







原创:DataBuff ROOT实验室
摘要:自2016年Gartner首次提出AIOps概念已过去8年时间,AIOps软件工具层出不穷,这篇文章给大家介绍下什么NGAIOps? 为什么需要NGAIOps? 以及国内外的AIOps的方案路径与落地对比。
▐ 当前国内AIOps方案普遍存在的问题
1.1 落地困难
数据是AIOps的基石,包含Traces、Metrics、Logs、Events等,然而这些数据目前的采集方式多种多样,比如:
-
Traces,有ddtrace、OpenTelemetry、Skywalking、Pinpoint等等
-
Metrics,有OpenTelemetry、Prometheus、Zabbix等等
-
Logs,有业务日志、k8s日志、主机日志等等
-
Events,有k8s的Pod重启事件、配置变更事件等等
采集的多样性以及这些数据之间的关联关系,都导致了AIOps面对的数据是非常复杂的,在落地AIOps时就有2种路径选择:
-
在复杂的数据之上直接做AIOps
-
优先做可观测标准化、产品化,在标准化、产品化的基础之上再做AIOps
前者一般是AIOps主导的厂商,由于没有可观测产品。虽然快速直接投入到AIOps中,但是在进行AIOps落地之前仍然需要频繁进行数据清理的定制化操作,数据质量非常受限于客户自身的数据关联质量。
