






摘要
视频跳切提供了一个突然的,有时是不必要的观看体验的变化。作者提出了一个新的框架来平滑这些跳切,在说话的头部视频的背景下,作者利用视频中其他源帧的人物外观,将其与由DensePose关键点和面部地标驱动的中级表示融合。为了实现运动,作者在剪切处周围的端点帧之间插入关键点和地标,然后使用关键点和源帧的图像转换网络来合成像素。由于关键点可能包含错误,作者提出了一种跨模态注意力方案,以便在每个关键点的多个选项中选择最合适的源。通过利用这种中级表示,该方法可以获得比其他基线方法更好的结果。作者在视频中演示了该方法,例如剪切填充词,暂停,甚至随机剪切。实验表明,该方法即使在跳切中头部旋转或剧烈移动等具有挑战性的情况下,仍然可以实现无缝过渡。
综合来说,作者提出了一种新的算法,通过运动引导重新合成来平滑说话视频中的跳切,这需要在真实的运动插值和保持身份之间取的平衡,为了改进ID保持,需要更大的信息瓶颈,例如更多的关键点或者更大潜编码,然而更多的潜在代码使运动插值具有挑战性。作者通过(1)使用更可靠和更密集的DensePose关键点和面部landmark进行引导;(2)设计基于初始DensePose关键点对应关系的交叉注意力模型,改进图像扭曲,允许合成网络从视频中关注更多帧并选择最合适的特征。(3)采用平滑线性插值和插值消融增强,训练模型处理跳切端的帧之间缺失的对应关系。实现表明,该方法可以无缝跨越各种跳切。
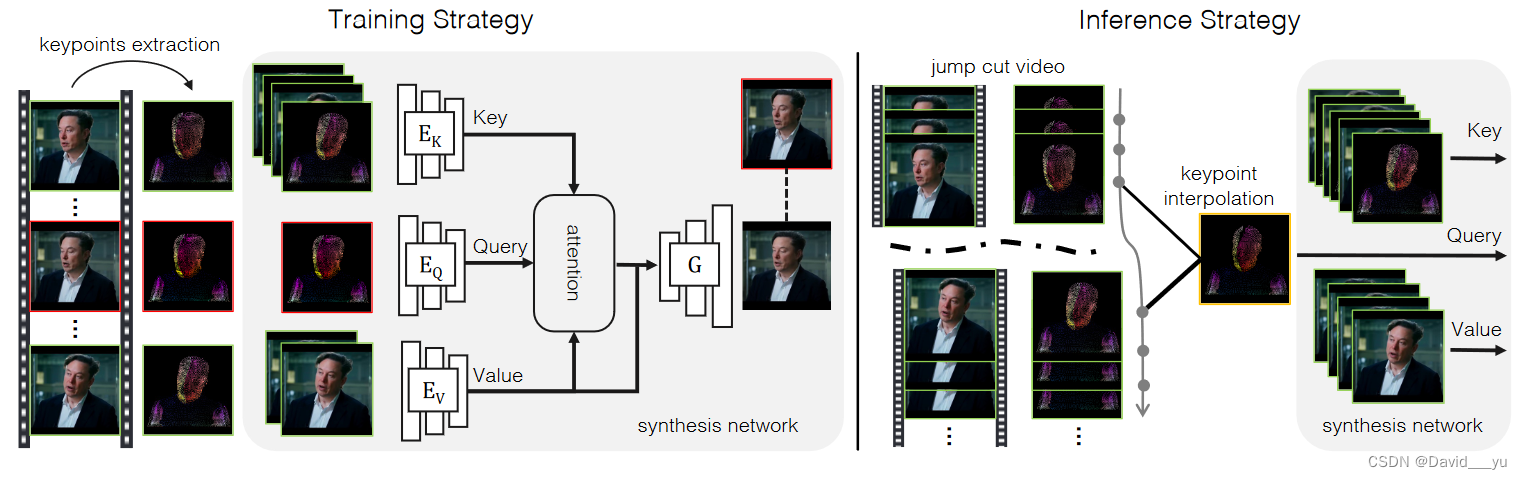
方法
作者以两阶段解决跳帧平滑的问题: (1)在训练阶段,给定一组源图像,网络学习使用相应的DensePose关键点作为运动指导来生成一张目标图像;(2)在推理阶段,通过跳帧两端帧的DensePose关键点的插值和视频中其他可用帧来生成每一个中间帧;
- DensePose关键点表征
作者使用DensePose关键点和脸部landmark作为运动引导来合成相应的图像。给定一张输入图高和宽分别为H、W的输入图像I,及其连续的DensePose P,即每个身体部位的图像空间UV坐标图,通过量化UV值从DensePose中提取DensePose关键点。对于每个身体部位的UV图,将其离散为nxn个单元,每个单元都代表一个关键点,本文只关注只出现一个人上半身的视频,因此每张图像有K=14xnxn个DensePose关键点(其中14是DensePose表示中上半身部位的数量)。关键点坐标和UV值是落在相应单元中像素坐标和UV值的平均值,这些带有UV的关键点根据坐标被分割到大小为HxW的网格中,然后得到离散化的DensePose IUV,如果DensePose中没有UV值落在单元格中,则对应的关键点不可见,并且不会溅射。
- Cross model attention warping
给定一组N个源图像,其各自的DensePose关键点和目标DensePose关键点,作者希望通过转移源图像的外观来生成逼真的目标图像。基本思想是利用这种密集对应将源图像特征扭曲到目标密集关键点,然后将扭曲的特征馈送到类似于Co-Mod GAN的生成器中,以生成相应的逼真目标图像。在这一过程中,获取一个高质量的warp特征非常重要,然而基于DensePose的对应关系往往是不准确的,当有多张源图像时,很自然的网络会选择最接近于目标图像的源图像,而不是做简单的平均,因此作者采用了注意力机制来实现这一选择能力。
