






SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
摘要:
将人脸交换与唇同步技术相结合,为定制化说话人脸生成提供了一种经济有效的解决方案。然而,直接将现有模型级联在一起往往会在任务之间引入明显的干扰,并降低视频清晰度,因为交互空间仅限于低级语义RGB空间。为了解决这一问题,本文提出了一个创新的统一框架SwapTalk,它在同一潜在空间内完成面部交换和嘴唇同步任务。参考最近在人脸生成方面的工作,作者选择了vq嵌入空间,因为它具有出色的可编辑性和保真性能。为了增强框架对不可见身份的泛化能力,本文在人脸交换模块的训练中加入了身份丢失。此外,在唇形同步模块的训练过程中引入了潜在空间内的专家判别器监督,以提高同步质量。在评价阶段,以往的研究主要集中在同步视听视频中唇部运动的自重构。为了更好地接近现实世界的应用,本文将评估范围扩展到异步音频-视频场景。此外,本文引入了一种新的身份一致性度量,以更全面地评估生成的面部视频中身份随时间序列的一致性。在HDTF上的实验结果表明,本文方法在视频质量、唇同步精度、人脸交换保真度和身份一致性方面明显优于现有技术。
近年来,音频驱动的虚拟数字人说话人脸生成技术取得了重大的技术进展。然而,从用户自定义的肖像中生成与嘴唇同步的谈话脸部视频仍然具有挑战性。在这种情况下,将面部交换与唇同步(lip-sync)技术相结合提供了一种经济实用的解决方案。
最直观的方法是将换脸模型和对口型模型串联起来,以满足该定制任务的要求。然而,这种直接的级联方法存在显著的相互干扰问题。如果在换脸之前进行对唇,换脸模型可能无法准确保留嘴唇的细节,从而影响视听同步的准确性。相反,如果在对唇之前进行换脸,虽然可以有效地实现唇动作的同步,但会降低换脸的质量和生成视频的整体一致性。作者推测这个问题主要是由于两个模型在RGB空间中的直接连接。由于RGB空间包含丰富的面部细节和低级语义,其可编辑性和解耦性受到限制,因此不适合作为两个模型之间交互的基础。此外,直接级联现有模型可能导致清晰度降低。虽然图像重建技术可以部分提高清晰度,但它们也可能损害唇同步的准确性,并在面部交换细节中引入错误。
为了解决前面讨论的问题,作者提出了一个创新的、统一的框架,称为SwapTalk。该框架在一个共享的潜在空间内管理换脸和对口型任务,期望提高这两个任务的准确性并提高整体一致性。受参考工作的启发,本文的框架建立在预训练的矢量量化生成对抗网络(VQGAN)的解耦和高保真vq嵌入空间上。在这个紧凑的潜在空间中学习这两个任务,减少了人脸交换和口型同步模块的计算成本。此外,它通过将高分辨率图像生成留给预训练的VQGAN来简化模型的学习过程。