后者一般是可观测厂商的选择路径。可观测的标准化、产品化难度大,但一旦克服后,数据质量高的优势将会得到极大发挥。在AIOps落地时能明显的跟前者拉开差距,而且其场景突破前景非常好,尤其是在故障定位上的表现。
1.2 效果有限
AIOps中主要有如下几个大的应用场景:
-
异常检测:
场景非常简单,场景非常简单,对某个指标曲线进行异常判定,更多的难点在于算法方面,所以一些算法强的厂商在这方面落地比较好
-
告警收敛:
普通收敛根据标签匹配的收敛能力有限,要想达到一个极致的收敛效果,还是需要借助于根因定位,将同根因的告警都能够收敛在一起,所以这个主要取决于下面的根因定位的落地效果
-
根因定位:
场景非常复杂,融合了可观测的几乎所有的数据和场景,涵盖IAAS、PAAS等领域知识,数据和场景的复杂度占比80%,算法的难度占比只有20%,所以对数据和场景的理解度更高的厂商才能有更好的落地效果
目前国内AIOps落地好的点基本也只是在异常检测方向,其他方向落地效果都不佳,在项目实际建设交付时瓶颈非常大、往往项目做不下去。
很多AIOps产品出厂,根本都没有经过测试验证,直接拿到客户现场做调试,分析的确定性无法保证,有点看天吃饭的感觉。
1.3 成本太高
AIOps落地时需要一些算法人员来开发一些更加智能化的算法,然而目前涉足AIOps领域的算法人员相对稀少,有大量落地经验的人员更是难以寻觅,稀缺就导致了算法人员这块的成本会非常高,然后实际的落地效果并不能达到预期。
