






什么是文件压缩?
文件压缩是指在不丢失文件数据信息的前提下,依靠一定的算法对数据进行处理,缩减数据量以减少存储空间,提高其存储,传输和处理的效率,或者按照一定的的算法对数据进行重新组织,从而达到减少数据冗余的一种数据处理手段。
为什么需要压缩?
1.压缩数据的存储容量,减少存储空间。
2.可以提高数据的传输效率,提高通讯的效率
3.文件压缩也是对文件安全的一种保护方法,增强了数据在传输过程中的安全性。
压缩的方法:
压缩的方法有很多种,而压缩的本质是让文件变小,减少文件所占的存储空间,因此无论我们采取怎样的方式,都不能离开这样的主题,因此在这里我主要呈现了两种处理数据的思想:
1.将文件中的每个字节找一个更短的编码
如果我们要处理的数据为 ABBBCCCCCDDDDDDD
| 字符 | 静态等长编码 | 动态不等长编码 |
| A | 00 | 100 |
| B | 01 | 101 |
| C | 10 | 11 |
| D | 11 | 0 |
如果采用静态编码的方式进行压缩:
00010101 10101010 10000000 00000000
如果采用动态编码的方式进行压缩:
10010110 11011111 11111100 00000000
这样处理的话我们就将一个16个字节的源文件处理成了一个4字节压缩文件,达到压缩的目的。
2.对文件中的重复数据进行替换处理达到压缩的效果,
比如源文件为mnoabczxyuvwabc123456abczxydefgh
在这段源文件数据中我们可以发现abc这段数据重复了多次,因此我们可以通过(距离,长度)键值对的方式对重复数据进行替换,从而达到压缩数据的目的
压缩后: mnoabczxyuvw(9,3)123456(18,6)defgh
我在这里首先介绍基于Huffman树的压缩方式:
首先什么是Huffman树:
从二叉树的根节点到二叉树的所有叶子节点得路径长度与相应权值的乘积之和成为该二叉树的带权路径长度WPL。
而带权路径最小的二叉树就称为Huffman树。
在基于Huffman树的文件压缩项目上,我将整个过程分为4步:
1.打开被压缩的文件,获取每个字符出现的次数
2.根据每个字符出现的次数构造Huffman树

在F中取两棵根节点权值最小的二叉树,作为左右子树构造一棵新的二叉树,新二叉树根节点的权值为其左右子树根节点的权值之和。
3。通过Huffman树获取每个字符的编码
以字符串中每个字符出现的次数作为权值构建Huffman树
每棵Huffman树的左分支为0,右分支为1

然后遍历每条到叶子节点的路径得到字符的Huffman编码:
A 100 B 101 C 11 D 0
编码时要注意,因为可能出现8位存不满的情况,我们需要对其进行补0操作,因此在解压缩时对于解压缩的控制应用字符次数进行控制,否则会出现错误。
得到Huffman编码后,我们需要对其进行reverse操作,因为我们是由叶子节点向根节点逆向溯源去还原Huffman树的
4.读取源文件,并对源文件中每个字符根据得到的Huffman编码进行改写。
将改写结果写到压缩文件中,直到文件结束
而在压缩完毕之后,我们应该对压缩文件的信息进行分析处理,而为了完成解压缩要使解压缩文件与源文件保持一致,还应在压缩文件中包含以下信息:源文件后缀,字符出现总行数,每个字符及其出现次数,来方便进行解压缩时还原Huffman树。
压缩文件的格式:

解压缩:
解压缩的过程同样分为四步:
1.从压缩文件中获取源文件的后缀
2.从压缩文件中获取字符次数的总函数
3.从压缩文件中获取每个字符出现的次数
4.重建Huffman树
解压压缩数据的处理细节:
1.从压缩文件中读取一个字节的数据ch
2.从根节点开始,按照ch的8个比特位的信息从高到低的顺序遍历Huffman树
a)如果该比特位为0,则取当前节点的左孩子,否则取右孩子,直到遍历当前路径的叶子节点,编码解析完毕,该字符被解析成功
b)将被解析成功的字符写入到文件中
c)如果在遍历过程中8个比特位的数据解析完毕后,仍然没有到达叶子节点,那么重复1的操作,再取一个字节的数据。
3.如何将字符串中存放的次数转换为数字,这里使用atoi函数
接下来我们介绍第二种压缩算法:LZ77
首先大概介绍一下LZ77算法,LZ77算法是一种通用的数据压缩算法,而所谓的通用则是指高压缩算法对于数据的类型没有什么限定,因此推广性更高,实用性更高,该算法奠定了今天大多数无损数据压缩的核心。
压缩原理及过程:
LZ77是基于字节操作的通用压缩算法,他的原理就是将源文件中重复的字节使用(距离,长度)这样的键值对的方式进行替换处理,达到压缩数据的目的:
举例: 待压缩数据为 mnoabczxyuvwabc123456abczxydefgh
压缩后为: mnoabczxyuvw(9,3)123456(18,6)defgh
LZ77压缩算法的核心思想就是利用两个缓冲区:查找缓冲区和前向缓冲区
当LZ77压缩时,数据是在一个滑动窗口中进行处理得,压缩开始,先加载一个滑动窗口大小的数据:
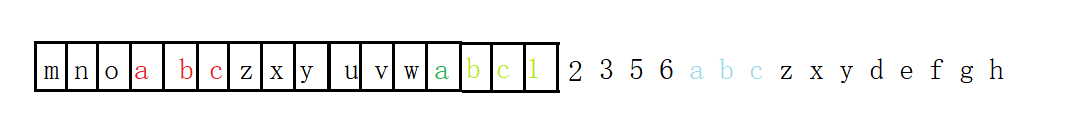
随着压缩的进行,滑动窗口被分两部分:已经查找过的数据和待压缩的数据
我们也可以将两个窗口分别理解为查找缓冲区和前向缓冲区

前面我们提到LZ77算法是通过对源文件中重复数据的处理达到压缩数据的目的,但这里存在一个问题就是这个重复数据的长度该如何界定?
由我们举出的例子可以看出,重复的数据会被加工成(距离,长度)的键值对的方式进行存储,因此我们对重复数据的界定就这样来定义:
1个字符,不替换,因为如果对单个字符去使用键值对的方式进行存储,替换处理后的数据变大,违背了压缩的基本要求。
2个字符,不替换,因为对两个字符长度的数据进行处理,处理后的数据大小没有发生变化。
因此我们对于重复数据长度的界定就应该是至少为3个字符,才进行替换操作。
设定 MIN_MATCH=3
而最大匹配长度就应该为总长度+前面匹配的三个字符:
MAX_MATCH=255+3=288
压缩开始后,每扫描到一个新字符,用当前字符与其后的两个字符组成字符串,然后在查找缓冲区中查找,如果找到匹配的字符串,使用(距离,长度)对进行替换,否则将该字符串写入压缩文件。

如上图所示:假如当前字符为‘a,那么将”abc”作为字符串在查找缓冲区内查找到9的位置找到匹配串,长度为3,将压缩结果写入文件得:
mnoabczxyuvw(9,3)
此时查找缓冲区向后“吞噬”三个字符串,同时前向缓冲区向后移动三位,继续压缩,直至结束。
但这时就存在一个问题,通过前面的方法我们是可以对文件进行压缩处理,但这效率太低,我们如何高效的找到最长的匹配串呢?
方法一:暴力破解法:即循环向前寻找匹配串
我在这里用一次查找的过程来做以演示:

假设当前匹配到了“a”的位置,将start位置的字符与ps位置额的字符进行比较,不匹配,则ps一直向前走。

当ps走到“a”的位置时,start与ps比较,匹配到了三个字符,进行替换,但此时查找并不能结束,因为此时不一定是最长匹配。

start与ps比较,匹配了6个字符,比上次匹配到的字符串长,因此找到了新的最长匹配串,用(距离,长度)键值对进行替换。
缺点:该算法虽然可以是实现我们的需求,但时间复杂度为O(n^2),处理的效率太低,这样的话一旦遇到了较大的待压缩文件,这样暴力求解的方式会大大影响压缩的时间和效率。
方法二:采用哈希桶来实现
采用哈希桶的方式,我们将每三个相邻的字符构成的字符串首字符作为索引保存在哈希桶中,压缩时每遇到新字符,计算该字符串所构成的串的哈希地址,然后将该字符串的首字符在窗口中的索引插入哈希桶,如果当前桶为空,说明未找到匹配,否则可能会找到匹配,在定位到具体的匹配串的位置进行匹配即可。
1.哈希桶的大小分析
而在分析时我们发现,对于哈希桶的大小我们应该如何界定?
如果按照单纯的想法,3个字符那就有(2^24)种取值方式,桶的个数则需要(2^24)个,而索引的大小为2个字节,这样算下来桶就要占到(2^25),也就是32M字节,这是一个非常大的开销,而且在压缩的过程中,表中的数据是在不断变化的,这样的话对于程序而言会严重影响程序运行的效率,因此我们在这里将哈希桶的个数界定为(2^15)也就是32K。
2.哈希表的结构
避免哈希冲突:
前面我们分析了为了保证程序运行的效率,我们将哈希桶的个数界定为了(2^15)个,而原本需要的哈希桶个数应该为(2^24)个,哈希桶的减少造成了key->value时,目标地址可能会被占用,正所谓一山不容二虎,因此必然会产生哈希冲突,而如果采用开散列来解决的话,链表中的节点要不断的申请和释放,影响效率,因此在这里我们将哈希表由一块连续的内存空间组成,同时分为两个部分,每部分大小为WSIZE(32K),

