JDK1.8新特性
Lambda表达式
public List<Product> filterProductByColor(List<Product> list){
List<Product> prods = new ArrayList<>();
for (Product product : list){
if ("红色".equals(product.getColor())){
prods.add(product);
}
}
return prods;
}
- 我们发现实际上这些过滤方法的核心就只有if语句中的条件判断,其他均为模版代码,每次变更一下需求,都需要新增一个方法,然后复制黏贴,假设这个过滤方法有几百行,那么这样的做法难免笨拙了一点。如何进行优化呢?
- 使用lambda表达式
定义过滤方法:
public List<Product> filterProductByPredicate(List<Product> list,MyPredicate<Product> mp){
List<Product> prods = new ArrayList<>();
for (Product prod : list){
if (mp.test(prod)){
prods.add(prod);
}
}
return prods;
}
使用lambda表达式进行过滤:
public void test(){
List<Product> products = filterProductByPredicate(proList, (p) -> p.getPrice() < 8000);
for (Product pro : products){
System.out.println(pro);
}
}
Lmabda表达式的语法总结: () -> ();
lambda总结
| 前置 | 语法 |
|---|
| 无参数无返回值 | () -> System.out.println(“Hello World!”) |
| 有一个参数无返回值 | (x) -> System.out.println(x) |
| 有切只有一个参数无返回值 | x -> System.out.println(x) |
| 有多个参数,有返回值,有多条lambda体语句 | (x ,y) -> {System.out.println(“xxx”);return xxx;}; |
| 有多个参数,有返回值,只有一条lambda体语句 | (x, y) -> xxxx |
- 口诀:左右遇一省括号,左侧推断类型省
- 当一个接口中存在多个抽象方法时,如果使用lambda表达式,并不能只能匹配对应的抽象方法,因此引入了函数式接口的概念
方法引用
- System.out :: println
" :: "即为方法引用
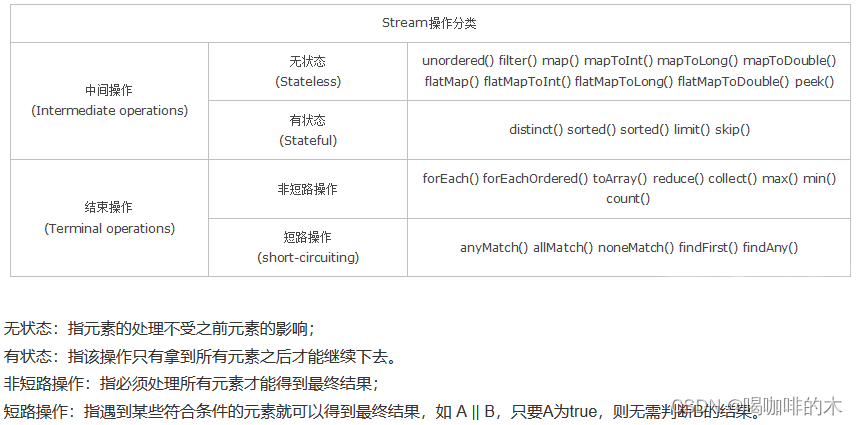
Stream API
Stream 操作的三个步骤
- 创建stream
- 中间操作(过滤、map)
- 终止操作
Stream创建
List<String> list = new ArrayList<>();
Strean<String> stream = list.stream();
Stream<String> parallelStream = list.parallelStream();
String[] str = new String[10];
Stream<String> stream2 = Arrays.stream(str);
Stream<String> stream3 = Stream.of("aa","bb","cc");
Stream<Integer> stream4 = Stream.iterate(0,(x) -> x+2).limit(6);
Stream<Double> stream3 = Stream.generate(Math::random).limit(2);
BufferedReader reader = new BufferedReader(new FileReader("F:\\test_stream.txt"));
Stream<String> lineStream = reader.lines();
lineStream.forEach(System.out::println);
Pattern pattern = Pattern.compile(",");
Stream<String> stringStream = pattern.splitAsStream("a,b,c,d");
stringStream.forEach(System.out::println);
Stream中间操作
筛选、过滤、去重
| 方法 | 说明 |
|---|
| filter | 过滤流中的某些元素(只保留返回值为true的项) |
| limit(n) | 获取前n个元素 |
| skip(n) | 跳过前n个元素,配合limit(n)可实现分页 |
| distinct | 通过流中元素的 hashCode() 和 equals() 去除重复元素 |
emps.stream()
.filter(e -> e.getAge() > 10)--过滤
.limit(4)--限制(输出前4个)
.skip(4)--跳过(前4个不输出)
.count()--统计
.distinct()--去重
.forEach(System.out::println)--遍历输出;
List<User> list = new ArrayList<User>() {{
add(new User("Tony", 20, "12"));
add(new User("Pepper", 20, "123"));
add(new User("Tony", 22, "1234"));
add(new User("Tony", 22, "12345"));
}};
List<User> streamByNameList = list.stream().collect(Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(User::getName))), ArrayList::new
));
System.out.println(streamByNameList);
List<User> streamByNameAndAgeList = list.stream().collect(Collectors.collectingAndThen(
Collectors.toCollection(
() -> new TreeSet<>(Comparator.comparing(o -> o.getName() + o.getAge()))), ArrayList::new
