






🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列

论文名:DreamLayer: Simultaneous Multi-Layer Generation via Diffusion Model
论文链接:https://arxiv.org/pdf/2503.12838
开源代码:https://ll3rd.github.io/DreamLayer/
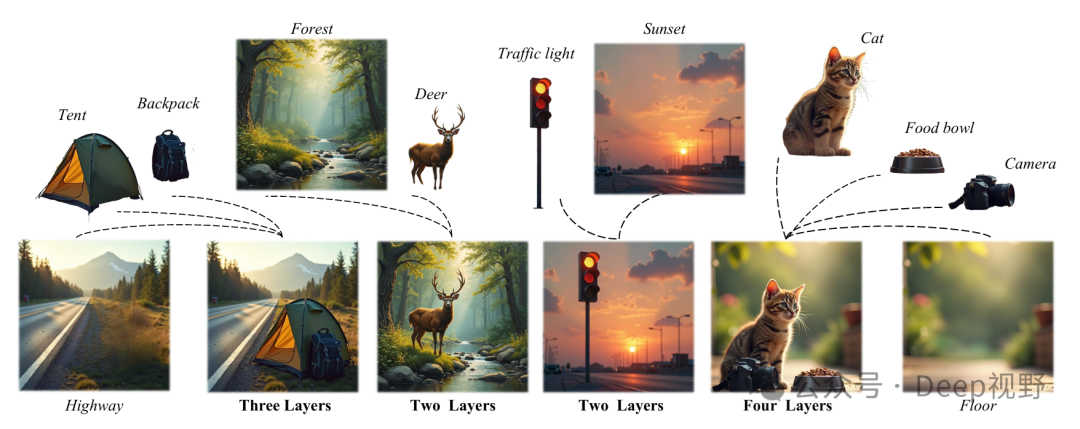
导读
近年来,基于扩散模型的文本到图像生成技术已展现出从文本提示中创建高质量、细节丰富图像的强大能力。然而,大多数方法专注于生成单个完整的图像,这极大地限制了它们在内容编辑和图形设计等严重依赖分层合成的应用中的潜力。分层结构对于包含多个对象的图像特别有利,因为它们允许进行更灵活和多样的编辑及创意修改。本文研究了如何通过简单的文本驱动过程,应用扩散模型生成连贯的多层图像。
简介
近年来,使用扩散模型进行文本驱动的图像生成受到了广泛关注。为了实现更灵活的图像操作和编辑,近期的研究已从单图像生成扩展到透明图层生成和多层合成。然而,现有方法往往未能对多层结构进行全面探索,导致层间交互不一致,如遮挡关系、空间布局和阴影效果等。在本文中,我们提出了梦境图层(Dream-Layer)这一新颖框架,通过显式建模透明前景和背景图层之间的关系,实现了连贯的文本驱动多层图像生成。梦境图层包含三个关键组件,即用于全局 - 局部信息交换的上下文感知交叉注意力机制(Context-Aware Cross-Attention,CACA)、用于建立稳健层间连接的层共享自注意力机制(Layer-Shared Self-Attention,LSSA)以及用于在潜在层面细化融合细节的信息保留协调机制(Information Retained Harmonization,IRH)。通过利用连贯的全图像上下文,梦境图层通过注意力机制建立层间连接,并应用协调步骤实现无缝的图层融合。为了促进多层生成的研究,我们构建了一个高质量、多样化的多层数据集,包含 个样本。大量实验和用户研究表明,梦境图层生成的图层更加连贯且对齐良好,具有广泛的适用性,包括潜在空间图像编辑和图像到图层分解。
方法与模型
定义。直观地说,一个层图像由一个背景层、前景层和一个全局层组成。每个层由一个三通道彩色图像和一个alpha通道 组成,其中alpha通道表示彩色图像中像素的可见性。形式上,全局层图像可以表示为
每个层都与一个相应的文本描述相关联,作为文本提示。
Alpha通道的生成。对于每个层图像,我们根据其alpha通道用纯灰色背景填充图像以获得一个RGB层。然后将这个RGB层编码为一个潜在图像,并在个时间步长上添加噪声以生成一个含噪潜在图像。以时间步长和文本提示为条件,扩散模型训练一个网络来预测添加到含噪潜在图像中的噪声
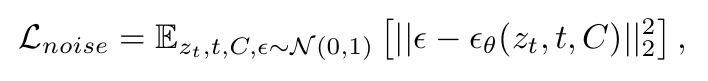