一方面是AIOps工程师的薪资要求高,另一方面是AIOps产品化程度较低、过多的定制/驻场,都直接拉升了整体项目的建设成本、运营成本。过高的投入成本、后期运营成本、使用成本,甲方对其价值预期也水涨船高,两相对比经常AIOps项目收尾难看。
1.4 客户不会用
比如异常检测方向,客户面对琳琅满目的算法选项,不知该如何配置检测规则。
比如根因定位方向,客户面临各种分析出来的机器底层指标或者各种分析结果,不知道该如何理解,不知道该如何处置。
如何解决底层技术和上层使用人员之间的gap也是一个大的难题,运维工具本身是一套辅助保障工具,过高的使用门槛不能友好的为甲方提供支撑、甲方经常会将其束之高阁。
1.5 落地难
即使做出了效果,也很难去呈现出对应的能力,这就需要混沌工程的加持,这块也是一个难点,需要投入大量的人力。
平台化过大的灵活性是一件好事,但甲方最终需要的是交钥匙、是分析结果,需要的不是复杂的过程。甲方在AIOps项目中过多的承担集成商、协调者的角色,疲于应对各种各样的数据生产者为AIOps平台服务,严重的分散精力,不能聚焦上本职业务上,长期投入不见成效会挫伤甲方的投入信心。
▐ 国外AIOps成熟厂商的现状
我们先来看两份报告:
第一是《The Forrester Wave™:AIOps 分析报告,Q4 2022》,可以看到Dynatrace长期处于Leaders 象限。
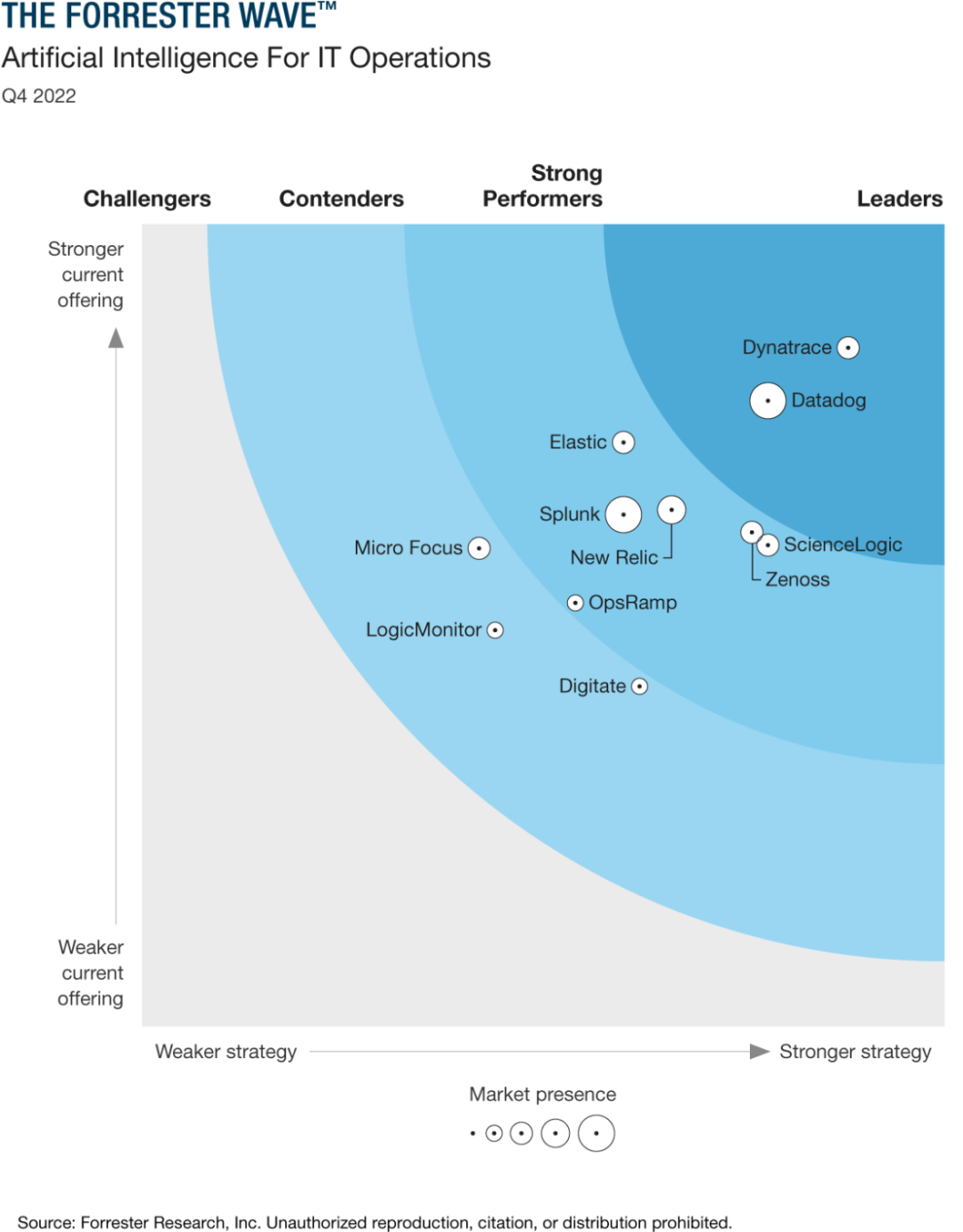
文章来源:https://reprints2.forrester.com/#/assets/2/88/RES177493/report
