







基于huffman压缩算法的文件压缩项目
今天我们来看看一个小项目基于huffman压缩算法的文件压缩项目.这个项目很简单就是使用我们自己实现的堆和huffman树,然后开始着手来对文件里
面
的内容进行一系列操作! 所以我总结了一下这个项目最关键的三个部分就是:
1.huffman树的构建(1.必须使用模板来构建(可能会存放自定义类型来构建) 2.要拥有在huffman树当中构建huffman编码的功能)
2.文件的压缩(将我们的文本文件的内容转换成由huffman编码构成的文件),等待解压缩)
3.文件的解压(将huffman编码文件转换成正常的文本文件)
完成这三大步,我们的文件压缩也算是就完成的一个大概了,现在我们开始对三大块进行个个击破!
huffman树的构建
关于huffman树的概念我以前是有一篇博客的:huffman树的构建原理,大家不明白可以点进去看一看,里面有huffman树的基本概念. 为了节约篇幅
我这里只讲讲为什么huffman树算法为什么会压缩文件?? 它是如何节约空间的? 请看下图:
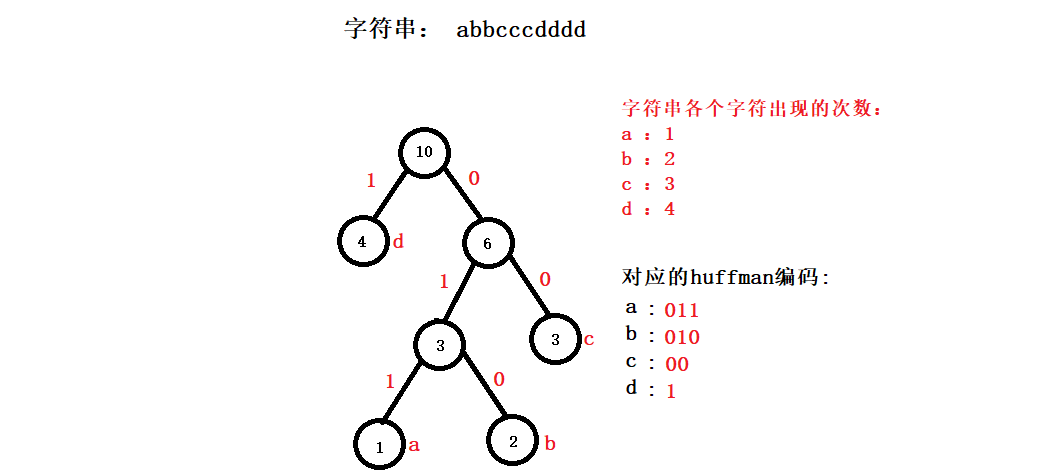
首先我们以每个字符的出现的次数作为构建huffman树的键值,然后对棵huffman树的每一个叶子结点生产huffman编码,这是最基本的工作.
我们已经得到了字符串中abcd的huffman编码了,它们分别是: '011' '010' '00' '1',注意由于这里的huffman编码都是01组成的,所以我们很容易
想到按位存储,这个时候这个字符串的huffman编码形式就是 0110100100000001111,我们将它按位写进文件中,这个文件占用19个比特位,所以占用
三个字节. 而原文件中有10个字符他们都是char类型,所以占用10个字节. 这就是huffman压缩算法的基本思想.
所以出现的越频繁次数越多的字符它的huffman编码越短,占用的空间越少. 出现较为少的字符他们的huffman的编码虽然长,但是出现的次数少.并且
我们的huffman编码是按位存储的,所以这里的压缩效率就显现出来了. huffman压缩算法压缩率高的情况就是 出现特别多的重复字符,只有极少数的
是别的字符(比如 abbbbbbbbbbbbbbbb). 效率低的情况下就是每个字符出现的次数都差不多很平均.(比如abcdabcd)
现在项目的思路渐渐地清晰了起来了:
1.统计:首先读取一个文件,统计出256个字符中各个字符出现的次数以及字符出现的总数.
2.建树:按照字符出现的次数,并以次数作为权值简历哈夫曼编码树,然后生产各个字符的huffman编码.
3.压缩:再次读取文件,按照该字符对应的编码写到新的编码文件当中.
4.加工:将文件的长度,文件中各个字符以及他们的出现次数,写进编码文件中.
5.解压:利用压缩文件和配置文件恢复出原文件.
6.测试:观察解压出的文件和原文件是否相同,再通过Beyond Compare 4软件进行对比,验证程序的正确性.
文件的压缩过程
压缩过程就是利用我们刚刚所统计出的个个字符对应的huffman编码,然后重新读取文件中的数据,根据读到的每一个字符将该字符对应的huffman编
码写入到配置文件中,还有将每个字符和出现次数写入这个文件(写到文件头和文件尾 看你的喜好了). 有人会问为什么? 这个下面会提到. 经历这两
个阶段,文件的压缩过程
也基本就结束了.
