






概述/导读:
在现代软件开发与运维领域,Java虚拟机(JVM)的性能监控至关重要,它直接关系到应用的稳定性、响应速度及资源利用率。本文深入剖析了JVM的核心监控指标,从内存管理的细微之处到线程调度的宏观视图,再到垃圾回收(GC)策略的评估与优化,为读者构建了一个全面而深入的知识框架。另外,我们通过 Databuff 这一先进的数据可观测平台展示了如何将理论知识转化为实践行动,以应对实际工作中的各种挑战。
常用JVM指标及其含义解读
1、堆内存使用情况
包括年轻代(Young Generation)和老年代(Old Generation)的使用率、eden区、survivor区的状态等,直接关系到垃圾回收(GC)行为和频率,是分析内存泄漏和GC效率的关键指标。
Heap Used:当前堆中已使用的内存大小,反映应用程序实时占用的内存情况。
Heap Committed:JVM已向操作系统申请可以使用的堆内存大小,这个值通常不会减少,除非进行一次完全的垃圾回收(Full GC)。
Heap Max:堆内存的最大可用容量,由JVM启动参数(如-Xmx)设定,超过此限制可能导致OutOfMemoryError。
2、线程信息
活跃线程数、线程状态(如Runnable、Blocked等)、线程堆栈信息,有助于识别线程阻塞、死锁等问题。
Thread Count:当前线程总数,过高可能意味着资源竞争或死锁。
Daemon Thread Count:守护线程的数量,通常不直接影响JVM退出。
Thread Peak:应用程序运行期间达到的最大线程数。
3、垃圾收集统计
包括GC次数、GC时间、各种GC算法的执行详情,是评估GC策略效果和调优的重要依据。
GC Time:垃圾回收所花费的时间,过高表明GC活动频繁,可能影响应用响应时间。
GC Count:自JVM启动以来执行的GC次数,可以用来分析GC频率。
GC Pause Time:每次GC暂停应用的时间,过长的暂停可能导致应用响应延迟。
4、CPU使用率
反映JVM及所在主机的CPU负荷,过高可能意味着计算密集或线程竞争激烈。