));
System.out.println(streamByNameAndAgeList);
映射
| 方法 | 说明 |
|---|
| map | 函数作为参数,该函数被应用到每个元素,并将其映射成一个新的元素。新值类型可以和原来的元素的类型不同。 |
| flatMap | 函数作为参数,将流中每个值换成另一个流,再把所有流连成一个流。 新值类型可以和原来的元素的类型不同。 |
| mapToInt/Long/Double | 跟map差不多。只是将其转为基本类型。 |
| flatMap ToInt/Long/Double | 跟flatMap差不多。只是将其转为基本类型。 |
List<String> list = Arrays.asList("a,b,c", "1,2,3");
Stream<String> s1 = list.stream().map(s -> s.replaceAll(",", ""));
s1.forEach(System.out::println);
Stream<String> s2 = list.stream().flatMap(s -> {
String[] split = s.split(",");
Stream<String> s3 = Arrays.stream(split);
return s3;
});
s2.forEach(System.out::println);
User u1 = new User("aa", 10);
User u2 = new User("bb", 20);
User u3 = new User("cc", 10);
List<User> list = Arrays.asList(u1, u2, u3);
Set<Integer> ageSet = list.stream().map(User::getAge).collect(Collectors.toSet());
ageSet.forEach(System.out::println);
int[] ageInt = list.stream().map(User::getAge).mapToInt(Integer::intValue).toArray();
for (int i : ageInt) {
System.out.println(i);
}
Stream<String> a=Stream.of("1","2","3");
Stream<String> b=Stream.of("4","5","6");
Stream.concat(a,b).forEach(System.out::println);
Stream.of(List1<A>,...ListN<A>).flatMap(Collection::stream).distinct().collect(Collectors.toList());
排序
| 方法 | 说明 |
|---|
| sorted() | 自然排序,流中元素需实现Comparable接口。 例:list.stream().sorted() |
| sorted(Comparator com) | 定制排序。常用以下几种:list.stream().sorted(Comparator.reverseOrder());list.stream().sorted(Comparator.comparing(Student::getAge));list.stream().sorted(Comparator.comparing(Student::getAge).reversed()) |
List<String> list = Arrays.asList("aa", "ff", "dd");
list.stream().sorted().forEach(System.out::println);
User u1 = new User("dd", 40);
User u2 = new User("bb", 20);
User u3 = new User("aa", 20);
User u4 = new User("aa", 30);
List<User> userList = Arrays.asList(u1, u2, u3, u4);
userList.stream().sorted(Comparator.comparing(User::getAge))
.forEach(System.out::println);
List<User> userList = Arrays.asList(u1, u2, u3, u4);
userList.stream().sorted(Comparator
.comparing(User::getAge)
.thenComparing(User::getName)
).forEach(System.out::println);
System.out.println("------------------------------------");
userList.stream().sorted(
(o1, o2) -> {
String tmp1 = o1.getAge() + o1.getName();
String tmp2 = o2.getAge() + o2.getName();
return tmp1.compareTo(tmp2);
}
).forEach(System.out::println);
System.out.println("------------------------------------");
userList.stream().sorted(
(o1, o2) -> {
if (!o1.getAge().equals(o2.getAge())) {
return o1.getAge().compareTo(o2.getAge());
} else {
return o1.getName().compareTo(o2.getName());
}
}
).forEach(System.out::println);
List<User> userList = Arrays.asList(u1, u2, u3, u4);
userList.stream().sorted(
(o1, o2) -> {
if (!o1.getAge().equals(o2.getAge())) {
return o1.getAge().compareTo(o2.getAge());
} else {
return o2.getName().compareTo(o1.getName());
}
}
).forEach(System.out::println);
消费
| 方法 | 说明 |
|---|