我们再来看一份G2网站上对国外AIOps领域的排名情
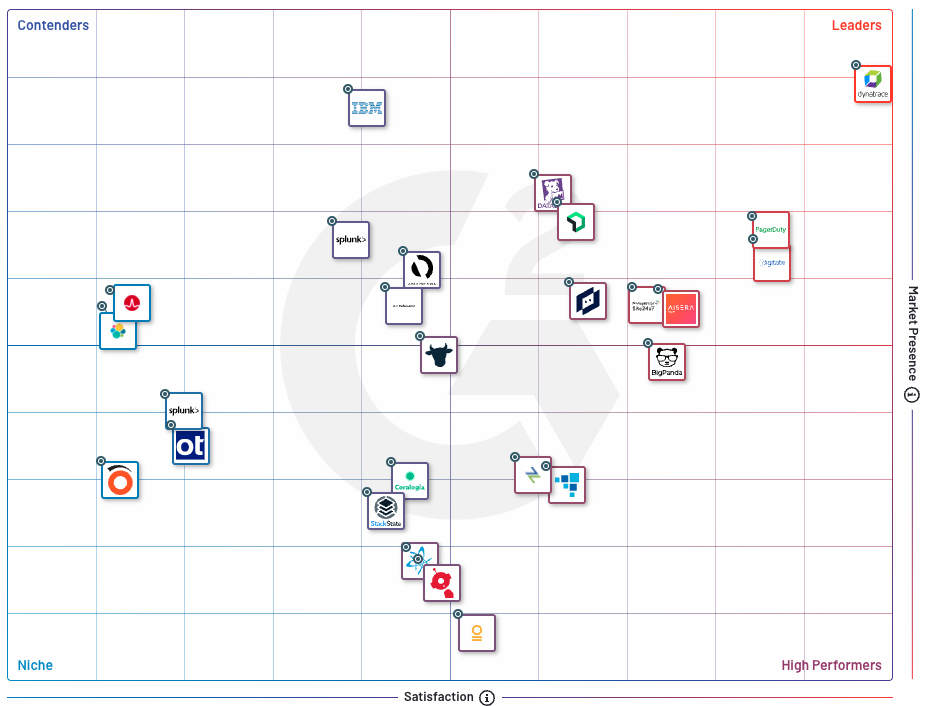
文章来源:Best AIOps Tools in 2024: Compare Reviews on 70+ Products | G2
在G2上的2,705条AIOps软件评价是基于来自真实用户的定性和定量反馈,以帮助比较和研究最适合企业业务的软件产品。目前,G2上列出了78款AIOps软件产品。根据评分和评价数量,以下是最受欢迎的:
-
Dynatrace(4.5星评分,889条评价)
-
PagerDuty(4.5星评分,348条评价)
-
Splunk Enterprise(4.3星评分,237条评价)
-
AppDynamics(4.3星评分,211条评价)
-
New Relic(4.3星评分,145条评价)
目前领头羊长期是dynatrace,那我们就看看dynatrace是如何做到的:
-
OneAgent:
落地了Traces、Metrics、Logs、Events的数据,并建立了丰富的数据关联
-
PurePath技术
-
端到端的全链路追踪,以及实时的profiling,并且可以做到完全自动化
-
端到端的统计分析能力,可以实现服务间的拓扑统计、接口级别的拓扑统计,以及更细粒度的某类请求的拓扑统计
-
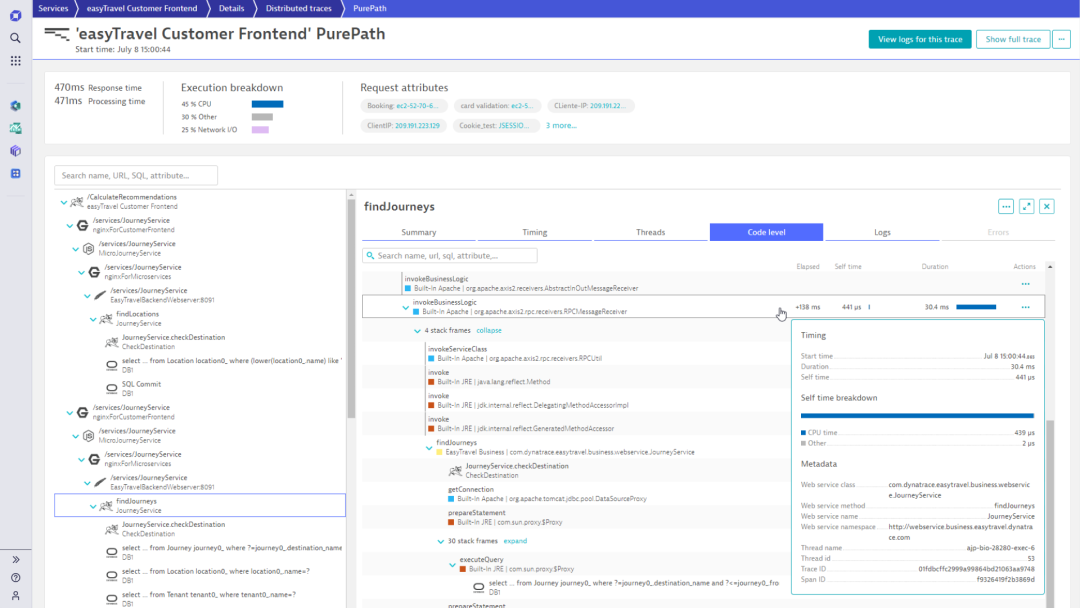
-
SmartScape技术
