






题目复现
2024年美赛C题以2023年温网男单决赛德约科维奇vs阿尔卡拉斯为切入点, 提出“动量”的概念,让我们证明“动量”是否存在,对选手实时表现程度的预测,以及如果存在动量,影响最大的因素是什么。比赛给出了2023年温布尔登网球比赛中的男单比赛数据和表格说明。

数据分析与处理
数据分析
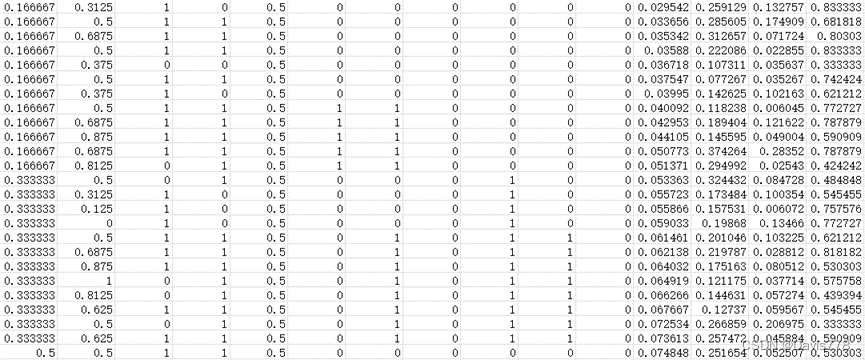
针对官方给出的男单数据.csv表格,我对其中的数据进行了筛选分析,以我个人对体育竞技赛事的了解,分析出了其中的几个重要数据,以p1为例,分别有p1_sets、p1_games、p1_score、server、p1_ace、p1_winner、p1_double_fault、p1_unf-err、p1_net_pt_won、p1_net_pt、p1_break_pt_won、p1_break_out、p1_distance_run、speed_mph。我没有对于最后几列关于球落点的处理,我认为可能影响不太大(但可能多少有点影响),由于全是字母,不知道如何转为数字处理,所以本文没有进行处理。根据上述表明的重要数据,我们通过计算得到了以下指标,建立了如下的评价体系:
| A | 是否在上一分中得分 |
| B | 是否为发球者 |
| C | 本局是否回击得分 |
| D | 本局是否发球得分 |
| E | 本game得分领先进度 |
| F | 是否出现非受迫性失误 |
| G | 对方发球机会与实际得分比 |
| H | 当前比赛获胜局数 |
| I | 上网次数与上网得分之比 |
| J | 此set的领先进度 |
| K | 发球配速 |
| L | 比赛运动总里程 |
| M | 前三个point的运动里程 |
| N | 上一个point的运动里程 |
通过将题给数据分析建立成上述评价指标体系,方便之后的输入机器学习或者深度学习模型中进行训练。
数据处理
将上述构建成一个具体的指标评价体系后,我们对异常值进行了处理,比如point中的AD(advantage)转换为了55,未测到的speed(NA)我们进行了剔除。此时各指标的数值大小大不相同,有的只有个位数,有的到了几百。接着为了将所有数值特征变化到一个共同的尺度,我们进行Min-Max标准化处理,得到最后的指标数值。
接着为了验证我们指标的正确性,我们以point为“时间”坐标轴(也就是总得分),以当前选手是否得分为结果(1为得分,0为未得分),使用SPSS对上述指标进行二元逻辑回归处理,处理结果如下:
| real measurement | 0 | 1 | Percentage correct | |
| result | 0 | 383 | 237 | 61.8 |
| 1 | 202 | 423 | 67.7 | |
| Overall percentage | 64.7 |
可以看出,提出的这些指标还算是正向的,只是准确率稍低,在之后的问题我对其进行了优化。
问题一
针对上文的指标体系,本文主要采用机器学习的方法对“动量”和比赛波动情况进行预测,挑选了几个经典的机器学习模型进行验证(注意,本文是以总得分为时间轴,因为两个人加起来的得分是按照自然数递增的,所以不考虑使用时序预测模型,而采用解释性更强的机器学习模型)。结果如下:
| ACC | Recall | F1score | AUC | |
| LightGBM | 0.695 | 0.731 | 0.711 | 0.774 |
| Random Forest | 0.691 | 0.713 | 0.707 | 0.773 |
| BP | 0.701 | 0.737 | 0.717 | 0.772 |