在开发模块时,作者使用Transformer重新设计了人脸交换模块,并使用来自Stable Diffusion的UNet重新设计了lipsync模块,两者都利用了VQembedding空间。在训练阶段,这些模块是独立训练的。作者在人脸交换模块的训练过程中引入了身份丢失,大大提高了模型处理不可见身份的能力。此外,在vq嵌入空间内利用口型同步专家监督对口型同步模块进行了增强,提高了口型同步的精度。在推理阶段,全面评估了应用这些模块的顺序,并发现在vq嵌入空间内进行口型同步之前执行面部交换可以产生最有效的结果,从而形成了本文的SwapTalk框架的基础。可视化结果请参见图1。
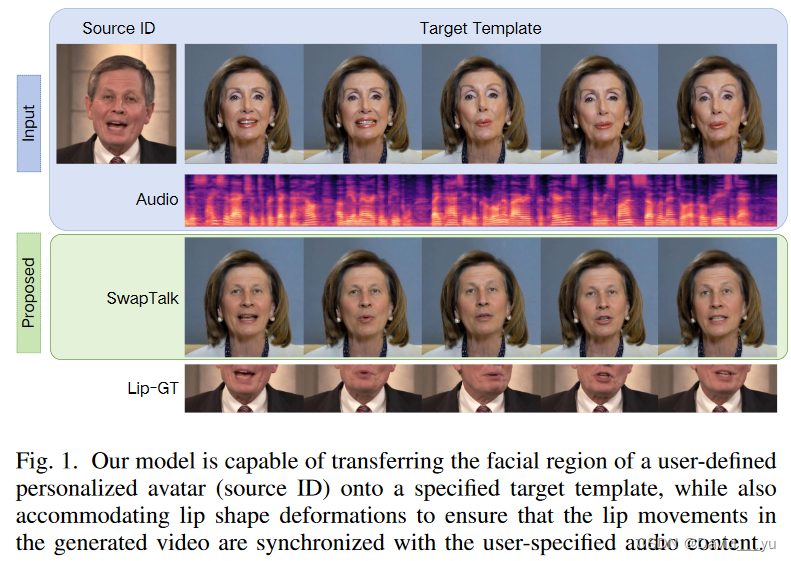
在评估阶段,作者发现以往的口型同步模型的比较主要集中在视听同步视频中口型运动的自构建任务上,不能充分满足实际应用的要求。因此,作者扩大了测试范围,包括在音频和视频不同步的实际情况下的评估,以更好地适应现实世界的应用场景。考虑到本文的框架涉及人脸交换和唇形同步任务,作者设计了两种测试场景:自驱动(音频源与视频中的原始身份匹配)和交叉驱动(音频源与原始身份不同)。这两种场景下的测试可以更准确地反映模型在各种应用条件下的性能。此外,为了评估视频中面部身份随时间序列的一致性,引入了一种新的身份一致性度量。该指标旨在综合评估现有面部视频生成模型的性能,特别是其在保持身份一致性方面的有效性。
基于以上讨论,我们的主要贡献可以总结如下:
- 本文提出了一个统一的框架,在语义丰富且解耦的vq嵌入空间内完成人脸交换和口型同步任务,同时实现口型同步,并保持ID外观和整体一致性。
- 利用预训练的VQGAN和人脸交换模块在训练过程中的身份损失来增强未见身份的泛化和跨时间序列的一致性。此外,作者在vq嵌入空间内引入了一名口型同步专家判别器,以提高口型同步的准确性。
- 作者指出了先前研究中唇同步评估的问题,并建议使用视听非同步设置来更准确地评估现实场景中的唇同步。此外,作者引入了一个指标,旨在合理地评估视频中的面部身份一致性。
方法
作者在一个大型高清面部图像数据集上预训练了一个VQGAN,作为我们框架的基础模型。在此阶段之后,我们冻结了基础模型,并在建立的vq嵌入空间内开发了换脸和对口型模块。图2(b)说明了作者提议的框架的整个管道。它需要三个面部图像——源、目标、参考——以及一个音频片段作为输入。首先,预训练好的VQ编码器将这些人脸图像投影到VQ嵌入空间中,分别表示为Svq、Tvq和Rvq。然后,人脸交换模块将源人脸转换到目标人脸和参考人脸上,分别生成 T~vq和R~vq。随后,唇部同步模块以T~vq作为姿态参考,R~vq作为唇部纹理参考,对音频输入进行积分,预测唇部同步的vq嵌入,记为T_vq。最后,VQGAN解码器将T_vq转换回RGB空间,得到最终的预测T_。预训练的VQGAN以及面部交换和口型同步模块的架构的详细解释分别在第III-A, III-B和III-C节中提供。