-
纵向串联服务、服务实例、进程、主机等的拓扑关系
-
横向串联上述同类实体间的拓扑关系
-
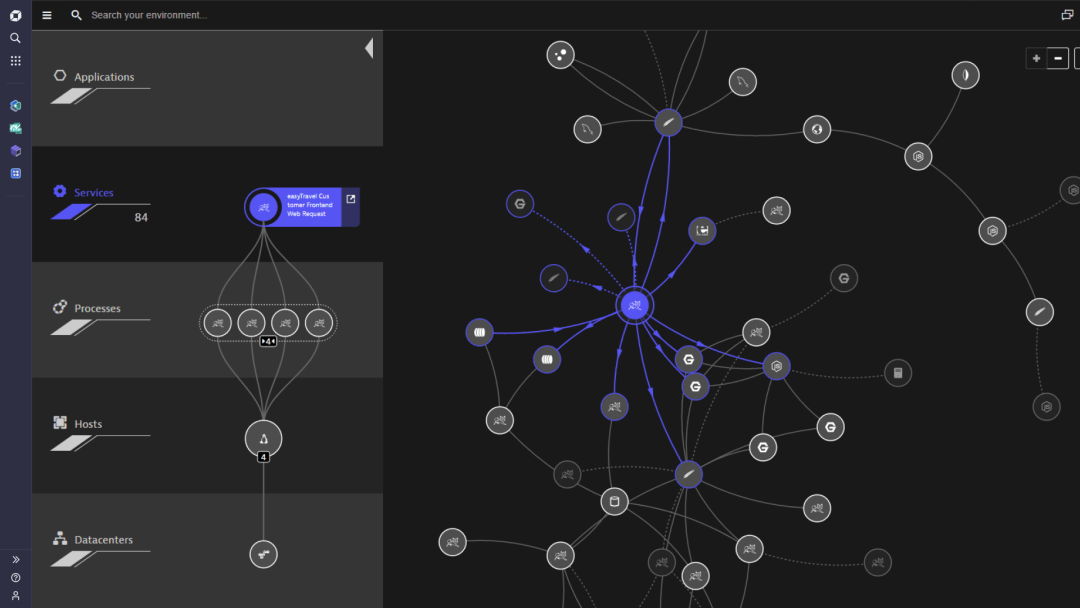
-
Davis AI
-
内置了大量的基础的阈值检测规则,以及一些动态基线的检测规则
-
在上述的PurePath、SmartScape技术之上,加上算法引擎,直接定位出根因
-
借助于上述根因,告警收敛方面的能力大大提高
-
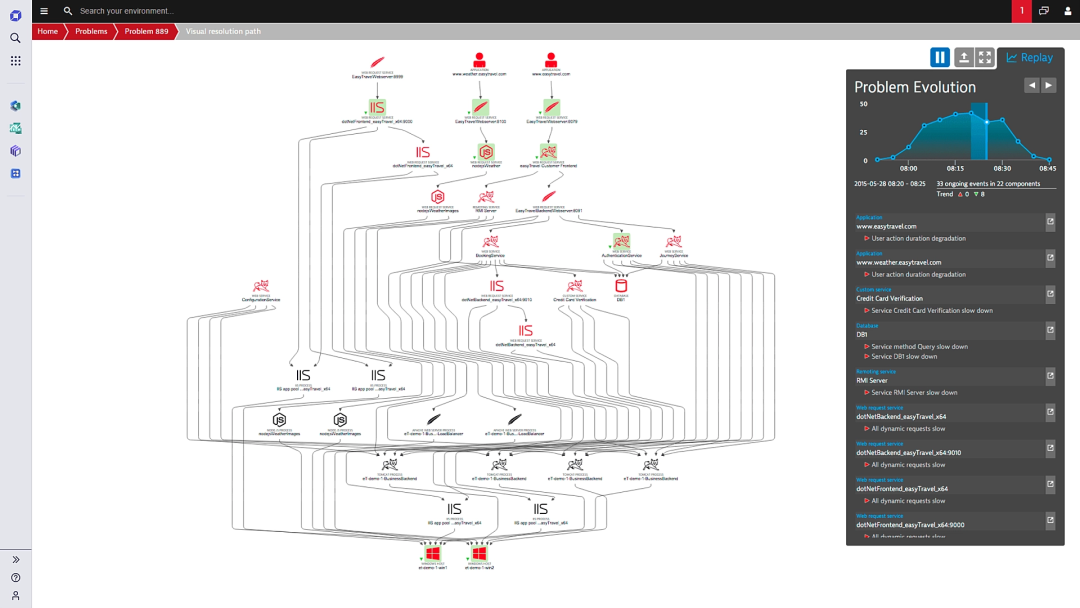
-
集成第三方数据参与AIOps
-
比如支持接入zabbix的数据,同时能参与到Davis AI
-
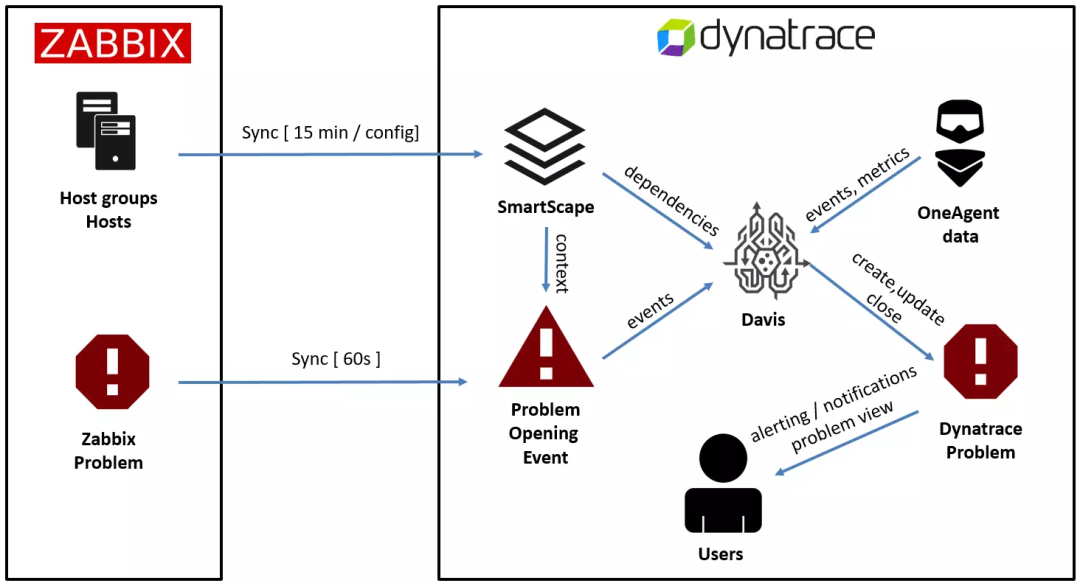
总之,dynatrace对数据和标准化做的非常到位,对数据和场景的理解力方面非一般厂商能比的,为自己的AIOps打下了坚实的基础,然后自家的AIOps才能达到一个更大的高度。而且可以开放灵活对接第三方工具或数据,在保证高质量交付的同时兼具开放灵活的特性。
▐ NGAIOps: 将由可观测厂商主导设计的AIOps
NGAIOps 即下一代的AIOps,必然是由像dynatrace这样的可观测厂商主导设计的AIOps,即专注将数据和场景吃透的,从中构建出定位模型的,再配合算法的加持,使得模型运行的泛化性更好,能够非常优雅的完成AIOps的价值落地。
NGAIOps到底需要具备哪些特征呢才能称之为NG呢 ?
