







大数据处理 — mapreduce的简易见解
MapReduce是一种编程模型,用于大规模数据集的并行运算. 概念 Map(映射)和 Reduce(归约), 是他们的主要思想,它极大方便了编程人员在不会分
布式并行编程的情况下,将自己的程序运行在分布式系统上. 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对(Mapper的输入键值)映
射成一组新的键值对(Mapper的输出键值),指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组(既相同的键数剧
发送到同一个reduce上,进行合并处理).
那么这个MapReduce编程模型究竟是怎么样的呢? 他实际上说了这样的一个事儿:已知手头上有许许多多(成万上亿)PC机,现在有一个复杂的任务,
需要处理海量的数据,数据在哪里呢? 数据实际上是随机的存储于这些个PC机器上,我们不需要统一地将数据一起存到一个超大的硬盘上,数据可
以据可以直接散布在这些个PC上,这些PC自身不仅是许许多多个处理器,也是许许多多个小硬盘.
这些PC机器分为三类,第一类称为Master,Master是负责调度的,相当于工地的工头,第二类叫Worker,相当于干活的工人. Woker进一步分为两
种,一种Worker叫做Mapper,另一种叫Reduce。 假设我们有一个巨大的数据集,里面有海量规模的元素,元素的个数为M,每个元素都需要进行同
一个函数的处理,于是Master将M分为许多小份,然后每一份分给一个Mapper来做,Mapper干完活,将自己的那一份的结果传给Reducer,Reducer
之后进行统计汇总各个Mapper传过来的结果,得到最后的任务的答案,当然,这是最简单的表述,因为实际上Master的任务分配过程是很复杂的,
包括任务时间,任务出错情况等等.
再举个例子来说,统计一系列文档中的词频,文档数量规模很大,有1000万个文档,英文单词的总数可能只有3000。 那么input就为10000000,
output = 3000. 于是我们搞了10000个PC做Mapper,100个PC作为Reducer,每一个Mapper做1000个文档的词频统计,统计之后把凡是和同一个word相
关的统计中间结果传给同一个Reducer做汇总. 比如某个Reducer负责词表中前30个词的词频统计,遍历10000个PC,这10000个Mapper PC将自己处理
后和词表中前30个词汇相关的中间结果都传给这个Reducer做最终的处理分析,至此MapReduce最核心的流程已经说明白了.
其实MapReduce讲的就是分而治之的程序处理理念,把一个复杂的任务划分为若干个简单的任务来做,另外,就是程序的调度问题,那些任务给那些
Mapper来处理是一个着重考虑的问题. MapReduce的根本原则是信息处理的本地化,哪台PC持有相应要处理的数据,哪台PC就负责处理该部分的数据
这样做的意义就在于可以减少网络通讯负担.下面附一张图帮大家理解:
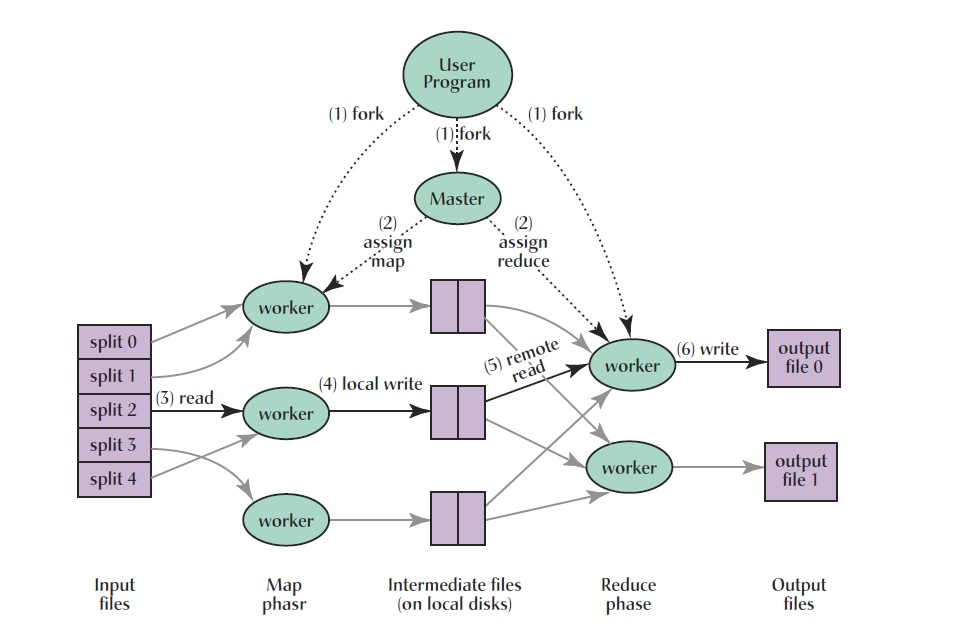
一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数.
图中执行的顺序都用了数字标记了.
1.MapReduce库先把user program的输入文件划分为M份,每一份通常有16MB到64MB,如图所示最左边的split0~4;
然后使用fork将用户仅此拷贝至集群内其他机器上.
2.user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业或者Reduce作业)
