






🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列

论文名:Personalize Anything for Free with Diffusion Transformer
论文链接:https://arxiv.org/pdf/2503.12590
开源代码:https://fenghora.github.io/Personalize-Anything-Page/

导读
个性化图像生成旨在生成用户指定概念的图像,同时实现灵活编辑。近期的免训练方法虽然比基于训练的方法具有更高的计算效率,但在身份保留、适用性以及与扩散变压器(DiT)的兼容性方面存在困难。在本文中,我们发掘了 的未被开发的潜力,即简单地用参考主体的去噪令牌替换原有令牌,就可以实现零样本主体重建。这种简单而有效的特征注入技术开启了从个性化到图像编辑的各种场景。基于这一观察,我们提出了“个性化任何内容”(Personalize Anything),这是一个免训练框架,通过以下方式在DiT中实现个性化图像生成:1)时间步自适应令牌替换,通过早期注入来确保主体一致性,并通过后期正则化增强灵活性;2)补丁扰动策略以提高结构多样性。我们的方法无缝支持布局引导生成、多主体个性化和掩码控制编辑。评估表明,该方法在身份保留和通用性方面达到了最先进的性能。我们的工作为DiT提供了新的见解,同时为高效个性化提供了实用范式。
简介
个性化图像生成旨在合成用户指定概念的图像,同时实现灵活编辑。文本到图像扩散模型的出现彻底改变了这一领域,使其在广告制作等领域得到应用。
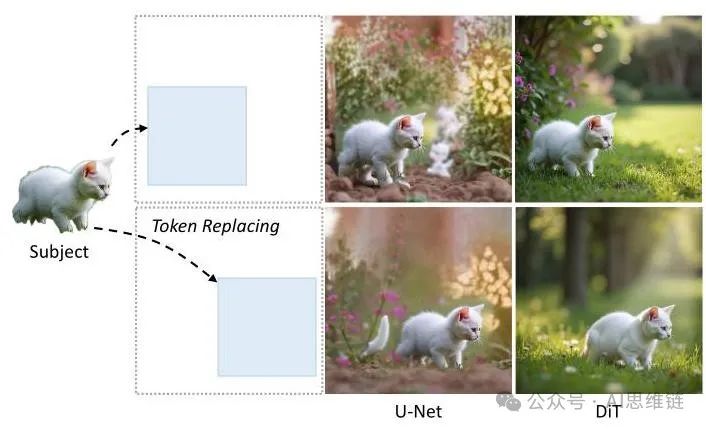
图2. DiT(右)中的简单标记替换通过其位置解耦表示实现了高保真度的主体重建,而U-Net的卷积纠缠(左)导致边缘模糊和伪影。
方法
本文介绍了一种使用扩散变换器(DiTs)进行个性化生成的免训练范式,该范式在保留文本可控性的同时,能够合成用户指定概念的高保真描绘。在接下来的章节中,我们首先概述文本到图像扩散模型的标准架构。第3.2节系统地揭示了阻碍现有注意力共享机制应用于扩散变换器的架构差异。第3.3节通过简单的令牌替换揭示了扩散变换器在主题重建方面的潜力,最后在第3.4节介绍了我们的“个性化一切”框架。
1. 预备知识
扩散模型通过网络 逐步对潜在变量 进行去噪,架构选择至关重要。我们分析了两种主要范式:
U型网络架构。稳定扩散(Stable Diffusion)中的卷积U型网络由成对的下采样和上采样块组成,中间由一个中间块连接。每个块将用于特征提取的残差块与用于捕捉空间关系的空间注意力层交错排列。
扩散变换器(DiT)。先进模型中的现代扩散变换器利用变换器处理离散化的潜在表示,包括图像令牌 和文本令牌 ,其中 是嵌入维度, 和 是序列长度。这些模型通常通过旋转位置编码(RoPE)对 的位置信息进行编码,该编码基于令牌在 网格中的坐标 (i,j) 应用旋转矩阵:
其中 表示位置 (i,j) 处的旋转矩阵, 和 。文本令牌 接收固定的位置锚点 以保持模态区分。然后将多模态注意力机制(MMA)应用于所有经过位置编码的令牌 ,实现跨两种模态的全双向注意力。
2. 扩散变换器中注意力共享失败
我们系统地研究了为什么现有的基于U型网络的个性化技术在简单地应用于扩散变换器架构时会失败,确定位置编码冲突是核心挑战。
位置编码冲突。在扩散变换器中实现现有方法的注意力共享时,我们将经过位置编码的去噪令牌 和参考令牌 (通过流反转获得)连接成一个统一的序列 。两种令牌都保留了原始位置 ,这对注意力计算造成了破坏性干扰。如图3a所示,这迫使去噪令牌过度关注具有相同位置的参考令牌,导致生成图像中出现参考主题的重影伪像。补充材料中的定量分析表明,扩散变换器中相同位置的去噪令牌和参考令牌之间的注意力得分比U型网络高723%,证实了扩散变换器对位置的敏感性。
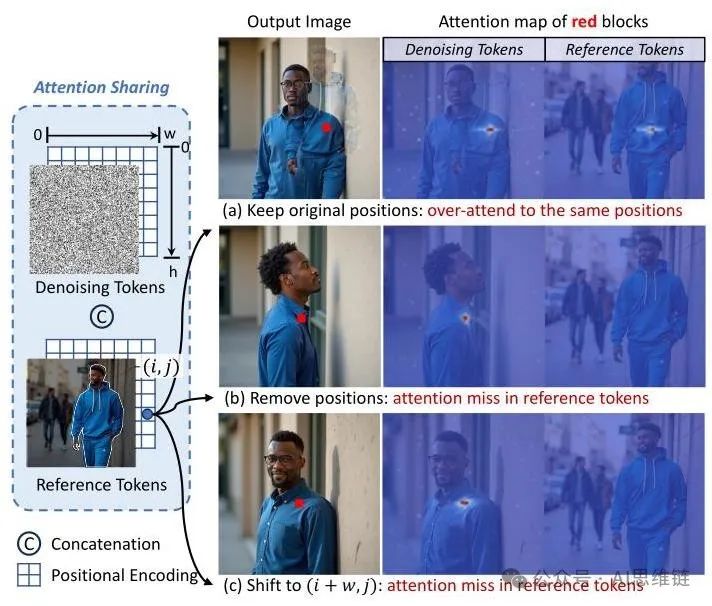
图3. 由于显式位置编码机制,注意力共享在DiT(扩散变压器,Diffusion Transformer)中失效。当在参考令牌中保留原始位置 时,去噪令牌会过度关注具有相同位置的参考令牌(如 (a) 的注意力图所示),从而在生成的图像中产生重影伪像。改进的策略,(b) 移除位置和 (c) 转移到非重叠区域,避免了冲突,但失去了身份对齐,因为参考令牌上几乎没有注意力。
改进的编码策略。受DiT(扩散变压器,Diffusion Transformer)的位置解缠编码(第3.1节)的启发,我们对 进行了两种位置调整,以获得无冲突的 :i) 移除位置并将所有参考位置固定为 (0,0),类似于文本令牌;ii) 将参考令牌转移到 ,创建非重叠区域。如图3 (b) 和 (c) 所示,虽然消除了冲突,但这两种方法都难以保留身份,因为参考令牌上几乎没有注意力。
综上所述,显式编码的位置信息对DiT(扩散变压器,Diffusion Transformer)中的注意力机制有很大影响,这与U-Net的隐式位置处理有根本区别。这使得生成的图像在传统的注意力共享中难以正确关注参考对象的令牌。