作者采用了最常用的注意力机制,其将Q作为目标的表征,K作为DensePose关键点的表征,V作为源图像特征的表征,对于q和k,使用基于StyleGAN2的编码器结构,在最后一个投影层将特征映射到dk维度,当编码源图像DensePose关键点时,将其和源图像级联在一起进行编码,源图像的外表特征也使用相似结构的编码器进行编码。所有这些编码器以输入的1/4分辨率进行输出,比如图像和离散DensePose关键点输入的尺寸是256x256,编码器输出nq=64x64个q,nk=64x64xN个k,其中N表示N张图像,根据注意力公式计算后重新reshape回64x64的尺寸,然后喂给生成器来生成对应的目标图像。
使用基于交叉注意力模型得到的扭曲场,一方面可以使得DensePose关键点的特征表示更加鲁棒,纠正DensePose的不对齐,另一方面该方法可以在每个位置的多个源图像中选择最相关的源特征,当使用整个视频的帧作为源时,这一机制对于跳切平滑特别有用。
- 跳切过渡的递归合成
在创建跳切平滑过渡时,首先在跳切结束帧之间创建一个线性插值的密集关键点序列,然后相应生成每个中间帧。当遮挡和解除遮挡发生在结束帧之间时会导致问题,比如当说话人头部从一边旋转到另外一边时,其脸部的部分关键点会消失,另一部分关键点又会出现,我们只能在两端插入可见的关键点,这会导致关键点集不完整。作者在训练中模拟了这种情况,只使用所有源图像中可见的关键点作为目标,并使生成器学习对空洞进行填补,生成逼真的图像。由于密集的关键点只对前景部分建模,作者额外地将两个端点帧特征与扭曲的特征连接在一起作为输入,使网络学会有选择地从端点帧复制背景以及未被DensePose建模的其余部分,如头发。进一步的,作者提出递归合成,如图5所示,对于长度为T的过渡序列,从离结束帧最近的两帧,即I1和IT开始合成,然后以之前合成的帧作为结束帧向中间移动,以提供背景信息。

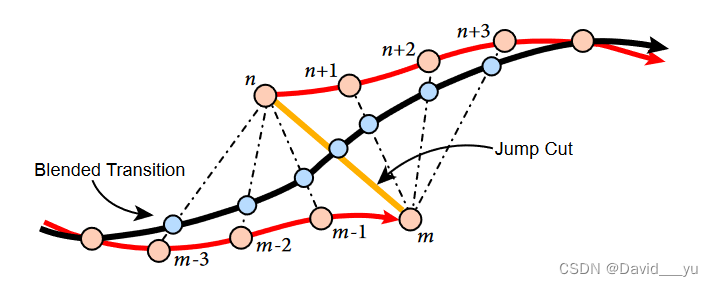
- 混合过渡
对于一个剪切,剪切前的帧称为Im,剪切后的帧称为In,他们对应的DensePose关键点为xm和xn,作者提供了两种方式来进行Im和In之间的无缝过渡。
第一种方式是在两帧之间添加T个中间帧,每一个中间帧It由xm和xn的DensePose的线性插值来组成,然而在某些情况下伴随着无音频的新帧会导致尴尬、断断续续的演讲。例如当一个人说得很快,但中间有简短的“嗯”时,如果删掉这些填充词,并用沉默的新帧填充,那么最终的视频听起来就会含糊不清。
因此,作者提供了另一种方法,称为混合过渡,以避免这种音频伪影。与Zhou等人类似,进行合成混合帧,用合成过渡代替小时间邻域周围的原始帧,使视频从Im之前的帧平滑过渡到In之后的帧,如图所示。