| peek | 类似于map,能得到流中的每一个元素。 但map接收的是一个Function表达式,有返回值; 而peek接收的是Consumer表达式,没有返回值。 |
User u1 = new User("dd", 40);
User u2 = new User("bb", 20);
User u3 = new User("aa", 20);
User u4 = new User("aa", 30);
List<User> list = Arrays.asList(u1, u2, u3, u4);
List<User> list1 = list.stream()
.peek(o -> o.setAge(100))
.collect(Collectors.toList());
System.out.println(list1);
Stream终止操作
匹配、最值、个数
| 方法 | 说明 |
|---|
| allMatch | 接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回false |
| noneMatch | 接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回false |
| angMatch | 接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回false |
| findFirst | 返回流中第一个元素 |
| findAny | 返回流中的任意元素 |
| count | 返回流中元素的总个数 |
| max | 返回流中元素最大值 |
| min | 返回流中元素最小值 |
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
boolean allMatch = list.stream().allMatch(e -> e > 10);
boolean noneMatch = list.stream().noneMatch(e -> e > 10);
boolean anyMatch = list.stream().anyMatch(e -> e > 4);
Integer findFirst = list.stream().findFirst().get();
Integer findAny = list.stream().findAny().get();
long count = list.stream().count();
Integer max = list.stream().max(Integer::compareTo).get();
Integer min = list.stream().min(Integer::compareTo).get();
User u1 = new User("dd", 40);
User u2 = new User("bb", 20);
User u3 = new User("aa", 20);
User u4 = new User("aa", 30);
List<User> list = Arrays.asList(u1, u2, u3, u4);
User user1 = list.stream()
.min(Comparator.comparing(User::getAge))
.orElse(null);
System.out.println(user1);
System.out.println("------------------------------------");
User user = list.stream().min((o1, o2) -> {
if (o1.getAge().equals(o2.getAge())) {
return o1.getName().compareTo(o2.getName());
} else {
return o1.getAge().compareTo(o2.getAge());
}
}).orElse(null);
System.out.println(user);
收集
| 方法 | 说明 |
|---|
| collect | 接收一个Collector实例,将流中元素收集成另外一个数据结构。 |
User u1 = new User("dd", 40);
User u2 = new User("bb", 20);
User u3 = new User("aa", 20);
User u4 = new User("aa", 30);
List<User> list = Arrays.asList(u1, u2, u3, u4);
String joinName = list.stream().map(User::getName).collect(Collectors.joining(",", "(", ")"));
System.out.println(joinName);
List<Integer> ageList = list.stream().map(User::getAge).collect(Collectors.toList());
System.out.println(ageList);
Set<Integer> ageSet = list.stream().map(User::getAge).collect(Collectors.toSet());
System.out.println(ageSet);
List<User> list = Arrays.asList(s1, s2, s3);
Map<String, Integer> ageMap = list.stream().collect(Collectors.toMap(User::getName, User::getAge));
System.out.println(ageMap);
Map<String, User> userMap = list.stream().collect(Collectors.toMap(User::getName, user -> user));
System.out.println(userMap);
聚合
Long count = list.stream().collect(Collectors.counting());
System.out.println(count);
Integer maxAge = list.stream().map(User::getAge).collect(Collectors.maxBy(Integer::compare)).get();
System.out.println(maxAge);
Integer sumAge = list.stream().collect(Collectors.summingInt(User::getAge));