现在我来解释一下为什么要往配置件中写入每个字符和它的出现次数!
我们生成了这个配置文件之后,我们肯定是要删除
掉原文件的(如果不删原文件,压缩有什么意思?
 ) ,但是之后的解压缩还要把huffman编码转为
) ,但是之后的解压缩还要把huffman编码转为
) ,但是之后的解压缩还要把huffman编码转为
字符. 但是... 你源文件都没有了,你的huffman树也随着没有啦,所以我们再之后的解压缩的时候还需要这颗huffman树,怎么办? 重建huffman
树! 所以这就是将每个字符和出现的次数写到文件中的原因. 这就是原因! 接下来我们来看看这段的代码! 我注释尽量详细:
typedef long long LongType;
//这是这个项目当中要用到的自定义类型. 里面存放有字符,字符出现个数,还有它的huffman编码.
struct CharInfo
{
char _ch; // 字符
LongType _count; // 出现次数
string _code; // huffman code
bool operator != (const CharInfo& info) const
{
return _count != info._count;
}
CharInfo operator+(const CharInfo& info) const
{
CharInfo ret;
ret._count = _count + info._count;
return ret;
}
bool operator<(const CharInfo& info) const
{
return _count < info._count;
}
};
class FileCompress
{
typedef HuffmanTreeNode<CharInfo> Node;
//压缩文件
void Compress(const char* filename)
{
assert(filename);
//这是专门用来以后往配置文件中写入的字符和字符出现次数准备的.
//为了在解压缩的时候进行构建huffman树.
struct _huffmanInfo
{
char _ch;
LongType _count;
};
//打开文件
FILE* fout = fopen(filename, "rb");
cout << errno << endl;
assert(fout);
// 1.统计字符出现的次数
char ch = fgetc(fout);
while (ch != EOF)
{
//_infos[]是一个CharInfo类型的数组,一共有256个元素. 每一个元素维护一个字符.
_infos[(unsigned char)ch]._count++;
ch = fgetc(fout);
}
// 2.构建huffman tree
CharInfo invalid;
invalid._count = 0;
HuffmanTree<CharInfo> tree(_infos, 256, invalid);
// 3.构建huffman编码
GenerateHuffmanCode(tree.GetRoot());
//4.开始压缩文件
string compressFile = filename;
compressFile += ".huffman";
//c_str()的用法就是返回一个正规的C字符串的指针,内容和本string相等
FILE* fIn = fopen(compressFile.c_str(), "wb");
assert(fIn);
_huffmanInfo info;
size_t size;
//这里先往配置文件中写入出现过的字符中,每个字符信息和每个字符的出现次数.
//用来解压缩的时候重建huffman树
for (size_t i = 0; i < 256; i++)
{
if (_infos[i]._count)
{
info._ch = _infos[i]._ch;
info._count = _infos[i]._count;
//利用二进制写入,这个结构体.
size = fwrite(&info, sizeof(_huffmanInfo), 1, fIn);
assert(size == 1);
}
}
info._count = 0;
size = fwrite(&info, sizeof(_huffmanInfo), 1, fIn);
assert(size == 1);
char value = 0;
int count = 0;
//让fout放置到文件开始
fseek(fout, 0, SEEK_SET);//SEEK_SET 开头 SEEK_CUR 当前位置 SEEK_END 文件结尾
ch = fgetc(fout);
//将huffman编码写入到配置文件中.
//好好体会这里的位运算的过程,value中写满了8个位,就往配置文件里面写一次
while (!feof(fout))
{
string& code = _infos[(unsigned char)ch]._code;
for (size_t i = 0; i < code.size(); ++i)
{
value <<= 1;
if (code[i] == '1')
value |= 1;
else
value |= 0;
++count;
if (count == 8)
{
fputc(value, fIn);
value = 0;
count = 0;
}
}
ch = fgetc(fout);
}
if (count != 0)
{
value <<= (8 - count);
fputc(value, fIn);
}
fclose(fIn);
fclose(fout);
}
protected:
CharInfo _infos[256];
};
我们要注意代码中出现了一个feof这样的函数,为什么我们没有直接使用eof判断呢?我们以后要尽量运用这些函数,不去使用EOF判断. 这个函数的实
现,有兴趣的人类可以下去了解一下.
文件的解压缩过程
先去读配置文件,构建huffman树和huffman编码,用压缩文件里的编码去huffman树中查找,找到对应的叶子结点. 就把叶子结点的字符写入到解压缩
文件中. 所以总结起来也就是那么几步:
1.读取配置文件,统计所有字符的个数.
2.构建huffman树,读解压缩文件,将所读到的编码字符的这个节点所含的字符,写到解压缩的文件中,直到将压缩文件读完
3.解压缩完成之后,利用软件测试,再然后测试一下压缩率.