其中表示扩散模型的学习目标。经过个去噪步骤后,潜在图像由一个层解码器解码,以生成带有alpha通道的最终透明层图像。层解码器可以多种多样,一些方法[10, 44]训练一个4通道变分自编码器(VAE)解码器,而其他方法[41]则使用一个VAE解码器与一个灰色背景分割模型相结合。在这项工作中,我们采用与LayerDif - fusion [41]中相同的层解码器。值得注意的是,我们主要关注多层生成中的布局连贯性和整体协调性,而不是alpha通道生成的准确性。
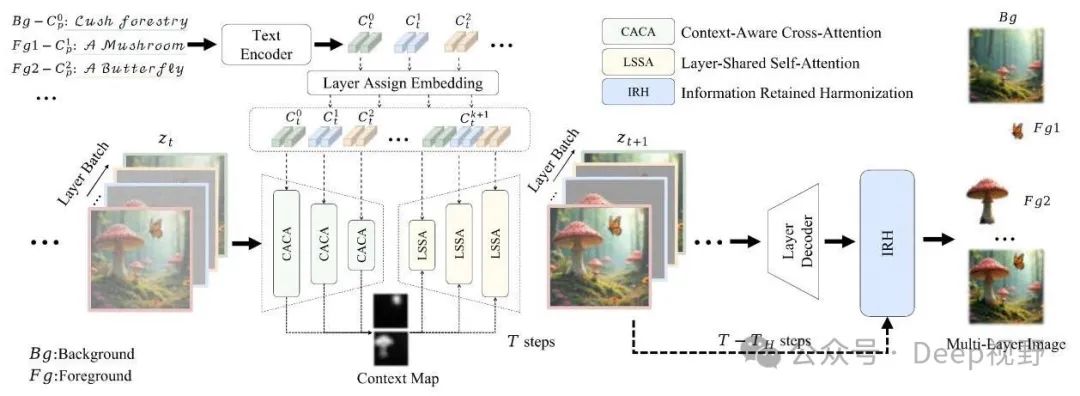
图3. 用于多层图像生成的DreamLayer框架:在生成过程中,背景和前景提示通过层分配嵌入进行组合,形成全局提示。在注意力阶段,上下文感知交叉注意力(CACA)从全局层提取上下文映射。随后,基于全局上下文映射,通过层共享自注意力(LSSA)在各层之间融合上下文信息。最后,信息保留协调(IRH)在去噪过程中使用潜在图像融合图像,实现和谐的结果。
概述。如图3所示,对于多层生成,我们使用文本编码器同时对背景层和每个前景层的提示进行编码,以获得文本嵌入 ,其中 表示分词后的序列长度。然后,将一个可学习的层分配嵌入添加到每个文本嵌入中。我们从每个文本嵌入中提取 [SOS] 和 [EOS] 标记之间的部分,并将它们连接起来形成全局嵌入 ,该全局嵌入捕获所有层的基本信息并指导全局层的生成。在扩散模型的注意力计算过程中,所有层以批量方式进行处理。为了充分利用全局层的信息,我们设计了三个关键组件:上下文感知交叉注意力(Context-Aware Cross-Attention,CACA)、层共享自注意力(Layer-Shared Self-Attention,LSSA)和信息保留协调(Information Retained Harmonization,IRH)。这些组件利用全局层的引导来确保背景层和前景层之间的一致性,促进和谐的多层图像生成。
1. 上下文感知交叉注意力
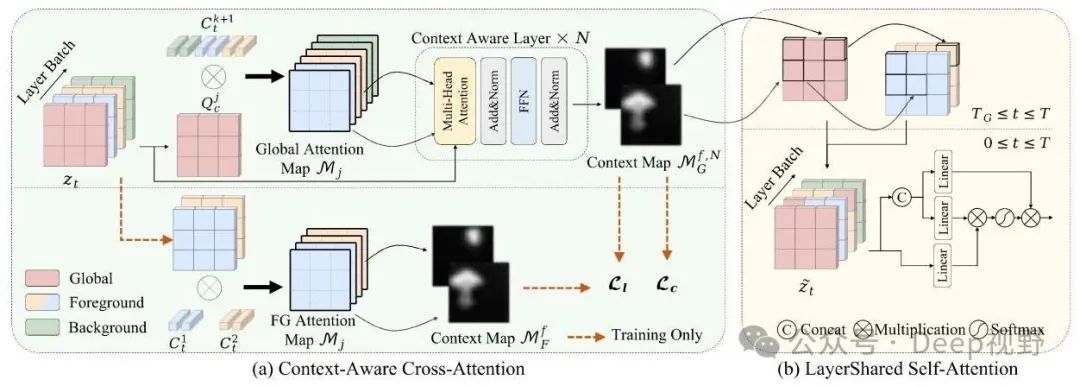
图4. DreamLayer中注意力机制概述:(a) 上下文感知交叉注意力用于提取全局上下文映射并引导前景层布局;(b) 层共享自注意力用于建立层间连接并确保一致性。
多层生成的关键是保持所有层在布局和比例上的一致性。在生成过程中,我们将其他层的布局位置与全局层对齐。利用每个层的文本嵌入,我们从全局层的交叉注意力中提取相关信息。形式上,如图4 (a) 所示,在 交叉注意力机制中的全局噪声潜在图像 被投影到查询矩阵 ,然后使用全局嵌入计算注意力图 为
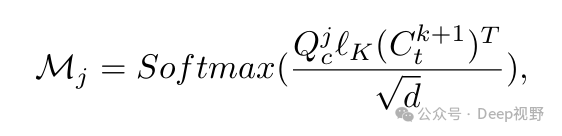
其中 是线性投影, 是潜在维度。注意力图保留了不同前景对象的空间布局和几何形状 [7, 43] 。因此,我们从扩散模型的 层中提取对应于每个前景对象的交叉注意力图。这些图被组合以创建 初始空间感知全局注意力图 :