CPU Usage:JVM进程消耗的CPU百分比,过高的CPU使用率可能指示计算密集型操作或瓶颈。
5、内存池
JVM(Java虚拟机)内存池是Java内存管理的一个核心概念,它将堆内存划分为不同的区域,以便更高效地管理对象的生命周期和内存分配。
Young Generation(Eden Space/Survivor Space):年轻代内存空间分为Eden和Survivor两部分,反映短期对象的分配和回收情况。
Old Generation(Tenured Gen):老年代的内存占用信息,负责保存长期存在的对象,而在此区域进行的垃圾回收活动往往具有更高的成本效益考量。
Direct Memory Usage:直接内存使用率,用于记录直接字节缓冲区的使用情况,该部分内存不在堆内,但同样受到操作系统内存限制。
6、类加载信息
类加载数量、卸载数量等,有助于监控类加载器的活动,诊断类定义冲突或内存泄漏问题。
Loaded/Unloaded Class Count:已加载和卸载的类数量,有助于识别类加载器的活动。
7、编译统计
如JIT编译的数量、耗时,对于理解代码执行效率和优化热点方法有重要作用。
JIT Compilation:即时编译的统计信息,如编译任务数和编译时间,反映代码从字节码转换为本地代码的效率。
Databuff中JVM指标数据的使用
Databuff 作为一站式观测领域的领航者,通过其强大的功能集,将JVM指标数据的监控与分析提升至全新高度,为开发与运维团队提供了前所未有的洞察力和效率。以下是其核心优势的深入解析:
数据采集与直观展示
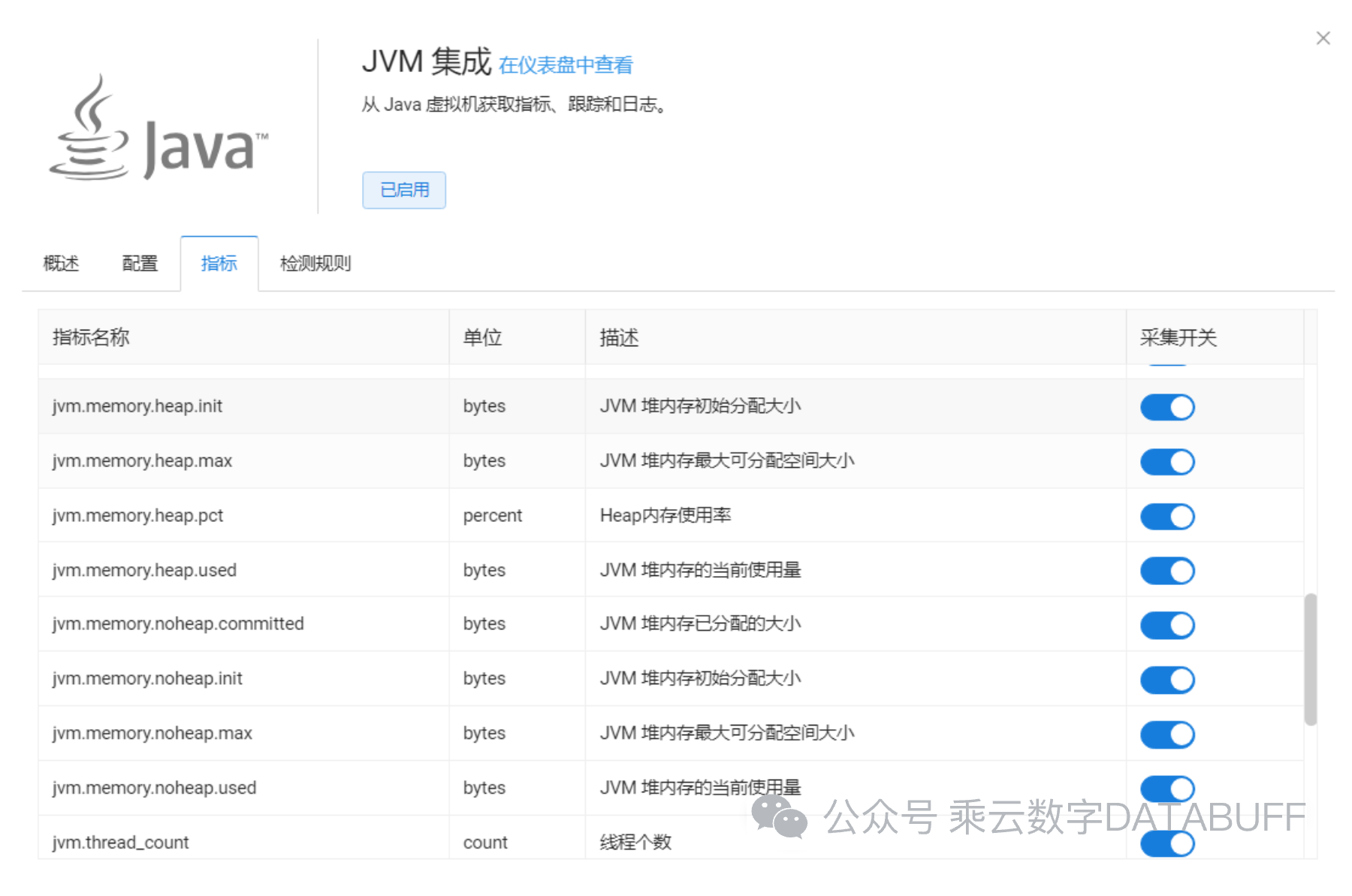
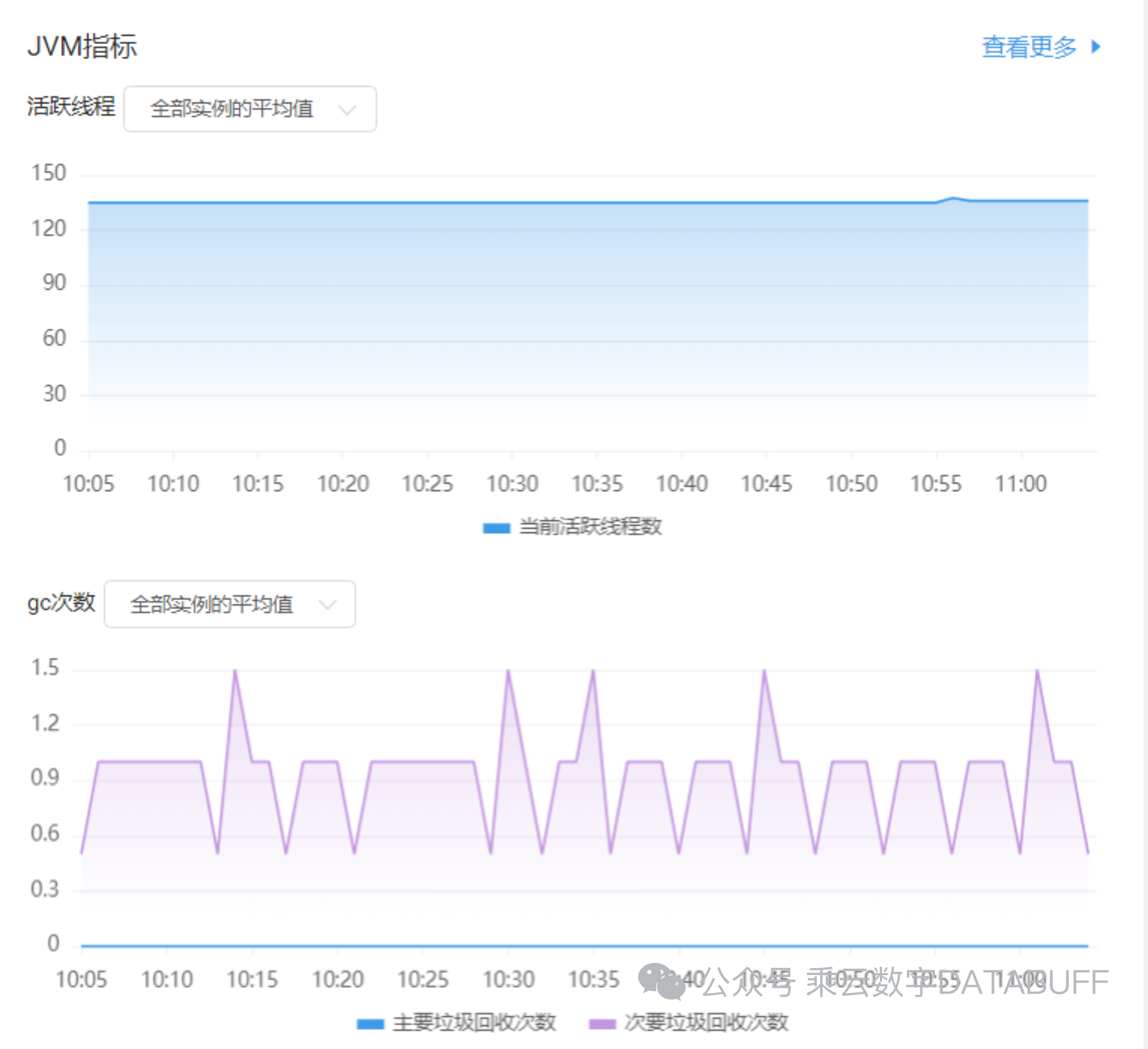
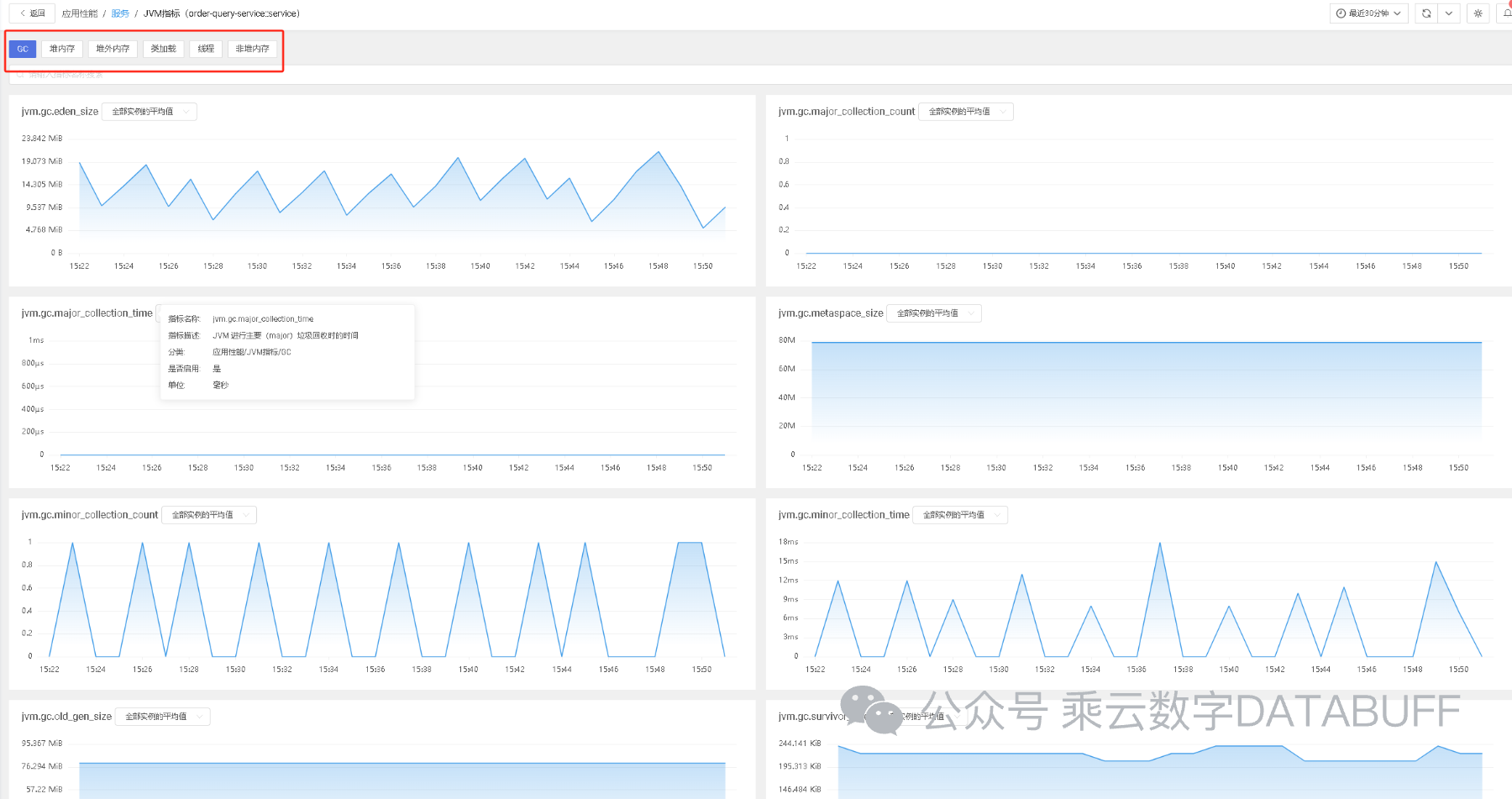
Databuff以极简的部署方式(一键安装与自动配置)著称,无缝集成了JVM指标的采集能力,从垃圾回收(GC)、堆内存、堆外内存到线程数量等关键性能指标,一应俱全。通过图表(如上图所示)实时展示应用性能状况,无需手动干预即可获得详尽的指标趋势,加速问题定位过程。