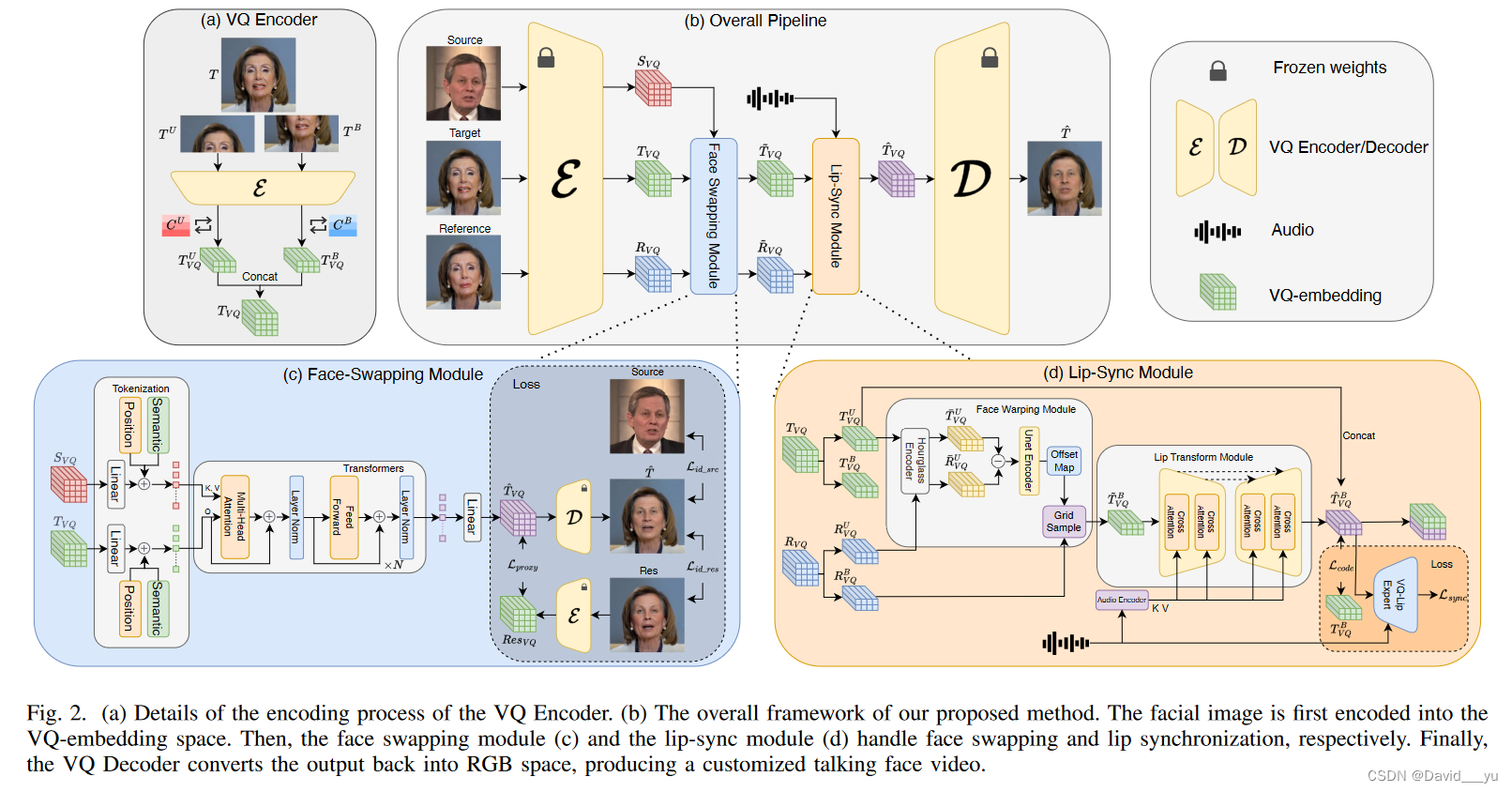
A.预训练VQGAN
按照参考文章的做法,作者分别使用两个码本CU和CB对人脸的上半部和下半部进行编码。作者期望CU从面部上部区域学习头部姿势,而CB从面部下部学习嘴唇运动。每个密码本包含2048个代码,每个代码是一个256维向量。如图2(a)所示,将输入的人脸图像T预处理为320 × 320 × 3的均匀尺寸,并将其分为上半部、下半部,T_U和T_B。VQ Encoder的编码过程如下:
T_U_vq = Quant(Enc(T_U), CU)
T_B_vq = Quant(Enc(T_B), CB)
T_vq = Cat([T_U_vq, T_B_vq])
通过VQ解码器对嵌入的VQ进行解码,重建人脸图像,其中,T_= Dec(T_vq)。
在训练中该模型不仅包含了传统的GAN loss,还包含像素级L1损失和感知损失,以及VQ量化损失,此外,为了增强模型在重建过程中保持身份的能力,作者还在预训练过程中引入了Arcface计算的身份损失,最终的损失L_pretrain = Lgan + λrec * Lrec + λvq * Lvq + λid * Lid
B.人脸交换模块
图2(c)描述了作者在vq嵌入空间内配置的人脸交换模块,由一个tokennization模块和几个transformer编码器组成。该模块处理输入源面和目标面在vq嵌入空间内的潜在表示,分别记为Svq和Tvq。标记化模块首先应用一个线性层来将这些表示调整为与transformer兼容的输入尺寸d。为了进一步定义这些标记的位置和起源,作者引入了位置和语义嵌入。在该过程中,作者将转换后的目标tokens用作查询(Q),将源tokens用作键(K)和值(V)。这种设置通过交叉注意机制促进信息交换和集成。在transformer内部进行多层交互后,再通过另一个简单的线性层将输出转换回vq嵌入空间,形成换脸模块的预测结果(记为T_vq)。
在训练过程中,本文的模块首先从代理换脸模型中学习。假设代理模型的换脸结果为Res,我们使用预训练好的VQ编码器将其编码到VQ嵌入空间中,得到Res_vq = Enc(Res)。这个编码结果作为我们的人脸交换模块的学习目标:Lproxy = ||Res_vq – T_vq||