其中 表示最小 - 最大归一化, 表示全局嵌入中每个前景文本嵌入的标记长度。为了增强提取的注意力图中的前景层上下文,我们将初始图和 交叉注意力机制的全局噪声潜在图像输入到 上下文感知层 中,以生成全局上下文图 如下:
每个上下文感知层由一个多头注意力 [33] 后跟一个前馈网络(Feed-Forward Network,FFN)组成。上下文图由前景图像的 alpha 通道监督,其中
其中 表示带插值的调整大小操作。
从全局层 中提取前景层的和谐布局和几何信息后,我们采用相同的方法从特定前景层 中提取相应的空间感知注意力图 。接下来,我们实现一个布局对齐损失 ,使全局层能够监督和引导局部前景层,促进它们之间的对齐和连贯性:
最终目标可以联合写为
其中 和 是权重项。
2. 层共享自注意力机制
为了进一步加强各层之间的联系,我们提出了一种层共享自注意力机制。该方法首先通过注意力图将全局层信息整合到前景层中,然后在自注意力机制内同时处理所有层的信息,强化层间关系,并确保多层生成过程的一致性。
具体而言,如图 4 (b) 所示,给定一个层批次的含噪潜在图像 以及时间步 时的全局上下文图 ,我们基于全局上下文图将全局信息整合到前景层中,其表达式为:
对于具有 个去噪步骤的扩散模型,我们在前 个步骤中执行该过程。此外,为了建立层间交互,我们在每个去噪步骤中沿序列维度拼接所有含噪潜在图像,以形成一个联合噪声图像:
然后,我们进行线性投影以生成联合键 和值 ,并使用原始层查询 应用注意力机制,形式上表示为:
其中 表示潜在维度。线性投影的权重直接从原始权重初始化。
3. 信息保留协调
在多层融合中,仅基于 alpha 通道混合各层通常会影响整体视觉质量,因为在现实场景中,将前景对象添加到背景中通常会引入阴影变化。为了实现合成图像更和谐的融合,我们提出了信息保留协调方法,该方法在去噪过程中混合潜在信息,并加入额外的去噪步骤,从而得到一个更连贯、视觉上更一致的最终合成图像。
具体来说,在标准的 个去噪步骤中,我们保留步骤 和 之间的含噪潜在图像,记为 。完成 个去噪步骤后,我们通过层解码器获得前景特定层的 alpha 通道 。然后,我们进行 个步骤的重新去噪作为协调过程,并在步骤 和 之间进行潜在级别的层融合。公式如下:
其中 表示在协调步骤中获得的含噪潜在图像。在信息保留协调(IRH)过程中,融合后的潜在信息在整个去噪步骤中受到前景对象的影响,从而能够生成相应的阴影细节并增强图像的整体连贯性。同时,前景层的信息在去噪过程中逐渐被保留,确保生成的前景层的一致性。
此外,我们可以在潜在空间内编辑各层,确保各层的融合更加平滑、和谐。这表示为:
其中表示调整大小、翻转和移动等操作。
4. 数据集准备
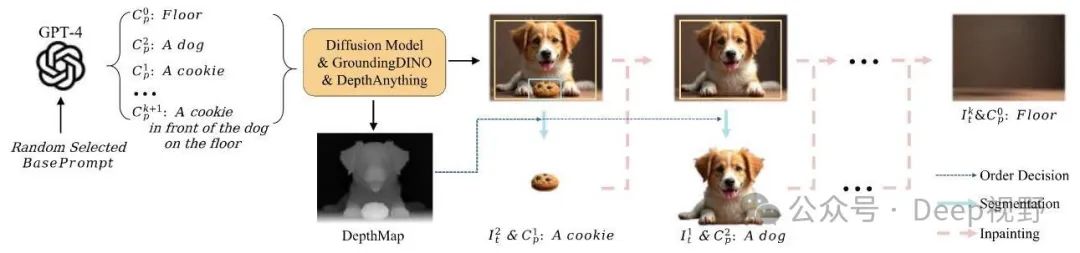
图5. 多层数据准备流程。我们利用GPT - 4处理随机选择的基础提示,将其构建为背景提示和多个前景提示。使用扩散模型生成图像后,我们应用开放集检测模型GroundingDINO来识别前景对象的位置,并使用DepthAnything模型获得深度图。根据深度顺序,我们依次提取前景层,并使用修复模型填充缺失区域。