System.out.println(sumAge);
Double averageAge = list.stream().collect(Collectors.averagingDouble(User::getAge));
System.out.println(averageAge);
DoubleSummaryStatistics stat = list.stream().collect(Collectors.summarizingDouble(User::getAge));
System.out.println("count:" + stat.getCount() + " max:" + stat.getMax() + " sum:" + stat.getSum()
+ " average:" + stat.getAverage());
分组
Map<Integer, List<User>> listMap = list.stream().collect(Collectors.groupingBy(User::getAge));
for (Map.Entry<Integer, List<User>> entry : listMap.entrySet()) {
System.out.println(entry.getKey() + "-->" + entry.getValue());
}
Map<String, List<User>> listMap = list.stream()
.collect(Collectors.groupingBy(
user -> {
return user.getAge() + ":" +
user.getName();
}));
for (Map.Entry<String, List<User>> entry : listMap.entrySet()) {
System.out.println(entry.getKey() + "-->" + entry.getValue());
}
Map<Integer, Map<String, List<User>>> ageNameMap = list.stream().collect(
Collectors.groupingBy(User::getAge, Collectors.groupingBy(User::getName)));
for (Map.Entry<Integer, Map<String, List<User>>> entry : ageNameMap.entrySet()) {
System.out.println(entry.getKey() + "-->" + entry.getValue());
}
分区
Map<Boolean, List<User>> partMap = list.stream().collect(Collectors.partitioningBy(v -> v.getAge() > 20));
for (Map.Entry<Boolean, List<User>> entry : partMap.entrySet()) {
System.out.println(entry.getKey() + "-->" + entry.getValue());
}
| 方法 | 说明 |
|---|
| Optional reduce(BinaryOperator accumulator) | 第一次执行时,accumulator函数的第一个参数为流中的第一个元素,第二个参数为流中元素的第二个元素; 第二次执行时,第一个参数为第一次函数执行的结果,第二个参数为流中的第三个元素; 依次类推。 |
| T reduce(T identity, BinaryOperator accumulator) | 流程跟上面一样,只是第一次执行时,accumulator函数的第一个参数为identity,而第二个参数为流中的第一个元素。 |
| U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator combiner) | 在串行流(stream)中,该方法跟第二个方法一样,即第三个参数combiner不会起作用。在并行流(parallelStream)中,我们知道流被fork join出多个线程进行执行,此时每个线程的执行流程就跟第二个方法reduce(identity,accumulator)一样,而第三个参数combiner函数,则是将每个线程的执行结果当成一个新的流,然后使用第一个方法reduce(accumulator)流程进行规约。 |
Reduce和Collect
reduce操作
- reduce:(T identity,BinaryOperator)/reduce(BinaryOperator)-可以将流中元素反复结合起来,得到一个值
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer count2 = list.stream()
.reduce(0, (x, y) -> x + y);
System.out.println(count2);
Optional<Double> sum = emps.stream()
.map(Employee::getSalary)
.reduce(Double::sum);
System.out.println(sum);
collect操作
- Collect-将流转换为其他形式,接收一个Collection接口的实现,用于给Stream中元素做汇总的方法
List<Integer> ageList = emps.stream()
.map(Employee::getAge)
.collect(Collectors.toList());
ageList.stream().forEach(System.out::println);
并行流和串行流
ForkJoin框架
Optional容器
- 使用Optional容器可以快速的定位NPE,并且在一定程度上可以减少对参数非空检验的代码量。
Optional<Employee> op = Optional.of(new Employee("zhansan", 11, 12.32, Employee.Status.BUSY));
System.out.println(op.get());
Optional<Employee> op2 = Optional.of(null);
System.out.println(op2);
@Test
public void test2(){
Optional<Object> op = Optional.empty();
System.out.println(op);
System.out.println(op.get());
