






摘要
相较于之前的工作,该工作不再需要对每个人物进行特定的训练,不再依赖于脸部检测和裁剪,而是直接能生成完整的图像(而不仅仅是面部和嘴唇),同时考虑了广泛的场景(包含可见的身体或者多样的ID)。
同时该工作还构建了一个称为MENTOR的数据集,包含了3d pose和表情的标注,比之前的数据集大一个数量级,同时还包含了动态的手势。
VLOGGER在三个标准上击败了SOTA:1.图像质量;2.ID保留;3.包含生成上半身手势的情况下能生成时序一致的结果;
提出一个两步方案,首先是基于扩散模型的网络根据输入的音频信号预测身体运动和面部表情,这种随机方法对于建模语言信号和姿态、视线、表情之间的微妙映射(一对多)是必要的;第二是提出一种基于最新图像扩散模型的新架构,该架构提供了时间和空间域的控制。通过额外依赖于在预训练期间获得的人物生成先验,该方法展示了这种组合架构如何提高图像扩散模型的能力(这类模型通常难以生成一致的人类图像,比如眼睛)。
同时该架构中除了基础模型外还包含一个超分辨率扩散模型来生成高质量视频。
该方法是基于2d条件控制的视频生成过程,2d控制涵盖全身包括脸部表情,也包含身体和手。
为了生成不同任意长度的视频,使用基于前序帧进行时序outpainting的方法来进行新片段的生成。
最后,由于方法的灵活性,也可以将其拓展至编辑人物视频中特定部分的任务,例如嘴部或者面部的修改。
为了进一步增强鲁棒性和生成能力,构建了一个大规模的数据集(MENTOR),包含在肤色、身体姿态、视角、语音和身体可见性等方面更大的多样性。
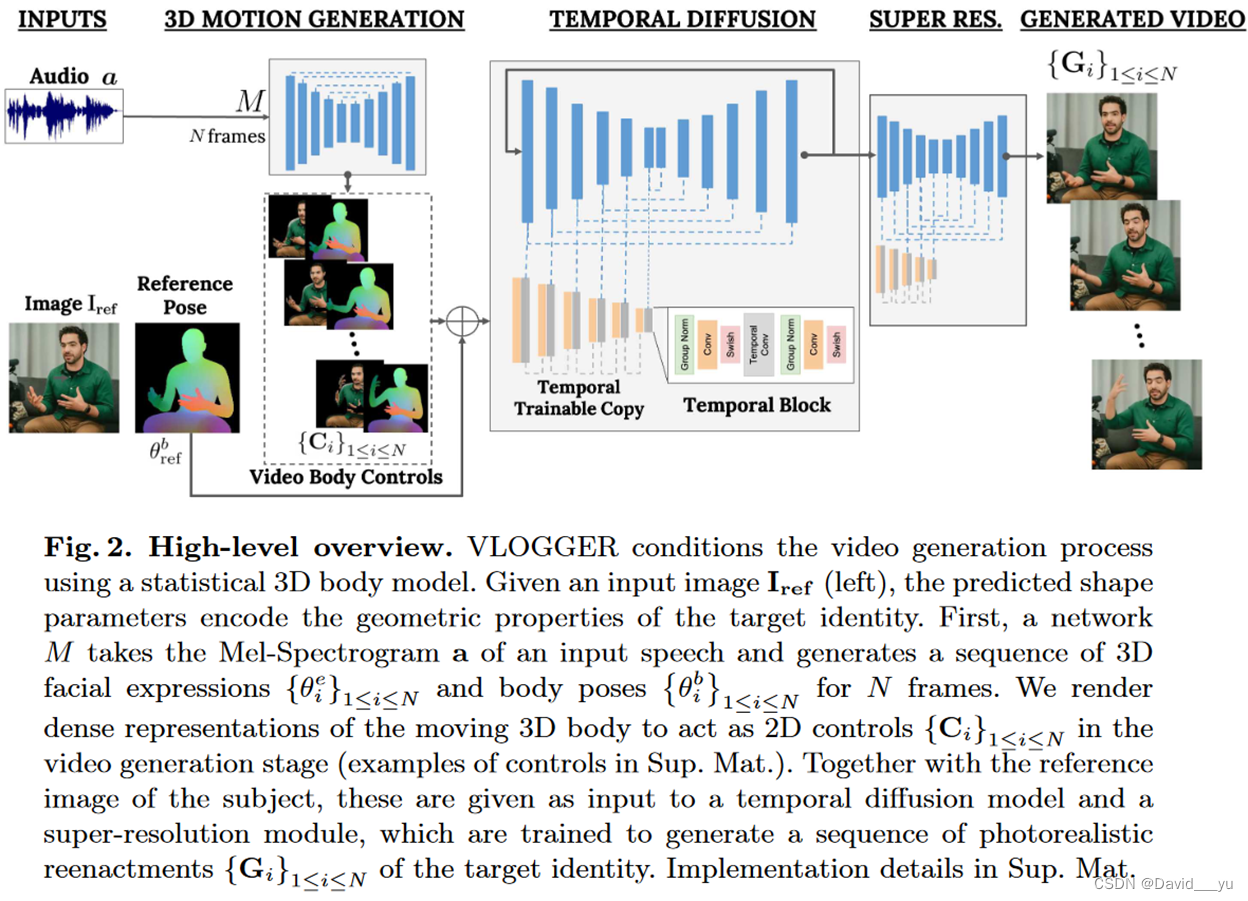
网络设计
1.第一部分:运动预测模块
损失函数
在这个语音生成运动的模块中,采用了直接预测真实分布的方式,同时为了保证连续帧之间的连续性,增加了额外一项连续帧损失,Ltemp,即两帧之间要尽可能接近。这两项损失进行线性加权,同时对身体和表情设置不同的权重;
2.第二部分:视频生成模块
采用类似controlnet的方式,输入N帧warp图像以及对应的控制信号,目标是生成参考任务人物对应的视频。
采用了两阶段训练,第一阶段是在单帧图像上训练为的是先学习到人物驱动的能力,再学习时序生成的能力。
3.第三部分:超分模块
采用级联的方式,在训练生成128x128分辨的基础模型后,再训练了两个128->256以及128->512两种超分模块。
4.第四部分:时序外插
先生成N帧,然后基于其中的N-N’帧迭代外插N’帧。使用DDPM来生成每个视频片段。
MENTOR数据集
视频包含240帧,帧率是24fps,时长是10s,语音是16kHz。
使用三维人体模型进行拟合,过滤掉视频背景变化、人脸和身体被部分遮挡、预测结果抖动以及低质量的视频。
最终得到一个一共包含8M秒(2200小时),80万ID的训练集,以及一个120小时,4千ID的测试集。
点评
随着扩散模型的持续火热,之前的数字人项目几乎都被“重做”了一遍。这一篇文章可以看到基于proxy到image生成的影子,同时保留了那个时代常用的warp方法,同时结合了扩散模型的scaling law,可以在很大的数据量上进行学习。但是从项目的主页来看似乎效果也有很多问题,可能第一个对于MENTOR这么大的数据集,音画同步的检查作者并没有提,这可能是影响最终质量的非常关键因素,另外在包含上半身的情况下基础模型的分辨率仅仅只有128x128,未免显得太小,使得模型对于面部尤其是口型的生成区域占比过小,生成效果变差。总体来讲这为包含身体动作的半身数字人生成提供了一个方向和思路,值得点赞。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