图5展示了我们的多层数据集的构建过程。为了管理复杂的图层关系,我们从全局图层开始,采用开放集目标检测、深度图和图像修复技术将其分解为多个图层。首先,我们从大规模提示数据集[35]中随机采样一个提示作为基础提示。然后,这个基础提示由GPT - 4模型处理,该模型将其分解为一个背景提示、几个前景提示和一个完整的全局提示。如果基础提示中缺乏足够的前景对象,GPT - 4会从Object365[29]数据集中选择一个合适的类别。接下来,全局提示通过强大的图像生成扩散模型,如Flux[14]、SD3[15]或SDXL[21],生成一幅完整的图像。然后,我们使用前景提示和开放集检测模型GroundingDINO[17],将文本与图像中的对象进行匹配。同时,我们使用DepthAnything[37]模型生成完整图像的深度图。基于深度图,我们使用抠图模型提取最前面的对象,并使用图像修复模型填充缺失区域。重复这个过程,我们利用深度图确定图层顺序,并提取相应的前景图层。我们使用分割掩码和检测框匹配对象和文本,最终获得多层的透明图像。目前的生成模型在生成大量对象方面仍然存在困难,导致数据保留率较低。因此,我们将最终输出设置为4个图层。管道的详细信息见补充材料。
按照这个流程,我们生成了一个包含数百万张多层图像的数据集。然后,我们进行了人工审核,筛选并选择符合特定标准的图像,如清晰完整的前景、无伪影的和谐背景以及其他质量标准。最终的数据集包括张两层图像、张三层图像和张四层图像。如表5所示,与现有数据集相比,我们的数据集包含更多的样本,并且涵盖了更广泛的类别。
实验与结果
1. 实现细节
训练。我们使用Stable Diffusion v1.5[23]的预训练权重初始化训练,并采用自定义扩散[13]策略,微调所有注意力层中的K&V线性层。对于前景图层,额外的层单独训练。上下文感知交叉注意力应用于分辨率为16的下采样层,而图层共享自注意力用于所有上采样层。每个图层批次使用相同的时间步噪声初始化,并且图层嵌入初始化为零,以尽量减少对原始权重的干扰。训练在2块A100 GPU上进行4天,批量大小为4,学习率为2e - 6。更多细节见补充材料。
评估。我们在我们提出的数据集中的张多层图像测试集上评估DreamLayer。使用AES分数[28]评估美学质量,使用CLIP分数[22]评估文本 - 图像对齐度,使用FID[8]评估分布相似度。
2. 多层图像生成的比较
定量比较。如表1所示,我们将DreamLayer在生成完整图层方面的性能与Stable Diffusion [23](SD15)和LayerDiffusion [41]的结果进行了比较。在这种设置下,SD15仅基于全局提示生成单个完整图像。我们使用LayerDiffusion的从背景到前景的方法来生成三层和四层图像,依次添加前景元素以模拟多层合成。如表所示,在多层生成的所有三个指标上,我们的方法都优于LayerDiffusion,美学得分显著提高了约0.5。对于合成多层图像,与SD15直接生成全图像相比,我们的方法还实现了更高的美学质量和更好的文本对齐。