实践与应用
为了深入理解如何通过Databuff平台有效监测并应对内存溢出这一典型故障场景,我们将通过一个详实的模拟过程来展示其强大的JVM指标监控与告警机制。此过程不仅涵盖了配置策略、动态分析,还涉及到利用ChaosBlade工具人为制造故障,以检验系统的实战响应能力。
1. 配置监测规则:构建预警防
首先,在Databuff平台上,我们精心设置两道监测防线,确保对潜在的内存溢出风险做到早发现、早预警。
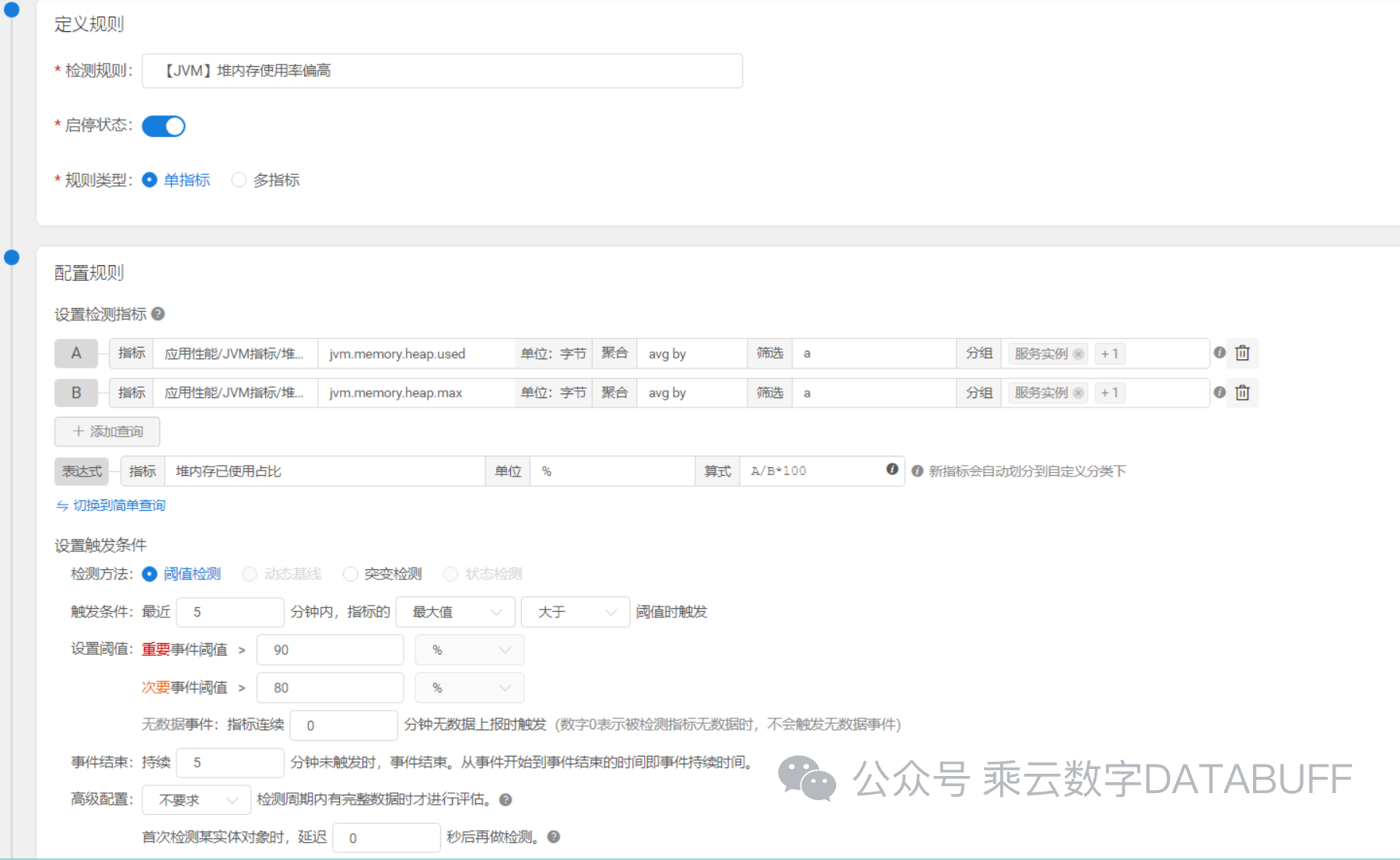
规则一:静态阈值监控
在此规则下,我们针对Java堆内存使用率设定了一道警戒线 —— 当使用率达到90%,系统即刻触发警报。这样的设定旨在快速响应那些可能导致服务中断的极端内存占用情况,确保运维团队能在第一时间介入处理。(参考下图配置界面)
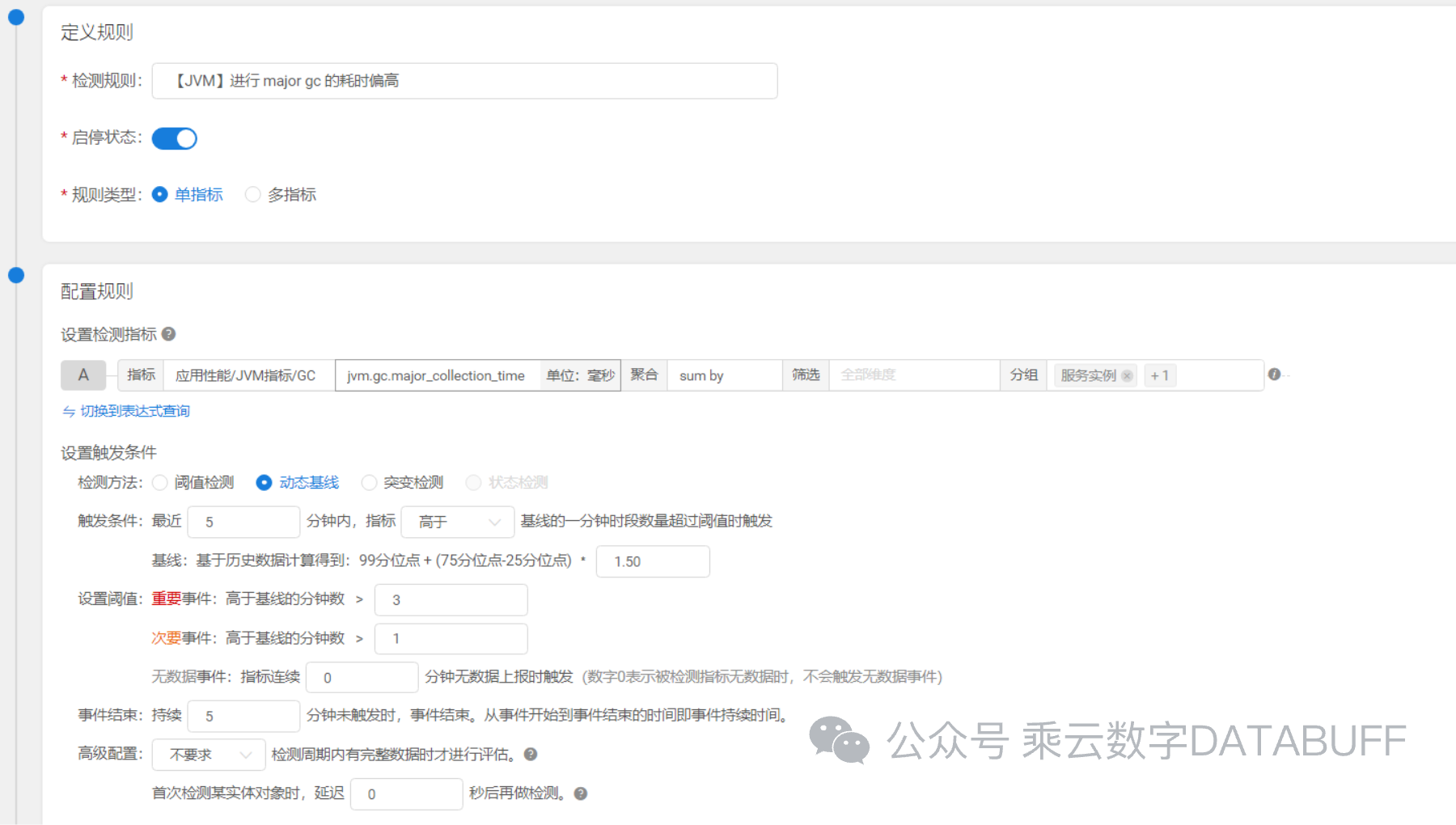