-
面向云原生,充分考虑到云原生的场景,高度敏捷、动态、弹性,在监控数据规模庞大、实体关系错综复杂的新场景下,依然能够非常优雅的发挥AI 的价值
-
相对产品化、标准化的,轻交付,能够一扫国内现有AIOps长期积弊,落地价值显著
-
易上手,使用门槛低
-
落地性强,真正能够落地AI在运维场景的价值
-
面向未来,要充分考虑并利用大模型的能力
-
开放灵活,拥抱开源,共建场景
-
使用门槛低、投入性价比高,不需要大资金投入也可以直接享受AIOps的效果
▐ NGAIOps 难点分析
不管是传统AIOps 还是NGAIOps,最难的还是根因定位RCA。对于其中的难点,Databuff是这样理解的,主要有4个难点:
-
基于故障场景知识图谱下的高质量的数据采集和关联
这是基础,基础不足很难通过后期的AI解决,AI不是神也要遵循基本的数学原理 -
高效的数据存储和查询
故障来临时,需要短时间内分析大量的数据,如果这些跟不上基本很难短时间内出结果 -
智能的异常检测算法和多维下钻分析算法
有了数据,需要专业的算法来分析 -
基于故障场景的知识图谱的分析
有了数据和算法,如何面对一个复杂场景进行综合分析,比如消息队列场景,需要消息队列的运行机制的知识,这方面需要专家经验或者大模型来构建
Databuff 是这样解决上述难点的:
4.1 基于故障场景知识图谱下的高质量的数据采集和关联
举个例子,比如业务服务基于JedisPool去访问Redis,这里面的实际场景是

这里面有几个关键点:
-
阶段1:获取连接
-
创建连接
-
达到最大值后,等待空闲的连接
-
testOnBorrow
-
-
阶段2:执行命令
-
发送命令
-
读取结果
-
testOnReturn
-
一般的Trace采集基本上只会采集到访问Redis的耗时,上述获取连接的流程通常会被忽略,最终也基本只能定位到访问Redis耗时增长,然后更新的信息就没有了,没法进一步明确耗时长是在哪一步
-
是每次都会创建新的连接?
-
是最大连接数太小,导致一直在等待可用连接?
-
是Redis服务端处理速度变慢了?