表1. 多层合成图像生成的定量比较。对于StableDiffusion v1.5(SD v1.5),我们从全局提示生成完整图像作为合成图像。
定性比较。在图7中,我们展示了多层图像生成结果。与Layerdiffusion [41]相比,我们的方法生成的前景层更加连贯且大小合适,并且实现了前景与背景更和谐的融合。
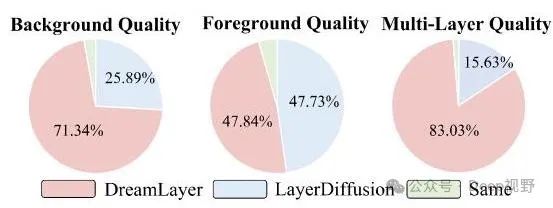
图6. 用户研究中的投票偏好百分比。我们从三个方面评估我们的方法和LayerDiffusion:多层、前景和背景质量。
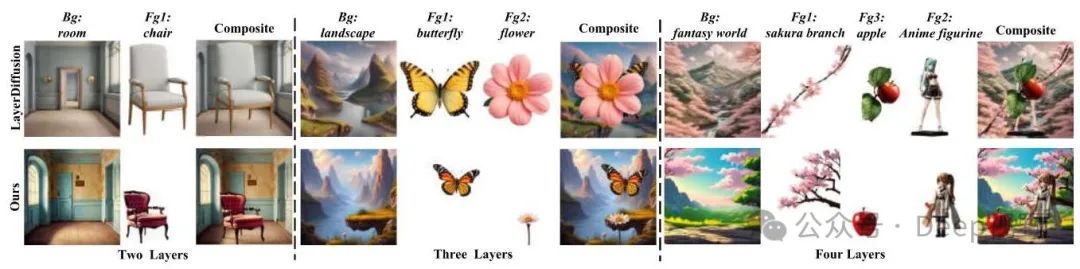
图7. 多层图像生成的定性比较。我们展示了Layerdiffusion和我们的方法在两层、三层和四层图像上的生成结果。
用户研究。如图6所示,我们对20名受试者的200个样本进行了用户研究,以从三个方面评估我们的方法和LayerDiffusion [41]的多层生成质量:多层质量、前景质量和背景质量。结果表明,在上述三个方面,我们的方法获得了的偏好百分比。这表明我们的方法能够提供更连贯的布局和更高的质量,特别是在背景和多层图像方面。
3. 消融研究
上下文感知交叉注意力(Context-Aware Cross-Attention,CACA)。CACA从全局层提取上下文地图信息,并利用来指导前景层的布局。如图8所示,没有布局对齐损失(即不使用)时,前景对象倾向于在相同位置生成,导致重叠和遮挡。我们在表3中报告了定性结果。去除CACA会显著降低图像质量,使多层生成的整体AES分数降低0.154。

图8. 上下文感知交叉注意力的消融研究:使用监督从全局图像中提取布局信息,指导前景图层的生成并减少重叠放置。
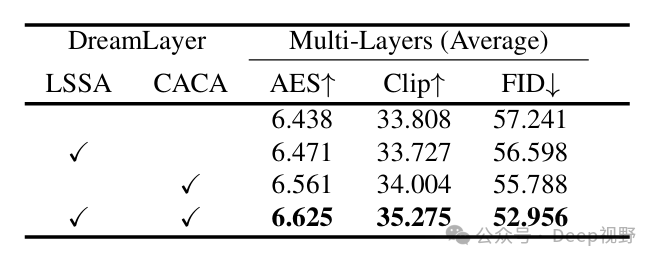
表3. 对局部自注意力机制(LSSA)和跨注意力上下文聚合(CACA)的消融研究。
层共享自注意力(Layer-Shared Self-Attention,LSSA)。LSSA主要用于保持不同图像层之间的一致性。如表3所示,缺少LSSA会导致CLIP分数显著下降,大约降低1.27。
信息保留协调(Information Retained Harmonization,IRH)。我们进一步研究了IRH在层合成中的作用。如图9所示,简单地堆叠前景层和背景层(混合)会产生不真实的合成图像,缺少阴影等纹理细节。例如,图9中的椅子看起来像是悬浮着没有阴影,破坏了视觉和谐。然而,使用IRH时,背景中会生成阴影和其他细节以反映前景对象的存在,从而实现更自然和连贯的层合成。从定量结果来看,如表1所示,“DreamLayer不使用IRH”的美学分数明显下降,不使用IRH时下降了0.1。

图9. 对IRH的消融研究。与直接混合不同,我们的协调方法为前景对象生成了合适的阴影,从而使整体合成更加连贯。