3. DiT(扩散变压器,Diffusion Transformer)中的令牌替换
基于对DiT(扩散变压器,Diffusion Transformer)架构差异的基础观察,我们将研究扩展到DiT中的潜在表示。我们发现,简单地用参考对象的令牌替换去噪令牌可以实现高保真的对象重建。
具体来说,我们对参考图像应用反演技术,获得没有编码位置信息的参考令牌 ,以及参考对象的掩码 。然后,我们通过令牌替换将 注入去噪令牌 的特定区域 :
其中 可以通过平移 获得。如图2所示,DiT(扩散变压器,Diffusion Transformer)中的令牌替换可以在指定位置重建具有一致对象的高保真图像,而U-Net的卷积纠缠表现为边缘模糊和伪像。
我们将此归因于DiT(扩散变压器,Diffusion Transformer)中通过其显式位置编码机制(第3.1节)实现的位置信息的单独嵌入。这种语义特征和位置的解耦使得可以替换纯语义令牌,避免了位置干扰。相反,U-Net的卷积机制将纹理和空间位置绑定在一起,在替换令牌时会导致位置冲突,从而导致低质量的图像生成。这一发现确立了令牌替换作为DiT中零样本对象个性化的可行途径。它开启了从个性化到图像修复和图像扩展等各种场景,无需复杂的注意力工程,并为我们在第3.4节中的个性化框架奠定了基础。
4. 任意对象个性化
基于这些发现,我们提出了“任意对象个性化”(Personalize Anything),这是一种用于扩散变压器(DiTs)的新型免训练个性化方法。该框架受DiTs中零样本对象重建的启发,并通过时间步自适应令牌替换和补丁扰动策略(图4)有效提高了灵活性。
时间步自适应令牌替换。我们的方法首先对包含所需对象的参考图像进行反演。这个过程产生参考令牌 (不包括位置编码)和相应的对象掩码 。与对象重建中在去噪过程中持续注入不同,我们引入了一种依赖时间步的策略:
-
通过标记替换(token replacement)进行早期主体锚定 。在初始去噪步骤 中(其中 是一个经验确定的阈值,设置为总去噪步骤 的 ),我们通过用参考标记 替换主体区域 内的去噪标记 来锚定主体的身份(公式 (2))。区域 可以通过将 平移到用户指定的位置来获得。我们保留与去噪标记 相关的位置编码,以保持空间连贯性。
2 通过多模态注意力(multi-modal attention)进行后期语义融合 。在后期去噪步骤 中,我们过渡到语义融合。在这里,我们将零位置参考标记 与去噪标记 和文本嵌入 连接起来。统一序列 经过多模态注意力(MMA)处理,以协调主体引导与文本条件。这个自适应阈值 平衡了主体身份的保留和文本提示所提供的灵活性。