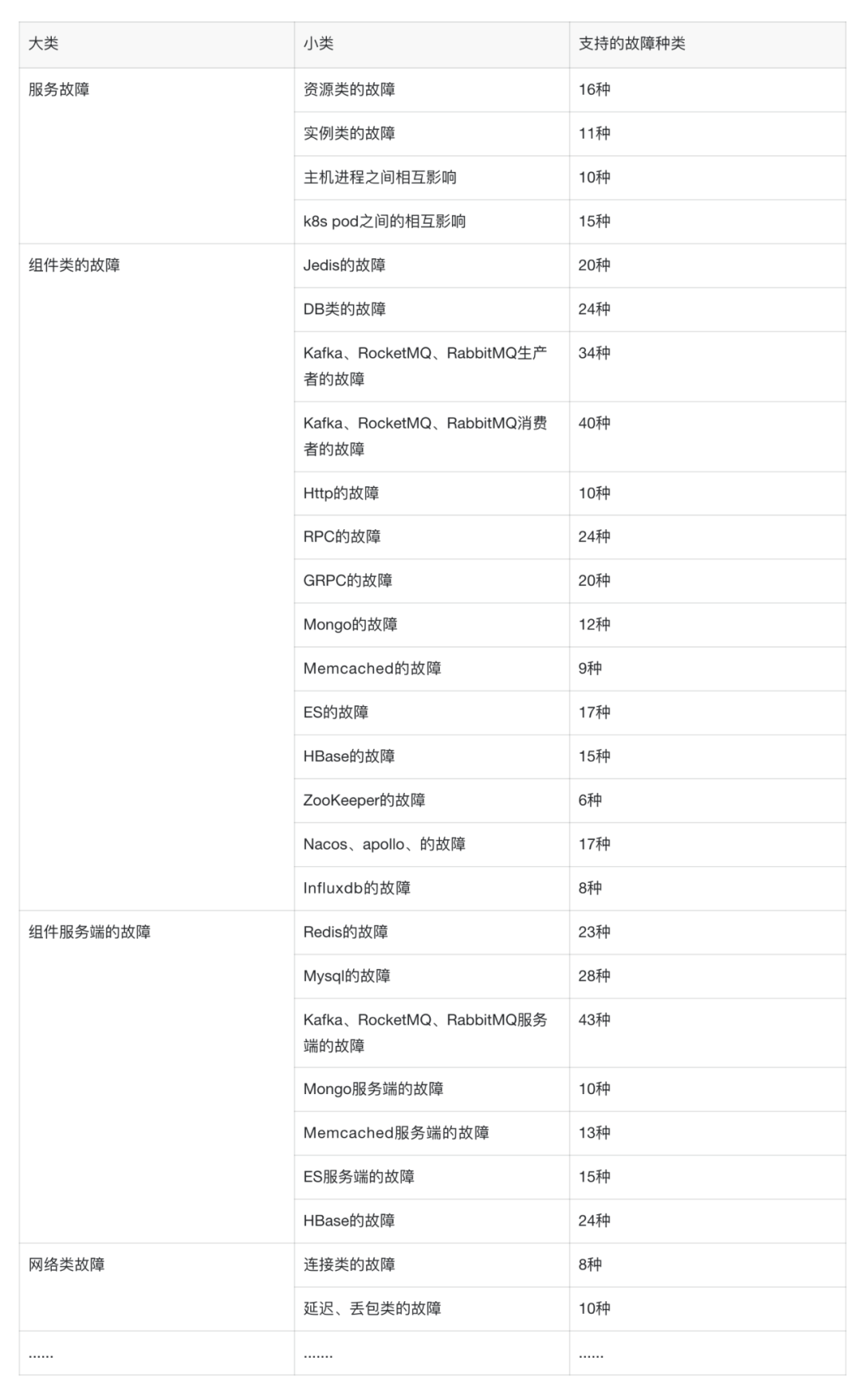
所以基于故障场景下的数据采集显得尤为重要,Databuff在这块投入很大,支持接500+故障种类,涵盖了
4.2 高效的数据存储和查询
在大故障来临时,需要分析大量的服务的数据,这就需要底层基石非常扎实,而Databuff在这方面也有领先的优势
-
MoreDB:写入性能是InfluxDB的4倍,查询性能是InfluxDB的10倍到100倍

-
TraceX:业界领先的专门为Trace设计的存储方案,整体成本是常见通用存储HBase、Clickhouse等方案的1/20

这2套系统能够充分保证了Databuff在大数据量下的性能表现,同时可以保证根因定位时对大量数据的查询需求
可以做到500ms内定位出故障的根因,而一般的根因定位方案都是分钟级别
4.3 智能的异常检测算法和多维下钻分析算法
智能的异常检测算法:需要对常见的Metric指标能够自适应波动并找到异常的波动范围
多维下钻分析算法:通常一个指标中有多个tag维度,需要能够自动分析出是哪些维度组合导致的该指标整体波动
-
常见的算法有Adtributor、Hotspot、Squeeze等但是大多实际落地效果并不佳
-
Databuff这边也自研了一个多维下钻分析算法,具有如下特点
-
速度快:10ms内可以快速分析出结果,可以满足大量的分析需求
-
适应性更好:能够自动适应并学习曲线的波动,可以剔除一些干扰点
-
结合性更好:在进行多维下钻分析时仍然需要一些外部数据才能给出更加精准的结果,比如仅仅有平均响应时间没有请求次数是无法达到更好的解释的
-
4.4 基于故障场景的知识图谱的分析
比如对于MQ生产和消费,如果不给定位系统投喂基本的MQ运行机制的原理(引自CSDN网友的文章),基本上是很难能真正定位出令人满意的结果的