}
@Test
public void test3(){
Optional<Employee> op = Optional.ofNullable(new Employee("lisi", 33, 131.42, Employee.Status.FREE));
System.out.println(op.get());
Optional<Object> op2 = Optional.ofNullable(null);
System.out.println(op2);
}
@Test
public void test5(){
Optional<Employee> op1 = Optional.ofNullable(new Employee("张三", 11, 11.33, Employee.Status.VOCATION));
System.out.println(op1.orElse(new Employee()));
System.out.println(op1.orElse(null));
}
@Test
public void test6(){
Optional<Employee> op1 = Optional.of(new Employee("田七", 11, 12.31, Employee.Status.BUSY));
op1 = Optional.empty();
Employee employee = op1.orElseGet(() -> new Employee());
System.out.println(employee);
}
@Test
public void test7(){
Optional<Employee> op1 = Optional.of(new Employee("田七", 11, 12.31, Employee.Status.BUSY));
System.out.println(op1.map( (e) -> e.getSalary()).get());
}
新的日期API LocalDate | LocalTime | LocalDateTime
- 新的日期API都是不可变的,更使用于多线程的使用环境中
@Test
public void test(){
LocalDateTime date = LocalDateTime.now();
System.out.println(date);
System.out.println(date.getYear());
System.out.println(date.getMonthValue());
System.out.println(date.getDayOfMonth());
System.out.println(date.getHour());
System.out.println(date.getMinute());
System.out.println(date.getSecond());
System.out.println(date.getNano());
LocalDateTime date2 = LocalDateTime.of(2017, 12, 17, 9, 31, 31, 31);
System.out.println(date2);
LocalDateTime date3 = date2.plusDays(12);
System.out.println(date3);
LocalDateTime date4 = date3.minusYears(2);
System.out.println(date4);
}
@Test
public void test2(){
Instant ins = Instant.now();
System.out.println(ins);
System.out.println(LocalDateTime.now().toInstant(ZoneOffset.of("+8")).toEpochMilli());
System.out.println(System.currentTimeMillis());
System.out.println(Instant.now().toEpochMilli());
System.out.println(Instant.now().atOffset(ZoneOffset.ofHours(8)).toInstant().toEpochMilli());
}
@Test
public void test3(){
Instant ins1 = Instant.now();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Instant ins2 = Instant.now();
Duration dura = Duration.between(ins1, ins2);
System.out.println(dura);
System.out.println(dura.toMillis());
System.out.println("======================");
LocalTime localTime = LocalTime.now();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
LocalTime localTime2 = LocalTime.now();
Duration du2 = Duration.between(localTime, localTime2);
System.out.println(du2);
System.out.println(du2.toMillis());
}
@Test
public void test4(){
LocalDateTime ldt1 = LocalDateTime.now();
System.out.println(ldt1);
LocalDateTime ldt2 = ldt1.withDayOfYear(1);
System.out.println(ldt2);
LocalDateTime ldt3 = ldt1.withDayOfMonth(1);
System.out.println(ldt3);
LocalDateTime ldt4 = ldt1.with(TemporalAdjusters.next(DayOfWeek.FRIDAY));
System.out.println(ldt4);
LocalDateTime ldt5 = ldt1.with((t) -> {
LocalDateTime ldt6 = (LocalDateTime)t;
DayOfWeek dayOfWeek = ldt6.getDayOfWeek();
if (DayOfWeek.FRIDAY.equals(dayOfWeek)){