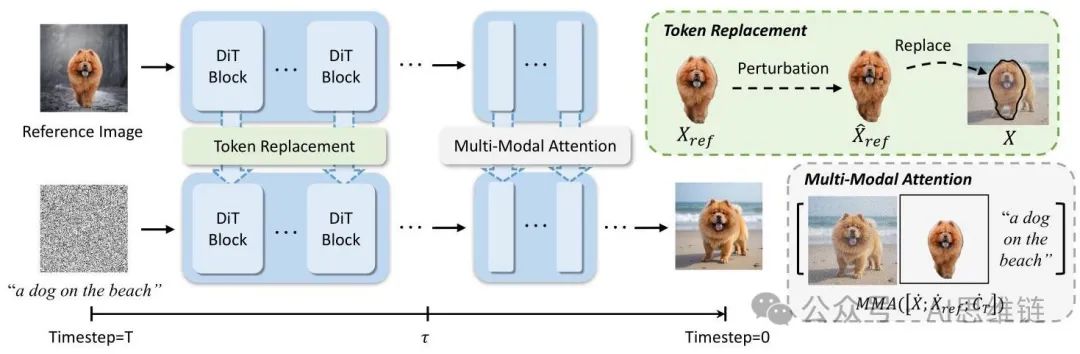
图 4. 方法概述。我们的框架在早期去噪过程中通过掩码引导的标记替换(保留位置编码)来锚定主体身份,并在后期步骤中过渡到多模态注意力以实现与文本的语义融合。在标记替换期间,我们通过块扰动(patch perturbation)注入变化。这种时间步自适应策略平衡了身份保留和生成灵活性。
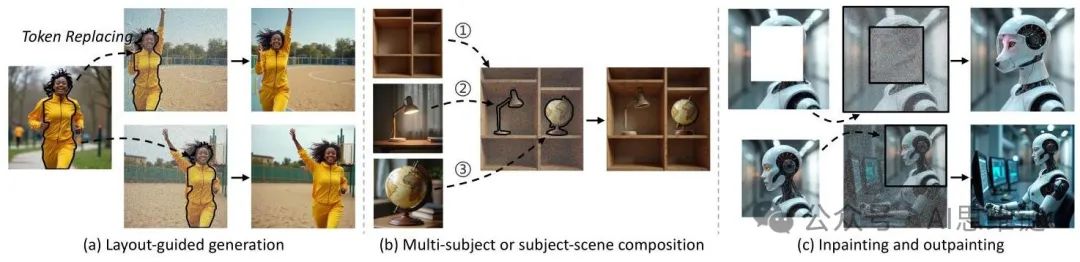
图 5. 无缝扩展。我们的框架支持:(a) 通过平移注入标记的区域进行布局引导生成,(b) 通过顺序注入标记进行多主体组合,以及 (c) 通过指定掩码和增加替换进行图像修复和扩展。
用于引入变化的块扰动(Patch Perturbation)。为了在保留身份一致性的同时防止身份过拟合,我们引入了两种互补的扰动:1) 在 窗口内进行随机局部标记洗牌,以破坏刚性纹理对齐;2) 对 进行掩码增强,包括使用 内核进行形态学膨胀/腐蚀来模拟自然形状变化,或手动选择强调身份的区域。这种局部干扰技术的理念是鼓励模型引入更多全局纹理特征,同时增强结构和局部多样性。
无缝扩展。如图 5 所示,我们的框架通过几何编程自然地扩展到复杂场景:平移 可以实现主体的空间排列,从而实现布局引导生成,而将多个 顺序注入不相交的 区域并进行统一的多模态注意力 处理有助于多主体或主体 - 场景组合。对于图像编辑任务,我们在反转过程中纳入用户指定的掩码,以获得应保留的参考 和 。同时,我们禁用扰动并将 设置为总步骤的 ,尽可能保留原始图像内容,实现连贯的图像修复或扩展。
实验
1. 实验设置
实现细节。我们的框架基于开源的 HunyuanDiT和 FLUX.1 - dev构建。我们采用 50 步采样和无分类器引导 ,生成 分辨率的图像。标记替换阈值 设置为总步骤的 。
基准协议。我们建立了三个评估层级:1) 单主体个性化,与涵盖基于训练和免训练范式的 10 种方法进行对比;2) 多主体个性化,与 6 种代表性方法进行评估;3) 主体 - 场景组合,以 AnyDoor为上下文自适应的参考进行基准测试。

图 6. 单主体个性化的定性比较。更多结果可在补充材料中找到。