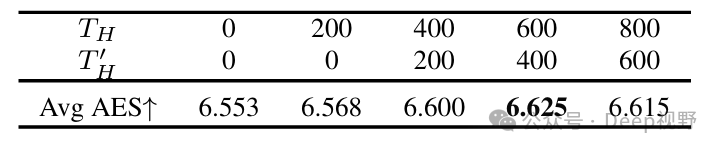
表4. 对IBH中和的研究。
IBH中的和。我们研究了IBH中和的值。我们对从800步到0步进行了实验。如表4所示,当在去噪过程接近结束时应用,会导致协调效果不佳和AES分数较低。相反,当较大(例如)时,IBH会过度修改背景,降低AES分数。基于这些观察结果,我们选择了和。
4. 进一步应用
图像到图层 在DreamLayer框架内,我们可以以无需训练的方式将其扩展到图像到图层任务。具体而言,我们将输入图像编码为潜在表示作为全局潜变量,然后使用反演技术[18]逐步添加噪声直至达到步潜变量,该潜变量作为DreamLayer中所有图层的初始潜变量。为了在这个反演过程中获得更准确的初始潜变量,我们使用掩码分离全局图像信息,以最小化其他图层的影响。如图10所示,这种方法使我们能够根据文本提示将输入图像分解为单独的图层。详细步骤见补充材料。图层编辑 在实际应用中,DreamLayer可以生成多层图像,并允许用户对图层进行协调的编辑。如公式(13)所述,我们在潜在空间的IRH内进行这些编辑,以确保调整更加连贯。例如,在图11中,当椅子被翻转并移动时,地板阴影会更新以与它的新位置对齐,从而增强整体真实感。此外,当前景对象的部分超出图像边界时,DreamLayer具有前景对象非模态补全的能力,在重新定位时可以根据需要补全缺失的部分。如图11所示,与DesignEdit[12]等现有方法相比,DreamLayer在机器人和蓝色花瓶等对象移动后成功恢复了它们超出画面的部分。

图10. 图像到图层可视化:通过利用反演将输入图像转换为所有图层的初始噪声潜变量,DreamLayer可以结合文本提示对输入进行分解。

图11. 图层编辑可视化:与DesignEdit相比,DreamLayer可以在图像边缘补充对象,并在对象翻转或移动时产生更连贯的效果。
总结
在本文中,我们介绍了一个大规模、高质量的多层数据集,其特点是包含多样的前景对象和背景。在此基础上,我们提出了DreamLayer,这是一个用于同时生成多层图像的框架。为了解决前景层之间的布局一致性问题,我们引入了上下文感知交叉注意力机制(Context-Aware Cross-Attention),该机制利用全局图像的和谐布局来引导前景生成。为了增强层间连接,我们提出了层共享自注意力机制(Layer-Shared Self-Attention),使各层之间能够进行有效的信息交换。最后,为了生成连贯的合成图像,我们提出了信息保留协调机制(Information Retained Harmonization),该机制在潜在层面合并各层以实现无缝融合。DreamLayer不仅支持多层生成,还支持通过反转进行图像到层任务的层分解,从而能够在潜在空间内进行灵活编辑以实现和谐调整。实验结果证明了DreamLayer在多层生成方面的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