使用帧范围定义一个领域,[m-H,m]和[n,n+H],其中H在实验中的设置是4。对于[m-H,m]之间的每一帧Ii,其与In进行混合,混合的权重αi∈[0,1/2H,…,1/2],DensePose关键点以xi’ = (1-αi)*xi + αi*xn来进行混合。相似的,[n,n+H]之间的每一帧Ij,与Im以[1/2,(H+1)/2H,…,1]的权重进行混合,xj’ = (1-αj)*xj + αj*xn。混合帧通过的DensePose关键点合成,混合过渡方法不改变视频中的现有帧数因此不会遇到音频插入问题。

实验部分
图中展示了不同剪切case下的效果,包含大的头部旋转,头部的前后运动等。
- 数据集和预处理
该方法的目标是将跳切平滑应用程序用于包含上半身的谈话视频。请注意,这是一个比许多现有的只包含面部部分的谈话头部视频数据集更广泛(因此更具挑战性)的裁剪方案。因此作者从AVSpeechDataset数据集收集了600段720P的视频用于训练,50段视频用于测试。每一段视频都包含一个人在静态背景下面向摄像机或采访者说话10-20秒。作者使用Detectron来检测每帧的DensePose身体部分的坐标图,并将DensePose uv图量化以转化为关键点。为了更准确低表达面部表情,使用HRNet添加脸部关键点用于增强DensePose关键点。对于训练,根据检测到的DensePose边界框进行裁剪,并将大小缩放为256x256,在训练阶段,作者随机选取两帧源图像帧和一帧目标图像帧,在推理时可以很容易的拓展到包含更多的源图像。
讨论与局限
该方法可以在不同的跳切情况下创造平滑的过渡,特别是头部运动。然而,当有复杂的手势移动时,可能导致失败。合成真实的手更具挑战性,因为1。手部运动的视频帧通常有运动模糊,这使得网络很难区分真手或假手。2.) DensePose本身不能模拟精细的手部特征,比如手指。3.) 手的动作比头的动作更复杂。例如,当说话者的手从紧握到伸展,或者从手掌朝向相机到背面朝向相机时,这种非平面运动不能用线性插值的关键点来建模。
补充
网络包含三个基于StyleGAN2结构的编码器:1.Ev用于编码源图像特征作为value;2.Ek编码源关键点作为key;3.Eq编码目标关键点作为q,三个编码器除了输入层以外的结构都是一样的,对于Eq将3通道DensePose关键点和68个高斯模糊的人脸关键点级联在一起产生一个71通道的输入,对于Ek将源图像和所有关键点一起输入产生一个74通道的输入,对于图像编码器Ev,输入是3通道RGB图像。
对于图像生成器部分,采用Co-Mod GAN中的网络结构,接受1/4分辨率的warp图像作为输入并生成输出图像,网络是一个Unet结构的网络。生成器的训练分为两个阶段,第一阶段使用完整的Densepose关键点和脸部关键点,在第二阶段为了模拟线性插值导致的DensePose关键点缺失,只对目标使用所有原图像中可见的DensePose,是的生成器学习弥补缺失并生成逼真图像。
















 89万+
89万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