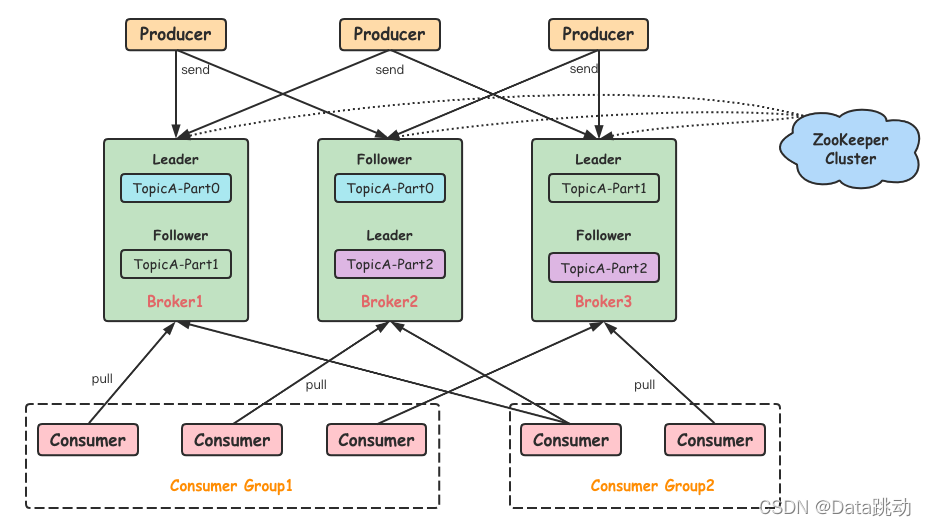
比如定位系统对TCP的很多细节知识不了解,仅仅给出几个抖动的指标,是很难去帮助用户解决问题的
所以定位系统必须要具备故障场景的知识图谱的,这个构建是一件非常复杂的事
-
要么靠专家经验不断去累计故障场景的知识图谱(目前Databuff已采用的)
-
要么靠大模型去不断学习构建出故障场景的知识图谱(未来的希望)
▐ NGAIOps的发展Map
Databuff 对 NGAIOps 的发展充满信心,号召全行业同仁投入到对NGAIOps 的发展建设中,达到国际领先的可观测与AIOps软件厂商的产品力水平。
Databuff 对NGAIOps的发展Map有如下的看法:
-
基础建设,打造高质量的可观测数据底座
-
磨刀不误砍柴工,数据质量是模型分析的上限,先打好基础功
-
基于高质量的可观测性平台底座,构建上层应用分析能力
-
可参考《可观测性成熟度模型》,思考如何构建符合自身的可观测体系
-
-
大力发展混沌工程,制造出相对饱和的故障案例
-
一方面既可以训练根因定位能力
-
另一方面可以展示根因定位的能力
-
打破国内只做AIOps不做测试验证的普遍现状
-
-
构建故障场景的知识图谱
-
使用专家经验构建
-
使用大模型构建
-
-
利用故障场景的知识图谱
-
指引采集的精细度
-
指引数据的指标体系
-
指引页面的交互分析
-
今天的文章就到这里,接下来的文章我会为大家逐步分享,作为一家国内领先的可观测性赛道厂商如何打造 NGAIOps 引擎。















 9385
9385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