好啦话不多说 上代码 分析过程:
//构建huffman编码的函数.
void GenerateHuffmanCode(Node* root)
{
if (root == NULL)
{
return;
}
if (root->_left == NULL &&root->_right == NULL)
{
string& code = _infos[(unsigned char)root->_w._ch]._code;
Node* cur = root;
Node* parent = cur->_parent;
while (parent)
{
if (parent->_left == cur)
{
code.push_back('0');
}
if (parent->_right == cur)
{
code.push_back('1');
}
cur = parent;
parent = cur->_parent;
}
reverse(code.begin(), code.end());
}
GenerateHuffmanCode(root->_left);
GenerateHuffmanCode(root->_right);
}
//解压缩文件
void Uncompress(const char* filename)
{
//为了区分解压出来的文件,不覆盖原文件名.
assert(filename);
struct _huffmanInfo
{
char _ch;
LongType _count;
};
string uncompressFile = filename;
//让pos等于找到第一个'.'出现的的下标位置
size_t pos = uncompressFile.rfind('.');
assert(pos != string::npos);
//从0开始取pos个字符
uncompressFile = uncompressFile.substr(0, pos);
uncompressFile += ".unhuffman";
FILE* fIn = fopen(uncompressFile.c_str(), "wb");
size_t size;
assert(fIn);
FILE* fout = fopen(filename, "rb");
//往解压缩文件中维护的_infos表当中写数据,然后利用这个_infos表生产huffman树.
while (1)
{
_huffmanInfo info;
size = fread(&info, sizeof(_huffmanInfo), 1, fout);
assert(1 == size);
if (info._count)
{
_infos[(unsigned char)info._ch]._ch = info._ch;
_infos[(unsigned char)info._ch]._count = info._count;
}
else
break;
}
//重新构建huffman树.
CharInfo invalid;
invalid._count = 0;
HuffmanTree<CharInfo> tree(_infos, 256, invalid);
//解压缩
Node* root = tree.GetRoot();
GenerateHuffmanCode(tree.GetRoot());
//统计一共有多少个数据.
LongType charcount = root->_w._count;
char value;
value = fgetc(fout);
Node* cur = root;
int count = 0;
//往解压缩文件当中开始写入数据. 在这里直接针对性的先统计出所有元素的个数.
//然后按照个数进行循环,写完循环结束.
while (charcount)
{
for (int pos = 7; pos >= 0; --pos)
{
if (value & (1 << pos)) //1
cur = cur->_right;
else //0
cur = cur->_left;
if (cur->_left == NULL && cur->_right == NULL)
{
fputc(cur->_w._ch, fIn);
cur = root;
--charcount;
if (charcount == 0)
{
break;
}
}
}
value = fgetc(fout);
}
fclose(fIn);
fclose(fout);
}
最后我们终于成功的,大概列出来代码的框架和主题思想,接下来就是我在写代码当中碰到的一些BUG和错误,我将这些总结起来.
(1).刚开始写的时候测试发现如果待压缩文件中出现了中文,程序就会崩溃,将错误定位到构建哈夫曼编码的函数处,最后发现是数组越界的错误
,因为如果只是字符,它的范围是-128~127,程序中使用char类型为数组下标(0~127),所以字符没有问题. 但是汉字的编码是两个字节,所以可能会
出现越界,解决方法就是将char类型强转为unsigned char,可表示范围为0~255.
(2)文件恢复的时候需要注意那些问题?
有些特殊字符在处理需要注意一下,比如'\n',我的程序中有一个函数就是读取一行字符,但是若是该字符本身就是一个'\n'呢? 这就非常的棘手
了. 对于这个问题一定好好好处理,读取配置文件时若读到了'\n',则说明该字符就是'\n',应该继续读取它的次数.
(3)解压缩文件生成后丢失了大部分的内容
这个BUG困扰我很久,最后为了测试我让程序打印出在压缩的时候它写入了多少次,然后再让程序在解压缩的时候打印自己读出了多少次. 最后我发现
在解压缩读出的时候出现了问题,究其原因我又发现了很久,我发现它过早的退出了循环,那么真相只有一个就是程序读到了EOF,但是我在文本末尾
才会是EOF啊,因为解压缩读取是二进制方式读写的,文件这么长! 他可能碰巧读到了EOF对于的二进制代码. 然后就退出啦.
解决方案: 使用feof()函数或者记录字符数据个数然后根据个数循环,这两种方法都可以解决上述问题.
这个项目其实就是利用我们学习过的堆和huffman树的实际应用来解决我们实际生活的一些小问题,这种小项目还需要我们多多练习呢~
利用代码解决生活的问题才是编程的意义,所以呢我们需要将理论和实际相结合~ 这样我们的学习就会越来越好~
这个项目的所有代码在我的github传送门在这里:
戳这里进入奇幻世界















 3780
3780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