评估指标。我们在 DreamBench上评估我们的“任意个性化”方法,该数据集包含 30 个基础对象,每个对象配有 25 条文本提示。我们使用组合规则将该数据集扩展为 750、1000 和 100 个测试用例,分别用于单主体、多主体和主体 - 场景个性化。定量评估采用多维指标:使用 FID进行质量分析,使用 CLIP - T进行图像 - 文本对齐,在单主体评估中使用 DINO、CLIP - I、DreamSim进行身份保留,在多主体评估中使用 SegCLIP - I。DreamSim是一种用于感知图像相似度的新指标,它弥合了“低级”指标(如 PSNR、SSIM、LPIPS)和“高级”指标(如 CLIP)之间的差距。SegCLIP - I 与 CLIP - I 类似,但源图像中的所有主体都进行了分割。
2. 与现有技术的比较
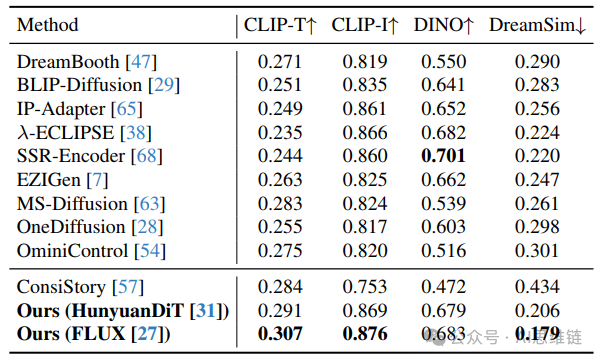
单主体个性化。图 6 展示了与代表性基线方法的定性比较。现有的测试时微调方法每个概念需要 30 个 GPU 分钟的优化,并且对于单图像输入有时会出现概念混淆,表现为将背景颜色视为主体的特征。基于训练但测试时免调优的方法尽管在大型数据集上进行了训练,但在处理真实图像输入时难以详细保留身份信息。免训练方法在单图像输入时生成的主体不一致。相比之下,我们的方法生成的高保真图像与指定主体高度一致,无需训练或微调。表 1 中的定量结果证实了我们在身份保留和图像 - 文本对齐方面的出色表现。
表 1. 单主体个性化的定量结果。
多主体个性化。从图7的定性角度来看,现有方法在生成多个主体时可能会出现概念融合的问题,难以保持每个主体的独特身份,或者由于对主体间关系的错误建模而产生碎片化的结果。相比之下,我们的方法通过布局引导生成来维持主体之间的自然交互,同时确保每个主体保留其相同的特征和独特性。从定量角度来看,表2中的结果展示了“任意个性化”(Personalize Anything)在SegCLIP - I和CLIP - T中的优势,表明我们的方法不仅能有效捕捉多个主体的身份,还能出色地保留文本控制能力。
主体 - 场景组合。我们进一步在主体 - 场景组合任务上评估我们的“任意个性化”(Personalize Anything)方法,并与Anydoor进行比较。我们在图8中展示了可视化结果,其中AnyDoor生成的结果不协调,表现为生成图像中主体与光照等环境因素之间的不一致。相比之下,我们的方法成功生成了自然的图像,同时有效保留了主体的细节。这展示了“任意个性化”(Personalize Anything)在生成高保真个性化图像方面的巨大潜力和泛化能力。

图7. 多主体个性化的定性比较。

图8. 主体 - 场景组合的定性结果。
3. 消融实验
我们对单主体个性化进行了消融实验,研究了标记替换时间步阈值和补丁扰动策略的影响。