如图所示:prev指向整个内存的起始位置,而因为内存是连续的,因此head=prev+WISZE;我们将prev和head看成两个数组,prev数组用来保存三个字符串首字符的索引位置,head的索引为三个字符通过哈希函数计算得出的哈希值
3.哈希函数
而对于哈希函数的设计我们则要遵循一个原则:简单,离散。
因此在这里我们将哈希函数设计成这样:
A(4,5) + A(6,7,8) ^ 8(1,2,3) + 8(4,5) + 8(6,7,8) ^ C(1,2,3) + C(4,5,6,7,8);
给一个简单的说明:A是指3个字节中的第1个字节,B是指第2个字节,C指第3个字节
A(4,5)是指第一个字节的第4,5位二进制码。
//HashAddr 上一个字符串计算得到的哈希地址
//而本次的哈希地址是通过上一次的哈希地址结合当前字符ch算出的;
//而这里将哈希地址与哈希掩码相与的目的是防止哈希地址越界
void HashTable::HashFunc(USH& HashAddr,UCH ch)
{
HashAddr = ((HashAddr) << H_SHIFT()) ^ (ch) & HASH_MASK;
}
USH HashTable::H_SHIFT()
{
return (Hash_Bits + MIN_MATCH -1)/MIN_MATCH;
}4.哈希表的构建
也就是字符串的插入过程:
a) 获取当前字符ch 在窗口中的位置为pos;
b) 用ch及与ch紧邻的两个字符构成当前的字符串 CurStr
c) 插入当前字符串 CurStr
这时我们注意,由于插入字符串的过程与压缩的过程是伴随进行的,而当前字符ch的位置pos也会一直向后走,这样的话就一定会造成pos的位置大于WSIZE,因此我们采用了哈希地址与哈希掩码相与的方式来防止越界。
// hashAddr:上一次哈希地址 ch:先行缓冲区第一个字符
// pos:ch在滑动窗口中的位置 matchHead:如果匹配,保存匹配串的起始位置
void HashTable::InsertString(USH& hashAddr, UCH ch, USH pos, USH& macthHead)
{
// 计算哈希地址 HashFunc(hashAddr, ch);
_prev[pos & WMASK] = _head[hashAddr];
macthHead = _head[hashAddr];
_head[hashAddr] = pos
}
此时,当压缩进行到‘a’的位置时,此时abc,bcz,czx,zxy,xyu.....345,456都已经插入到哈希表中了,前向缓冲区中的第一个字符ch为“a”,因此我们将“a”与其后的“bc”组成当前字符串“abc”在查找缓冲区中寻找匹配串:
1.计算“abc”字符串的哈希地址HashAddr
2.检测head[HashAddr]的位置是否为空,如果为空则说明没有找到匹配,说明“abc”在查找缓冲区还没有出现过,,不为空则将“abc”插入哈希表。
3.我们假设此时“abc”字符串计算得出的哈希地址为3
4.然后通过matchhead来判断是否发生匹配:
则有以下的查找过程