return ldt6.plusDays(3);
}
else if (DayOfWeek.SATURDAY.equals(dayOfWeek)){
return ldt6.plusDays(2);
}
else {
return ldt6.plusDays(1);
}
});
System.out.println(ldt5);
}
@Test
public void test5(){
LocalDateTime ldt1 = LocalDateTime.now();
System.out.println(ldt1);
LocalDateTime ldt2 = ldt1.withDayOfYear(1);
System.out.println(ldt2);
LocalDateTime ldt3 = ldt1.withDayOfMonth(1);
System.out.println(ldt3);
LocalDateTime ldt4 = ldt1.with(TemporalAdjusters.next(DayOfWeek.FRIDAY));
System.out.println(ldt4);
LocalDateTime ldt5 = ldt1.with((t) -> {
LocalDateTime ldt6 = (LocalDateTime)t;
DayOfWeek dayOfWeek = ldt6.getDayOfWeek();
if (DayOfWeek.FRIDAY.equals(dayOfWeek)){
return ldt6.plusDays(3);
}
else if (DayOfWeek.SATURDAY.equals(dayOfWeek)){
return ldt6.plusDays(2);
}
else {
return ldt6.plusDays(1);
}
});
System.out.println(ldt5);
}
新的日期API的几个有点
1、之前使用的java.util.Date月份从0开始,我们一般会+1使用,很不方便,java.time.LocalDate月份和星期都改成了enum
2、java.util.Date和SimpleDateFormat都不是线程安全的,而LocalDate和LocalTime和最基本的String一样,是不变类型,不但线程安全,而且不能修改。
3、java.util.Date是一个“万能接口”,它包含日期、时间,还有毫秒数,更加明确需求取舍
4、新接口更好用的原因是考虑到了日期时间的操作,经常发生往前推或往后推几天的情况。用java.util.Date配合Calendar要写好多代码,而且一般的开发人员还不一定能写对。
LocalDate 只包含日月年
public static void localDateTest() {
//获取当前日期,只含年月日 固定格式 yyyy-MM-dd 2018-05-04
LocalDate today = LocalDate.now();
// 根据年月日取日期,5月就是5,
LocalDate oldDate = LocalDate.of(2018, 5, 1);
// 根据字符串取:默认格式yyyy-MM-dd,02不能写成2
LocalDate yesteday = LocalDate.parse("2018-05-03");
// 如果不是闰年 传入29号也会报错
LocalDate.parse("2018-02-29");
}
LocalDate常用转化
/**
* 日期转换常用,第一天或者最后一天...
*/
public static void localDateTransferTest(){
//2018-05-04
LocalDate today = LocalDate.now();
// 取本月第1天: 2018-05-01
LocalDate firstDayOfThisMonth = today.with(TemporalAdjusters.firstDayOfMonth());
// 取本月第2天:2018-05-02
LocalDate secondDayOfThisMonth = today.withDayOfMonth(2);
// 取本月最后一天,再也不用计算是28,29,30还是31: 2018-05-31
LocalDate lastDayOfThisMonth = today.with(TemporalAdjusters.lastDayOfMonth());
// 取下一天:2018-06-01
LocalDate firstDayOf2015 = lastDayOfThisMonth.plusDays(1);
// 取2018年10月第一个周三 so easy?: 2018-10-03
LocalDate thirdMondayOf2018 = LocalDate.parse("2018-10-01").with(TemporalAdjusters.firstInMonth(DayOfWeek.WEDNESDAY));
}
LocalTime 只包含时分秒
public static void localTimeTest(){
//16:25:46.448(纳秒值)
LocalTime todayTimeWithMillisTime = LocalTime.now();
//16:28:48 不带纳秒值
LocalTime todayTimeWithNoMillisTime = LocalTime.now().withNano(0);
LocalTime time1 = LocalTime.parse("23:59:59");
}
LocalDateTime
public static void localDateTimeTest(){
//转化为时间戳 毫秒值
long time1 = LocalDateTime.now().toInstant(ZoneOffset.of("+8")).toEpochMilli();
long time2 = System.currentTimeMillis();
//时间戳转化为localdatetime
DateTimeFormatter df= DateTimeFormatter.ofPattern("YYYY-MM-dd HH:mm:ss.SSS");
System.out.println(df.format(LocalDateTime.ofInstant(Instant.ofEpochMilli(time1),ZoneId.of("Asia/Shanghai"))));
}























 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