规则二:动态基线检测
相较于固定的阈值,动态基线则更加智能。Databuff利用历史数据,通过机器学习算法动态分析应用的内存使用模式,自动设定个性化的基线标准。一旦当前内存使用偏离这一动态基线,系统将自动触发警报,这尤其适用于那些负载波动较大的应用场景,能够更精准地识别异常。(参考下图配置界面)
2. 实施收敛规则:优化告警体验
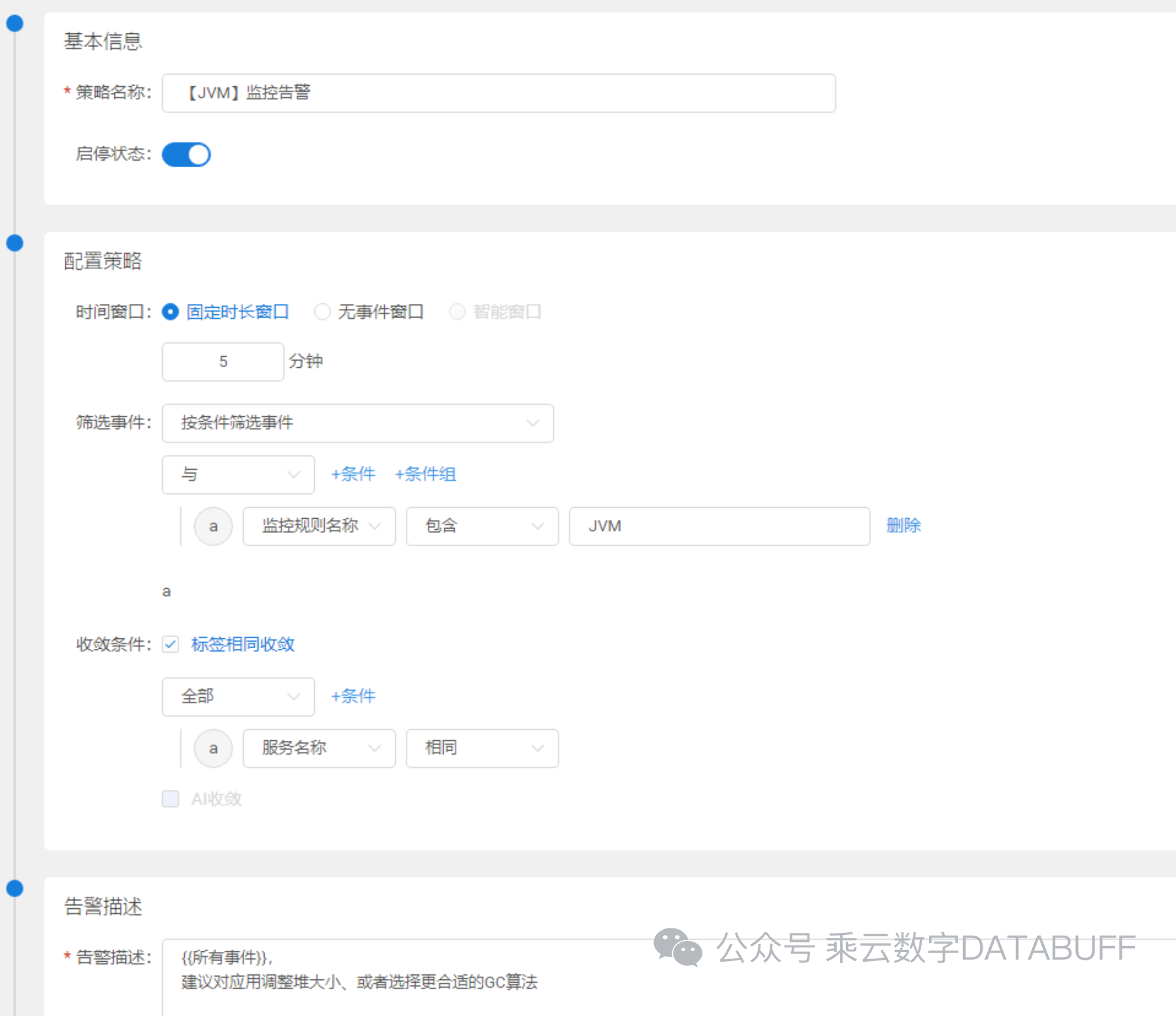
为了避免告警风暴,我们进一步配置了告警收敛规则。这意味着在特定时间段内,即便相关事件频繁发生,Databuff也会将这些事件整合成一条综合告警,提供简洁明了的报警信息,减少噪音干扰,让运维人员能集中精力处理核心问题。
3. 模拟故障场景:ChaosBlade上阵
为了测试Databuff的实际监控与告警效果,我们选择使用ChaosBlade这一强大的混沌工程工具。具体操作是针对目标应用服务demo-service-b-1.0:auto执行内存溢出模拟实验。