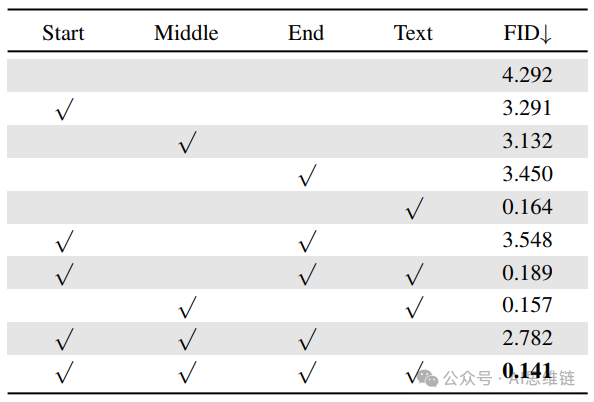
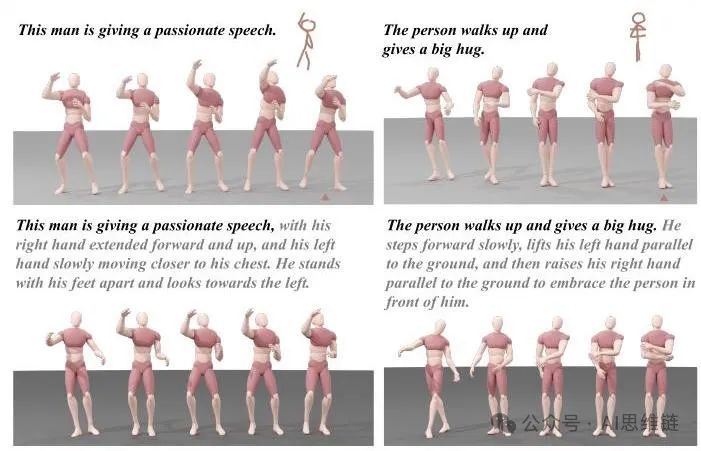
图5. StickMotion(上)的整体描述与火柴人对比,以及ReMoDiffuse(下)的详细描述对比。
表6. 火柴人及文本到运动任务与文本到运动任务的对比。“TA”和“TB”分别代表整体描述和详细描述的时间成本,而“TS”表示绘制火柴人所需的时间。此外,“TI”代表所使用模型的推理时间。条件模块,用于创建与文本描述和火柴人条件相匹配的运动序列,同时保持较低的计算复杂度。最后,我们提出了一种新的StiSim指标,用于在传统的文本到运动评估中衡量火柴人的相似度。我们的目标是为文本到运动生成贡献一种新型火柴人条件,并为多条件场景提供一个多条件模块,简化并加速创作者获取所需人体运动的过程。
总结
本文提出了一种新颖的线条人条件,用于通过简单的文本描述来满足用户对身体姿势的详细要求。为了有效利用线条人条件,我们最初开发了一种基于现有数据集中关节位置生成手绘线条人的算法。随后,我们引入了 StickMotion,这是一种基于扩散的方法,并结合多条件模块,创建与文本描述和线条人相一致的运动序列,同时保持较低的计算复杂性。最后,我们提出了一种新的 StiSim 指标,用于衡量传统文本到运动评估中的线条人相似性。我们的目标是将一种新颖的线条人条件贡献给文本到运动生成,并为多条件场景提供一个多条件模块,从而简化和加速创作者获取所需人类运动的过程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