,worker的数量也是有用户指定的
3.被分配了Map作业的worker,开始读取对应分片的输入数据,Map作业数量由M决定,和split一一对应; Map作业从输入数据中抽取出键值
对,每一个键值对都作为参数传递给map函数,mapper函数产生的中间键值会调用OutPutCollector组件写入环形缓冲区.
4.唤醒缓冲区的中间键值对会定期写入本地磁盘当中,并且被分为R个区,R的大小是由用户定于的,将来每一个区会对应一个Reduce作业;这些中间
键值对的位置会通报给master,master负责将信息转发给Reduce worker.
5.master通知分配了Reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每一个Map作业产生的中间键值对都可能映射到所有R
个不同分区),当Reduce worker把它负责的中间键值对都读过来后,先对他们进行排序,使得相同键的键值对聚集在一起. 因为不同的键可能
会映射到同一分区也就是同一个Reduce作业,所以排序是必须的.
6.reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个
分区的输出文件中
7.当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program代码.
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中,用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MaoReduce程序处
理. 整个过程中,输入数据是来自底层分布式文件系统的,中间数据是放在本地文件系统的,最终输出数据是写在底层分布式文件系统的,而且我
们要注意Map/Reduce作业和map/reduce函数的区别: Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每一个输入键值对,
Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,reduce作业最终也对应一个输出文件.
MapReduce的工作流程
MapReduce其实是分治算法的一种实现,所谓分支算法就是"分而治之",将大的问题分解成相同类型的子问题(最好具有相同的规模),对子问题进行
求解,然后合并成大问题的解. MapReduce就是分治法的一种,将输入进行分片,然后交给不同的task进行处理,然后合并成最终的解,
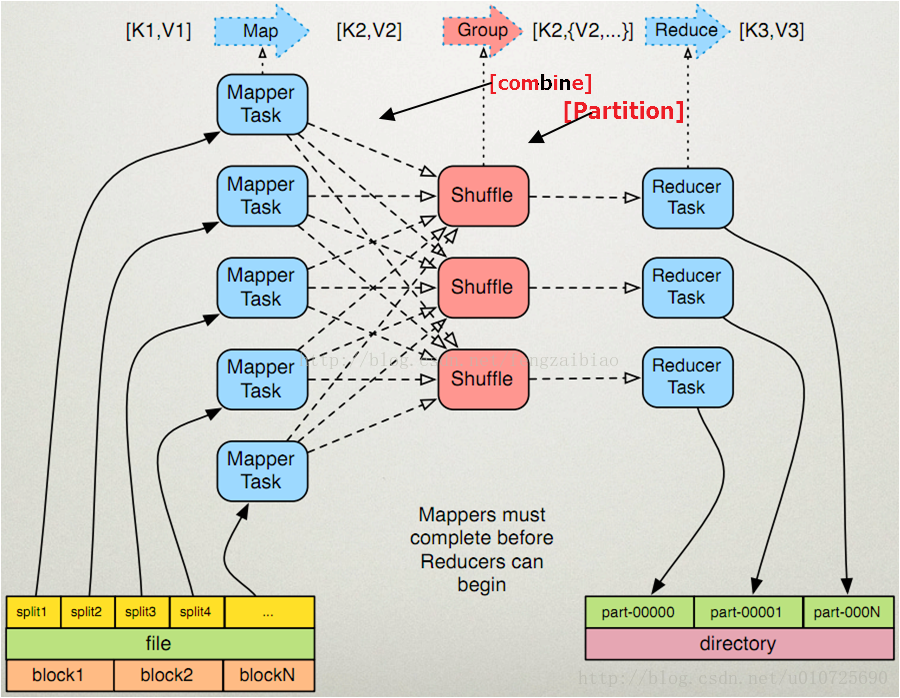
MapReduce实际的处理过程可以理解为Input->Map->sork->combine->partition->Reduce->Output
1.input阶段:数据以一定的格式传递给Mapper,有TextInputFormat,DBInputFormat,SequenceFileFormat等可以使用
2.Map阶段对输入的key,value进行处理,既map(k1,v1) -> list(k2,v2),
3.sork阶段对于Mapper的输出进行排序,可以定义排序规则.
4.combine阶段对sort之后又想用key的结果进行合并
5.partition阶段,将Mapper的中间结果按照Key的范围划分为R份,默认使用HashPatitioner,也可以自定义划分函数.
6.Reduce阶段对于Mapper的结果进一步进行处理.
7.Output阶段, Reduce输出数据的格式.
Combiner