通过ChaosBlade的JVM故障注入功能,我们可以精确控制何时何地在应用中触发OutOfMemoryError,以此来验证系统的韧性与监控的有效性。

4. 触发告警与深入分析
随着ChaosBlade成功模拟内存溢出,Databuff平台迅速响应,依据先前设定的规则触发告警。
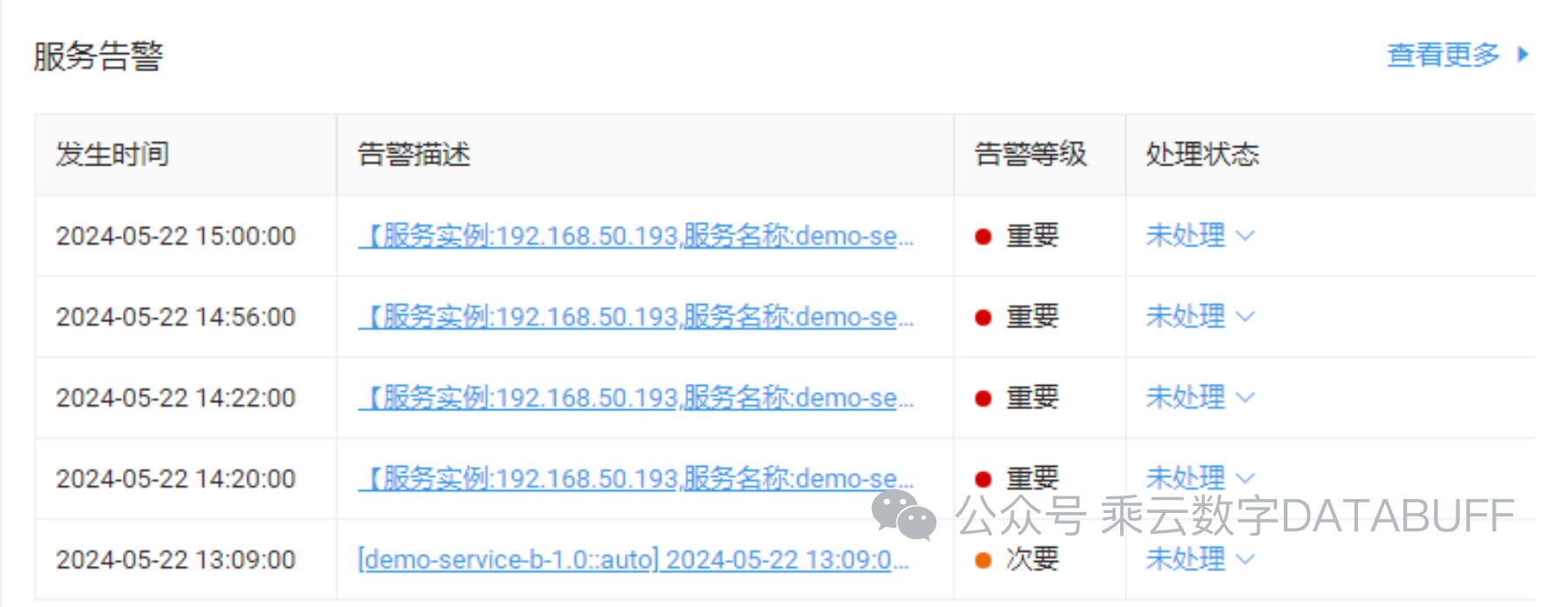
得益于告警收敛机制,运维团队接收到的是经过整合的、高度概括的警告信息,而非冗余的单项告警。

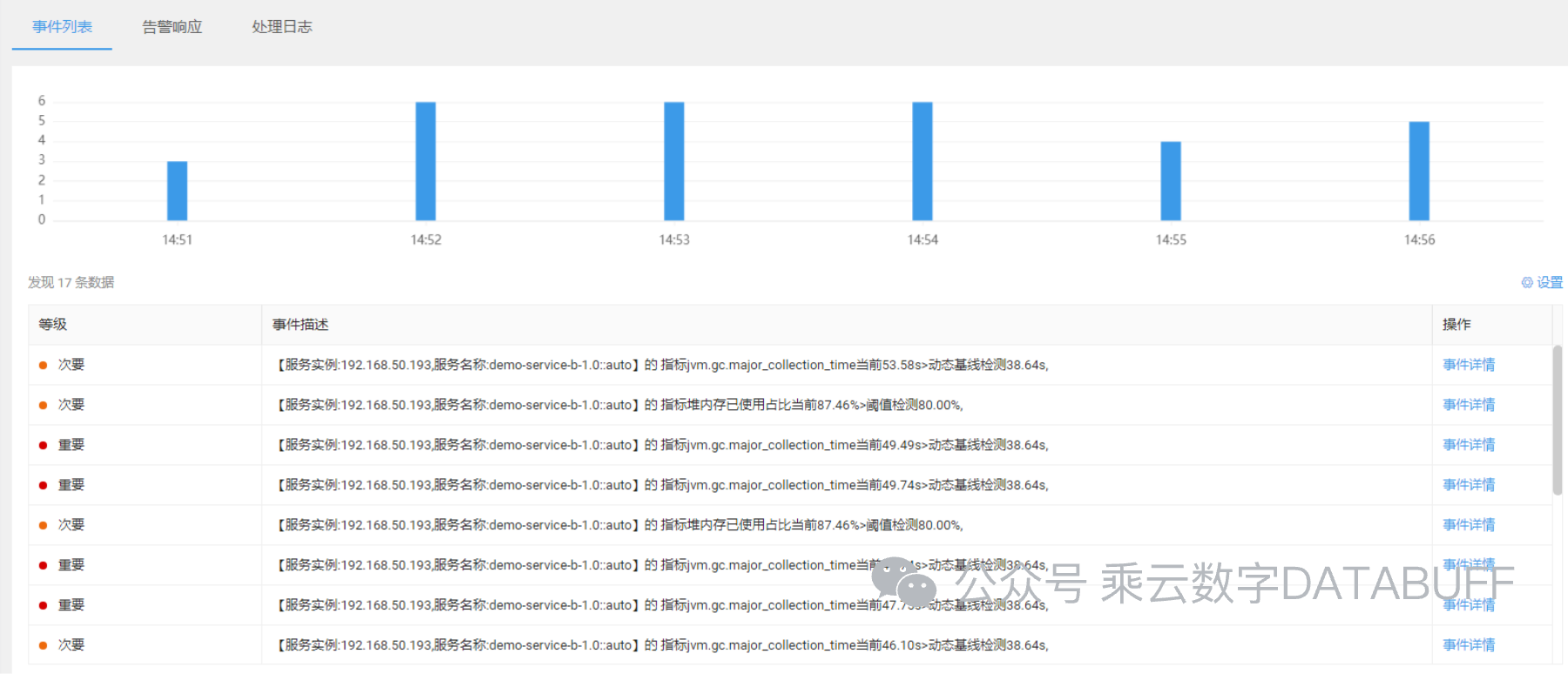
点击进入事件详情页面,即可直观看到内存使用的历史趋势图,以及触发告警的具体对象和时间点,为问题定位与解决提供了宝贵的数据支持。
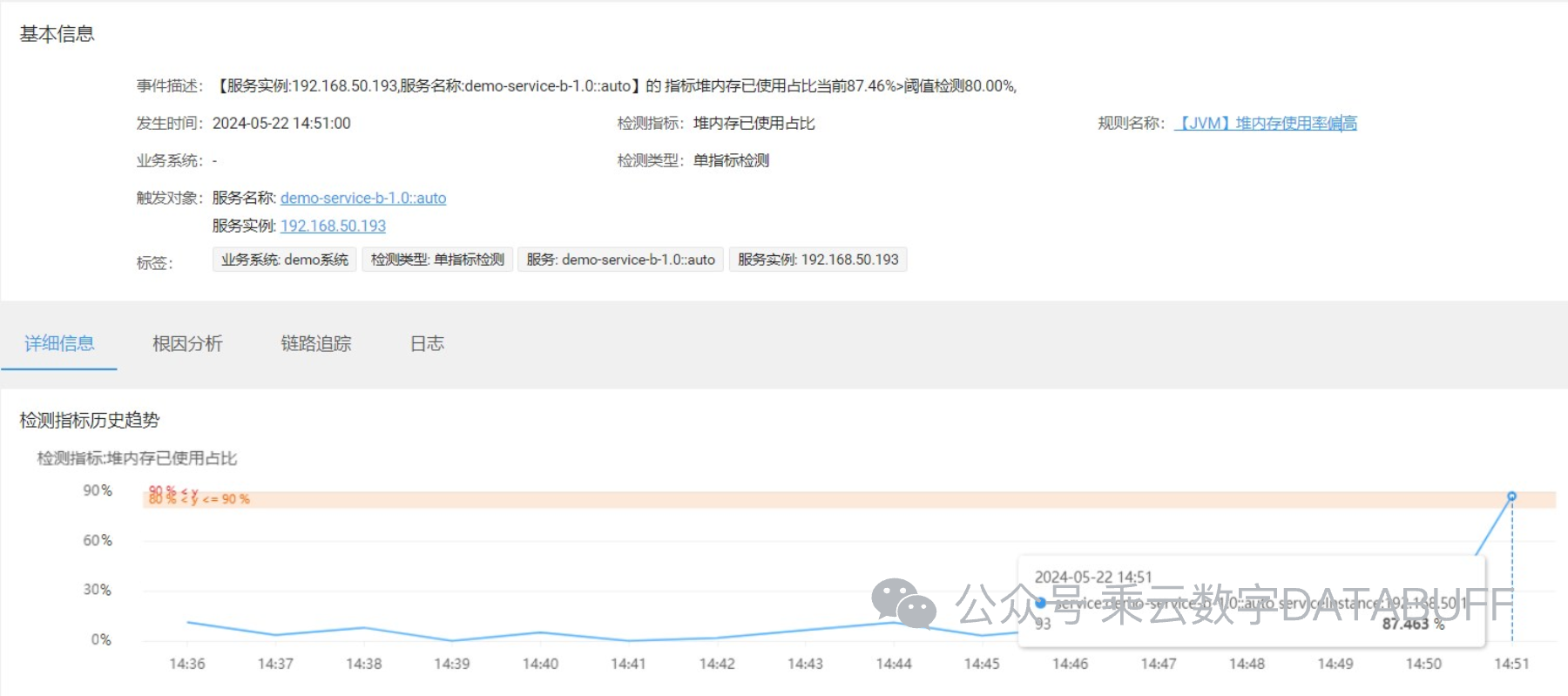
通过这次从规则配置到故障模拟的全过程,Databuff展现了其在JVM监控与告警领域的高效与灵活性。不仅能够通过静态阈值及时预警,还能依托动态基线实现智能化监控,加之告警收敛策略的运用,大大提升了故障响应的效率与准确性。结合ChaosBlade的故障注入测试,企业可以信心满满地面对生产环境中的各种挑战,确保服务的稳定与可靠。
加入乘云伙伴群

深度分析与系统优化展望
虽然Databuff在JVM监控上的表现已十分出色,但要实现对系统性能的全方位透视,还需结合调用链追踪与Profiling技术。随着对Trace与Profiling技术的深入应用,预示着可观测性实践的新一轮升级,让开发者与运维人员拥有更加锐利的工具,以应对日益复杂的系统挑战。未来篇章《透视系统性能:Trace与Profiling融合实战的可观测性升级》将探索如何通过对这些高端技术的深度融合,进而细化问题根源。无论是微服务架构下的请求追踪,还是代码级性能剖析,都将助力提升系统的稳定性和性能表现至新境界。
















 4345
4345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