此外,作者观察到,仅仅从代理模型学习人脸交换并不能有效地推广到新的case。因此,作者使用预训练的V解码器将预测的T_vq重新映射到RGB空间得到T_。在此基础上,引入了T_与源图像人脸(S)之间以及T与代理模型交换结果之间的id损失,增强了生成视频的id一致性,最终的损失为Lfaceswap = Lproxy + λsrc*Lid_src + λres*Lid_res
C.嘴型同步模块
唇形同步模块的设计如图2(d)所示,由人脸翘曲和唇形变换两个子模块组成,分别处理目标和参考向量嵌入输入后的姿态转移和唇形修改。最初,输入被分成脸的上半部分和下半部分:
Tvq = Cat([T_U_vq, T_B_vq]) Rvq = Cat([R_U_vq, R_B_vq])
人脸扭曲模块计算T_U_vq和R_U_vq之间的差异,并将偏移映射和网格样本应用于参考人脸R_B_vq的下部,从而得到目标人脸下部的估计,即T~B_vq ,从而对齐姿态差异。随后,唇部变换模块在输入音频的引导下,在嘴部区域进行T~B_vq的变形,预测与语音同步的vq嵌入T^B_vq 。lip变换模块使用了UNet结构(表示为Fldm_unet(·,·)),它可以包含条件输入。将条件输入通过交叉注意注入骨干网络结构,影响8x和4x的下采样特征层,对输入音频进行HuBERT(记为EncH(·))预处理,提取语音特征,然后将其作为条件注入唇形变换模块,得到人脸与语音同步的vq嵌入的下半部分的估计,通过串联得到完整的预测结果:
T^vq = Cat([T_U_vq, T^B_vq])
在训练过程中,目标和参考输入来自同一视频的不同帧,而音频与目标保持同步。在此阶段,口型同步模块预测的T^B_vq的真值应为T_B_vq,这两个vq嵌入之间的L1距离用作潜在空间中的编码损失。此外,与参考工作类似,作者还在vq嵌入空间中训练了一个对唇专家来监督唇同步。该模块以下面部的vq嵌入和音频(记为A)为输入,分别使用EncExpert VQ(·)和EncExpert A(·)两个编码器进行编码,计算特征层之间的余弦相似度为唇同步得分。这个阶段的唇同步损失定义为Lsync,总计的损失为Llip-sync = Lcode + λsync * Lsync
在推理阶段,方法根据任务类型而有所不同。对于那些涉及同步输入音频和目标视频的自驱动任务,用目标视频第一帧的vq嵌入来初始化R_vq。这种策略可以防止唇形泄漏问题。相反,在跨ID驱动任务中,输入音频和目标视频之间缺乏同步,R_vq被赋予与T_vq相同的值。此外,我们在推理过程中绕过面部扭曲模块,直接设置T~B_vq等于T_B _vq,然后通过唇形变换模块实现音频与唇形运动的对齐。
D.一致性指标