1.每一个map可能会产生大量的输出,combiner的作用就是在Map端对输出先做一次合并,以减少传输到reducer的数据量,因为从map端对输出先做一
次合并,以减少传输到reduce的数据量,因为map端到reduce端会涉及到网络IO
2.combiner最基本就是实现本地key的归并,combiner具有类似本地的reduce功能,合并相同的Key对应的value,通常与Reduce逻辑一样.
3.如果不用combiner,那么所有的结果都是reduce完成,效率会相对低下,使用combiner,先完成的Map会在本地聚合,提升速度.
shuffle是什么?

系统执行排序的过程,称为shuffle,既这张图主要是对shuffle过程的描述,shuffle的是MapReduce的心脏,shuffle的主要工作就是从Map结束
到Reduce开始之间的过程. 首先看下这张图,就能够理解shuffle所处的位置。 图中的partitions,copy phase,sort phase所代表的就是shuffle的
不同阶段,也可以这样理解,shuffle描述着数据从map task输出到reduce task输入的这段过程.
map端的shuffle细节:
1.在map task执行时,它的输入数据来源于HDFD的block(map函数产生输出时,利用缓冲的方式写入内存,并出于效率考虑的方式进行预排序. 如上
图。 此处默认的内存大小100M,可通过io.sort.mr来设置,当此缓冲变成80%的时候,一个后台线程就会将内容写入磁盘,在写入磁盘之前,线程
首先根据最终要传的reduce把这些数据划分成相应的分区,在每个分区当中,后台线程进行内排序,如果有combine,就会在排序后的分区内执行)
在经过mapper的运行后,我们得知mapper的输出是这样一个key/value对:相同的key到底应该交由那个reduce去做,是现在决定的,也就是
partition的作用.接下来,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map的结果,减少磁盘IO的影响.key/value对以及partition的
结果都会被写入缓冲区,当然写入之前,key与value值都会被序列化成字节数目. reduce task在执行之前的工作就是不断地拉取当前job里面每一
个map task的最终结果,然后将不同地方拉取过来的数据不断地进行merge,也最终形成了一个文件作为reduce task的输入文件.
partition是什么?
Map的结果,会通过partition分发到Reduce上,Reducer做完Reduce操作后,通过OutputFormat,进行输出. partition是分割map上每个节点的结果
,按照key分别映射给不同的reduce,也是可以自定义的.这里可以理解为归类, Mapper的结果,可能送到Combiner做合并,Combiner在系统中并没
有自己的基类,而使用Reducer作为Combinder的积累,他们对外的功能是一样的,只是使用的位置和使用时的上下文不太一样而已. Mapper最终处
理的键值对.
就是指定Mapper输出的键值对到哪一个reducer上去.系统缺省的partitioner是HashPartitioner,它以key的Hash值对Reducer的数目取模,得到对
应的Reducer.这样保证如果有相同的key值,肯定会被分配到同一个reduce上. 如果有N个reducer,编号就为0,1,2,3....(N-1).

参照资料:
http://blog.csdn.net/u010725690/article/details/53893667
http://blog.csdn.net/cnhk1225/article/details/50859216
http://www.tuicool.com/articles/uaQVjqm















 168
168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