| Logistic Regression | 0.666 | 0.689 | 0.679 | 0.722 |
| SVC | 0.692 | 0.712 | 0.708 | 0.755 |
| BernoulliNB | 0.659 | 0.643 | 0.659 | 0.713 |
可以看出,LightGBM和BP的预测准确性是最高的,我们用BP神经网络对“经典战役”中的德约科维奇表现进行了实时预测分析,
index = df[df.match_id=='2023-wimbledon-1701'].reset_index(drop=True).index
test = dataset.iloc[index]
train = dataset.drop(index,axis=0)
model = MLPClassifier(random_state=30)
model.fit(train[columns].values,train['label'].values)
pred = model.predict_proba(test[columns].values)
pred = pd.DataFrame({'score':pred[:,1]})
match1 = pred.iloc[:45]
match2 = pred.iloc[45:126]
match3 = pred.iloc[126:195]
match4 = pred.iloc[195:259]
match5 = pred.iloc[259:]
plt.figure(figsize=(12, 6), dpi=80, facecolor='w')
plt.plot(match1.index,match1.values)
plt.plot(match2.index,match2.values)
plt.plot(match3.index,match3.values)
plt.plot(match4.index,match4.values)
plt.plot(match5.index,match5.values)
plt.xlabel("Points")
plt.ylabel("Performance")
plt.savefig('走势.png',dpi=500)
plt.show()以几个赛点为转折点,得到了表现程度图如下

问题二
问题二主要是让我们分析哪些因素对比赛的波动影响最大,根据上面的指标体系,其实可以大致分为几个方向:个人能力,临场心态(比如比分落后或领先)和疲惫程度(跑动距离)。我们利用Kendall’s Tau、Pearson和Spearman对相关性进行检验。
| Symbol | Correlation coefficient | P-value |
| Pearson | 0.486 | <0.001 |
| Spearman | 0.484 | <0.001 |
| Kendall’s Tau | 0.396 | <0.001 |
三种方法得出的相关性都非常统计显著,这是由它们的P值来证实的,这些P值非常小,远低于常用的显著性水平0.05。这意味着观测到的相关性非常不可能是由偶然因素造成的。
接着使用一元线性回归对体系进行验证。
| 0LS Regression Results | |
| R-squared: | 0.236 |
| Adj. R-squared: | 0.236 |
| F-statistic: | 404.1 |
| Prob(F-statistic): | 1.63e-78 |
| Log-Likelihood: | -771.90 |
| AIC: | 1548 |
| BIC: | 1558 |