在说话脸生成任务中,保持生成视频的身份一致性是至关重要的。因此,作者提出了一个创新的度量标准来衡量身份一致性。对于给定生成的视频片段{T(i)},使用预训练的人脸识别网络(不同于之前用于训练VQGAN和人脸交换的Arcface架构)来提取特征Fi = Encface(T(i))。然后,我们计算这些特征与源面部特征之间的平均余弦相似度,将此度量定义为视频的身份一致性评分。
实验
A.数据集
a)预训练数据:在VQGAN的预训练阶段,使用了三个公共数据集:FFHQ, CelebAHQ和VFHQ。此外,从自有数据中整合了大约143k张包含33k个不同身份的图像,以丰富模型的学习材料。
b)对口型和换脸数据
作者使用HDTF数据集来训练对口型和换脸模块。这个数据集包括412个视频,每个视频都与一个不同的演讲者相关联。作者将这些视频分成5586个10秒的片段,保持每秒25帧的帧率。数据集以9:1的比例分割,采用身份隔离策略来确保测试集中的说话者不会与训练集中的说话者重叠。采用这种策略的目的是精确地评估模型推广到不可见身份的能力。对于人脸交换数据集,将HDTF训练视频中的每一帧视为具有相同身份的单独图像,并使用Roop随机执行人脸交换,该方法产生了总共109k个训练数据对(Source, Target, Res)。
为了进一步提高两个模块的泛化性能,作者扩展了训练数据集。对于人脸交换模块,额外的数据来自VQGAN预训练数据集。作者通过创建随机对并使用Roop生成代理交换的面孔来生成216,000个训练样本。与此同时,唇形同步模块还增加了8.5万个10秒的视频片段,其中包括1.5万个私人收藏的独特ID。这些剪辑像HDTF数据集一样处理,确保数据处理的一致性。
在数据预处理阶段,作者采用与FFHQ相同的对齐方法,使用68个地标检测技术对人脸进行对齐,然后裁剪并缩放到512像素的分辨率。在对VQGAN进行预训练时,将损失函数的超参数设为λrec = 1.0,λvq = 1.0,λid = 1.0。同时,批量大小设置为12,学习率调整为4.5e−6。然后,在训练人脸交换模块时,进一步设置λres = λsrc = 1.0,将批大小调整为8,学习率为5e−5。另外在训练lip-sync模块时,也设置λsync = 0.3,选择更大的批大小为20,并将学习率提高到1e−4。所有这些模块都在PyTorch中使用Adam优化器实现,并在具有8个Nvidia RTX3090 gpu的服务器上进行了训练。















 1009
1009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