表2. 多主体个性化的定量结果。
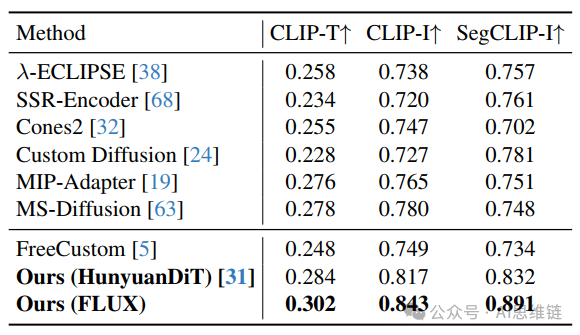
表3. 消融研究。我们评估了标记替换阈值 和块扰动的影响。
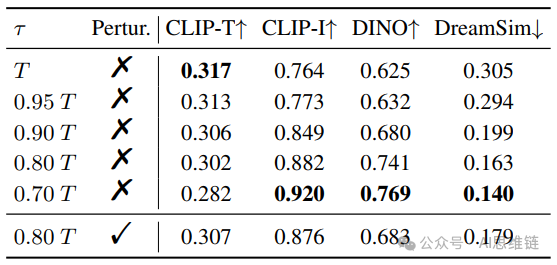
阈值 的影响。我们对时间步长阈值 的系统研究揭示了其在平衡参考主体一致性和灵活性方面的关键作用。如图 9 所示,早中期替换阶段 逐步融入参考令牌的几何和外观先验信息,最初捕捉粗略布局(0.9T),然后细化颜色图案和纹理(0.8T)。超过 后,后期颜色融合占主导地位,生成的主体几乎与参考主体完全相同(0.7T)。定量结果如表 3 所示,其中平衡的 在保持 0.302 的图像 - 文本对齐度(CLIP - T)的同时,实现了 0.882 的参考相似度保留率(CLIP - I)。

图 9. 关于令牌替换阈值 和块扰动的定性消融研究。
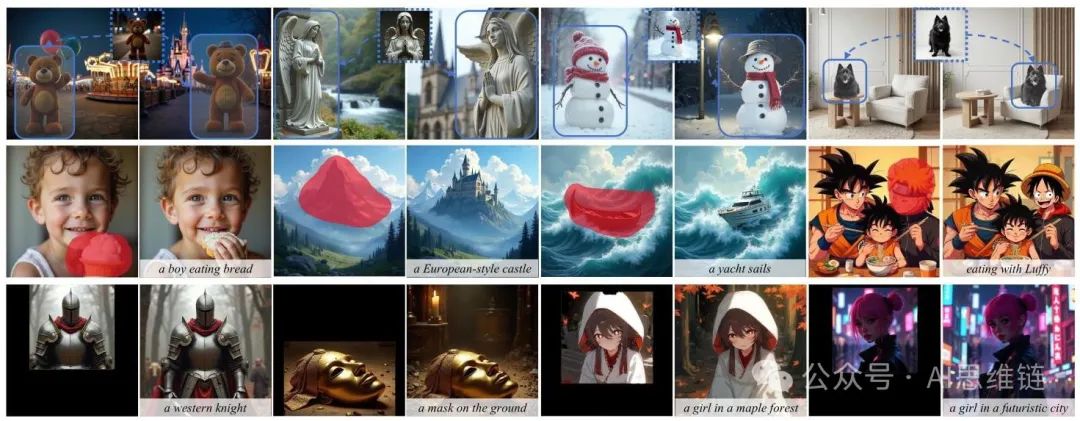
图 10. “个性化万物”在布局引导生成(上)、图像修复(中)和图像扩展(下)中的可视化结果。
块扰动的影响。通过结合局部令牌洗牌和掩码变形,我们的扰动策略减少了纹理和结构的过拟合。在 的情况下,未进行扰动时生成的主体和参考主体在结构上相似(图 9)。相反,应用扰动使结构和纹理更加灵活,同时保持高度一致性。
4. 应用
如图 5 所示,我们的“个性化万物”方法自然地扩展到了各种实际应用中,包括布局引导的主体驱动图像生成、图像修复和图像扩展。图 10 中的可视化结果展示了我们的框架在布局引导个性化以及基于掩码条件的精确编辑方面的能力,且无需进行架构修改或微调。
总结
本文揭示了在扩散变压器(DiTs)中,简单的令牌替换能够实现高保真的主体重建,这得益于 DiTs 中的位置解耦表示。语义特征和位置的解耦使得可以替换纯语义令牌,避免了位置干扰。基于这一发现,我们提出了“个性化万物”方法,这是一个无需训练的框架,通过时间步长自适应令牌注入和策略性块扰动实现高保真的个性化图像生成。我们的方法无需对每个主体进行优化或大规模训练,同时在身份保留方面表现出色,并且在布局引导生成、多主体个性化和掩码控制编辑方面具有前所未有的可扩展性。DiTs 的几何编程为可控合成建立了新的范式,其空间操作原则可扩展到视频/3D 生成,重新定义了生成式人工智能中的可扩展定制。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