| Durbin-Watson | 2.080 |
回归结果表明,F统计量和非常小的P值表明模型是有效的,至少有一个自变量对因变量有着显著的影响,这说明模型室友信息量的,并能捕捉到自变量与因变量之间的关系。 且Durbin-Watson统计量接近2,表明残差之间没有自相关,这符合良好回归模型的一个重要假设。总的来说,我们的模型验证了至少有一个指标以上对选手得分有着显著的影响,也就是“动量”是可以存在且影响着选手的得分情况。
问题三
针对上述指标体系二元逻辑回归表现一般的情况,我们对数据进行了聚合处理,从之前的每point记录胜负聚合为每set记录胜负,得到了1100余条数据,在对这些数据进行二元逻辑回归,结果如下:
| real measurement | 0 | 1 | Percentage correct | |
| result | 0 | 388 | 167 | 69.9 |
| 1 | 148 | 405 | 73.2 | |
| Overall percentage | 71.6 |
可以看到整体正确率得到了提升,说明我们的聚合操作是有效的,为进一步的分析或模型开发提供了坚实的基础。
基于上述聚合后的数据,考虑到特征可能有点过多(15维),我们采用了利用PCA降维处理,再输入高斯贝叶斯进行预测,我们将这种新方法命名为Gaussian Probabilistic Dimensionality Reduction,依旧是对比几个网络的结果。
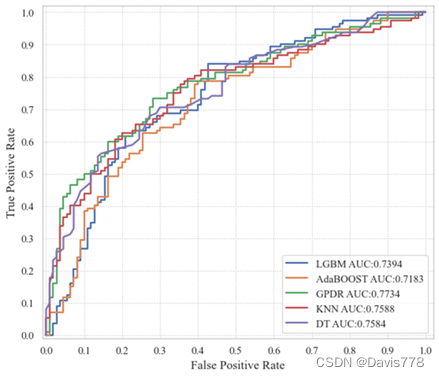
可以看出我们的GDPR的AUC是最高的。最后再对“经典战役”的德约科维奇表现进行预测。
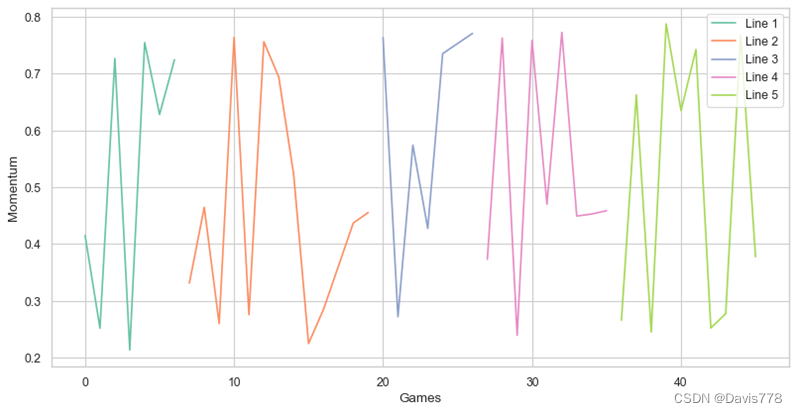
可以看到,相较于问题一提出的模型,GPDR有着更符合实际情况的预测。
对于聚合后的指标数据,我们计算了其在GDPR模型下的重要性得分,以确定哪些因素是极为重要的。(这里的O是之前定的,后面删掉了,这里没改)
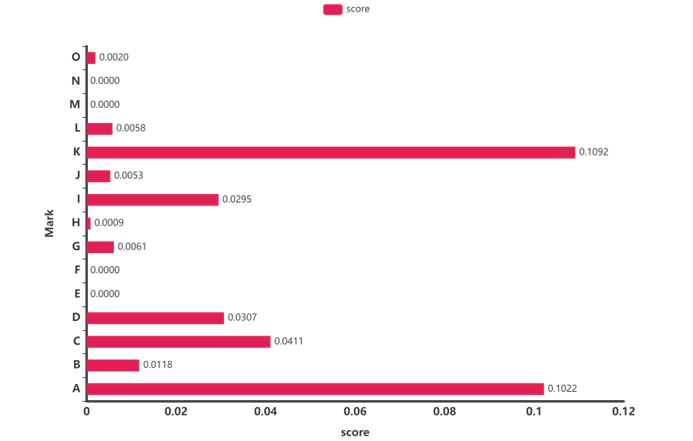
结果可以看出,大部分指标都是有效的,尤其是K(Leading progress of the game )、A(Whether or not you scored in the previous point)、C(Whether or not to score a comeback)等与比赛过程中的波动极为相关,这说明在比赛中,个人能力和心态是主要因素,面对较大比分落后时,选手面临的压力可能会较大。
问题四、五
其实就是让我们在对模型进行泛化性实验,这里提供一下往年的温网数据:https://github.com/JeffSackmann/tennis_slam_pointbypoint/tree/master
我们对2023女单的比赛进行了泛化性实验,总而言之,我们构建的指标体系不仅适用于特定体育项目,也提供了一个可推广的框架,适用于其他体育赛事的预测分析。这为评价和理解运动员表现的波动提供了有力支持,从而可以更全面地评估和预测体育竞技赛事的结果。
总结
本次MCM的C题还是比较有挑战性的,本文只是根据我们的方法给出了一个拙劣的思路供大家参考,事实上使用时序预测模型可能效果会更好,只是他的时间都是随机数,可能这里需要调整,然后指标体系可能也需要调整,我们的指标设定不一定完全符合真实的体育赛事影响因素,比如有些在特征重要性的分中出现了0的情况,但由于时间问题,我们也只做到了这里。















 4260
4260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