5.查找最长匹配串
首先我们知道,在压缩的过程中进行着不断查找及将字符串插入的过程,字符串插入后,如果matchhead为空,则说明之前未遇到过这个字符串,否则则表示在查找缓冲区中曾遇到过该字符串,此时我们就顺着匹配链去一次寻找所有的匹配串,直到找到最长的匹配串。
//matchHead----哈希匹配链的起始位置
UCH Lz77::maxLongMatch(USH matchHead, USH& curMatchDist)
{
UCH curMatchLen = 0;
UCH maxlen = 0;
USH pos = 0;
//哈希链的最大遍历长度,因为在插入函数时pos与WMASK相与可能会破坏匹配链,造成死循环
UCH Chain_Len = 256;
USH limit = _start > MAX_DIST ? _start - MAX_DIST : 0;
do
{
//待匹配字符串的最大位置
//[pStart,]
UCH* pStart = _pWin + _start;
//找到匹配串的位置
UCH* pCurMatchStart = _pWin + matchHead;
UCH* pEnd = pStart + MAX_MATCH - 1;
//找单条链的匹配长度
while (pStart < pEnd && *pStart == *pCurMatchStart)
{
pStart++;
pCurMatchStart++;
curMatchLen++;
}
//对已经查找过的最佳匹配进行更新
if (curMatchLen > maxlen)
{
maxlen = curMatchLen;
pos = matchHead;
}
} while ((matchHead = _ht.GetNextList(matchHead)) > limit && Chain_Len--);
curMatchDist = _start - pos;
return maxlen;
}
注意:在查找最长匹配的过程中,我们定义了一个最大遍历长度Chain_Length,定义它的意义是什么呢?
因为我们在插入函数时使用pos与WMASK相与可能会破坏匹配链,造成死循环,因此我们为确保插入函数的安全以及查找最长匹配链的查找过程不越界,给他的遍历加以Chain_Length的限制。
如果没有找到最长匹配,那么直接将字符串写入即可。
这里我们容易忽略的一点是:在我们完成匹配链的插入后,
我们想象中的数据是这样的:mnoabczxyuvw(9,3)123456(18,6)defgh
但是在压缩过程中,我们只是将(距离,长度)对理解为带括号的形式便于我们分别与源字符的区别,但在实际过程中
我们压缩后的数据是这样的:mnoabczxyuvw93123456186defgh
编译器是无法识别(距离,长度)对与源文件字符之间的区别的,因此我们要加以标志符来区别:
void Lz77::WriteFlag(FILE* pOutF, UCH& chFlag, UCH& bitCount, bool IsChar)
{
chFlag <<= 1;
//检测是否为距离长度对
if (IsChar)
chFlag |= 1;
bitCount++;
if (8 == bitCount)
{
fputc(chFlag, pOutF);
chFlag = 0;
bitCount = 0;
}
}
而随着滑动窗口的不断移动,右侧窗口中的数据可能存在不足的情况,因此需要把右窗数据(32k)移至左窗,但要注意的是:窗口中数据的移动,必须要更新哈希表!
void Update()
{
//将右窗口的匹配位置更新到左窗口
//更新head
for (size_t i = 0; i < HASH_SIZE; i++)
{
if (_head[i] >= WSIZE)
_head[i] -= WSIZE;
else
_head[i] = 0;
}
//更新prev
for (size_t i = 0; i < WSIZE; ++i)
{
if (_prev[i] >= WSIZE)
_prev[i] -= WSIZE;
else
_prev[i] = 0;
}LZ77解压缩的过程:
解压缩模块我分为了两个部分:
一、.解压缩前对压缩文件的处理工作
a).首先我们需要获取源文件的大小来作为解压缩是否结束的标志
//获取标记的大小
size_t flagSize = 0;
int offset = 0 - sizeof(flagSize);
fseek(fIn, offset, SEEK_END);
fread(&flagSize, sizeof(flagSize), 1, fIn);
//获取源文件大小
ULL fileSize = 0;
fseek(fIn, 0 - (sizeof(flagSize) + sizeof(fileSize) + flagSize), SEEK_END);
fread(&fileSize, sizeof(fileSize), 1, fIn);b) 其次由于我们还要获取区分标志符,来区分当前字符到底是源文件中的字符还是(距离,长度)对
ULL Flag = 0;
char flagLeftCount = -1;
while (fileSize)
{
//读取标记 并判断是源字符还是键值对内的数据
if (flagLeftCount < 0)
{
Flag = fgetc(FInFlag);
flagLeftCount = 7;
}
//是键值对
if (((Flag >> flagLeftCount) & 1) == 1)
{
//长度距离对
USH matchdist = 0; //距离
fread(&matchdist, 2, 1, fIn);
UCH matchlen = fgetc(fIn); //长度
fflush(fOut);
fseek(FPreMatch, 0 - matchdist, SEEK_END);
fileSize -= matchlen;
while (matchlen != 0)
{
UCH ch = fgetc(FPreMatch);
fputc(ch, fOut);
//在压缩时可能会出现重叠的情况跟
fflush(fOut);
matchlen--;
}
fseek(fOut, 0, SEEK_END);
}
//说明是源字符
//直接打印
else
{
UCH ch = fgetc(fIn);
fputc(ch, fOut);
fileSize--;
}
flagLeftCount--;
}二、解压缩过程
1)读取头部信息:即获取原文件的后缀,因为在压缩的时候,直接保存在了第一行,因此,直接使用getline() 获取值即可。
2).根据所获取到的标志符将对数据的解压缩处理分为两部分:
a) 0 : 如果是‘0’则说明当前字符为源文件字符,直接写入
b) 1 : 如果为'1'则说明当前字符为(距离,长度)对,则应将当前文件指针的位置向前寻找,找到匹配字符串的位置,然后从目标位置读取目标长度,将该字符串写入
c) 随着解压缩的进行向后继续处理,直至达到源文件的大小,则解压缩结束。















 977
977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









